
Write Optimized Indices
B+-tree의 경우는 write-intensive한 일에 대해서, 즉 쓰기 연산이 많은 작업에서는 비효율적일 수 있습니다. 하나의 leaf노드강 하나의 I/O가 필요한데, 총 100개의 record들에 대해 write operation을 수행하고 싶으면 최악의 경우 100번의 I/O가 필요할 수 있습니다.
따라서 write에 집중된 작업에 특화된 방법이 필요했고 그것이 Log-structured merge tree (LSM tree)입니다.
Log Structured Merge (LSM) Tree
LSM tree는 매우 빠른 insertion을 제공하며, 그대신 B+-tree에 비해 조금 느린 search performance를 보여줍니다. *search complexity of B+-tree is O(height). B+-tree와 달리, LSM-tree는 메모리에 먼저 기록하고 주기적으로 정렬(batch)된 형태로 디스크에 한 번에 순차 쓰기 함으로써 I/O 횟수를 획기적으로 줄일 수 있었습니다.
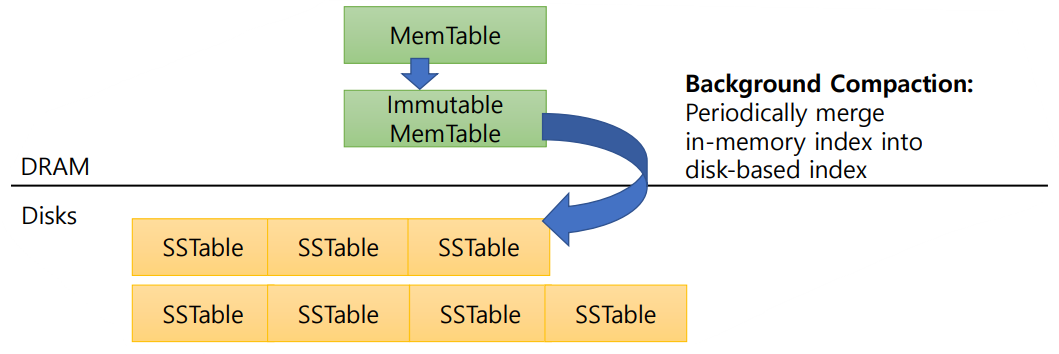
위 그림은 LSM-tree의 구조를 그림으로 나타낸 것이며, 각각 다음의 아키텍처로 구성됩니다:
- MemTable - 이는 SkipList(또는 Red-Black Tree)로 구성됩니다. DRAM 상에서 정렬 상태를 유지하면서 빠른 삽입/검색/삭제를 지원합니다. *B+-tree와 달리 삽입/검색/삭제가 DRAM 위에서 이뤄지기 때문에 매우 빠르게 동작을 수행할 수 있습니다.
- Immutable MemTable - 이는 Disk로 Flush되는 대상으로, MemTable이 가득 차면 읽기 전용 테이블인 Immutable MemTable로 고정합니다. 그 후 백그라운드 쓰레드가 Disk로 Flush합니다.
- SSTable - 이는 정렬된 불변 파일입니다.




위 그림과 같은 과정을 통해 SSTable이 만들어지고, SSTable이 너무 많아지면 Background Compaction을 통해 Disk의 다음 level로 SSTable을 내려보냅니다. 하지만 이렇게 만들어지는 SSTable은 DRAM에서 이뤄지는 Insertion과 독립적으로 이뤄지기 때문에 즉, 같은 key-value 데이터가 서로 다른 SSTable에 저장될 수 있습니다. 데이터가 겹쳐서 저장될 수도 있는 것입니다. 이를 Amplification Problem이라고 부르며 이를 줄이기 위해서 Background Compaction을 수행합니다:
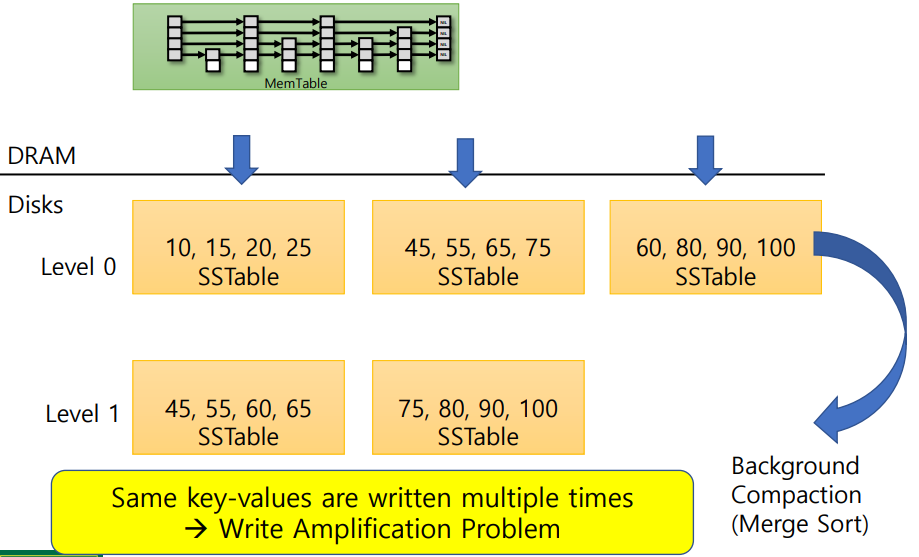
*LSM-tree의 읽기 쓰기 경로
1. 쓰기 경로 (Write Path)
- 삽입/갱신/삭제 요청이 오면 MemTable에 바로 기록(삭제는 Tombstone 마커로 기록).
- MemTable이 임계 크기에 도달하면 Immutable MemTable로 전환되고, 새 MemTable을 할당.
- 백그라운드 스레드가 Immutable MemTable을 SSTable(Level 0) 로 디스크에 flush (배치 순차 쓰기).
- Level 0 SSTable 수가 임계치를 넘으면 Compaction(merge-sort) 을 통해 하위 레벨과 병합하여 더 큰 SSTable로 재배치.lecture20.LSM-and-Query…
장점: 디스크 접근은 순차/배치로 일어나 IOPS 소모가 작다.
문제점: 같은 키가 여러 레벨에 중복 저장 → Write Amplification 및 Compaction 부하.lecture20.LSM-and-Query…
2. 읽기 경로 (Read Path)
- MemTable → Immutable MemTables 를 차례로 탐색.
- 디스크 레벨은 보통 Bloom Filter 로 전체 SSTable 중 “해당 키가 있을 법한 파일”만 빠르게 거름.
- SSTable 내부에서 Block Index와 Binary Search로 키 위치를 찾음.
- 동일 키가 여러 번 나타나면 가장 최신(가장 위 레벨) 값을 반환하고, Tombstone이면 ‘삭제’로 처리.
읽기 비용은 레벨 수와 Bloom Filter 효율에 따라 달라지며, Compaction을 게을리 하면 Read Amplification이 커진다.
이런 주기적인 Background Compaction이 이뤄져야 Amplification도 줄어들어서, 성능이 좋아지지만, Insertion은 DRAM에서 이뤄지고, Backgroud Compaction은 Disks에서 이뤄지기 때문에 속도 차이가 발생할 수 있습니다. 이런 경우는 Insertion을 Stall함으로써 Background Compaction이 이뤄지기 기다리는 방법을 사용합니다. 이는 당연히 성능을 낮추는 결과를 만들긴 합니다:
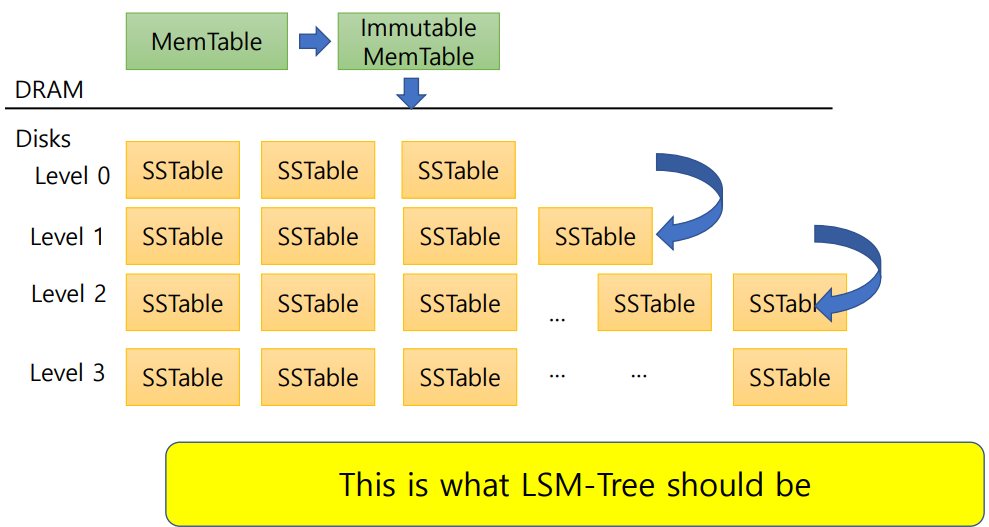
*참고로 높은 level의 SSTable이 낮은 level에 비해 크기도 크고 (because of Merge Sort) 하나로 정렬된 많은 데이터가 묶여있기 때문에 적은 양의 I/O로 빠르게 데이터를 찾을 수 있습니다.


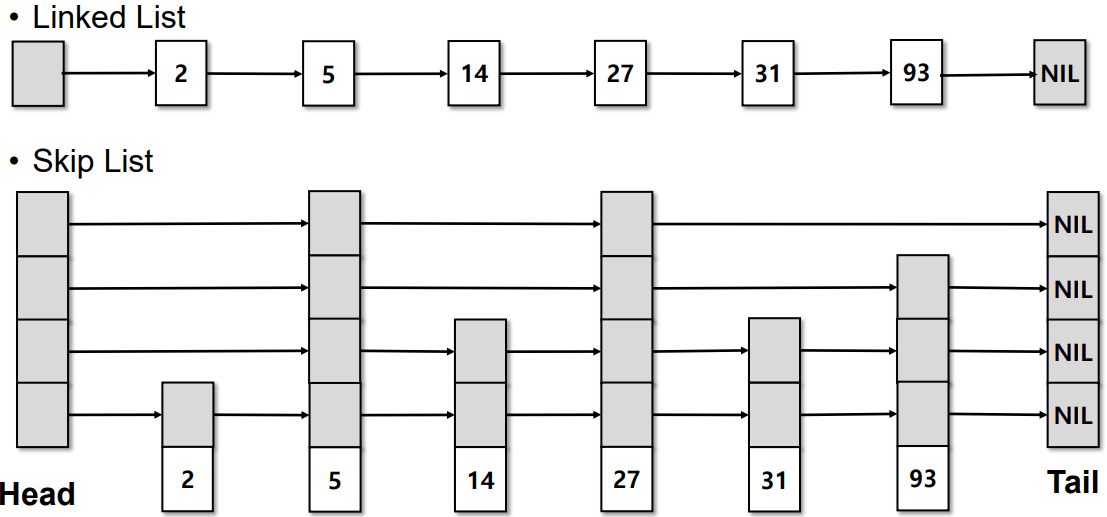
SkipList: Randomized data structure
Linked List와 달리 SkipList는 O(logN)에 탐색, 삽입, 삭제를 수행할 수 있고, 간단한 포인터 조작만으로 flush 시 정렬 배열(SSTable)로 변환이 쉽숩니다.
2024.05.28 - [[학교 수업]/[학교 수업] Data Structure] - 자료구조 및 알고리즘 11 - B+ Tree, BR Tree and Skip List
자료구조 및 알고리즘 11 - B+ Tree, BR Tree and Skip List
0. 들어가기 전2024.05.14 - [자료구조 및 알고리즘] - 자료구조 및 알고리즘 10 - 2-3 Tree and 2-3-4 Tree 자료구조 및 알고리즘 10 - 2-3 Tree and 2-3-4 Tree0. 2-3 Tree Likewise, 2-3 Tree is also a height balanced tree. The time
hw-hk.tistory.com
'[Konkuk Univ. 3rd] > [Database]' 카테고리의 다른 글
| [Database] Concurrency Control (1) | 2025.06.06 |
|---|---|
| [Database] Query Processing (2) | 2025.05.27 |
| [Database] Transaction (2) | 2025.05.25 |
| [Database] Hashing (1) | 2025.05.24 |
| [Database] Indexing - B+-tree (4) | 2025.05.14 |