
https://arxiv.org/abs/2308.00442
FLatten Transformer: Vision Transformer using Focused Linear Attention
The quadratic computation complexity of self-attention has been a persistent challenge when applying Transformer models to vision tasks. Linear attention, on the other hand, offers a much more efficient alternative with its linear complexity by approximati
arxiv.org
Abstract.
Transformer 모델을 vision task에 적용할 때, self-attention의 quadratic computation complexity는 지속적인 문제로 작용해 왔습니다. 반면에 Linear Attention은 사전에 설계된 mapping 함수를 통해 softmax 연산을 근사함으로써, linear complexity를 갖는 훨씬 더 효율적인 대안을 제공합니다. 그러나 현재(2023년)의 Linear Attention 방법들은 심각한 성능 저하를 겪거나 mapping 함수로 인해 추가적인 computation overhead를 유발한다는 단점이 있습니다.
본 논문에서는 높은 효율성과 표현력을 동시에 달성하기 위해 새로운 focused linear attention 모듈을 제안합니다. 먼저 linear attention의 성능 저하를 유발하는 요인들을 focus ability와 feature diversity라는 두 가지 관점에서 분석하며, 이러한 한계를 극복하기 위해, 낮은 연산 복잡도를 유지하면서도 self-attention의 표현력을 향상시키는 효과적인 mapping 함수와 효율적인 rank restoration 모듈을 도입합니다.
Introduction.
Transformer를 vision model에 적용하는 것은 단순한 작업이 아닙니다. 경량화된 CNN과 달리, global receptive field를 갖는 self-attention을 사용할 경우 sequence length N에 비례하는 quadratic computation complexity O(N^2)로 인해 막대한 연산 비용이 발생합니다. 기존 연구들은 sparse global attention pattern을 설계학나 더 작은 attention window를 적용하는 등의 방식으로 global receptive field를 더 작은 영역으로 제한하여 이 문제를 완화하고자 했습니다. 이러한 방법들이 효과적이기는 하나, 지정된 attention pattern으로 인해 다른 영역의 유용한 특징들을 무시하기 쉽거나, long-range dependencies를 모델링하는 능력을 희생하게 됩니다.
반면, Linear attention은 전반적인 복잡도를 낮추어 이러한 연산량의 딜레마를 해결할 수 있는 간단하면서도 효과적인 대안으로 여겨져 왔습니다. 초기 연구는 연산 복잡도를 O(N^2)에서 O(NlogN)으로 압축하는 locally-sensitive hashing 기법을 활용했습니다. 그럼에도 불구하고, 이 방식은 complexity term 앞에 큰 상수가 붙기 때문에 일반적인 상황에서는 여전히 연산 비용을 감당하기 어렵습니다. 최근(2023년)의 연구들은 self-attention에서 softmax 함수를 사용하는 것이 사실상 모든 queries와 keys 간의 pairwise computation을 강제하며, 이로 인해 O(N^2)라는 지배적인 복잡도가 발생한다는 사실에 주목했습니다.
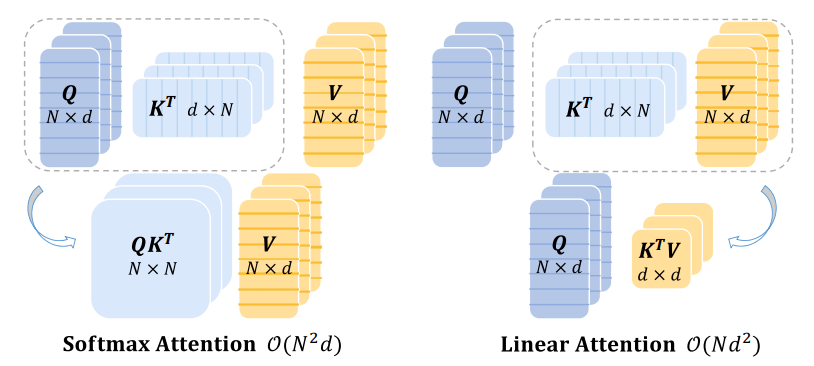
이를 해결하기 위해, 여러 접근법들이 단순한 활성화 함수나 맞춤형 매핑 함수를 채택하여 원래의 softmax 함수를 근사하고 있습니다. 그림 1. 에 묘사된 바와 같이, 연산 순서를 (query x key) x value에서 query x (key x value)로 변경함으로써 전체 연산 복잡도를 O(N)으로 줄일 수 있습니다. 그러나 기존 softmax attention과 비교할 때, linear attention 접근법들은 여전히 심각한 성능 저하를 겪고 있으며 매핑 함수로 인한 추가적인 computational overhead를 유발할 수 있어 실제 응용에 제약이 따릅니다.
본 논문에서는 linear attention의 접근법들의 이러한 한계를 겨냥하여, 높은 효율성과 표현력을 모두 달성하는 새로운 focused linear attention 모듈을 제안합니다. 구체적으로, linear attention의 성능 저하를 유발하는 요인들에 대해 두 갈래의 분석을 수행하고 이에 상응하는 해결책을 제시합니다.
첫째, 기존 linear attention 모듈의 attention weight 분포는 상대적으로 평탄하여, 가장 유용한 특징들을 다루기 위한 focus ability가 부족합니다. 이에 대한 해결책으로, queries와 keys의 feature direction을 조정하여 attention weight를 더 잘 구별되도록 만드는 간단한 매핑 함수를 제안합니다.
*Note: original ViT가 사용하는 softmax attention은 지수 함수를 사용하기 때문에 값이 큰 것은 극단적으로 키우고, 작은 것은 0에 가깝게 눌립니다(sparsification). 그리고 image classification이나 object detection에서 픽셀간의 관계 또한 매우 sparse합니다. '강아지'를 분류할 때는 강아지의 눈, 코, 귀 픽셀에만 attention이 집중되어야지, 배경인 하늘이나 잔디에 골고루 분산되면 오히려 노이즈가 됩니다. 하지만 Linear attention을 통해 softmax를 근사하면, 지수 함수가 갖는 sparsification 기능이 사라져, 결과적으로 특정 픽셀에 집중하지 못하고 모든 픽셀의 정보를 골고루 섞어버리는 oversmoothing이 발생합니다.
둘째, attention matrix의 diminished rank가 linear attention 내 특징 다양성을 저하시킨다는 점에 주목했습니다. 이를 해결하기 위해, 원래의 attention matrix에 추가적인 depthwise comvolution을 적용하는 rank restoration 모듈을 제안합니다. 이는 행렬의 rank를 복원하는데 도움을 주며 여러 위치의 출력 feature들을 다양하게 유지시킵니다.
*Note: original softmax attention NxN matrix는 softmax를 통과하므로 행렬의 rank가 최대 N까지 보장됩니다. 반면, Linear attention은 φ(Q), φ(K)의 내적으로, 이 두 행렬을 곱한 결과 행렬의 rank는 최대 min(N,d)입니다. 즉, rank가 d로 고정됩니다. 이는 N개의 이미지 patch들이 d개의 basis로만 표현된다는 뜻이며, 이를 CNN(DWC)를 이용해 다시 복원하는 것입니다.
Related Works.
Vision Transformer.
Transformer와 self-attention mechanism은 NLP 분야에서 처음 도입되었으며, 이후 computer vision 분야에서도 광범위한 연구 관심을 얻었습니다. 그럼에도 불구하고, self-attention의 높은 computational complexity는 vision task에서 이를 직접 적용하는 데 제역을 가했습니다. 이전 연구들은 여러 관점에서 이 문제를 해결하고자 했으며, ViT는 인접한 픽셀들을 단일 token으로 병합하여 입력 해상도를 줄이는 방법을 제안했습니다.
또 다른 연구 흐름은 feature resolution을 점진적으로 줄이면서, 신중하게 설계된 attention pattern을 채택하여 참조하는 토큰의 수를 제한하는 것입니다. 많은 연구들은 sparse attention pattern을 사용하고 전역적인 관점에서 참조 토큰을 선택합니다.
일부 연구들은 Convolution 연산이 transformer 모델에 유용하며 전반적인 효율성을 향상시키는 데 도움이 될 수 있다는 점에도 주목했습니다. depthwise convolution과 같은 효율적인 합성곱 연산자와 transformer block을 결합하여 더 나은 trade-off를 달성합니다. 하지만 이런 접근법들은 여전치 softmax 연산자에 의존하고 있으며, softmax가 본질적으로 가지고 있는 높은 연산 복잡도는 불가피하게 모델 아키텍처 설계와 실제 응용에 있어 불편함을 초래합니다.
Linear Attention.
위 방법들과 별개로, 또 다른 연구 흐름은 linear attention을 통해 높은 computational complexity 문제를 해결합니다. linear attention은 self-attention 내의 softmax 함수를 분리된 kernel functions로 대체합니다. 이 경우 linear attention은 pairwise similarity인 QK^T를 먼저 계산할 필요가 없습니다. 그림 1. 에서 묘사된 바와 같이, 행렬 곱셈의 결합 법칙에 기반하여, linear attention은 K^TV를 먼저 계산하도록 연산 순서를 변경할 수 있으며, 이를 통해 연산 복잡도를 O(N^2d)에서 O(Nd^2)로 줄일 수 있습니다.
이는 효율적이기는 하지만, softmax attention 만큼 효과적인 linear attention 모듈을 설계하는 것은 간단한 문제가 아닙니다. Performer는 orthogonal random feature를 사용하여 softmax 연산을 근사합니다. Efficient attention은 Q와 K에 각각 softmax 함수를 적용하는데, 이는 자연스럽게 QK^T의 각 행의 합이 1이 되도록 보장합니다 ...
그럼에도 불구하고, 현재의 linear attention 설계들은 softmax attention을 따라잡기에는 표현력이 부족하거나, 복잡한 kernel 함수로 인해 추가적인 연산 오버헤드를 수반합니다. 본 연구에서는 focus ability와 feature diversity의 관점에서 linear attention의 성능 저하 원인을 분석합니다. 이러한 분석을 바탕으로, 낮은 연산 복잡도로 softmax attention 모다 더 나은 성능을 달성하는 focused linear attention이라는 새로운 linear attention 모듈을 제안합니다.
Preliminaries.
Vision Transformer and Self-Attention.
먼저 ViT 내 self-attention의 일반적인 형태를 다시 살펴봅니다. 입력된 N개의 tokens가 주어졌을 때, 각 head 내에서 self-attention은 다음과 같이 쓸 수 있습니다:

여기서 W_Q, W_K, W_V는 projection matrices이며, Sim()은 유사도 함수를 나타냅니다. 현대의 ViT들은 주로 softmax attention을 사용하고 있으며, 이때 유사도 Sim()은 exp(QK^T)로 측정됩니다. 이 경우, 모든 query-key pair 간의 유사도를 계산하여 attention map을 얻게 되며, 이는 O(N^2)의 연산 복잡도를 유발합니다.
quadratic computation complexity로 인해 global receptive field를 갖는 self-attention을 단순히 사용하는 것은 다루기 어려워지며, 일반적으로 과도한 연산 비용을 수반합니다. 기존 연구들은 sparse global attention pattern을 설계하거나, 더 작은 attention window를 적용하는 방식으로 이 문제를 해결하고자 했습니다. 효과적이기는 하나, 이러한 접근법들은 설계된 attention pattern의 형태에 영향을 받기 쉽고, long-range dependencies를 모델링하는 능력을 불가피하게 희생하게 됩니다.
Linear Attention.
이에 비해 linear attention은 연산 복잡도를 O(N^2)에서 O(N)으로 제한하는 효과적인 대안으롤 여겨집니다. 구체적으로, 원래 유사도 함수에 대한 근사로서 kernel이 도입됩니다:

여기서 self-attention module은 다음과 같이 다시 쓸 수 있습니다:

이런 방식으로 행렬 곱셈의 결합 법칙에 기반하여 연산 순서를 (QK^T)V에서 Q(K^TV)로 바꿀 수 있습니다(그림 1. 참조):

여기서 tokens 수에 대한 연산 복잡도는 O(N)으로 감소합니다. 그러나 현재의 linear attention 접근법들 역시 모델 복잡도와 표현력 사이의 딜레마에 직면해 있습니다. 한편으로 ReLU 활성화 함수를 사용하는 것과 같은 단순한 근사는 너무 느슨하여 심각한 성능 저하를 초래합니다. 다른 한편으로 세심하게 설계된 kernel 함수나 행렬 분해 접근법은 추가적인 연산 오버헤드를 유발할 수 있습니다.
Focused Linear Attention.
linear computational complexity라는 이점에도 불구하고, 다양한 이전 연구들은 softmax attention을 linear attention으로 단순히 대체하는 것이 일반적으로 심각한 성능 저하를 초래한다는 점을 입증했습니다. 이 섹션에서는 먼저 linear attention의 저조한 성능에 대해 focus ability와 feature diversity라는 두 가지 관점에서 상세히 분석합니다. 그런 다음, 이러한 문제들을 적절히 해결하여 높은 효율성과 표현력을 달성하는 focused linear attention을 제안합니다.
Focus Ability.
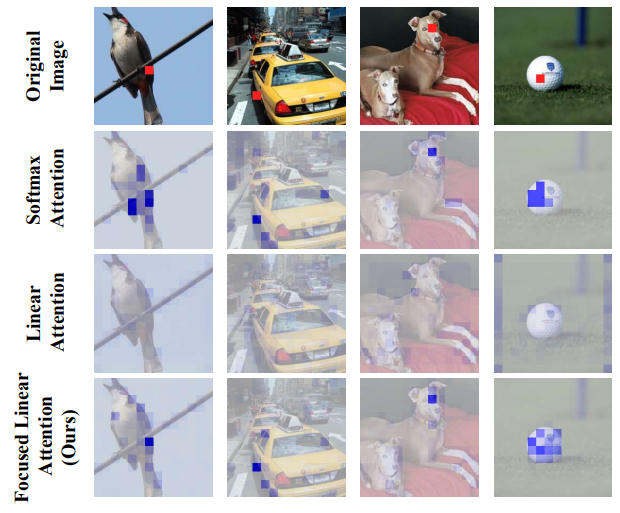
softmax attention은 사실상 nonlinear reweighting mechanism을 제공하여 중요한 feature들에 concentrate할 수 있게 해줍니다. 위 그림 3. 에서 볼 수 있듯이 softmax attention의 attention map 분포는 foreground 객체들과 가은 feature region에서 특히 뾰족합니다. 이에 반해 linear attention의 분포는 상대적으로 평탄하여 그 출력이 모든 feature들의 평균에 가까워지며, 더 유용한(informative) 영역에 집중하지 못합니다.
이에 대한 해결책으로, 각 queries와 key feature의 방향을 조정하여 유사한 query-key pair는 더 가깝게 끌어당기고 유사하지 않은 query-key pair는 밀어냄으로써 간단하면서도 효과적인 솔루션을 제안합니다. 구체적으로, focused function이라고 부르는 간단한 매핑 함수 f를 제안합니다:

여기서 x**p는 x의 p승을 나타냅니다. 위 식에서 입력의 non-negativity와 분모의 유효성을 보장하기 위해, 이전 linear attention 모듈들을 따라 ReLU 함수를 사용합니다. 직접 관찰할 수 있는 점은 mapping 후에도 feature의 norm이 보존된다는 점이며, 이는 오직 feature의 방향만이 조정됨을 의미합니다.

명제 1. 에 따르면 적절한 p와 함께라면, focused function f_p()는 실제로 유사한 query-key pair 쌍과 유사하지 않는 query-key pair 사이의 차이를 더 뚜렷하게 만들며, 원래의 softmax 함수처럼 뾰족한 attention 분포를 복원합니다.

위 그림 4. 는 f_p의 효과를 보여주는 예시입니다. f_p가 실제로 각 벡터를 가장 가까운 축으로 끌어당김(pull)을 볼 수 있으며, p는 이 끌어당기는 정도를 결정합니다. 이를 통해 f_p는 특징들을 가장 가까운 축에 따라 여러 그룹으로 나누는 데 도움을 주어 그룹 내의 유사도는 향상시키고 그룹 간의 유사도는 감소시킵니다.
Feature Diversity.

focus ability 외에도, feature diversity 역시 linear attention의 표현력을 제한하는 요인 중 하나입니다. 그 가능한 원인 중 하나는 attention matrix의 rank에 기인하며, 여기서 상당한 차이를 볼 수 있습니다. N = 14 x 14인 DeiT-Tiny의 transformer layer 중 하나를 예로 들면, 그림 5. (a) 에서 attention matrix가 full rank를 가짐을 볼 수 있으며, 이는 V로부터 feature를 aggregation할 때의 다양성을 보여줍니다.
그럼에도 불구하고, linear attention의 경우 이를 달성하기가 매우 어렵습니다. 사실, linear attention에서 attention matrix의 rank는 tokens 수 N과 각 head의 채널 차원 d에 의해 다음과 같이 upper bound가 정해집니다:

여기서 d는 일반적인 ViT 설계에서 대개 N보다 작습니다. 예를 들어 DeiT에서는 d = 64, N = 196이고, SwinT 에서는 d = 32, N = 49 입니다. 이 경우 attention 행렬 rank의 상한선이 더 낮은 비율로 제한되며, 이는 attention map의 더 많은 rows들이 심각하게 homogenized 됨을 나타냅니다. self-attention의 출력은 동일한 V 집합의 가중합이므로, attention 가중치의 homogenization은 불가피하게 aggregated features 들 사이의 유사성으로 이어집니다.
위 그림 5. (b)에서 기존 softmax attention을 linear attention으로 대체하고 attention map의 rank를 나타냅니다. rank가 크게 감소하였고, attention 행렬의 많은 행들이 유사해진 것을 관찰할 수 있습니다.
이에 대한 해결책으로, linear attention의 이러한 한계를 해결하기 위해 간단하지만 효과적인 솔루션을 제안합니다. depth-wise convolution 모듈이 attention 행렬에 추가되며, 출력은 다음과 같이 공식화될 수 있습니다:
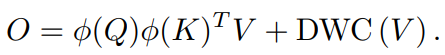
이 DWC 모듈의 효과를 더 잘 이해하기 위해, 이를 일정의 attention으로 간주할 수 있습니다. 이 attention에서는 각 query가 전체 feature V 대신 공간상에서 인접한 몇 개의 features들에만 집중하게 됩니다. 이러한 locailty는 두 queries들에 해당하는 linear attention들이 동일하더라도, 서로 다른 local feature들로부터 여전히 다른 출력을 얻을 수 있게 보장하여 feature diversity를 유지합니다. DWC의 효과는 행렬 rank의 관점에서도 설명될 수 있습니다:

여기서 M_DWC는 depth-wise convolution function에 대응하는 sparse matrix를 나타내며, M_eq는 그와 동등한 전체 attention map을 나타냅니다. M_DWC가 full rank matrix가 될 수 있는 잠재력을 가지기 때문에, 사실상 동등한 attention matrix rank의 상한선을 실질적으로 높이게 됩니다. 이는 연산 오버헤드를 거의 발생시키지 않으면서도 linear attention의 성능을 크게 향상시킵니다.
추가적인 DWC 모듈과 함께라면, linear attention 내 attention map의 rank는 그림 5. (c)에서 볼 수 있듯 full rank로 복원될 수 있으며, 이는 기존 softmax attention과 같은 feature diversity를 유지시킵니다.
Focused Linear Attention Module.
앞서 언급한 분석을 바탕으로, 연산 복잡도는 줄이면서도 표현력은 유지하는 focused linear attention이라는 새로운 linear attention module을 제안합니다. 구체적으로 먼저 원래 softmax attention의 뾰족한 분포를 모방하는 새로운 매핑 함수를 설계합니다. 이를 기반으로 이전 linear attention 모듈들의 low-rank 딜레마에 초점을 맞추고, feature diversity를 복원하기 위해 단순한 DWC를 채택합니다. 이렇게 함으로써 새로운 모듈은 linear complexity와 높은 표현력이라는 두 가지 이점을 모두 누릴 수 있습니다:

이는 다음과 같은 이점들을 지닙니다:
- Low computation complexity as linear attention: self-attention의 연산 순서를 변경함으로써, 복잡도는 O(N^2)에서 O(N)으로 변환됩니다. 여기서 N과 d는 각각 토큰 수와 각 head의 채널 차원을 나타냅니다. 일반적인 ViT 설계에서 d는 보통 N보다 작기 때문에, 전반적인 연산량은 실질적으로 감소합니다. 또한 복잡한 kernel 함수를 설계했던 이전의 linear attention module들과 비교할 때, 제안하는 focus function f_p는 아주 단순한 연산자들만 채택하여 최ㅣ소한의 연산 오버헤드로 근사를 달성합니다.
- High expressive capability as Softmax attention: 위에서 분석했듯, kernel 기반의 linear attention 설계들은 focus ability와 feature diversity의 측면에서 일반적으로 softmax 방식에 비해 열등합니다. 제안된 focus function과 DWC를 이용하면, softmax attention 보다 더 뛰어난 성능을 달성할 수 있습니다.
추가적으로, 더 넓은 receptive field와 다영한 모델 아키텍처에 적응할 수 있는 잠재력을 지니고 있습니다. softmax attention에 기반한 현대 transformer 모델들은 토큰 수에 대한 이차 복잡도 때문에 주로 제한된 수의 key/value 쌍만을 이용합니다. 그럼에도 불구하고, linear complexity는 연산량을 동일하게 유지하면서 receptive field를 더 넓은 영역을 확장할 수 있는 능력을 부여하며, 장기 의존성 모델링이라는 이점을 누릴 수 있게 합니다.
Experiments.
(.. 자세한 내용은 논문 참조 ..)