[Database] Buffer and Indexing
Storage Access
Block (일반적으로 4KB)은 storage allocation과 data transfer의 기본 단위입니다. DB system은 disk와 memory사이의 block transfer의 수를 줄임으로써 성능을 좋게 만드려 노력합니다. 일반적으로 DB system은 가능한 많은 block들을 memory에 저장하여 유지하는 방법을 통해 transfer의 수를 줄입니다.
transfer의 수를 줄이기 위한 노력으로 disk의 block들의 복사본들이 memory에 저장되는데, 이때의 memory 공간을 Buffer라고 부릅니다. 그리고 이 buffer를 관리하는 subsystem을 buffer manager라고 부릅니다. 이 buffer manager는 buffer space를 할당하는 역할을 맡습니다.
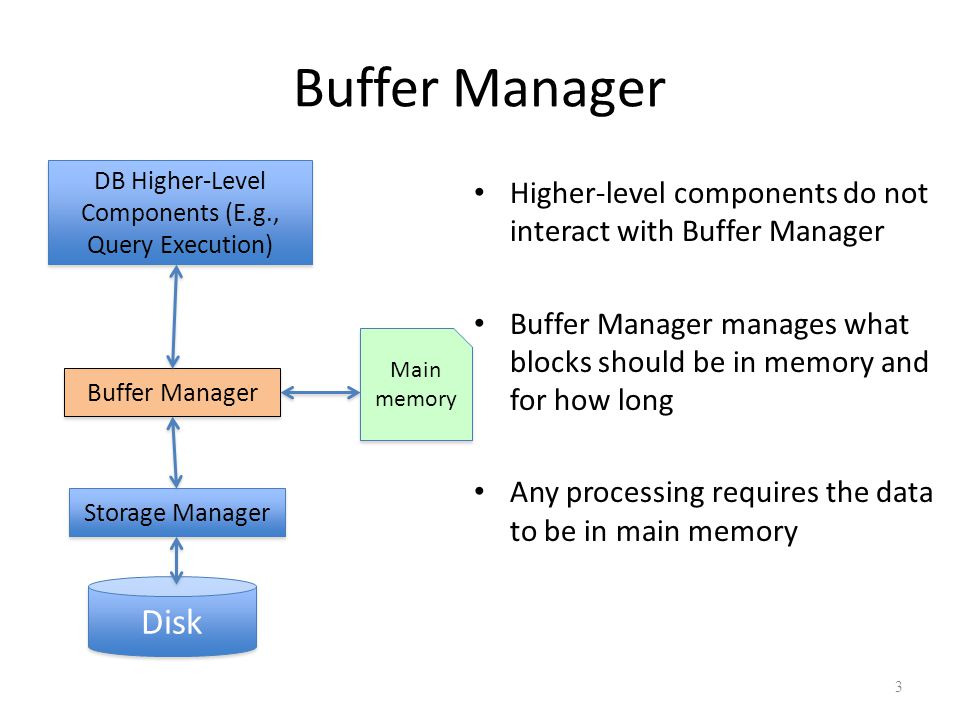
Buffer Manager
프로그램이 disk로부터 block이 필요하면 먼저 buffer manager를 호출합니다:
- 만약 buffer에 해당 block이 존재한다면, buffer manager는 main memory안에 있는 block의 주소를 return합니다. 이를 cache hit라고 부릅니다. *이게 가능하기 위해서는 buffer manager는 buffer안에 있는 block들의 주소들과 내용들을 모두 파악하고 있어야하며, 이는 hash table로 구현됩니다.
- 만약 buffer에 해당 block이 존재하지 않는다면:
- buffer에 공간이 없는 경우 disk에서 가져오는 block을 위한 자리를 만들기 위해 buffer에 있는 block을 disk로 내려보냅니다. 이때 교체되는 block은 해당 block이 한 번이라도 수정된 block입니다. *buffer에서만 수정된 경우 disk와 synch를 맞출겸, 공간도 비울겸 disk로 내려갑니다.
- disk에서 block을 buffer로 가져오면 사용자에게 해당 block의 주소를 return합니다.
Read

(1) Read Request: 사용자가 query를 통해 Read Request를 호출합니다.
(1-1) Buffer Manager는 해당 query에 필요한 block이 buffer에 있는지 확인합니다. 만약 buffer에 있다면 바로 (4)로 넘어가 block의 address를 return합니다. *cache hit
(2) If not found in buffer: 만약 buffer에서 block을 찾지 못했다면 disk로 내려갑니다. *cache miss
(3) Get Page: disk에서 block을 찾아 main memory로 옮깁니다.
(3) Replacement: 만약 buffer가 가득 찼다면 buffer에 있는 다른 block들이 dirty(수정된 기록이 있는) block인지를 확인한 후dirty하다면 disk로 내려보내 disk에 있는 block과 synch를 맞춰주고, 만약 dirty하지 않다면 disk와 synch를 맞출 필요가 없으니 그냥 버려줍니다. *이때 어떤 block을 버리거나 disk로 보내고, 어떤 block은 남겨두는지는 buffer manager의 policy에 따라 달라집니다.
(4) Get Page: main memory에서 사용자가 찾던 block의 주소를 넘겨줍니다.
Write

(1) Write Request: 사용자가 query를 통해 Write Request를 호출합니다.
(1-1) buffer manager는 해당 query에 필요한 block이 buffer에 있는지 확인합니다. 만약 buffer에 있다면 바로 그 자리에서Write operation을 수행한 후 종료합니다. *Write Request는 Read Request와 달리 사용자에게 address를 알려줄 필요는 없습니다. cache hit!
(2) If not found in buffer: 만약 buffer에서 block을 찾지 못했다면 disk로 내려갑니다.
(3) Get Page: disk에서 block을 찾아 main memory로 옮깁니다. 그 후 Write Request를 수행합니다.
(3) Replacement: Read Request와 마찬가지로 dirty유무에 따라 버릴지 disk로 내려보낼지를 결정합니다.
Transaction Commit

(1) Commit Request: 사용자가 query를 통해 Commit Request를 호출합니다.
(2) Flush Dirty Pages: buffer에 존재하는 dirty block들을 disk로 내려보내 disk와 buffer의 synch를 맞춰줍니다.
Buffer Manager
- Buffer replacement strategy (the policy): 이전에 말한 buffer의 block들이 replacement되는 기준이 됩니다.
- Pinned block: disk에 쓰여지는 것이 불가능한 block을 말합니다. 예를 들어 어떤 프로그램에 의해 사용중인 block의 경우 disk로 내려가지 않습니다. 그때 그런 block을 pinned block이라고 부릅니다.
- Pin: block에 reading/writing data가 아직 끝나지 않은 상태
- Unpin: block에 reading/writing data가 완전히 끝난 상태. 이 상태의 경우 disk로 flush될 수 있습니다.
- DB system은 여러 operation들을 동시에 수행할 수 있기 때문에 하나의 block에 여러번의 pin/unpin operation이 적용될 수 있습니다. *이 경우에는 pin count를 가지고 있으며, 오직 pin count = 0 일때만 disk로 내려보냅니다.
- Shared and exclusive locks on buffer: 위에서 말했듯이, DB system은 동시에 여러개의 operation이 동작함을 허용합니다. 그렇기 때문에 공유하는 data에 대한 충돌이 issue가 될 수 있습니다. 이를 막기 위해 DB system은 lock을 운용합니다.
- block을 읽는 경우 Reader들은 shared lock (=read lock)을 사용합니다.
- block을 쓰는 경우 Writer들은 exclusive lock (=write lock)을 사용합니다.
- Locking rules:
- 오직 하나의 프로세스만 exclusive lock(write lock)을 갖습니다. *공용의 data를 쓰는경우가 conflict가 발생할 가능성이 크기 때문에, write lock의 경우는 엄격하게 lock을 지킵니다.
- 여러 프로세스들은 shared lock(read lock)을 동시에 가질 수 있습니다. *read만 하는 경우 conflict가 발생하지 않기 때문에 read lock의 경우 동시성을 허용합니다. 만약 mutex처럼 하나의 lock을 이용하여 DB system을 운용한다면 overhead가 크기 때문에 read lock의 경우만 동시성을 허용합니다.
- shared lock과 exclusive lock은 동시에 활성화될 수 없습니다. *buffer에 대해 read lock과 write lock이 동시에 활성화 되는 것 자체가 conflict가 발생할 수 있기 때문에 이는 통제합니다.
Buffer-Replacement Policies
대부분의 OS는 least recently used (LRU strategy)를 사용합니다. 이는 사용한 지 오래된 데이터를 replacement하는 정책입니다. 하지만 LRU는 DB system과 어울리지 않는 전략일 수 있습니다. 예를 들어 join을 수행하는 경우입니다. *생각해보기
DB system에서의 query는 사실 disk의 데이터를 어떻게 사용하고 접근할 것인지에 대해 패턴화 되어있습니다. 따라서 DBMS는 이런 패턴을 이용하여 다음에 참조할 references(=block)들을 예측할 수 있습니다. *예를 들어 join 연산을 수행하는 경우 join의 연산 순서가 패턴화되어있습니다.
Toss-immediate strategy는 사용한 block을 바로 replacement하는 전략입니다. 이 전략의 variation으로서 Most recently used (MRU) strategy가 있습니다. MRU는 임의의 block이 process에 의해 pinned인 상태에서 operation이 끝나 unpinned 되면 해당 block은 replacement의 후보가 되어 replacement가 됩니다. *이는 LRU에 비해 join연산에서 강합니다.
buffer는 여러가지 통계정보를 이용할 수도 있습니다. 이를 통해 특정 table 혹은 block을 사용자가 요청할 확률을 계산할 수 있습니다. 예를 들어 data dictionary를 가장 자주 사용했다면, Heuristic하게 data-dictionary block을 memory(buffer)에 올려놓을 수도 있습니다.
이때 Filesystem은 write operation의 순서를 재배열할 수도 있습니다. 즉 사용자가 w1, w2, w3 순으로 write operation을 수행했더라도 filesystem이 자제적으로 w2, w1, w3 순으로 명령을 수행할 수도 있습니다. 이렇게 되면 이미 존재하지 않는 데이터에 대해 수정을 요청하는 에러가 발생할 수 있으므로 이런 문제를 해결하기 위해 프로그래머는 순서에 주의하여 명령을 요청해야합니다. *혹은 fsynch()를 통해 write operation의 순서를 강제할 수도 있습니다.
Indexing
indexing은 어떤 데이터를 찾을 때 속도를 높이기 위해서 사용되는 기술입니다. Search key는 record들을 찾아볼 때 사용할 attribute입니다. index file은 index entrie라고도 불리는 record들로 구성되어 있으며 아래와 같은 형태를 띕니다:

*이때 pointer는 실제 데이터를 가르키는 pointer입니다.
index는 일반적으로 original table보다는 크기가 작습니다. *pointer로 인해 실제 데이터를 저장하지 않아도 되기 때문에. 그리고 index의 방법론은 크게 두 가지로 구분할 수 있습니다. (1) ordered indices: search-key가 정렬되어있어 seach-key를 기준으로 이진 탐색을 통해 빠르게 데이터에 접근할 수 있습니다. (2) hash indices: hash function을 통해 저장되어있는 bucket에서 데이터를 접근합니다.
Index Evaluation Metrics
- Access types supported efficiently. E.g.,
- Point query (i.e., key = value): 특정한 한 값을 찾는 쿼리의 경우 hash index나 ordered index모두 효율적으로 사용가능합니다.
- Range query (i.e., low < key < high): 특정한 범위에 해당하는 쿼리(들)을 찾는 경우 hash index는 효율적으로 처리할 수 없을 수도 있습니다. *ordered index는 이미 정렬되어있기 때문에 빠르게 접근할 수 있습니다.
- Access time
- Insertion time
- Deletion time
- Space overhead: 굉장히 많은 index file들을 통해 데이터를 빠르게 접근한다면 memory공간의 비효율이 발생할 수 있습니다. 메모리 공간의 비효율 또한 index의 평가기준이 되야합니다.
Ordered Indicies
ordered index에서는 각각의 index들이 search key를 기준으로 정렬되어 데이터가 정렬되어있습니다. 이를 구현하는 대표적인 예시가 B+-tree입니다. ordered index에서 자세히 들어가면 크게 두 가지로 구분할 수 있습니다:
- Clustered index (primary index)
- index에서의 search key의 정렬과 file에서의 entries들의 정렬이 같은 경우
- Secondary index (nonclustered index)
- search key로 특징되는 index의 순서와 file에서 정렬되어있는 데이터들의 순서가 다른 경우
만약 sequential file의 순서가 search key의 순서와 같다면(clustered index), 이때 그 file을 indexed-sequential file(ISAM)이라고 합니다.
Dense Index Files
Dense index는 clustered index 방법의 한 종류로 각각의 index가 모든 search key value를 특정하고 있는 index를 말합니다. 예를 들어 index파일과 entry file의 정렬 기준이 ID로 똑같아서, 모든 index가 모든 entry를 가르키는 경우 Dense index file입니다:

하지만 위에 예시처럼 모든 index가 모든 entry들을 가르키지 않아도 Dense index file일 수 있습니다. 예를 들어 index의 search key는 dept_name이고 이를 이용해서 file을 정렬한 경우 1:1 mapping이 아닐 수도 있지만 dense index file입니다:

Sparse Index Files
이에 반해 sparse index는 index가 search key의 "일부"만 특정하는 것입니다:

이는 dense index file에 비해 index file을 가볍게 유지할 수 있거 index search time이 줄어든다는 장점이 있지만, 특정한 search key K를 기준으로 record를 찾으려고 할때, record file에서 sequentially searching을 해야한다는 단점이 있을 수 있습니다.
Secondary indices Example
index의 정렬 순서와 file의 정렬 순서가 같지 않은 경우를 말합니다. 아래의 예시는 index file은 salary를 기준으로 정렬되어있지만, file은 ID를 기준으로 정렬되어있는 경우를 나타냅니다:

이를 유지하기 위해서는 index file과 file 사이에 존재하는 bucket이 필수적입니다. bucket은 record들의 pointer를 가지고 있어서 index를 기준으로 record를 찾을때 record가 어디있는지를 알려줍니다. 이때 secondary indicies는 반드시 dense index이어야합니다. sparse index라면 어떤 search key K를 기준으로 record를 찾을때 file에서 sequentially search함을 가정하는데, secondary indices의 경우 index의 정렬기준과 file의 정렬기준이 달라서 K근처의 index를 기준으로 file에 들어가도 빠른 search time을 보장할 수 없습니다. 따라서 search key에 대해서는 모든 record들이 특정되어야합니다.
Multilevel index
만약 index가 memory에 fit하지 않는다면(기본적으로 실제 file은 secondary storage에 있다고 가정하고, index file은 memory에 둬서 file을 메모리에 두지 않아도 빠르게 찾을 수 있는 상황을 가정), secondary storage에 있는 index file에 접근해야하는데 이는 비용이 매우 비쌉니다. 따라서 index file에 대한 index file을 만들어서 memory에 넣는 방법을 사용합니다. 따라서 outer index는 basic index에 대한 sparse index이고, inner index는 basic index인 것입니다. 이것도 크다면 다시 outer index에 대한 index file을 만들어서 관리할 수도 있습니다.
이 경우 index들이 업데이트(insertion or deletion) 된다면, 모든 level의 indices들 또한 같이 업데이트 되어야합니다. 즉, 모든 file들이 consistency를 유지하도록 해야합니다.
