

주제 선정
저희는 이전 프로젝트에서 TF-IDF나, cosine-similarity, n-grams와 같은 전통적인 NLP기법들을 사용했었습니다.
[Deep daiv.] 딥러닝 입문 프로젝트 (1) - Do you know?
주제 Do you know? 게임 Do you know? 게임은 파리올림픽에 출전한 선수들의 이름을 맞추는 게임입니다. 선수들의 이름을 맞출 수 있는 힌트 단어를 플레이어에게 보여주고 플레이어는 해당 힌트 단
hw-hk.tistory.com
그렇기 때문에, 이번 후반기 프로젝트에서는 전통적인 기법들보다는,
딥러닝 모델을 사용해보자고 생각했습니다.
또한, 딥러닝 모델은 예측하는 것을 잘하니까,
NLP task에서의 예측인 문장 생성과 관련되서 프로젝트를 하면 재밌겠다 생각했습니다.
따라서 다음과 같은 주제를 도출할 수 있었습니다
AI와 주고 받으면서 소설을 완성해볼까?
사용자와 AI는 서로 한 문장씩 혹은 여러 문장씩 주고 받으면서 하나의 큰 소설을 써 내려값니다.
아래는 사용자와 AI가 서로 주고 받으면서 소설을 완성하는,
예상 프로그램의 모습입니다:

하지만 이렇게,
사용자가 입력하는 문장과 가장 잘 어울리는 소설의 다음 문장을
AI가 생성해주면 재미없다고 저희 팀원들은 생각했습니다.
왜냐하면,
저희는 사용자가 이 프로그램을 쓰면서
'재미'를 느꼈으면 좋겠는데,
뻔한 이야기를 만들어내는 AI는 재미없을거라고 생각했기 때문입니다.
따라서 '뻔한'이야기를 만들지 않으려면,
사용자가 AI를 '뻔한'이야기를 만들지 않도록
잘 컨트롤해줄 수 있다면,
사용자와 AI가 조금 더 Interactive하게 소통할 수 있다면,
사용자가 재미를 더 느낄 수 있다고 판단했습니다.
따라서 최종적으로 저희가 원하는
AI와 사용자의 대화는 다음과 같습니다:

사용자가 다음에 나왔으면 좋겠을 AI의 문장에
재미있는 특성들을 추가해주는 것입니다.
이를 통해 AI는 뻔하고 재미없는 문장이 아닌,
재미있고 신선한 문장을 만들 수 있습니다.
모델 선정
그렇다면 이러한 task에는 어떤 딥러닝 모델이 적합할까요?
우선 저희는 아래와 같은 요소들을 모델을 선택하는 과정에서 고려했습니다:
- 문장 생성 → 문장 생성에 장점을 가지고 있는 GPT 모델이 적합합니다
- 한국어 → 저희는 한국어 데이터를 이용하기 때문에 한국어에 특화된 모델이 적합합니다
- 오픈 소스 → 저희는 딥러닝 입문반이기 때문에, 좋은 성능보단, 공부에 의의를 두었습니다
그래서 저희는
KoGPT2
를 사용하기로 했습니다.
2024.09.09 - [[Deep daiv.]/[Deep daiv.] NLP] - [Deep daiv.] NLP, WIL - 9. ELMo and GPT (1)
[Deep daiv.] NLP, WIL - 9. ELMo and GPT (1)
0. Word Embedding 머신 러닝 모델들이 단어를 처리하고 계산에 이용하기 위해서는, 이 단어들을 숫자로 표현(* numeric representation)을 해야만 합니다. Word2Vec은 벡터를 이용하면 제대로 단어의 의미와
hw-hk.tistory.com
GPT는 기존의 encoder-decoder 기반의 모델인 transformer에서
decoder만 가져온 모델로서 여러 층의 decoder blocks들로 구성되어있는 모델입니다.
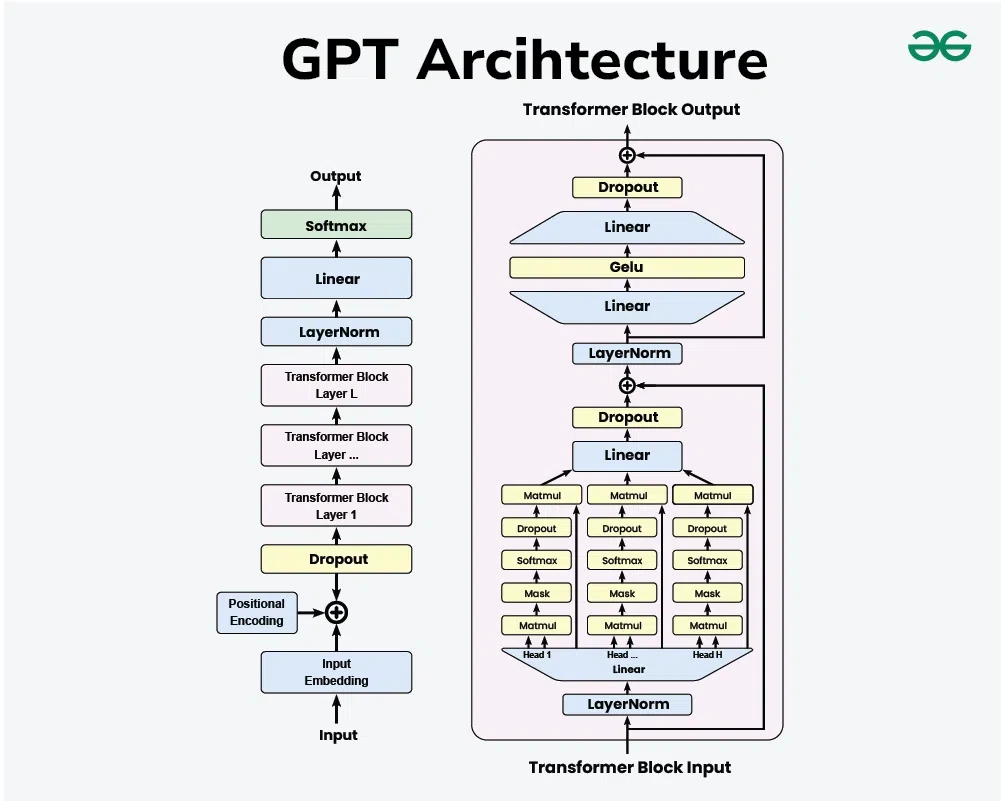

decoder block은 크게 Masked self-attention과 Feed Forware Neural Network로 나뉩니다.
여기서 Maked self-attention이 모델을 이해하는데 가장 중요한 포인트 입니다.
나는 한강에 러닝을 하러 갔다
라는 문장이 있다고 가정해보면,
토큰화를 통해'나는', '한강', '에', '러닝', '을', 하러', '갔다'로 토큰이 생성될 것입니다.(* 물론 토크나이저가 무엇인지에 따라 달라집니다.)
처음에 입력 토큰으로 '나는'이 들어간다고 했을 때 정답 단어는 '한강'입니다.
하지만 Attention을 아시는 분은 아시겠지만,
Attention Matrix의 크기는 Embedding size x Attention vector size로 정해져있습니다.
이때, '나는'에 대한 embedding vector를 이용해 Attention이 계산되고,
그 결과로 나온 값과 '한강'이라는 정답의 차이(loss)로 인해 Attention matrix의 모든 값이 수정되면 안됩니다.
왜냐하면, 이는 '나는'에 대한 Attention matrix값만 바뀌어야지,
다른 단어들의 Q, K, V matrix까지 바뀌어서는 안되기 때문입니다. *'나는' 뒤에 값들은 아직 입력되지 않은 것인데, 값이 들어오기도 전에 Attention matrix의 값이 바뀌면 안되기에 ...
따라서, 이를 막기위해 '나는'에 해당하는 Attention값을 제외한 나머지 값에 대한 Attention value는 -inf로 수정합니다. 즉 masking을 하는 것입니다.
Attention value가 -inf이면, softmax에 의한 Value에 곱해지는 Attention score는 0이 되기 때문에,
'나는'이후에 단어에 대해 Attention이 들어가지 않습니다.
정리하자면 입력 토큰을 기준으로 입력 토큰 전까지의 토큰만을 참고하게 하기 위해토큰 이후의 단어들을 마스킹하는 것을 말합니다.
그 다음으로 Feed Forward Neural Network를 통해서 모델의 비선형성 추가 (ReLU)
Attention으로 맥락에 대한 가중치를 계산했다면,
FFN을 통해서는 그 단어 자체의 가중치를 계산등을 얻을 수 있습니다.
데이터
사전 학습된 KoGPT2를 파인튜닝하기 위해서는 다양하고 많은 양의 데이터가 필요합니다.
또한, 감정과 서사구조 단계들이 레이블링 되어있는 데이터가 필요합니다.
왜 갑자기 감정과 서사구조 단계?
앞서 예상도를 보면 알 수 있듯, 저희는 AI에게 다음 문장으로 오면 좋을 특성들을 입력해줍니다.
이를 AI에게 학습시켜야하기 때문에, 저희는 각 문장별로 감정이 이렇고, 서사구조 단계가 저렇고 등을 알려줘야합니다.
데이터로 저희는 AI-Hub에서 "다양한 문화 콘텐츠 스토리 데이터"를 찾았습니다.
이 데이터는 스토리 작품을 유닛 단위로 하여,줄거리를 작성하고, 설정이나 모티프, 인물, 서사단계, 감정등의 스토리 창작 요소가 레이블링 되어있습니다.
{
"id": "03_1779",
"type": "novel",
"title": "돈이 필요해서 그만",
"genre": [
"드라마"
],
"year": 2014,
"theme": "도전",
"concept": "돈이 없어 C001가 집을 구하기 위해 부잣집 강아지 C008를 몰래 훔친 후 돌려주고 사례금을 받을 계획을 세운다.",
"structure": "스토리헬퍼 15단계",
"motif": "동물과의 우정",
"main_character": "엉뚱함",
"conflict": "강아지 C008를 둘러싼 사람들이 각자의 이익을 위해 고군분투한다.",
"characters": [
"C001",
"C002",
"C003",
"C004",
"C005",
],
"units": [
{
"id": "03_1779_01",
"next_id": "03_1779_02",
"characters": [
"토끼",
"C001",
"사자",
"개구리",
"담임선생님"
],
"stage": "Opening Salvo",
"storyline": "C001가 학교에서 수업을 듣던 도중 수업 내용에 불만이 생긴다.",
"causality": "First Action(시작)",
"story_scripts": [
{
"type": "narrative",
"location": "나레이션",
"character": [
"토끼"
],
"act": "공개하다/드러내다",
"content": "화면 속에 토끼 그림이 나타난다."
},
{
"type": "script",
"location": "나레이션",
"character": [
"C001"
],
"act": "말하다",
"emotion": "담담하다",
"content": "옛날 옛날에 토끼 형제가 세 마리 살았다."
},
{
"type": "narrative",
"location": "나레이션",
"character": [
"토끼"
],
"act": "보다",
"emotion": "긴장되다",
"content": "토끼 세 마리가 풀숲에 숨어 망을 보고 있다."
},
{
"type": "script",
"location": "나레이션",
"character": [
"C001"
],
"act": "말하다",
"emotion": "담담하다",
"content": "이 토끼들은 숨어서 망을 보는 게 인생의 전부였다."
},
{
"type": "narrative",
"location": "나레이션",
"character": [
"사자"
],
"act": "공격하다",
"emotion": "비장하다",
"content": "사자가 튀어나와 토끼들을 겁준다."
},
우선 저희는 감정과 서사구조 단계를 사용자가 선택할 수 있는 특성으로 선택했습니다.
감정은 프로그램의 재미를 위해서,
서사구조 단계는 소설의 완성도를 위해서입니다.
만약 AI가 만들어내는 문장이 발단이었다가,
절정이었다가, 문제를 해결하지도 않고
다시 발단으로 넘어간다면 소설의 완성도가 떨어질 것입니다.
전처리
KoGPT2를 파인튜닝하기 전에, 데이터를 저희 프로그램 목적에 맞게 전처리 해야합니다.
서사구조와 감정 맵핑
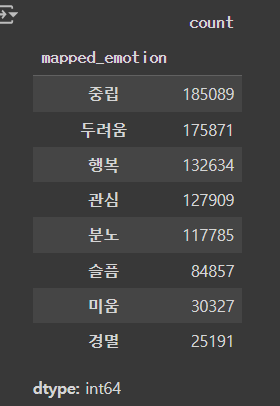
원 데이터에는 서사구조 단계는 총 27종류, 감정은 90여 종류가 있었습니다.
만약 사용자가 선택할 수 있는 감정의 종류가 90개나 있다면,
사용자가 선택하기도 힘들 뿐더러
각 감정별로 AI가 학습하기 힘들것이라고 판단했습니다.
따라서 저희는 감정과 서사구조 단계의 종류
각각 6종류씩으로 대폭 줄였습니다

감정 레이블링의 경우 처음에는 8개의 감정으로 레이블링을 시도했는데,감정간의 데이터 불균형이 심해,다시 6개의 감정 레이블로 통합해주었습니다.

대사
모델이 소설 문장을 생성할 때,
다음과 같이 문장을 생성한다면 사용자는 혼란스러울 것입니다:
정조가 얘기했다. 영의정은 역모를 꾸미지 않았다. 중신1이 소리친다. 영의정은 전하를 해치려 한 자입니다!
바로,
대사와 대사가 아닌 부분이 구분이 안된다는 점입니다.
따라서 학습 데이터 수준에서
대사라면 따옴표 ("") 를 추가하는 전처리를 수행했습니다.

3문장씩 묶기
사용자와 AI가 문장을 주고 받으며 소설을 완성하는 것이 저희 프로그램의 목표입니다.
하지만, AI가 한 문장씩만 찔끔 찔끔 생성한다면,
소설 한 편을 만들어나가기 굉장히 오래걸릴 것입니다.
따라서 저희는 데이터 수준에서 문장들을 묶어 AI가 출력하는 문장의 길이를 조절하려 했습니다.
저희는 우선 3문장씩 묶어주었는데,
사용자가 작성하는 문장의 길이가 3문장을 넘지 않을 것이라는 판단과,
AI가 혼자서 우다다 쏟는 느낌이 아니라 적당히 생성하는 문장의 길이가 3문장 정도 일 것 같다는 휴리스틱한 판단이었습니다.
3문장씩 묶을 때의 기준은
소설의 순서를 유지하며,
서사구조가 가능한 같은 문장끼리
묶어주었습니다.

파인 튜닝
저희 프로그램은 사용자와 GPT가 서로 대화를 주고 받으면서 소설을 완성합니다.
이는 Q&A 혹은 Chatbot Task와 유사합니다.
그래서 저희는 파인튜닝의 인풋을 다음과 같이 정했습니다.
- Input: <Q_TOKEN> 이전 문장 <DELIM> 감정 <DELIM> 서사구조 <DELIM> <A_TOKEN> 이후 문장
이를 통해 이전 문장과 감정, 사서구조를 이용해서 이후 문장을 예측하는 모델로 튜닝할 수 있습니다.
소설 생성단계의 인풋은 다음과 같습니다:
- <Q_TOKEN> 사용자 입력 문장 <DELIM> 감정 <DELIM> 서사구조 <DELIM> <A_TOKEN>
max-length 설정
max-length는 한 번에 모델에 넣을 input의 길이를 의미합니다.
모델을 파인 튜닝 시킬때는 모든 input의 길이를 맞춰주어야합니다.
max-length에 맞춰서 Attention matrix의 크기가 정해지기 때문입니다.
만약 max-length가 너무 짧다면,
데이터의 문장들이 잘려서 들어갈 것이고 이는 정확도의 감소를 일으킬 것입니다.
반면, max-length가 너무 길다면,
학습을 하는데에 메모리의 사용량이 너무 커질 수 있습니다.
따라서 적당한 max-length를 설정하는 것이 중요합니다.
그래서 저희는 3문장 묶음의 토큰길이를 통계를 내봤습니다.

토큰의 길이가 100개가 안되는 것들이 대부분을 차지함을 알 수 있습니다.
저희의 입력은 이전문장과 이후문장을 같이 인풋으로 넣어주기 때문에,
그래서 저희는 max-length값을 256으로 설정했습니다.
Attention Mask
max-length를 256으로 설정하면,
원래 데이터의 길이가 256보다 짧은 데이터들은 뒤에 <PAD>값이 들어가게 됩니다.
이 <PAD>는 Attention계산을 하는데
불필요할 뿐더러 정확도를 낮추기도 합니다.
따라서 Attention Mask를 만들어서 <PAD>값에 대한 Attention 계산을 하지 않도록 막습니다.

문제점
위 방식대로 파인 튜닝을 시킨 KoGPT2를 이용해 몇 가지 실험을 진행해봤는데,
다음과 같은 문제점들이 있었습니다.
등장인물 인식
AI-Hub의 원본 데이터는 등장인물의 이름이 C001과 같은 값으로 되어있습니다.
이러한 형태의 데이터를 가지고 파인 튜닝을 시켰기 때문에, 저희의 모델은
사용자가 입력하는 등장인물의 이름을 인식하지 못하고,
C001로 문장을 출력하는 문제가 있었습니다.

그래서 저희는 등장인물 이름 변환기를 통해 해결하고자 했습니다.
등장인물 이름 변환기
이름은 뭔가 거창한데 사실 그냥 딕셔너리입니다.
사용자가 프로그램을 사용하기 전에,
소설에 등장하는 등장인물의 이름을 알려주면,
그 이름들을
C001, C002에 하나하나 매핑해주어서 관리합니다.

모델의 인풋으로 들어갈 때는 C001과 같이 원본 데이터의 형식을 유지하고 출력되어 사용자에게 보여질 때는 "홍길동"과 같은 실제 이름으로 보이도록 했습니다.

하지만 만약 사용자가 '준수'라는 이름을 사용하고 싶다면,
'준수'는 C001과 같은 이름과 매핑이 되는데
이때,
준수는 그저 법을 준수했을 뿐이다.
과 같은 입력을 사용자가 넣는다면
등장인물 이름 변환기를 통해 모델에는
"C001는 그저 법을 C001했을 뿐이다."
와 같이 들어갈 것입니다.
이는 등장인물의 이름을 그저 Rule Base로 처리하면 안됨을 보여줍니다.
따라서 저희는 NER을 통해 이를 해결했습니다.
NER
NER은 Named Entity Recognition의 약자로
말 그대로 텍스트 문장에서 이름이 있는 개체를 찾아주는 것입니다.
위 예시에서
'사람' '준수'는 PERSON으로 인식해야하는 반면,
'-을 준수하다'의 '준수'는 이름이 있는 개체가 아니기 때문에 인식하지 않습니다.
이 처럼 PERSON으로 인식하는 개체에 대해서만 등장인물 이름 변환기를 사용하는 방법을 통해
문제를 해결했습니다.

모델의 평가
소설을 잘 썼다는 것은 무엇일까요?
누군가는 다양한 표현을 많이 쓰면 소설을 잘 썼다고 합니다.
또 누군가는 플롯이 명확해야 소설을 잘 썼다고 평가합니다.
또 다른 누군가는 주제가 뚜렷해야 소설을 잘 썼다고 말합니다.
즉, 사람마다 평가기준이 다르다는 것입니다.
하지만 모델의 평가는 상당히 중요합니다.
Validation Set을 통한 평가는
과적합 유무나 하이퍼 파라미터 수정에 기준이 되기 때문입니다.
하지만, 저희는 소설을 만든다는 특수한 task때문에 Validation이 불가능했고,
저희 팀원들이 일일이 하이퍼 파라미터를 수정했습니다.
맥락 이해
저희 모델은 소설의 맥락을 이해하지 못한다는 문제점도 있었습니다.
저희 모델에 들어가는 입력값을 보면 이해할 수 있는데,
문장 생성단계에서의 인풋에는 사용자 입력 문장 한 문장과 감정, 서사구조 단계 데이터만 들어가기 때문에,
모델은 직전에 사용자가 입력한 문장에 대해서만 가장 잘 어울리는 문장을 만듭니다.
전체적인 맥락을 모델에게 이해시키고자
소설의 서사 구조 단계를 입력으로 넣어주긴 했는데, 세밀한 부분에서는 여전히 부족함을 느꼈습니다.
그래서 저희는 사용자와 AI가 함께 만들어간 소설 데이터 로그를 다시 입력으로 넣기로 했습니다.
즉, 이전에 작성하고 만들었던 데이터를 다시 입력으로 같이 넣어준다는 뜻입니다.
하지만 이러면 문제가 생길 수 있습니다.
바로 오류의 누적입니다.
이전 데이터에는 AI가 생성한 문장도 들어갑니다.
AI가 생성한 문장을 다시 AI의 입력으로 넣게된다면 오류가 누적될 수 있다는 문제가 있습니다.
그러나 저희 프로그램은 문장 단위로 맥락이 바뀌기 때문에
AI가 생성한 문장을 입력으로 넣지 않는다면 맥락이해에 어려움을 겪을 수 있다 판단했고,
오류의 누적을 감수하고 입력으로 넣기로 결정했습니다.
결과
아래는 각각 BEST CASE와 FAILURE CASE입니다.


'[Deep daiv.] > [Deep daiv.] Deep Learning 입문 프로젝트' 카테고리의 다른 글
| [Deep daiv.] NLP Team Project - 전교 일등의 비밀 (0) | 2025.02.06 |
|---|---|
| [Deep daiv.] 딥러닝 입문 프로젝트 (1) - Do you know? (2) | 2024.11.01 |