
Chapter 1. Introduction
Why do we need database systems? - Drawback of file systems
파일 시스템으로 데이터를 관라한다면 여러가지 문제점들이 발생합니다:
- Data redundancy and inconsistency
- 파일로 데이터를 관리하면, 중복되는 데이터 (Redundant Data) 가 여러 파일에 걸쳐 등장할 수 있습니다. 이에 데이터를 저장하는데 용량이 커지게 되며, 이는 데이터 탐색의 시간을 늘려 성능의 비효율을 발생시킵니다.
- 또한 여러 파일에 걸쳐서 데이터가 겹쳐있기 때문에 데이터 수정 시, 누락으로 인한 불일치 (Inconsistent) 가 발생할 수도 있습니다.
- Difficulty in accssing data
- 기존의 파일 시스템으로 데이터를 저장한다면, 저장된 데이터 파일의 format (예: word, 한글, pdf, etc.)이나 data type (예: fp32, int16, etc.)를 고려해야하는데 이는 overhead가 큽니다.
- Data isolation
- 앞서 말했듯, 데이터가 여러 파일들에 걸쳐 다양한 format으로 저장되어있기 때문에 데이터들을 분리시켜 독립적으로 운영할 필요가 생겼습니다.
- Integrity problems
- 파일 시스템으로 데이터를 저장한다면 각 데이터의 조건들을 달아줄 수 없습니다. 하지만, DB를 통해 데이터를 저장한다면, 데이터 수준에서 안정성을 보장할 수 있습니다.
- 예를 들어, 월급은 반드시 최저시급으로 계산된 월급보다 커야하며, 나이는 0보다는 작을 수 없다. 등 데이터들에 조건을 달아줘서 데이터의 안정성을 보장할 수 있습니다.
- Atomicity problems
- System programming에서도 봤듯, 파일을 통해 저장된 데이터를 처리할 때는 atomicity가 중요합니다. DB를 통해 데이터를 저장하고 수정한다면, race condition을 DB system 수준에서 잘 처리할 수 있습니다.
- atomicity를 보장한다는 것은 all or nothing을 보장한다는 뜻입니다. 아래의 예시처럼, 2개의 수정사항이 있고 이를 수정하면 모든 수정사항이 적용되거나, 아에 적용되지 못하는 경우만 허용합니다. 하나만 변경되는 경우는 허용하지 않는것입니다. 명령을 쪼갤 수 없습니다.
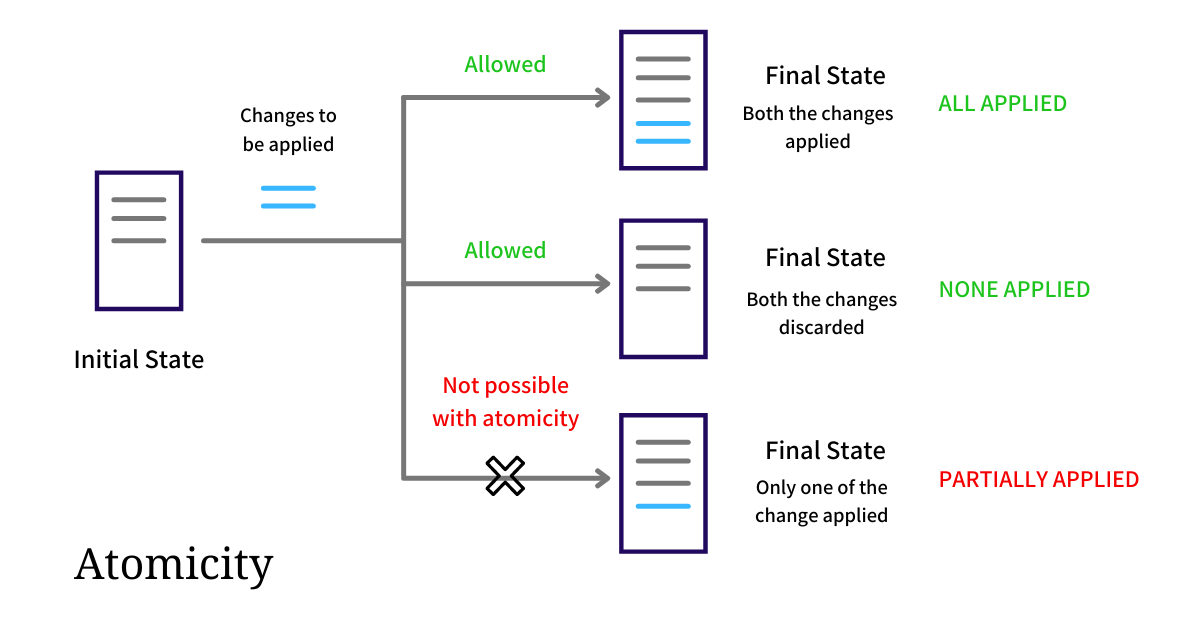
- Concurrent-access anomalies
- 하나의 공통된 데이터를 두 개 이상의 명령이 접근하는 경우 발생할 수 있는 문제를 말합니다. 파일 시스템을 이용하면 이를 통제하기 힘들지만 DB는 시스템 수준에서 이를 통제할 수 있습니다.

- Security problems
- 파일을 이용해서 데이터를 저장하면 해당 데이터의 권한은 파일 수준으로 이루어집니다. 즉, 파일 내부의 데이터 수준에서의 권한 관리는 매우 힘듭니다. 하지만 DB는 이런 권한 관리를 통한 안정성 및 보안을 유지하기 편리합니다.
Data models
데이터나 데이터들끼리의 관계들을 설명하기 위한 개념적인 도구를 data model이라고 부릅니다.이런 모델은 실제 세상에서는 실용적인 측면에서 할 수 없던 것들을 효과적으로 실험하거나 관리하기 위해 사용합니다.
DB에서는 크게 (1) Relation model (Entity-Relation data model), (2) Object-based data model, (3) Semi-structured data model (XML) 들을 사용합니다. 이 중 이번 학기에서 볼 모델은 ER model입니다.
Data abstraction
이런 DB system이 존재하는 이유는 추상화를 제공하기 위함입니다. application을 통해 DB에 접근하는 사람들을 DB의 내부를 모르거나 알 필요가 없는 사람들입니다. 이들에게 내부 동작을 보여주는 것은 불필요하기 때문에, DB system을 통해 추상화를 수행합니다.
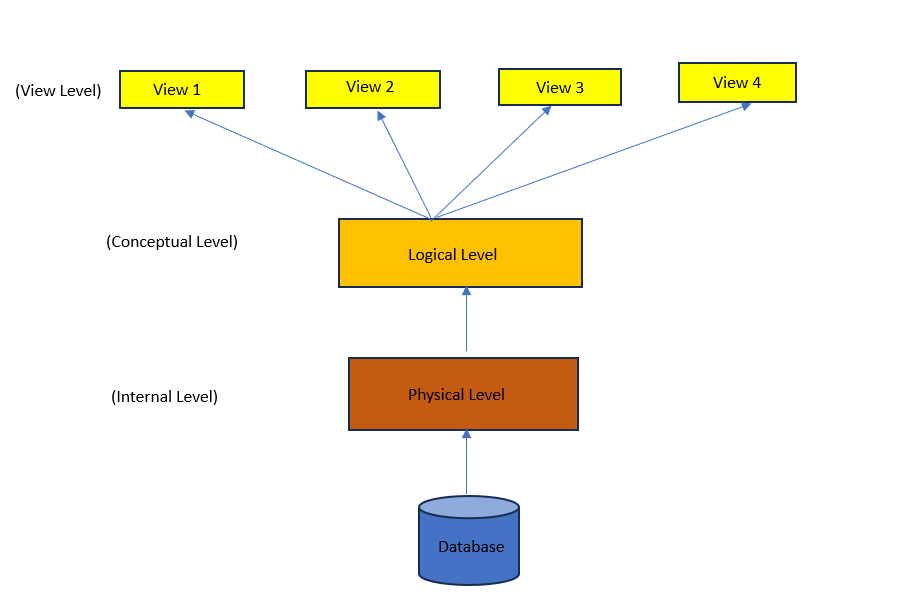
- Physical level
- 데이터들이 실제로 저장되어있는 방법을 말합니다.
- B+ tree, Hash table 등의 index 구조를 통해 저장될 수 있습니다.
- Logical level
- 사람들이 볼 수 있는 데이터 레벨을 말합니다.
- View level
- logical level에서의 디테일들을 숨기고, 보안 매커니즘을 제공합니다.
- 각 view는 권한에 따라 logical level에 있는 데이터를 선택적으로 접근할 수 있음을 나타냅니다.
- 예를 들어, 학생의 view는 교수의 연봉 데이터를 접근할 수 없도록 합니다.
Instances and Schemas
DB의 Schema (스키마)는 데이터가 다른 테이블 또는 다른 데이터 모델과 어떻게 관련될 수 있는지 설명하는 DB의 청사진으로 간주됩니다.
Logical schema (논리 스키마)는 테이블 이름, 필드 이름, 엔티티 관계 및 무결성 제약 조건과 같은 정보를 사용하여 스키마 개체를 명확하게 정의합니다. 이는 DB의 전체적인 논리적 구조입니다.
Physical schema (물리 스키마)는 논리 스키마가 제공하는 정보 외의 기술 정보를 제공합니다. 즉, 디스크 스토리지 내에서 이러한 데이터 구조를 만드는 데 사용되는 구문도 포함되어 있습니다. 즉 DB의 실제 구조를 말합니다.
DB의 Instance (인스턴스)는 특정 시점의 DB 데이터 샘플을 말합니다. 여기에는 스키마가 데이터 값으로 설명하는 모든 속성이 포함되어 있습니다. DB의 인스턴스는 특정 시점의 스냅샷일 뿐이므로 DB 스키마와 달리 시간이 지남에 따라 변경될 가능성이 높습니다. 예를 들어, 대학교 학생 관리 DB의 경우, 매년 logical schema는 달라지지 않지만(DB의 논리적인 구조가 바뀌지는 않지만) Instance는 매년 달라집니다(학생이 달라지기 때문에; 졸업, 입학 등).
Physical data independence
이는 logical schema의 변경 없이도 physical schema를 변경할 수 있는 능력을 말합니다. DB는 한 번 구성이 되고 변동사항 없이 평생 사용할 수도 있지만 대부분은 부분적인 변경이 지속적으로 이루어집니다. 하지만 이때 매번 새로운 DB를 만들 수는 없습니다. 효울성의 측면에서 기존의 DB를 부분적으로 수정하여 사용할 수 있으면 효과적인데 이것을 Data independence라고 부릅니다.
예를 들어, DB system의 성능 개선을 위해 physical schema의 구조를 변경하더라도 application이 접근하는 logical schema는 변경되지 않아야 하는 것입니다.
Chapter 2. Introdiuction to Relational Model
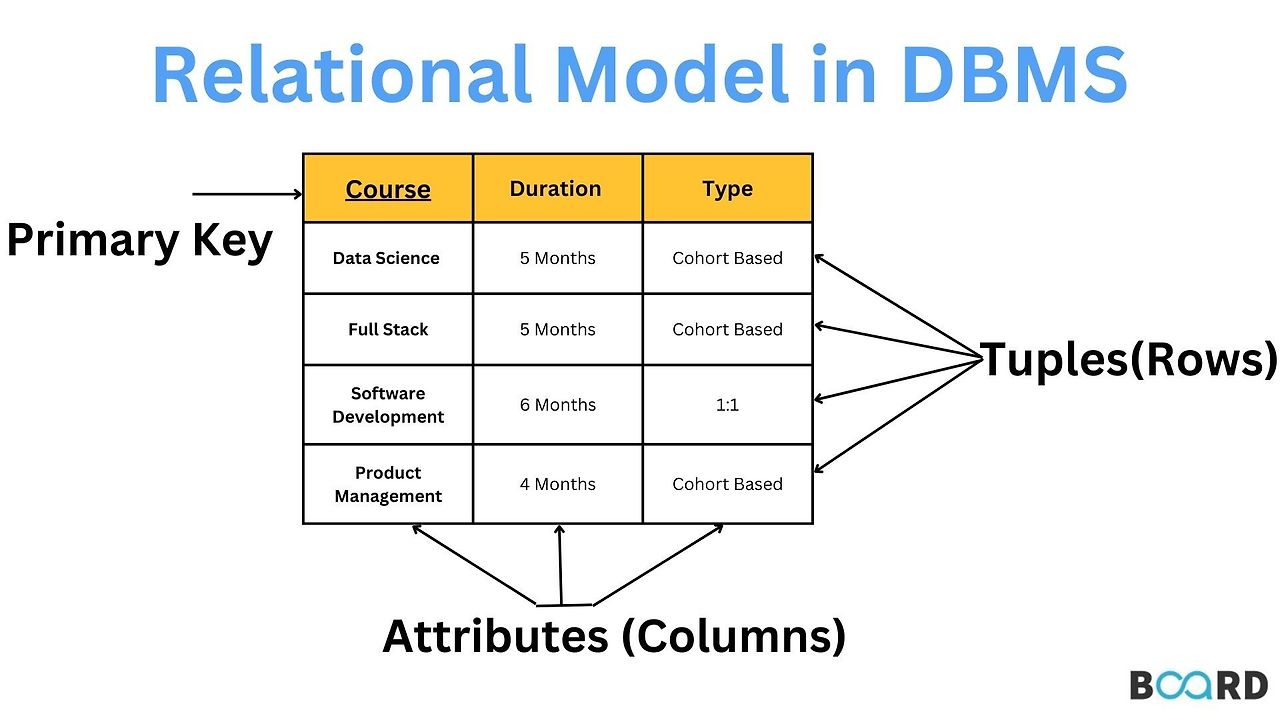
위의 그림같이 하나의 관계를 설명하는 테이블을 table 혹은 relation이라고 부릅니다. 이때 각 행에 해당하는 것을 속성 Attribute라고 부르고, 각 열에 해당하는 것을 튜플 Tuple이라고 부릅니다. 이때 하나의 튜플은 하나의 개체를 말합니다.
Attribute Types
이때 각 속성들이 가질 수 있는 값의 범위를 도메인이라고 합니다. 예를 들어, 대학생을 관리하는 DB가 있을 때 학생들의 학년 속성의 도메인은 1, 2, 3, 4가 되는 것입니다(학년이 1, 2, 3, 4학년 밖에 없으니, 이를 통해 data integrity를 유지할 수 있습니다).
또한 각 속성들은 최대한 쪼개지지 않는 (atomicity)속성들로 정의해야합니다. 그리고 특수값인 null은 모든 도메인의 멤버로 사용될 수 있습니다. 만약 null값을 허용하지 않으려면 추가 조건이 필요합니다.
Relation Schema and Instance
A1, A2, ..., An 을 속성들이라고 할 때, R = (A1, A2, ..., An)은 relation schema를 말합니다. 예를 들어,
instructor = (ID, name, dept_name, salary)
속성 ID, name, dept_name, salary를 갖는 relation instructor를 의미합니다.
이때, relation schema R에서 정의되는 instance r은 r(R)이라고 표현하며, 관계 r에서의 원소 element t는 tuple이라고 불립니다.
Relations are Unordered
기본적으로 각 tuple들은 정렬되어있지 않습니다.
만약 정렬하고 싶다면 추가 작업을 수행해야 합니다.
Database
DB는 여러개의 relation들의 조합을 말합니다.
만약 하나의 relation을 통해 DB를 구성한다면 다음과 같은 문제가 있습니다:
univ(instructor_ID, name, dept_name, salary, student_ID, ...)
이는 (1) 중복되는 정보가 발생합니다. 예를 들어, 10명의 학생이 한 명의 교수 수업을 듣는경우. (2) null값들이 많아집니다. 예를 들어, 학생 개체의 경우 instructor_ID는 null값이 되어 공간 비효율이 늘어납니다. 이는 탐색 시간을 늘릴 수 있습니다.
Keys
key는 relation R의 Attribute들의 부분집합으로, 속성들의 부분집합입니다.
만약 그 key가 relation R의 tuple들 중 unique한 튜플을 지정한다면 그 key를 superkey라고 부릅니다.
superkey들 중에 가장 작은 최소 부분집합을 candidate key라고 합니다.
이런 candidate key들 중 임의의 하나, 사용자가 선택한 candidate key를 primary key라고 부릅니다.
또한 다른 relation에도 존재하는 key를 foreign key라고 부릅니다.
'[학교 수업] > [학교 수업] Database' 카테고리의 다른 글
| [Database] Database Design Using The E-R Model | Week 5 (0) | 2025.04.03 |
|---|---|
| [Database] Intermediate SQL | Week 4 (0) | 2025.03.25 |
| [Database] Intermediate SQL | Week 3 (0) | 2025.03.21 |
| [Database] Basic SQL | Week 3 (0) | 2025.03.19 |
| [Database] Relational Model & Basic SQL | Week 2 (0) | 2025.03.11 |