
Combine Schemas?
아래와 같은 table이 있을때:
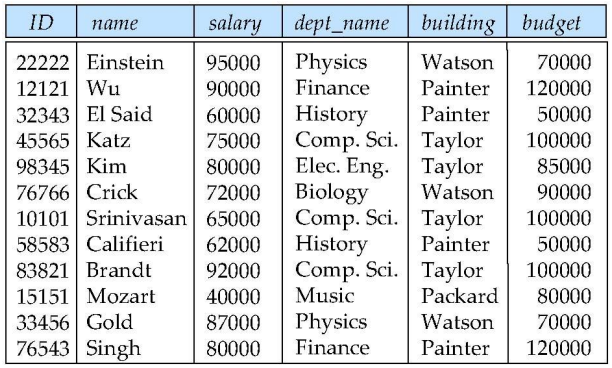
instructor와 department를 묶을 수 있을까? 왜냐하면 dept_name에 따라 building과 budget이 결정되기 때문에 데이터의 중복이 발생하고, 이를 분리할 수 있을까? 입니다.
A combined Schema Without Repetition
section(course_id, sec_id, semester, year, building, room_number) 라는 테이블이 있는 경우 이를 잘 분리해서 sec_class(sec_id, building, room_number)와 section(course_id, sec_id, semester, year)로 분리한다면 반복 없이 모든 데이터를 나타낼 수 있을 것입니다.
What About Smaller Schemas?
inst_dept와 같은 DB를 구축한다고 했을때, 그러면 왜 작은 테이블들로 이들을 나눠야할까요? 이는 functional dependency를 더 잘 확인하기 위해서 입니다. 이때 functional dependency란 특정 attr.이 다른 attr.을 결정하는 관계를 말합니다. 앞선 예에서는 dept_name이 building과 budget을 결정했기 때문에 이들 attr.끼리는 functional dependency가 있으며, 이들을 하나의 테이블로 묶으면 이가 더 잘 보일 것입니다.
하지만 모든 분해 (decomposition)이 좋은 것은 아닙니다. 다음과 같은 예가 있는 경우:
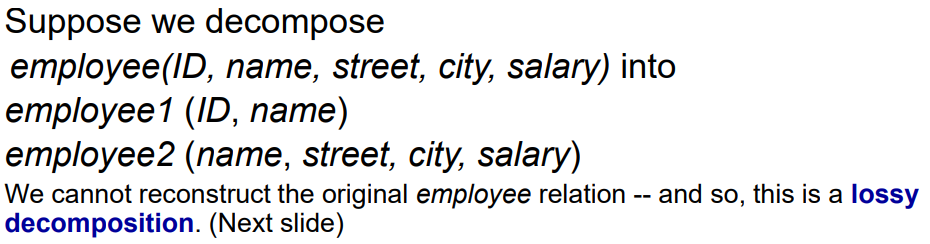
이를 decomposition한 후, 다시 natural join을 하면 왜 lossy decomposition인지 알 수 있습니다:
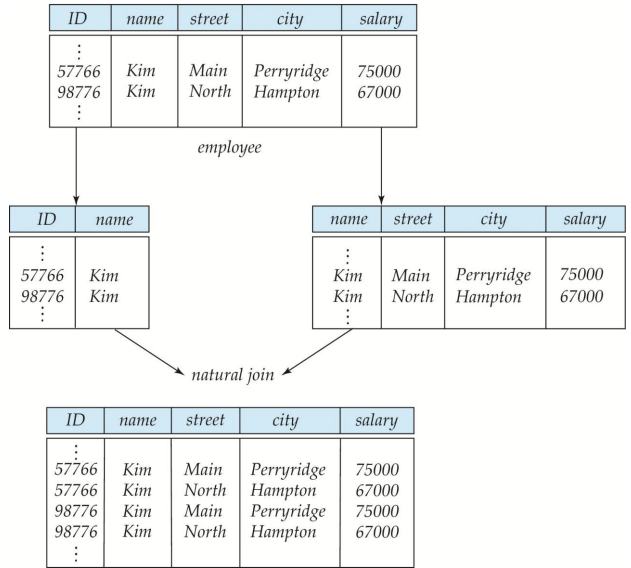
결과적으로 원본 테이블과 형태가 달라짐을 알 수 있습니다. *name은 functional dependency가 없는 attr.이기 때문입니다.
Example of Lossless-Join Decomposition
반대로 lossless란 decomposition후 natural join을 해도 원본과 다르지 않는 경우를 말합니다:

First Normal Form
우선 정규화에 앞서 정규화 형태를 맞춰야합니다. 첫번째 형태는 해당 속성의 값들이 더 이상 나눠지지 않아야한다는 것입니다. 이에 해당하지 않는 예는 다음과 같습니다.
- 원자값(Atomic Value)
- 한 컬럼은 오직 더 이상 분해할 수 없는 하나의 값만을 저장해야 합니다.
- 예: “여러 개의 전화번호를 한 칸에 콤마로 구분하여 저장” → 1NF 위배 가능성이 큼.
- 중복되는 속성 및 반복 속성 제거
- “전화번호1, 전화번호2, 전화번호3…”처럼 반복 그룹을 컬럼으로 구성하는 것은 1NF를 위배할 수 있습니다.
- 복합 속성(Composite Attribute)은 보통 분리
- 예: 주소(시, 구, 도로명, 상세주소 등)는 각각의 원자값으로 분리해서 테이블 컬럼으로 설계하는 것이 권장됩니다.
Goal - Devise a Theory for the Following
임의의 테이블 R을 "good form"을으로 변환하는 것이 목표입니다. 이는 functional dependencies와 multivalued dependencies를 기반으로 합니다. 또한 lossless-join decomposition으로 해야합니다.
Functional Dependencies

a가 b에 영향을 준다는 것은 같은 a값을 같는 튜플들은 반드시 b값을 가져야한다는 것을 말합니다.
예를 들어 다음과 같은 상황이 주어졌을 때:

a→b는 성립하지 않습니다. 1이라는 값을 같는 두 튜플들에 대해서 b값이 4와 5로 다르기 때문입니다. 하지만 b→a는 성립할 수도 있습니다. 조건에 위배되지는 않기 때문입니다.
즉 table R의 attr.들에 대해서 K→R이 성립한다면 K는 super key입니다. 그리고 K가 super key라면 K→R가 성립합니다 (if and only if). *이때 중복행은 고려하지 않습니다.
하지만 이때 K가 candidate key라는 것은 아닌데, candidate key이려면 K의 부분 집합인 attr.을 빼도 여전히 K→R가 유지되지 않아야합니다. 그래서 K의 요소(들)이 최소의 attr.들이라는 뜻이기 때문입니다.
이때 functional dependency를 확장하는 여러 공식(?)들이 존재합니다.주어진 functional dependency를 F라고 했을때, 이렇게 확장된 functional dependency들을 closure of functional dependency, F+라고 합니다.
그리고 아래는 그 공식들 입니다:
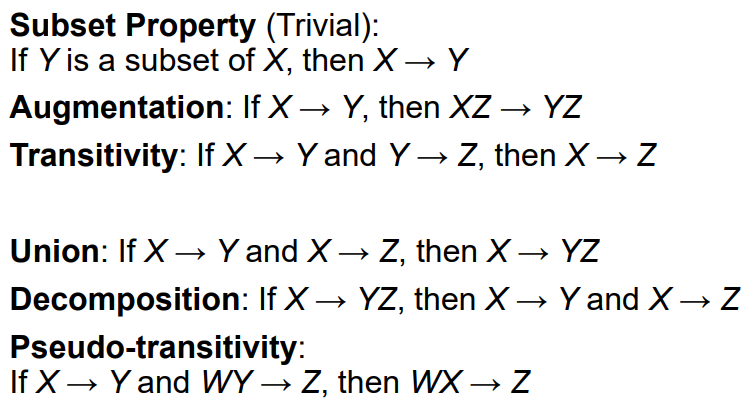
'[학교 수업] > [학교 수업] Database' 카테고리의 다른 글
| [Database] Database Design Using The E-R Model | Week 5 (0) | 2025.04.03 |
|---|---|
| [Database] Intermediate SQL | Week 4 (0) | 2025.03.25 |
| [Database] Intermediate SQL | Week 3 (0) | 2025.03.21 |
| [Database] Basic SQL | Week 3 (0) | 2025.03.19 |
| [Database] Relational Model & Basic SQL | Week 2 (0) | 2025.03.11 |
Combine Schemas?
아래와 같은 table이 있을때:
instructor와 department를 묶을 수 있을까? 왜냐하면 dept_name에 따라 building과 budget이 결정되기 때문에 데이터의 중복이 발생하고, 이를 분리할 수 있을까? 입니다.
A combined Schema Without Repetition
section(course_id, sec_id, semester, year, building, room_number) 라는 테이블이 있는 경우 이를 잘 분리해서 sec_class(sec_id, building, room_number)와 section(course_id, sec_id, semester, year)로 분리한다면 반복 없이 모든 데이터를 나타낼 수 있을 것입니다.
What About Smaller Schemas?
inst_dept와 같은 DB를 구축한다고 했을때, 그러면 왜 작은 테이블들로 이들을 나눠야할까요? 이는 functional dependency를 더 잘 확인하기 위해서 입니다. 이때 functional dependency란 특정 attr.이 다른 attr.을 결정하는 관계를 말합니다. 앞선 예에서는 dept_name이 building과 budget을 결정했기 때문에 이들 attr.끼리는 functional dependency가 있으며, 이들을 하나의 테이블로 묶으면 이가 더 잘 보일 것입니다.
하지만 모든 분해 (decomposition)이 좋은 것은 아닙니다. 다음과 같은 예가 있는 경우:
이를 decomposition한 후, 다시 natural join을 하면 왜 lossy decomposition인지 알 수 있습니다:
결과적으로 원본 테이블과 형태가 달라짐을 알 수 있습니다. *name은 functional dependency가 없는 attr.이기 때문입니다.
Example of Lossless-Join Decomposition
반대로 lossless란 decomposition후 natural join을 해도 원본과 다르지 않는 경우를 말합니다:
First Normal Form
우선 정규화에 앞서 정규화 형태를 맞춰야합니다. 첫번째 형태는 해당 속성의 값들이 더 이상 나눠지지 않아야한다는 것입니다. 이에 해당하지 않는 예는 다음과 같습니다.
- 원자값(Atomic Value)
- 한 컬럼은 오직 더 이상 분해할 수 없는 하나의 값만을 저장해야 합니다.
- 예: “여러 개의 전화번호를 한 칸에 콤마로 구분하여 저장” → 1NF 위배 가능성이 큼.
- 중복되는 속성 및 반복 속성 제거
- “전화번호1, 전화번호2, 전화번호3…”처럼 반복 그룹을 컬럼으로 구성하는 것은 1NF를 위배할 수 있습니다.
- 복합 속성(Composite Attribute)은 보통 분리
- 예: 주소(시, 구, 도로명, 상세주소 등)는 각각의 원자값으로 분리해서 테이블 컬럼으로 설계하는 것이 권장됩니다.
Goal - Devise a Theory for the Following
임의의 테이블 R을 "good form"을으로 변환하는 것이 목표입니다. 이는 functional dependencies와 multivalued dependencies를 기반으로 합니다. 또한 lossless-join decomposition으로 해야합니다.
Functional Dependencies
a가 b에 영향을 준다는 것은 같은 a값을 같는 튜플들은 반드시 b값을 가져야한다는 것을 말합니다.
예를 들어 다음과 같은 상황이 주어졌을 때:
a→b는 성립하지 않습니다. 1이라는 값을 같는 두 튜플들에 대해서 b값이 4와 5로 다르기 때문입니다. 하지만 b→a는 성립할 수도 있습니다. 조건에 위배되지는 않기 때문입니다.
즉 table R의 attr.들에 대해서 K→R이 성립한다면 K는 super key입니다. 그리고 K가 super key라면 K→R가 성립합니다 (if and only if). *이때 중복행은 고려하지 않습니다.
하지만 이때 K가 candidate key라는 것은 아닌데, candidate key이려면 K의 부분 집합인 attr.을 빼도 여전히 K→R가 유지되지 않아야합니다. 그래서 K의 요소(들)이 최소의 attr.들이라는 뜻이기 때문입니다.
이때 functional dependency를 확장하는 여러 공식(?)들이 존재합니다.주어진 functional dependency를 F라고 했을때, 이렇게 확장된 functional dependency들을 closure of functional dependency, F+라고 합니다.
그리고 아래는 그 공식들 입니다:
'[학교 수업] > [학교 수업] Database' 카테고리의 다른 글
| [Database] Database Design Using The E-R Model | Week 5 (0) | 2025.04.03 |
|---|---|
| [Database] Intermediate SQL | Week 4 (0) | 2025.03.25 |
| [Database] Intermediate SQL | Week 3 (0) | 2025.03.21 |
| [Database] Basic SQL | Week 3 (0) | 2025.03.19 |
| [Database] Relational Model & Basic SQL | Week 2 (0) | 2025.03.11 |