
https://ieeexplore.ieee.org/abstract/document/8269806
Multimodal Machine Learning: A Survey and Taxonomy
Our experience of the world is multimodal - we see objects, hear sounds, feel texture, smell odors, and taste flavors. Modality refers to the way in which something happens or is experienced and a research problem is characterized as multimodal when it inc
ieeexplore.ieee.org
1. Introduction
인간은 오감(다양한 모달리티)을 통해 세상을 경험합니다. 일반적으로 모달리티란 어떤 일이 발생하거나 경험되는 방식을 의미합니다. 여러 모달리티가 포함된 연구 문제나 데이터셋을 멀티모달(multimodal)이라고 불립니다. 해당 논문에서는 모든 모달리티 대신 주로 다음 세 가지의 모달리티에 집중합니다:
- 자연어: 말로 하거나 글로 쓸 수 있는
- 시각 신호: 이미지나 비디오
- 음성 신호: 소리 및 억양, 감정 표현 등의 정보
AI가 세상을 이해하기 위해서는 이런 멀티모달 메시지들을 해석하고 추론할 수 있어야 합니다. 멀티모달 머신러닝은 여러 모달리티의 정보를 처리하고 연결하는 모델을 구축하는 것을 목표로 합니다. 멀티모달 머신러닝 분야는 서로 다른 데이터들을 이용해 모달리티 간의 대응 (correspondence)을 포착하고, 자연 현상에 대한 심층적인 이해를 얻을 수 있다는 특징이 있습니다.
해당 논문에서는 다음 5가지의 핵심 기술 과제에 대해 다룹니다:
- Representation
- 여러 모달리티의 보완성과 중복성을 활용할 수 있도록 멀티모달 데이터를 표현하고 요약하는 방법을 학습
- 멀티모달 데이터간의 이질성은 이를 표현하기 어렵게 만듭니다.
- 예를 들어 언어는 symbolic하며, 오디오나 비전은 signal이라서 같이 표현하기 힘들다.
- Translation
- 한 모달리티를 다른 모달리티로 매핑하는 방법
- 데이터들끼리는 서로 이질적일 뿐 아니라, 모달리티 간의 관계는 종종 closed-end가 아니며 주관적입니다.
- 예를 들어 이미지를 설명하는 방법은 여러 가지가 있을 수 있으며, 하나의 완벽한 번역이 존재하지 않다.
- Alignment
- 서로 다른 모달리티의 하위 요소들 간 관계를 찾아내는 것
- 이 과제를 해결하기 위해서는 서로 다른 모달리티 간 유사성을 측정하고, 장기 의존성(long-range dependencies)와 모호성(ambiguity)에 대처해야합니다.
- 예를 들어 요리 레시피(언어)와 요리 동영상(비디오)의 매칭
- Fusion
- 여러 모달리티를 결합해서 예측 수행
- 서로 다른 모달리티에서 오는 정보는 예측 능력과 노이즈 특성이 다를 수 있으며, 일부 모달리티에서는 데이터가 누락될 수도 있습니다.
- Co-learning
- 이는 모달리티나 모달리티의 표현, 해당 예측 모델간의 지식 전이를 다룹니다.
- 한 모달리티에서 배운 지식이 다른 모달리티 학습을 도울 수 있습니다.
- 이 과제는 특히 한 모달리티의 자원이 제한적(레이블 부족 문제)일때, 이를 해결하는 데 유용할 수 있습니다.
2. Applications: A historical Perspective
멀티모달 머신러닝은 오디오-비주얼 음성 인식에서 이미지 캡셔닝에 이르기까지 광범위한 응용을 가능하게 했습니다. 해당 섹션에서는 오디오-비주얼 음성 인식에서 최근 언어와 비전 응용 분야에 대한 관심이 새로워지기까지, 멀티모달 응용의 간략한 역사를 소개합니다.
(1) AVSR (audio-visual speech recognition)
멀티모달 연구의 가장 초기 사례 중 하나는 오디오-비주얼 음성 인식(AVSR)입니다. 이는 McGurk효과; 말소리 인식 중 청각과 시각의 상호작용에 의해 동기부여된 태스크입니다.https://ko.wikipedia.org/wiki/%EB%A7%A5%EA%B1%B0%ED%81%AC_%ED%9A%A8%EA%B3%BC
맥거크 효과 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 맥거크 효과(McGurk effect)는 음성 인식에 있어서 청각정보가 시각정보의 간섭으로 변화된 후 인지되는 현상을 말한다. 1976년 해리 맥거크(Harry McGurk)가 과학 학술
ko.wikipedia.org
예를 들어 사람이 /ga-ga/라고 말하는 입 모양을 보면서 /ba-ba/ 라는 소리를 들어면, 사람들은 제3의 소리인 /da-da/를 인식했습니다. 이 결과는 많은 음성 연구자들이 자신들의 접근 방식에 시각 정보를 추가하도록 동기부여했습니다. 이는 hidden Markov models (HMM)을 이용해 수행되었으며, 초기 AVSR 모델 중 다수는 HMM의 확장이었습니다.
https://untitledtblog.tistory.com/97
[머신 러닝] - 은닉 마르코프 모델 (Hidden Markov Model, HMM)
Markov model은 어떠한 날씨, 주식가격 등과 같은 어떠한 현상의 변화를 확률 모델로 표현한 것이다. Hidden Markov model (HMM)은 이러한 Markov model에 은닉된 state와 직접적으로 확인 가능한 observation을 추
untitledtblog.tistory.com
AVSR의 원래 목표는 모든 상황에서 음성 인식 성능을 향상시키는 것이었지만, 실험 결과에 따르면 시각 정보의 주요 이점은 음성 신호에 노이즈가 많은 상황에서만 나타났습니다. 즉, 모달리티 간 상호작용은 보완적(complementary) 라기 보다는 보조적(supplementary)이었습니다. 같은 정보가 두 모달리티에 모두 포착되어 멀티모달 모델의 견고성(robustness)은 향상되었지만, 노이즈가 없는 상황에서는 음성 인식 성능이 향상되지는 않았습니다.
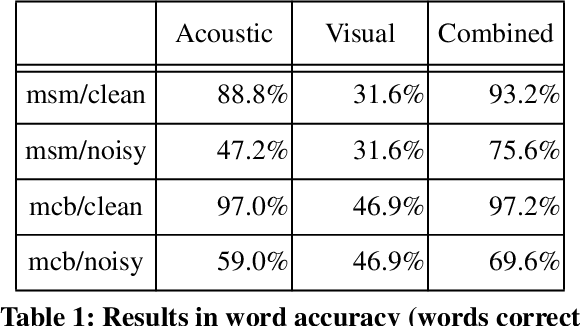
(2) Multimedia content indexing and retrieval
두 번째 응용 범주는 멀티미디어 콘텐츠 인덱싱 및 검색 분야입니다. 개인용 컴퓨터와 인터넷의 발전으로 디지털 멀티미디어 콘텐츠의 양이 급격이 증가함으로써 초기에는 키워드 기반 검색 방법이 주류였지만, 이후 시각적 및 멀티모달 콘텐츠를 "직접" 검색하려는 시도가 등장하면서 새로운 연구 문제가 생겼습니다.
이로 인해 자동 장면 경계 탐지(automatic shot-boundary detection)나 비디오 요약(video summarization)같은 멀티미디어 콘텐츠 분석 주제가 탄생했습니다. *비디오에서 장면이 변경되는 부분을 탐지하는 태스크

이러한 연구들은 TrecVid initiative에 의해 지원되었으며, 이는 2011년에 시작된 멀티미디어 이벤트 감지(MED) 과제를 포함해 많은 고품질 데이터셋을 제공했습니다.
(3) multimodal interaction
세 번째 응용 분야는 2000년대 초반 등장한 멀티모달 상호작용 분야입니다. 이 분야는 사회적 상호작용 중 인간의 멀티모달 행동을 이해하는 것을 목표로 합니다. 대표적인 데이터셋으로는 다음이 있습니다:
- AMI Meeting Corpus: 100시간 이상의 회의 녹화 영상과 완전한 전사 및 주석이 포함
- SEMAINE Corpus: 화자와 청자의 대인 관계 역학을 연구할 수 있는 데이터셋
이는 오디오-비주얼 감정 인식 대회(AVEC)의 기반이 되었습니다. 감정 인식과 감성 컴퓨팅(affective computing) 분야는 자동 얼굴 검출, 얼굴 랜드마크 검출, 얼굴 표정 인식 기술의 발전으로 2010년대 초 급성장했습니다. D'Mello의 연구에 따르면 대부분의 최신 멀티모달 감성 인식 연구는 둘 이상의 모달리티를 사용할 때 성능이 향상되지만, 자연 발생 감정(naturally-occurring emotions)을 인식할 때는 그 향상이 줄어드는 것으로 나타났습니다.
(4) media description
가장 최근에는 언어와 비전을 강조하는 새로운 멀티모달 응용 범주가 등장했습니다. 이는 미디어 설명입니다.
대표적인 응용은 이미지 캡셔닝(image captioning)으로, 입력 이미지를 설명하는 텍스트를 생성하는 작업입니다. 이는 시각 장애인들이 일상 생활을 수행하는 데 도움을 줄 수 있습니다.
최근에는 반대로 텍스트로부터 미디어를 생성하는(media generation from text) 작업에서도 많은 발전이 있었습니다. 여기에서의 주요 도전 과제는 평가(evaluation)입니다. 예측된 설명과 미디어의 품질을 어떻게 평가할 것인가? 시각적 질문-응답(Visual Question Answering, VQA) 작업이 이 평가 문제를 일부 해결하기 위해 제안되었습니다.
VQA: Visual Question Answering - Computer Vision & NLP 분야에 대해
최근에 VQA 논문에 대해 찾아보고 있었는데, VQA 분야가 발전된 흐름이나 최신 트렌드를 정리해놓은 글이 생각보다 적었다. 이것저것 조사하다 보니, 기록도 할겸 VQA 분야가 어떤 연구 트렌드로
kookie12.tistory.com
하지만 현실 세계에 이러한 응용을 가져오기 위해서는, 멀티모달 머신러닝이 직면한 여러 기술적 도전 과제들을 해결해야합니다. 그리고 가장 중요한 과제 중 하나인 multimodal representation을 다음 섹선에서 중점적으로 다룰 것입니다.
3. Multimodal Representation
데이터를 컴퓨팅 모델이 사용할 수 있는 형식으로 표현하는 것은 머신러닝에서 항상 도전 과제였습니다. 멀티모달 표현(multimodal representation)은 모달리티 간의 표현들의 정보를 활용하여 데이터를 표현하는 것입니다. 이렇게 여러 모달리티를 표현하는 데는 많은 어려움이 따릅니다:
- 이질적인 source로부터 데이터를 어떻게 결합할지,
- 서로 다른 수준의 노이즈를 어떻게 처리할지,
- 누락된 데이터를 어떻게 다룰지.
데이터를 의미 있는 방식으로 표현하는 능력은 멀티모달 문제에 매우 중요하며, 모든 모델의 기반(backbone)을 이룹니다.
좋은 표현은 머신러닝 모델의 성능에 매우 중요합니다. 이는 최근 음성 인식과 시각적 객체 분류 시스템의 성능이 급격히 향상된 사례에서 잘 드러납니다. Bengio et al. 은 좋은 표현을 위한 여러 속성들을 식별했습니다:
- 부드러움(smoothness) *비슷한 입력 데이터는 비슷한 표현값을 가져야한다는 뜻. 데이터가 조금 변해도 표현 값이 크게 변하지 않아야 일반화가 잘 됩니다.
- 시간적 및 공간적 일관성 (Temporal and Spatial Coherence) *시간이나 공간적으로 가까운 데이터는 비슷한 의미를 갖는다는 뜻. 모델은 이런 일관성을 잘 포착함으로써 변화난 움직임을 자연스럽게 이해할 수 있습니다.
- 희소성(Sparsity) *사실 이게 제일 이해가 안됐었다. 그런데 이걸 정규화라고 생각하니 좀 이해가됐다. 표현 벡터에서 많은 값이 0이고, 소수의 값만 의미 있는 값을 갖는다는 것입니다. 이를 통해 해석이 쉬워지며(어떤 특성인지 알 수 있다), 노이즈에 강해질 수 있습니다. ex. sparse CNN
- 자연스러운 군집화(Natural Clustering) *비슷한 개념들은 표현 공간에서 서로 가깝게 모여야합니다. 이는 word2vec에서 비슷한 단어들끼리는 벡터 공간 상에 비슷한 위치에 있는 현상과 유사하게 해석할 수 있습니다.
*참고로 자연스러운 군집화를 목표로 한다면 Triplet loss를 사용할 수도 있습니다.
Triplet Loss, Triplet Mining 정리
Triplet Loss 개요 Triplet Loss는 앞에 설명한 Contrastive loss 와 같이 Deep learning based Face recognition에서 두가지 기술 발전방향중 Loss function에의한 발전에 속하고 그 중에서 verification loss function에 해당. 간
mic97.tistory.com
또한 Srivastava and Salakhutdinov는 멀티모달 표현에 대해 추가적으로 바람직한 속성을 제시했습니다:
- 표현 공간 내에서의 유사성은 해당 개념 간 유사성을 반영해야 하며,
- 일부 모달리티가 없더라도 쉽게 표현을 얻을 수 있어야 하며, *이는 어떻게 보면 당연한게 다양한 모달리티들의 상호작용을 학습하는 것이 목표이기 때문에 좋은 멀티모달 표현은 이를 달성해야합니다.
- 관찰된 모달리티를 기반으로 누락된 모달리티를 채워 넣을 수 있어야 합니다. *위 내용과 비슷함
단일 모달리티(unimodal) 표현 개발은 광범위하게 연구되었습니다. 예를 들어 2000년대 초에는 이미지를 표현하는 가장 인기 있는 방법 중 하나가 핸드메이드 특징(예: SIFT)을 이용한 시각적 단어 집합(bag of visual words) 방식이었습니다. 하지만 현재는 대부분의 이미지는 합성곱 신경망(CNN) 같은 신경망 구조를 통해 데이터로부터 학습된 표현을 사용합니다.
비슷하게 오디오 분야에서는 MFCC 같은 음향 특징이 (1) 음성 인식에서는 데이터 기반 DNN(Deep Neural Network), (2) 준언어 분석(para-linguistic analysis)에서는 순환 신경망(RNN)으로 대체되었습니다.
자연어 처리(NLP) 분야에서는, 초기에는 문서 내 단어 등장 횟수를 세는 방식(bag of words)이 주류였지만, 지금은 단어 임베딩(word embeddings) 기술이 문맥을 활용하여 데이터 기반으로 단어를 표현합니다.
단일 모달리티 표현에 대한 연구는 방대하지만, 최근까지 대부분의 멀티모달 표현은 단순히 단일 모달리티 표현을 연결(concatenation)하는 방식이었습니다. 하지만 이것은 빠르게 변화하고 있습니다. 해당 논문에서 제시하는 멀티모달 표현 분류는 두 가지입니다:
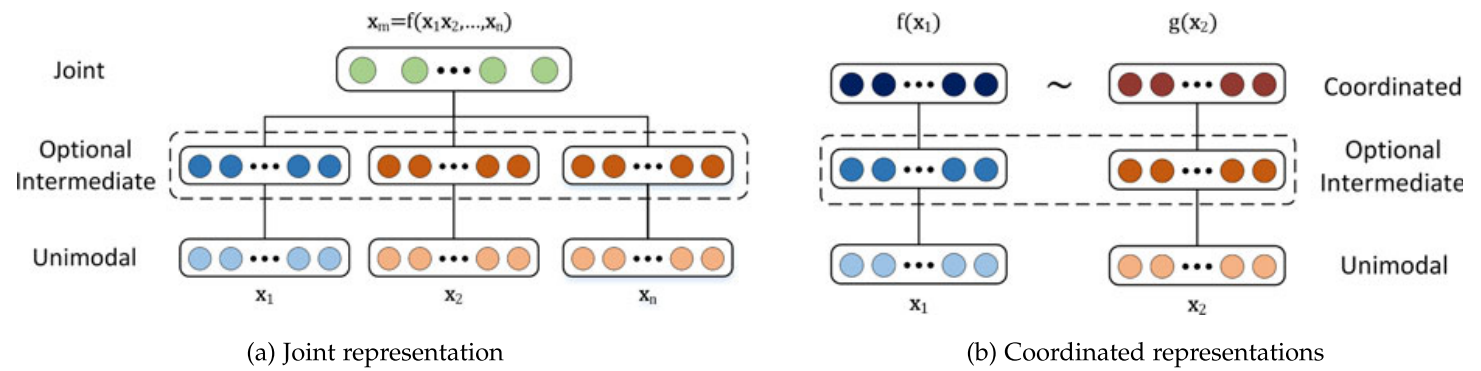
- Joint Representations (공동 표현):
- 서로 다른 단일 모달리티 신호를 하나의 표현 공간으로 결합합니다.
- Coordinated Representations (조정 표현):
- 단일 모달리티 신호를 각각 따로 처리하되, 특정 유사성 제약을 적용하여 '조정된 공간(coordinated space)'에 맵핑합니다.
수학적으로 표현하면 다음과 같습니다.
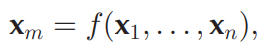
공동 표현의 경우, xm은 단일 모달리티 표현 x1, ..., xn을 기반으로 함수 f(예: DNN, RNN, etc.)를 통해 계산됩니다.
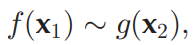
조정 표현의 경우 각 모달리티에 대해 해당 모달리티를 조정된 멀티모달 공간으로 투사(projection)하는 별도의 함수 f와 g가 존재합니다. 모달리티 별 투사는 독립적이지만, 결과 공간은 조정되어 있습니다. 조정의 예로는 다음이 있습니다:
- 코사인 거리 최소화(cosine distance minimization)
- 상관 관계 최대화(correlation maximization)
- 결과 공간 간의 부분 순서(partial order) 강제
*여기서 결과 공간 간의 부분 순서 강제 부분이 이해가 잘 안됐다. 그래서 찾아보니, 부분 순서는 모든 쌍이 비교 가능한 건 아니지만 비교 가능한 쌍끼리는 일정한 '우선 순위'가 존재하는 구조를 말한답니다. 이는 RLHF의 강화학습으로 이해하면 편한데, 인간의 선호도에 따라 모든 데이터들을 비교할 수는 없기 때문에 강화학습 모델을 학습할 때 비선호 출력과 선호 출력간의 비교를 통해서 학습을 했었음. 위에서 말한 triplet loss도 비슷한 의미입니다.
*대표적인 모델로는 CLIP이 있는데, 이미지는 ViT(Transformer), 텍스트는 Transformer로 각각 따로 인코딩한 후, 두 표현 벡터가 비슷한 의미를 공유하도록 대조 학습(Contrastive Learning)을 사용했습니다.
Contrastive Learning Loss: NT-Xent & InfoNCE
Both are commonly used loss functions in self-supervised learning tasks, where the goal is to learn meaningful representations by maximizing the similarity between positive pairs (augmented views of the same instance) while minimizing the similarity with n
medium.com
3.1 공동 표현 (Joint Representations)
먼저 단일 모달리티 표현을 함께 투사하여 멀티모달 공간으로 만드는 공동 표현부터 살펴보겠습니다. 공동 표현은 주로 학습 단계와 추론 단계에서 모두 멀티모달 데이터가 존재하는 경우에 사용됩니다. 공동 표현의 가장 간단한 예는 개별 모달리티 특징을 단순 연결(concatenation)하는 것으로 early fusion이라고도 불립니다. 이 절에서는 신경망, graphic model, 순환 신경망을 이용해 공동 표현을 만드는 방법들에 대해 논의합니다.
3.1.1 신경망 (Nueral Networks)
신경망은 단일 모달리티 데이터 표현에서는 매우 인기 있는 방법이며, 시각, 음향, 텍스트 데이터를 표현하는 데 사용됩니다. 그리고 멀티모달 분야에서도 점점 더 많이 사용되고 있습니다. 일반적으로 신경망은 내적과 비선형 활성화 함수로 구성된 연속적인 블록으로 이루어집니다. 깊은 신경망은 여러 층을 가지며, 각 층은 점점 더 추상적인 수준에서 데이터를 표현한다고 가정합니다. 따라서 최종 층 도는 마지막 층에서 두 번째 층을 데이터 표현을 사용하는 것이 일반적입니다.
멀티모달 표현을 구성할 때는, 각 모달리티가 개별 신경망 층을 거친 후, 공동 공간으로 투사(projection)하는 은닉층(hidden layer)로 이어집니다. 그 이후, 공동 표현은 추가적인 은닉층을 통과하거나 직접 예측에 사용될 수 있습니다.
신경망은 많은 수의 라벨링된 데이터가 필요하기 때문에, (1) 비지도 데이터(예: 오토인코더)를 사용하거나, (2) 다른 관련 도메인의 지도 데이터를 사용하여 사전학습 하는 경우가 많습니다. *Autoencoder란 표현 학습 작업에 신경망을 활용하도록 하는 비지도 학습 방법입니다. 이는 입력이 들어왔을 때, 해당 입력 데이터를 최대한 압축시킨 후, 데이터의 특징을 추출하여 다시 본래의 입력 형태로 복원시키는 신경망입니다. 이가 멀티모달에서 사용된다면 다음과 같은 방식으로 사용됩니다:
(이미지, 텍스트, 오디오)
↓ (각 모달리티별 인코더)
[ 통합된 잠재 공간 z ] ← ★ 여기가 공동 표현
↓ (디코더)
(이미지', 텍스트', 오디오') → 재구성[딥러닝] AutoEncoder 개념 및 종류
Autoencoder(오토인코더)란 representation learning 작업에 신경망을 활용하도록 하는 비지도 학습 방법 입력이 들어왔을 때, 해당 입력 데이터를 최대한 압축시킨 후 , 데이터의 특징을 추출하여 다시 본
velog.io
신경망 기반 공동 표현의 주요 장점은, 라벨이 충분하지 않은 경우 비지도 데이터로 사전 학습이 가능하다는 것입니다(autoencoding). 또한 사전학습된 표현은 특정 작업에 대해 fine-tuning할 수도 있습니다. 하지만 신경망은 missing data를 잘 다루지 못하는 경향이 있으며, 학습이 어렵다는 문제가 있습니다. 하지만 이는 (1) 개선된 정규화, (2) 배치 정규화, (3) 적응적 그래디언트 알고리즘을 통해 해결할 수 있습니다.
3.1.2 확률적 그래픽 모델 (Probabilistic Graphical Models)
확률적 그래픽 모델은 잠재 랜덤 변수를 통해 표현을 구성하는 데 사용할 수 있습니다. 여기서는 단일 및 멀티모달 데이터를 그래픽 모델로 표현하는 방법을 설명합니다. 대표적으로는 딥 볼츠만 머신(Deep Boltzman Machine, DBM)이 있으며, 이는 제한 볼츠만 머신(RBM)을 여러 층 쌓아 구성합니다.
https://angeloyeo.github.io/2020/10/02/RBM.html
Restricted Boltzmann Machine - 공돌이의 수학정리노트 (Angelo's Math Notes)
angeloyeo.github.io
신경망과 유사하게, DBM의 각 층은 데이터의 더 높은 수준의 추상 표현을 학습합니다. DBM의 장점은 지도 학습 없이 학습할 수 있다는 것입니다. 멀티모달 DBM의 주요 장점은 (1) 생성적(generative) 특성 덕분에 결손 데이터가 있어도 자연스럽게 다룰 수 있다는 것입니다. 또한 (2) 하나의 모달리티만으로도 다른 모달리티를 생성할 수도 있습니다. 하지만 DBM은 학습이 매우 어렵고, 고비용이 들며. 근사 변분 학습(approximate variational methods)을 사용해야한다는 단점이 있습니다.
Variational Inference & Free Energy
## 책 소개 **《변분추론과 Free Energy》**는 베이즈 추론에서 자주 등장하는 **사후분포 추정** 문제를 보다 간단한 **근사(Variational) 분포**로 해…
wikidocs.net
3.1.3 순차적 표현 (Sequential Representation)
지금까지는 고정 길이 데이터를 다루는 모델을 살펴보았지만, 실제로는 문장, 비디오, 오디오 스트림처럼 가변 길이 시퀀스를 표현해야 할 필요가 있습니다. 순환 신경망(RNN) 및 그 변형인 LSTM은 시퀀스 모델링에 성공하면서 인기를 얻었습니다. RNN은 주로 단일 모달리티를 표현하는 데 사용되었으며, 특히 언어 도메인에서 큰 성공을 거두었습니다.
RNN의 hidden state는 데이터 표현으로 볼 수 있습니다. 특히, 시점 t에서의 RNN hidden state는 그 시점까지의 시퀀스를 요약한 것으로 간주할 수도 있습니다. 이는 RNN encoder-decoder 구조에서 특히 뚜렷합니다. 인코더가 스퀀스를 hidden state에 요약하고 디코더가 이를 재구성합니다.
3.2 Coordinate Representation
joint multimodal representation의 대안은 coordinated representation입니다. 모달리티를 하나의 공간으로 함께 투사하는 대신, 각 모달리티에 대해 별개의 표현을 학습하지만 제약조건을 통해 이들을 조정합니다.
3.2.1 유사성 기반 조정 표현 (Similarity Models)
유사성 모델은 조정된 공간에서 모달리티 간 거리를 최소화합니다. 예를 들어 단어 "dog"와 개의 이미지는 서로 거리가 가깝고, "dog"와 자동차 이미지 간 거리는 멀도록 학습합니다. 초기 예시 중 하나는 Weston et al. 의 WSABIE입니다. WSABIE는 이미지와 텍스트 특징을 선형 매핑하여 대응되는 주석과 이미지 표현 간 내적(inner product)을 최대화(또는 코사인 거리를 최소화)하는 방식으로 조정된 공간을 만듭니다.
3.2.2 신경망 기반 조정 표현
최근에는 신경망을 사용하여 조정된 표현을 구성하는 방식이 인기입니다. 이 방식의 장점은 end-to-end로 coordinate representation을 학습할 수 있기 때문입니다. 예시는 다음과 같습니다:
- DeViSE: 이미지와 단어를 신경망을 통해 임베딩한 후 WSABIE와 유사하게 내적과 순위 손실(ranking loss)을 사용합니다.
- Kiros et al.: LSTM과 pairwise ranking loss를 이용해서 문장과 이미지 간 조정 표현을 만들었습니다.
- Socher et al.: 문장 모델을 의존 트리 RNN(dependency tree RNN)으로 확장하여 조합적 의미론을 추가했습니다.
이러한 표현들은 주로 크로스 모달 검색(cross-modal retrieval) 및 비디오 설명(video decription)에 사용됩니다.
3.2.3 구조화된 조정 표현 (Structured Coordinated Representations)
위 모델들은 단순히 유사성만 강제했지만, 구조화된 조정 표현은 이에 추가적인 제약을 더 가합니다. 이 제약은 응용에 따라 달라지며, 해싱(Hasing), 크로스 모달 검색(cross-modal retrieval)이나 이미지 캡셔닝 등에 사용됩니다.
크로스 모달 해싱의 경우는 고차원의 데이터를 짧은 이진 코드로 압축하는 태스크입니다. 이는 크로스 모달 검색을 위한 코드를 제공하기 위해서 수행됩니다. 이 경우 다음의 조건을 만족해야합니다:
- 해밍 공간(Hamming space)에서 표현되야합니다. (N-bit binary code)
- 다른 모달리티에서 온 같은 객체는 유사한 해시 코드를 가져야합니다.
- 임베딩 공간은 유사성을 유지해야합니다.
부분 순서 임베딩은 Vendrov et al.에 의해 제안되었습니다. 이는 데이터들 간에 존재하는 위계적 관계(hierachy)나 일반화 관계(generalization)를 임베딩 공간에 직접 반영하려는 기법입니다. "더 구체적인 개념"은 "더 일반적인 개념"보다 임베딩 공간에서 아래에 위치해야한다는 부분순서를 학습하는 것입니다.
일반적인 크로스 모달 임베딩에서는 모든 쌍을 그냥 비슷하게만 만들려고 하지만, 해당 임베딩을 사용하면 "여성이 개를 산책시키는 사진" ⟶ "여성이 개를 산책한다" ⟶ "여성" 과 같이 "특정 이미지"는 "보다 일반적인 문장"들을 모두 포함하는 개념으로 이를 임베딩 공간에서 강제합니다.
더 구체적일수록 임베딩 값이 크다고 정의하고 만약 x는 y보다 구체적이라면
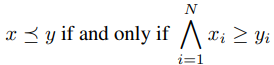
와 같이 강제합니다. 이때 손실함수는 다음과 같습니다:
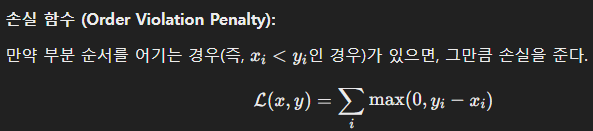
Zhang et al.은 더 나아가 텍스트와 이미지의 구조적 표현을 활용해 개념 분류 체계를 비지도 학습하기도 했습니다.
CCA (Canonical Correlation Analysis)는 서로 다른 두 모달리티 사시의 공통된 정보를 최대한 잡아내는 방법입니다. 즉, 서로 다른 두 데이터셋을 각각 다른 공간에 표현하면서, 표현된 것끼리 가장 잘 맞게(상관이 높게) 만드는 선형 변환을 찾는 것입니다.
쉽게 말하자면 서로 다른 모달리티의 표현 X와 Y를 각각 적절히 선형 변환해서 둘 사이의 상관계수(correlation coefficient)를 최대화하는 것입니다.

KCCA는 CCA을 비선형 문제에 적용하기 위해 만들어진 방법으로 kernel trick을 사용해서 데이터를 고차원 공간으로 옮긴 뒤 선형 CCA를 수행하는 것입니다. 이는 비선형 관계도 잡아낼 수 있다는 장점이 있지만, 비모수적 방법이라 대규모 데이터에서는 스케일이 안 된다는 단점이 있었습니다.
DCCA(Deep CCA)는 CCA를 딥러닝으로 확장한 방법으로 X와 Y를 각각 신경망을 통해 인코딩한 후 그 결과를 가지고 상관관계를 최대화하는 것입니다.

이는 매우 복잡하고 비선형적인 관계까지 잡아낼 수 있으며, KCCA와 같이 메모리 폭발 문제가 발생하지 않습니다. 그러므로 대규모 데이터셋에서도 확장 가능합니다.
3.3 Discussion
section 3.에서는 두 가지 멀티모달 표현 방식 - 공동 표현(joint representation) 과 조정된 표현(coordinated representation)에 대해 알아봤습니다.
- 공동 표현은 멀티모달 데이터를 공통 공간(common space)으로 투사하며, 이는 모든 모달리티가 추론(inference) 시점에 존재하는 상황에 가장 적합합니다. 공동 표현은 오디오-비주얼 음성 인식(AVSR), 감정 인식(affect recognition), 멀티모달 제스처 인식에서 널리 사용되었습니다.
- 조정된 표현은 각 모달리티를 별개의 공간으로 투사하지만, 이 공간들은 서로 조정되어 있습니다. 조정된 표현한 테스트 시점에 하나의 모달리티만 존재하는 응용에 적합합니다. 예를 들어:
- 멀티모달 검색(multimodal retrieval)
- 변환(translation)
- 개념 그라운딩(concept grounding)
- 제로샷 러닝(zero-shot learning)
*입력 단에서 모든 모달리티가 같이 입력되야하는 공동 표현 방법은 테스트 단계에서도 모든 모달리티가 동시에 들어오는 것이 보장된 태스크에서 유용하며, coordinated representation은 별도의 공간에 투사하기 때문에 테스트 단계에서 일부의 모달리티만 들어와도 괜찮고, 심지어는 들어오지 않은 모달리티에 대한 추론까지 할 수 있다.
'[CoIn]' 카테고리의 다른 글
| [CoIn] 논문 리뷰 | Multimodal Machine Learning:A Survey and Taxonomy (2) (0) | 2025.04.07 |
|---|
https://ieeexplore.ieee.org/abstract/document/8269806
Multimodal Machine Learning: A Survey and Taxonomy
Our experience of the world is multimodal - we see objects, hear sounds, feel texture, smell odors, and taste flavors. Modality refers to the way in which something happens or is experienced and a research problem is characterized as multimodal when it inc
ieeexplore.ieee.org
1. Introduction
인간은 오감(다양한 모달리티)을 통해 세상을 경험합니다. 일반적으로 모달리티란 어떤 일이 발생하거나 경험되는 방식을 의미합니다. 여러 모달리티가 포함된 연구 문제나 데이터셋을 멀티모달(multimodal)이라고 불립니다. 해당 논문에서는 모든 모달리티 대신 주로 다음 세 가지의 모달리티에 집중합니다:
- 자연어: 말로 하거나 글로 쓸 수 있는
- 시각 신호: 이미지나 비디오
- 음성 신호: 소리 및 억양, 감정 표현 등의 정보
AI가 세상을 이해하기 위해서는 이런 멀티모달 메시지들을 해석하고 추론할 수 있어야 합니다. 멀티모달 머신러닝은 여러 모달리티의 정보를 처리하고 연결하는 모델을 구축하는 것을 목표로 합니다. 멀티모달 머신러닝 분야는 서로 다른 데이터들을 이용해 모달리티 간의 대응 (correspondence)을 포착하고, 자연 현상에 대한 심층적인 이해를 얻을 수 있다는 특징이 있습니다.
해당 논문에서는 다음 5가지의 핵심 기술 과제에 대해 다룹니다:
- Representation
- 여러 모달리티의 보완성과 중복성을 활용할 수 있도록 멀티모달 데이터를 표현하고 요약하는 방법을 학습
- 멀티모달 데이터간의 이질성은 이를 표현하기 어렵게 만듭니다.
- 예를 들어 언어는 symbolic하며, 오디오나 비전은 signal이라서 같이 표현하기 힘들다.
- Translation
- 한 모달리티를 다른 모달리티로 매핑하는 방법
- 데이터들끼리는 서로 이질적일 뿐 아니라, 모달리티 간의 관계는 종종 closed-end가 아니며 주관적입니다.
- 예를 들어 이미지를 설명하는 방법은 여러 가지가 있을 수 있으며, 하나의 완벽한 번역이 존재하지 않다.
- Alignment
- 서로 다른 모달리티의 하위 요소들 간 관계를 찾아내는 것
- 이 과제를 해결하기 위해서는 서로 다른 모달리티 간 유사성을 측정하고, 장기 의존성(long-range dependencies)와 모호성(ambiguity)에 대처해야합니다.
- 예를 들어 요리 레시피(언어)와 요리 동영상(비디오)의 매칭
- Fusion
- 여러 모달리티를 결합해서 예측 수행
- 서로 다른 모달리티에서 오는 정보는 예측 능력과 노이즈 특성이 다를 수 있으며, 일부 모달리티에서는 데이터가 누락될 수도 있습니다.
- Co-learning
- 이는 모달리티나 모달리티의 표현, 해당 예측 모델간의 지식 전이를 다룹니다.
- 한 모달리티에서 배운 지식이 다른 모달리티 학습을 도울 수 있습니다.
- 이 과제는 특히 한 모달리티의 자원이 제한적(레이블 부족 문제)일때, 이를 해결하는 데 유용할 수 있습니다.
2. Applications: A historical Perspective
멀티모달 머신러닝은 오디오-비주얼 음성 인식에서 이미지 캡셔닝에 이르기까지 광범위한 응용을 가능하게 했습니다. 해당 섹션에서는 오디오-비주얼 음성 인식에서 최근 언어와 비전 응용 분야에 대한 관심이 새로워지기까지, 멀티모달 응용의 간략한 역사를 소개합니다.
(1) AVSR (audio-visual speech recognition)
멀티모달 연구의 가장 초기 사례 중 하나는 오디오-비주얼 음성 인식(AVSR)입니다. 이는 McGurk효과; 말소리 인식 중 청각과 시각의 상호작용에 의해 동기부여된 태스크입니다.https://ko.wikipedia.org/wiki/%EB%A7%A5%EA%B1%B0%ED%81%AC_%ED%9A%A8%EA%B3%BC
맥거크 효과 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 맥거크 효과(McGurk effect)는 음성 인식에 있어서 청각정보가 시각정보의 간섭으로 변화된 후 인지되는 현상을 말한다. 1976년 해리 맥거크(Harry McGurk)가 과학 학술
ko.wikipedia.org
예를 들어 사람이 /ga-ga/라고 말하는 입 모양을 보면서 /ba-ba/ 라는 소리를 들어면, 사람들은 제3의 소리인 /da-da/를 인식했습니다. 이 결과는 많은 음성 연구자들이 자신들의 접근 방식에 시각 정보를 추가하도록 동기부여했습니다. 이는 hidden Markov models (HMM)을 이용해 수행되었으며, 초기 AVSR 모델 중 다수는 HMM의 확장이었습니다.
https://untitledtblog.tistory.com/97
[머신 러닝] - 은닉 마르코프 모델 (Hidden Markov Model, HMM)
Markov model은 어떠한 날씨, 주식가격 등과 같은 어떠한 현상의 변화를 확률 모델로 표현한 것이다. Hidden Markov model (HMM)은 이러한 Markov model에 은닉된 state와 직접적으로 확인 가능한 observation을 추
untitledtblog.tistory.com
AVSR의 원래 목표는 모든 상황에서 음성 인식 성능을 향상시키는 것이었지만, 실험 결과에 따르면 시각 정보의 주요 이점은 음성 신호에 노이즈가 많은 상황에서만 나타났습니다. 즉, 모달리티 간 상호작용은 보완적(complementary) 라기 보다는 보조적(supplementary)이었습니다. 같은 정보가 두 모달리티에 모두 포착되어 멀티모달 모델의 견고성(robustness)은 향상되었지만, 노이즈가 없는 상황에서는 음성 인식 성능이 향상되지는 않았습니다.
(2) Multimedia content indexing and retrieval
두 번째 응용 범주는 멀티미디어 콘텐츠 인덱싱 및 검색 분야입니다. 개인용 컴퓨터와 인터넷의 발전으로 디지털 멀티미디어 콘텐츠의 양이 급격이 증가함으로써 초기에는 키워드 기반 검색 방법이 주류였지만, 이후 시각적 및 멀티모달 콘텐츠를 "직접" 검색하려는 시도가 등장하면서 새로운 연구 문제가 생겼습니다.
이로 인해 자동 장면 경계 탐지(automatic shot-boundary detection)나 비디오 요약(video summarization)같은 멀티미디어 콘텐츠 분석 주제가 탄생했습니다. *비디오에서 장면이 변경되는 부분을 탐지하는 태스크
이러한 연구들은 TrecVid initiative에 의해 지원되었으며, 이는 2011년에 시작된 멀티미디어 이벤트 감지(MED) 과제를 포함해 많은 고품질 데이터셋을 제공했습니다.
(3) multimodal interaction
세 번째 응용 분야는 2000년대 초반 등장한 멀티모달 상호작용 분야입니다. 이 분야는 사회적 상호작용 중 인간의 멀티모달 행동을 이해하는 것을 목표로 합니다. 대표적인 데이터셋으로는 다음이 있습니다:
- AMI Meeting Corpus: 100시간 이상의 회의 녹화 영상과 완전한 전사 및 주석이 포함
- SEMAINE Corpus: 화자와 청자의 대인 관계 역학을 연구할 수 있는 데이터셋
이는 오디오-비주얼 감정 인식 대회(AVEC)의 기반이 되었습니다. 감정 인식과 감성 컴퓨팅(affective computing) 분야는 자동 얼굴 검출, 얼굴 랜드마크 검출, 얼굴 표정 인식 기술의 발전으로 2010년대 초 급성장했습니다. D'Mello의 연구에 따르면 대부분의 최신 멀티모달 감성 인식 연구는 둘 이상의 모달리티를 사용할 때 성능이 향상되지만, 자연 발생 감정(naturally-occurring emotions)을 인식할 때는 그 향상이 줄어드는 것으로 나타났습니다.
(4) media description
가장 최근에는 언어와 비전을 강조하는 새로운 멀티모달 응용 범주가 등장했습니다. 이는 미디어 설명입니다.
대표적인 응용은 이미지 캡셔닝(image captioning)으로, 입력 이미지를 설명하는 텍스트를 생성하는 작업입니다. 이는 시각 장애인들이 일상 생활을 수행하는 데 도움을 줄 수 있습니다.
최근에는 반대로 텍스트로부터 미디어를 생성하는(media generation from text) 작업에서도 많은 발전이 있었습니다. 여기에서의 주요 도전 과제는 평가(evaluation)입니다. 예측된 설명과 미디어의 품질을 어떻게 평가할 것인가? 시각적 질문-응답(Visual Question Answering, VQA) 작업이 이 평가 문제를 일부 해결하기 위해 제안되었습니다.
VQA: Visual Question Answering - Computer Vision & NLP 분야에 대해
최근에 VQA 논문에 대해 찾아보고 있었는데, VQA 분야가 발전된 흐름이나 최신 트렌드를 정리해놓은 글이 생각보다 적었다. 이것저것 조사하다 보니, 기록도 할겸 VQA 분야가 어떤 연구 트렌드로
kookie12.tistory.com
하지만 현실 세계에 이러한 응용을 가져오기 위해서는, 멀티모달 머신러닝이 직면한 여러 기술적 도전 과제들을 해결해야합니다. 그리고 가장 중요한 과제 중 하나인 multimodal representation을 다음 섹선에서 중점적으로 다룰 것입니다.
3. Multimodal Representation
데이터를 컴퓨팅 모델이 사용할 수 있는 형식으로 표현하는 것은 머신러닝에서 항상 도전 과제였습니다. 멀티모달 표현(multimodal representation)은 모달리티 간의 표현들의 정보를 활용하여 데이터를 표현하는 것입니다. 이렇게 여러 모달리티를 표현하는 데는 많은 어려움이 따릅니다:
- 이질적인 source로부터 데이터를 어떻게 결합할지,
- 서로 다른 수준의 노이즈를 어떻게 처리할지,
- 누락된 데이터를 어떻게 다룰지.
데이터를 의미 있는 방식으로 표현하는 능력은 멀티모달 문제에 매우 중요하며, 모든 모델의 기반(backbone)을 이룹니다.
좋은 표현은 머신러닝 모델의 성능에 매우 중요합니다. 이는 최근 음성 인식과 시각적 객체 분류 시스템의 성능이 급격히 향상된 사례에서 잘 드러납니다. Bengio et al. 은 좋은 표현을 위한 여러 속성들을 식별했습니다:
- 부드러움(smoothness) *비슷한 입력 데이터는 비슷한 표현값을 가져야한다는 뜻. 데이터가 조금 변해도 표현 값이 크게 변하지 않아야 일반화가 잘 됩니다.
- 시간적 및 공간적 일관성 (Temporal and Spatial Coherence) *시간이나 공간적으로 가까운 데이터는 비슷한 의미를 갖는다는 뜻. 모델은 이런 일관성을 잘 포착함으로써 변화난 움직임을 자연스럽게 이해할 수 있습니다.
- 희소성(Sparsity) *사실 이게 제일 이해가 안됐었다. 그런데 이걸 정규화라고 생각하니 좀 이해가됐다. 표현 벡터에서 많은 값이 0이고, 소수의 값만 의미 있는 값을 갖는다는 것입니다. 이를 통해 해석이 쉬워지며(어떤 특성인지 알 수 있다), 노이즈에 강해질 수 있습니다. ex. sparse CNN
- 자연스러운 군집화(Natural Clustering) *비슷한 개념들은 표현 공간에서 서로 가깝게 모여야합니다. 이는 word2vec에서 비슷한 단어들끼리는 벡터 공간 상에 비슷한 위치에 있는 현상과 유사하게 해석할 수 있습니다.
*참고로 자연스러운 군집화를 목표로 한다면 Triplet loss를 사용할 수도 있습니다.
Triplet Loss, Triplet Mining 정리
Triplet Loss 개요 Triplet Loss는 앞에 설명한 Contrastive loss 와 같이 Deep learning based Face recognition에서 두가지 기술 발전방향중 Loss function에의한 발전에 속하고 그 중에서 verification loss function에 해당. 간
mic97.tistory.com
또한 Srivastava and Salakhutdinov는 멀티모달 표현에 대해 추가적으로 바람직한 속성을 제시했습니다:
- 표현 공간 내에서의 유사성은 해당 개념 간 유사성을 반영해야 하며,
- 일부 모달리티가 없더라도 쉽게 표현을 얻을 수 있어야 하며, *이는 어떻게 보면 당연한게 다양한 모달리티들의 상호작용을 학습하는 것이 목표이기 때문에 좋은 멀티모달 표현은 이를 달성해야합니다.
- 관찰된 모달리티를 기반으로 누락된 모달리티를 채워 넣을 수 있어야 합니다. *위 내용과 비슷함
단일 모달리티(unimodal) 표현 개발은 광범위하게 연구되었습니다. 예를 들어 2000년대 초에는 이미지를 표현하는 가장 인기 있는 방법 중 하나가 핸드메이드 특징(예: SIFT)을 이용한 시각적 단어 집합(bag of visual words) 방식이었습니다. 하지만 현재는 대부분의 이미지는 합성곱 신경망(CNN) 같은 신경망 구조를 통해 데이터로부터 학습된 표현을 사용합니다.
비슷하게 오디오 분야에서는 MFCC 같은 음향 특징이 (1) 음성 인식에서는 데이터 기반 DNN(Deep Neural Network), (2) 준언어 분석(para-linguistic analysis)에서는 순환 신경망(RNN)으로 대체되었습니다.
자연어 처리(NLP) 분야에서는, 초기에는 문서 내 단어 등장 횟수를 세는 방식(bag of words)이 주류였지만, 지금은 단어 임베딩(word embeddings) 기술이 문맥을 활용하여 데이터 기반으로 단어를 표현합니다.
단일 모달리티 표현에 대한 연구는 방대하지만, 최근까지 대부분의 멀티모달 표현은 단순히 단일 모달리티 표현을 연결(concatenation)하는 방식이었습니다. 하지만 이것은 빠르게 변화하고 있습니다. 해당 논문에서 제시하는 멀티모달 표현 분류는 두 가지입니다:
- Joint Representations (공동 표현):
- 서로 다른 단일 모달리티 신호를 하나의 표현 공간으로 결합합니다.
- Coordinated Representations (조정 표현):
- 단일 모달리티 신호를 각각 따로 처리하되, 특정 유사성 제약을 적용하여 '조정된 공간(coordinated space)'에 맵핑합니다.
수학적으로 표현하면 다음과 같습니다.
공동 표현의 경우, xm은 단일 모달리티 표현 x1, ..., xn을 기반으로 함수 f(예: DNN, RNN, etc.)를 통해 계산됩니다.
조정 표현의 경우 각 모달리티에 대해 해당 모달리티를 조정된 멀티모달 공간으로 투사(projection)하는 별도의 함수 f와 g가 존재합니다. 모달리티 별 투사는 독립적이지만, 결과 공간은 조정되어 있습니다. 조정의 예로는 다음이 있습니다:
- 코사인 거리 최소화(cosine distance minimization)
- 상관 관계 최대화(correlation maximization)
- 결과 공간 간의 부분 순서(partial order) 강제
*여기서 결과 공간 간의 부분 순서 강제 부분이 이해가 잘 안됐다. 그래서 찾아보니, 부분 순서는 모든 쌍이 비교 가능한 건 아니지만 비교 가능한 쌍끼리는 일정한 '우선 순위'가 존재하는 구조를 말한답니다. 이는 RLHF의 강화학습으로 이해하면 편한데, 인간의 선호도에 따라 모든 데이터들을 비교할 수는 없기 때문에 강화학습 모델을 학습할 때 비선호 출력과 선호 출력간의 비교를 통해서 학습을 했었음. 위에서 말한 triplet loss도 비슷한 의미입니다.
*대표적인 모델로는 CLIP이 있는데, 이미지는 ViT(Transformer), 텍스트는 Transformer로 각각 따로 인코딩한 후, 두 표현 벡터가 비슷한 의미를 공유하도록 대조 학습(Contrastive Learning)을 사용했습니다.
Contrastive Learning Loss: NT-Xent & InfoNCE
Both are commonly used loss functions in self-supervised learning tasks, where the goal is to learn meaningful representations by maximizing the similarity between positive pairs (augmented views of the same instance) while minimizing the similarity with n
medium.com
3.1 공동 표현 (Joint Representations)
먼저 단일 모달리티 표현을 함께 투사하여 멀티모달 공간으로 만드는 공동 표현부터 살펴보겠습니다. 공동 표현은 주로 학습 단계와 추론 단계에서 모두 멀티모달 데이터가 존재하는 경우에 사용됩니다. 공동 표현의 가장 간단한 예는 개별 모달리티 특징을 단순 연결(concatenation)하는 것으로 early fusion이라고도 불립니다. 이 절에서는 신경망, graphic model, 순환 신경망을 이용해 공동 표현을 만드는 방법들에 대해 논의합니다.
3.1.1 신경망 (Nueral Networks)
신경망은 단일 모달리티 데이터 표현에서는 매우 인기 있는 방법이며, 시각, 음향, 텍스트 데이터를 표현하는 데 사용됩니다. 그리고 멀티모달 분야에서도 점점 더 많이 사용되고 있습니다. 일반적으로 신경망은 내적과 비선형 활성화 함수로 구성된 연속적인 블록으로 이루어집니다. 깊은 신경망은 여러 층을 가지며, 각 층은 점점 더 추상적인 수준에서 데이터를 표현한다고 가정합니다. 따라서 최종 층 도는 마지막 층에서 두 번째 층을 데이터 표현을 사용하는 것이 일반적입니다.
멀티모달 표현을 구성할 때는, 각 모달리티가 개별 신경망 층을 거친 후, 공동 공간으로 투사(projection)하는 은닉층(hidden layer)로 이어집니다. 그 이후, 공동 표현은 추가적인 은닉층을 통과하거나 직접 예측에 사용될 수 있습니다.
신경망은 많은 수의 라벨링된 데이터가 필요하기 때문에, (1) 비지도 데이터(예: 오토인코더)를 사용하거나, (2) 다른 관련 도메인의 지도 데이터를 사용하여 사전학습 하는 경우가 많습니다. *Autoencoder란 표현 학습 작업에 신경망을 활용하도록 하는 비지도 학습 방법입니다. 이는 입력이 들어왔을 때, 해당 입력 데이터를 최대한 압축시킨 후, 데이터의 특징을 추출하여 다시 본래의 입력 형태로 복원시키는 신경망입니다. 이가 멀티모달에서 사용된다면 다음과 같은 방식으로 사용됩니다:
(이미지, 텍스트, 오디오)
↓ (각 모달리티별 인코더)
[ 통합된 잠재 공간 z ] ← ★ 여기가 공동 표현
↓ (디코더)
(이미지', 텍스트', 오디오') → 재구성[딥러닝] AutoEncoder 개념 및 종류
Autoencoder(오토인코더)란 representation learning 작업에 신경망을 활용하도록 하는 비지도 학습 방법 입력이 들어왔을 때, 해당 입력 데이터를 최대한 압축시킨 후 , 데이터의 특징을 추출하여 다시 본
velog.io
신경망 기반 공동 표현의 주요 장점은, 라벨이 충분하지 않은 경우 비지도 데이터로 사전 학습이 가능하다는 것입니다(autoencoding). 또한 사전학습된 표현은 특정 작업에 대해 fine-tuning할 수도 있습니다. 하지만 신경망은 missing data를 잘 다루지 못하는 경향이 있으며, 학습이 어렵다는 문제가 있습니다. 하지만 이는 (1) 개선된 정규화, (2) 배치 정규화, (3) 적응적 그래디언트 알고리즘을 통해 해결할 수 있습니다.
3.1.2 확률적 그래픽 모델 (Probabilistic Graphical Models)
확률적 그래픽 모델은 잠재 랜덤 변수를 통해 표현을 구성하는 데 사용할 수 있습니다. 여기서는 단일 및 멀티모달 데이터를 그래픽 모델로 표현하는 방법을 설명합니다. 대표적으로는 딥 볼츠만 머신(Deep Boltzman Machine, DBM)이 있으며, 이는 제한 볼츠만 머신(RBM)을 여러 층 쌓아 구성합니다.
https://angeloyeo.github.io/2020/10/02/RBM.html
Restricted Boltzmann Machine - 공돌이의 수학정리노트 (Angelo's Math Notes)
angeloyeo.github.io
신경망과 유사하게, DBM의 각 층은 데이터의 더 높은 수준의 추상 표현을 학습합니다. DBM의 장점은 지도 학습 없이 학습할 수 있다는 것입니다. 멀티모달 DBM의 주요 장점은 (1) 생성적(generative) 특성 덕분에 결손 데이터가 있어도 자연스럽게 다룰 수 있다는 것입니다. 또한 (2) 하나의 모달리티만으로도 다른 모달리티를 생성할 수도 있습니다. 하지만 DBM은 학습이 매우 어렵고, 고비용이 들며. 근사 변분 학습(approximate variational methods)을 사용해야한다는 단점이 있습니다.
Variational Inference & Free Energy
## 책 소개 **《변분추론과 Free Energy》**는 베이즈 추론에서 자주 등장하는 **사후분포 추정** 문제를 보다 간단한 **근사(Variational) 분포**로 해…
wikidocs.net
3.1.3 순차적 표현 (Sequential Representation)
지금까지는 고정 길이 데이터를 다루는 모델을 살펴보았지만, 실제로는 문장, 비디오, 오디오 스트림처럼 가변 길이 시퀀스를 표현해야 할 필요가 있습니다. 순환 신경망(RNN) 및 그 변형인 LSTM은 시퀀스 모델링에 성공하면서 인기를 얻었습니다. RNN은 주로 단일 모달리티를 표현하는 데 사용되었으며, 특히 언어 도메인에서 큰 성공을 거두었습니다.
RNN의 hidden state는 데이터 표현으로 볼 수 있습니다. 특히, 시점 t에서의 RNN hidden state는 그 시점까지의 시퀀스를 요약한 것으로 간주할 수도 있습니다. 이는 RNN encoder-decoder 구조에서 특히 뚜렷합니다. 인코더가 스퀀스를 hidden state에 요약하고 디코더가 이를 재구성합니다.
3.2 Coordinate Representation
joint multimodal representation의 대안은 coordinated representation입니다. 모달리티를 하나의 공간으로 함께 투사하는 대신, 각 모달리티에 대해 별개의 표현을 학습하지만 제약조건을 통해 이들을 조정합니다.
3.2.1 유사성 기반 조정 표현 (Similarity Models)
유사성 모델은 조정된 공간에서 모달리티 간 거리를 최소화합니다. 예를 들어 단어 "dog"와 개의 이미지는 서로 거리가 가깝고, "dog"와 자동차 이미지 간 거리는 멀도록 학습합니다. 초기 예시 중 하나는 Weston et al. 의 WSABIE입니다. WSABIE는 이미지와 텍스트 특징을 선형 매핑하여 대응되는 주석과 이미지 표현 간 내적(inner product)을 최대화(또는 코사인 거리를 최소화)하는 방식으로 조정된 공간을 만듭니다.
3.2.2 신경망 기반 조정 표현
최근에는 신경망을 사용하여 조정된 표현을 구성하는 방식이 인기입니다. 이 방식의 장점은 end-to-end로 coordinate representation을 학습할 수 있기 때문입니다. 예시는 다음과 같습니다:
- DeViSE: 이미지와 단어를 신경망을 통해 임베딩한 후 WSABIE와 유사하게 내적과 순위 손실(ranking loss)을 사용합니다.
- Kiros et al.: LSTM과 pairwise ranking loss를 이용해서 문장과 이미지 간 조정 표현을 만들었습니다.
- Socher et al.: 문장 모델을 의존 트리 RNN(dependency tree RNN)으로 확장하여 조합적 의미론을 추가했습니다.
이러한 표현들은 주로 크로스 모달 검색(cross-modal retrieval) 및 비디오 설명(video decription)에 사용됩니다.
3.2.3 구조화된 조정 표현 (Structured Coordinated Representations)
위 모델들은 단순히 유사성만 강제했지만, 구조화된 조정 표현은 이에 추가적인 제약을 더 가합니다. 이 제약은 응용에 따라 달라지며, 해싱(Hasing), 크로스 모달 검색(cross-modal retrieval)이나 이미지 캡셔닝 등에 사용됩니다.
크로스 모달 해싱의 경우는 고차원의 데이터를 짧은 이진 코드로 압축하는 태스크입니다. 이는 크로스 모달 검색을 위한 코드를 제공하기 위해서 수행됩니다. 이 경우 다음의 조건을 만족해야합니다:
- 해밍 공간(Hamming space)에서 표현되야합니다. (N-bit binary code)
- 다른 모달리티에서 온 같은 객체는 유사한 해시 코드를 가져야합니다.
- 임베딩 공간은 유사성을 유지해야합니다.
부분 순서 임베딩은 Vendrov et al.에 의해 제안되었습니다. 이는 데이터들 간에 존재하는 위계적 관계(hierachy)나 일반화 관계(generalization)를 임베딩 공간에 직접 반영하려는 기법입니다. "더 구체적인 개념"은 "더 일반적인 개념"보다 임베딩 공간에서 아래에 위치해야한다는 부분순서를 학습하는 것입니다.
일반적인 크로스 모달 임베딩에서는 모든 쌍을 그냥 비슷하게만 만들려고 하지만, 해당 임베딩을 사용하면 "여성이 개를 산책시키는 사진" ⟶ "여성이 개를 산책한다" ⟶ "여성" 과 같이 "특정 이미지"는 "보다 일반적인 문장"들을 모두 포함하는 개념으로 이를 임베딩 공간에서 강제합니다.
더 구체적일수록 임베딩 값이 크다고 정의하고 만약 x는 y보다 구체적이라면
와 같이 강제합니다. 이때 손실함수는 다음과 같습니다:
Zhang et al.은 더 나아가 텍스트와 이미지의 구조적 표현을 활용해 개념 분류 체계를 비지도 학습하기도 했습니다.
CCA (Canonical Correlation Analysis)는 서로 다른 두 모달리티 사시의 공통된 정보를 최대한 잡아내는 방법입니다. 즉, 서로 다른 두 데이터셋을 각각 다른 공간에 표현하면서, 표현된 것끼리 가장 잘 맞게(상관이 높게) 만드는 선형 변환을 찾는 것입니다.
쉽게 말하자면 서로 다른 모달리티의 표현 X와 Y를 각각 적절히 선형 변환해서 둘 사이의 상관계수(correlation coefficient)를 최대화하는 것입니다.
KCCA는 CCA을 비선형 문제에 적용하기 위해 만들어진 방법으로 kernel trick을 사용해서 데이터를 고차원 공간으로 옮긴 뒤 선형 CCA를 수행하는 것입니다. 이는 비선형 관계도 잡아낼 수 있다는 장점이 있지만, 비모수적 방법이라 대규모 데이터에서는 스케일이 안 된다는 단점이 있었습니다.
DCCA(Deep CCA)는 CCA를 딥러닝으로 확장한 방법으로 X와 Y를 각각 신경망을 통해 인코딩한 후 그 결과를 가지고 상관관계를 최대화하는 것입니다.
이는 매우 복잡하고 비선형적인 관계까지 잡아낼 수 있으며, KCCA와 같이 메모리 폭발 문제가 발생하지 않습니다. 그러므로 대규모 데이터셋에서도 확장 가능합니다.
3.3 Discussion
section 3.에서는 두 가지 멀티모달 표현 방식 - 공동 표현(joint representation) 과 조정된 표현(coordinated representation)에 대해 알아봤습니다.
- 공동 표현은 멀티모달 데이터를 공통 공간(common space)으로 투사하며, 이는 모든 모달리티가 추론(inference) 시점에 존재하는 상황에 가장 적합합니다. 공동 표현은 오디오-비주얼 음성 인식(AVSR), 감정 인식(affect recognition), 멀티모달 제스처 인식에서 널리 사용되었습니다.
- 조정된 표현은 각 모달리티를 별개의 공간으로 투사하지만, 이 공간들은 서로 조정되어 있습니다. 조정된 표현한 테스트 시점에 하나의 모달리티만 존재하는 응용에 적합합니다. 예를 들어:
- 멀티모달 검색(multimodal retrieval)
- 변환(translation)
- 개념 그라운딩(concept grounding)
- 제로샷 러닝(zero-shot learning)
*입력 단에서 모든 모달리티가 같이 입력되야하는 공동 표현 방법은 테스트 단계에서도 모든 모달리티가 동시에 들어오는 것이 보장된 태스크에서 유용하며, coordinated representation은 별도의 공간에 투사하기 때문에 테스트 단계에서 일부의 모달리티만 들어와도 괜찮고, 심지어는 들어오지 않은 모달리티에 대한 추론까지 할 수 있다.
'[CoIn]' 카테고리의 다른 글
| [CoIn] 논문 리뷰 | Multimodal Machine Learning:A Survey and Taxonomy (2) (0) | 2025.04.07 |
|---|