
Basic concepts
CPU utilization을 최대화하기 위해서 multiprogramming은 필수적입니다. 이때 CPU의 cycle은 CPU burst와 I/O burst의 반복으로 이뤄집니다. *CPU burst에 의해 I/O burst가 일어나기에, CPU burst가 일반적으로 우선합니다(시간적으로).


CPU Scheduler
Short-term scheduler는 ready queue에 있는 process들 중 CPU에 할당할 process를 선택하는 역할을 맡습니다. 이때 CPU scheduler가 동작하는 경우는 아래의 4가지 경우입니다:
- Terminates; running 중인 process가 종료되는 경우
- Switches from running to waiting queue
- Switches from running to ready queue
- Switches from waiting to ready queue
위 케이스들 중 1번과 2번은 nonpreemptive, 3번과 4번을 preemptive하다고 합니다. 1,2번의 경우 스스로 running에서 빠져나온 것(1는 process 스스로 종료, 2는 process의 I/O 작업 때문에 running에서 나감)이기 때문에 우선순위에 의한 선점은 일어나지 않지만, 3,4번의 경우 ready queue로 들어온 process와 현재 runnning 중인 process간의 우선순위에 의한 선점이 일어날 수 있습니다.
preemptive상황의 경우 아래와 같은 고려사항들이 있습니다:
- Consider access to shared data
- Consider preemptive while in kernel mode
- Consider interrupts occurring during crucial OS activities
Dispatcher
Dispatcher 모듈은 CPU의 통제권을 scheduler에게 선택된 process에게 주는 역할을 수행합니다. 이는 다음과 같은 활동들을 포함합니다:
- switching context
- switching to user mode
- jumping to the proper location in the user program to restart that program
이때 발생하는 dispatch latency는 dispatcher가 프로세스를 종료시키고 다시 다른 프로세스를 실행시킬때까지 걸린 시간을 말합니다.
Scheduling Criteria
스케쥴러의 평가기준은 다음과 같습니다:
- CPU utilization; keep the CPU as busy as possible
- Throughput; # of processes that complete their execution per time unit. 단위 시간당 실행이 아에 끝난 프로세스의 수. 클 수록 good
- Turnaround time; amout of time to execute a particular process. 어떤 process가 ready queue에 들어가서 완전히 종료될 때까지 걸린 시간. 작을 수록 good
- Waiting time; amout of time a process has been waiting in the ready queue. 어떤 프로세스가 ready queue안에 들어가있던 총 시간. 작은 수록 good
- Response time; amount of time it takes from when a request was submitted until first response is produced, not output (for time-sharing environment). ready queue에 프로세스가 들어가서 처음 실행될 때까지의 시간. 작을 수록 good
Firtst-Come, First-Served (FCFS) Scheduling
가장 먼저 FCFS 스케쥴링입니다. 이는 말 그대로 먼저 오는 것을 먼저 처리하겠다는 것으로 FIFO와 같습니다. 예를 들어:

다음과 같은 프로세스들이 있을 때, 프로세스가 RQ로 들어오는 순서가 P1, P2, P3 순이면, 들어온 순서대로, P1, P2, P3 순서대로 처리합니다. 이때 Waiting time을 계산해보면 17이 나오게됩니다.
반면, 들어오는 순서를 조금 바꿔보면 어떨까요?

만약 들어오는 순서가 P2, P3, P1 순서였다면, Waiting tume은 3이 나옵니다. 즉, 들어오는 순서에 따라 scheduling의 성능이 매우 달라질 수 있는 것입니다. 이렇게 CPU burst가 긴 프로세스 뒤에 burst가 짧은 프로세스들이 있어서 waiting time이 매우 길어지는 효과를 Convoy effect라고 합니다. *예를 들어 CPU-bound 뒤에 I/O-bound process들이 RQ에 들어있는 상황이 있습니다.
Shortest-Job-First (SJF) Scheduling
이는 가장 짧은 burst를 갖는 프로세스 먼저 처리하는 스케쥴링입니다. 앞선 예시들 중 두 번째 예시가 SJF에 해당한다고 볼 수 있습니다. SJF는 최적해를 보장합니다. 즉, 가장 작은 average waiting time을 보장하는 스케쥴링 방법입니다. 하지만 CPU가 다음에 요청되는 Process의 burst를 미리 알기는 힘들기 때문에 구현하기 힘들다는 단점이 있습니다. *user에게 물어보는 해결방법도 있긴 하지만...
SJF의 예시입니다(들어오는 순서는 상관없고, 모든 process들의 burst time을 안다고 가정합니다):

Determining Length of Next CPU Burst
앞서 말했듯 앞으로 들어올 process의 실제 cpu burst를 알기는 힘듭니다. 그래서 예측한 cpu burst time을 사용합니다. 이는 다음과 같이 구할 수 있습니다:

n+1번째 process의 CPU burst를 예측하려는 경우, n번째 프로세스의 실제 CPU burst 시간과 n번째 프로세스에 대해 예측한 CPU burst 시간의 가중평균을 이용합니다. 이때 일반적으로 alpha는 1/2를 사용하여, 실제 값과 예측 값의 평균으로 다음 프로세스의 예측값을 사용합니다.
만약 이를 preemptive한 방식으로 사용한다면 이를 shortest-remaining-time-first라고 부릅니다. SJF는 처음 RQ에 들어왔을 때 계산(예측)한 burst time을 이용하여 스케쥴링을 진행하며, 어떤 process가 처리중이라면 다른 process가 이를 뺏지는 않습니다(non-preemptive). 하지만 shortest-remaining-time-first 방식은 처리중인 process든, 아니든 처리할 수 있는 process들의 남아있는 burst time을 기준으로 가장 작은 것을 먼저 처리하는 것입니다. 따라서 처리중인 process의 remaining time이 새롭게 RQ로 들어온 process의 remaining time보다 길다면, CPU control을 잃고 RQ로 내려와야합니다. 자세한 내용은 뒤에 있습니다.
다시 돌아와 다음 프로세스의 CPU burst를 예측하는 것을 그래프로 그리면 다음과 같습니다:

Examples of Exponential Averaging
아까 일반적으로는 alpha값을 1/2로 설정한다고 했는데, 만약 극한 값으로 설정한다면 어떤 일이 일어날까요?
만약 alpha = 0 이라면:

alpha가 0이면 가장 최근에 들어온 process의 CPU burst time을 사용하지 않고 예측하는 것입니다.
만약 alpha = 1 이라면:

alpha가 1이면 가장 최근에 예측한 값을 사용하지 않고 이전에 등장했던 실제 CPU burst time을 그대로 다음 CPU burst time의 예측값으로 사용하는 것입니다.
예측에 대한 식을 계속 풀어보면 다음과 같은데:
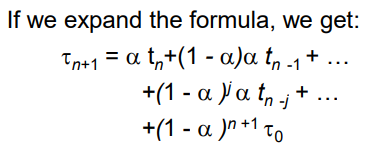
이는 이전의 들어온 모든 해당 프로세스의 CPU burst time들을 이용해 n+1번째 프로세스의 CPU burst time을 예측한다는 의미입니다.
Example of Shortest-remaining-time-first
preemptive 버전인 경우 다음과 같습니다:

이 과정을 글로 쓰기는 복잡해서 간단히만 설명하자면, 이는 SJF와 달리 도착시간도 고려해야하며(*그래야 선점(preemptive)하는 케이스가 나오니까), 시간이 지남에 따라 burst time이 점점 줄어드는 것도 고려해야합니다. 그렇게 줄어든 burst time과 RQ에 도착해서 대기하고 있는 프로세스들 간의 burst time을 비교합니다.
결과적으로 이는 최적까지는 아니지만 꽤나 괜찮은 average waiting time을 기록합니다. *average waiting time을 계산할 때 도착 시각도 고려해야합니다
Priority Scheduling
프로세스에 우선순위가 있으며, 우선순위가 높은 순서대로 처리하는 스케쥴링 방법입니다. 구현에 따라 다르겠지만 일반적으로 우선순위를 가르키는 integer가 낮으면 높은 우선순위를 의미합니다. SJF도 priority scheduler의 일종으로 볼 수 있습니다. 이때의 priority는 예상되는 CPU burst time의 역수입니다.
우선순위 스케쥴러를 사용하면 Starvation 문제가 발생할 수도 있습니다. 이는 낮은 우선순위의 프로세스가 높은 우선순위의 프로세스에게 계속해서 밀려서 한 번도 실행되지 않는 경우를 말합니다. 이에 대한 해결책으로는 aging이 있습니다. aging은 시간이 지남에 따라 프로세스들의 우선순위를 올려주는 것입니다. 그렇다면 우선순위가 낮은 오래전에 RQ에 들어온 프로세스는 시간이 지남에 따라 점점 우선순위가 높아져 CPU에 의해 실행될 확률이 올라갑니다.
Priority scheduler의 예시는 다음과 같습니다:

*위 예시는 non-preemptive한 스케쥴러의 예시이지만, preemptive한 예시도 존재합니다.
Round Robin (RR)
RR방식은 일정한 작은 단위의 CPU time(time quantum, q is usually 10-100 milliseconds)을 설정해서 그 시간이 지날 때마다 다른 프로세스들이 preemptive하고, 해당 프로세스는 RQ의 가장 마지막에 저장하는 방식입니다. 이는 RQ에 프로세스가 n개가 있을 때, 프로세스가 RQ에서 기다리는 시간을 최대 (n-1)*q 로 제한할 수 있습니다. *이는 Starvation문제를 해결할 수 있습니다.
q마다 timer interrupt를 호출하며 다음 프로세스를 scheduling하는 것입니다. 만약 q가 매우 크다면 이는 FIFO나 FCFS와 유사한 성능을 낼 것이며, q가 매우 작다면 context switch가 매우 자주 발생할 것이고 이에 드는 overhead가 매우 커질 것입니다. 즉 적절한 q의 설정이 매우 중요합니다. *q는 context switch에 드는 시간보다 반드시 커야합니다. context switch하는 동안 q가 다 지나갈 수 있기 때문입니다.
아래의 예시는 RR에서 quatum을 4로 설정한 예시입니다:

이는 turnaround time이나 waiting time의 관점에서는 SJF보다는 좋지 않지만 reponse time의 관점에서 어느정도 upper bound가 보장된 reponse를 제공한다는 점에서 장점을 갖습니다. *참고로 turnaround time이나 waiting time은 어느정도의 맥락을 공유하는 점이 있습니다.
아래의 그림은 time quantum과 context switch의 양에 대한 그림입니다:
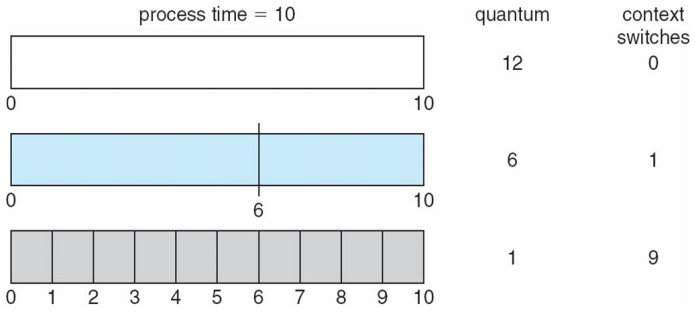
즉, q가 작으면 context switch의 수가 늘어난다는 것을 의미합니다.
아래의 그림은 turnaround time과 time quantum의 관계를 그래프로 그린 그림입니다:

일반적으로 q가 작으면 하나의 프로세스를 완전히 끝내지 않고 여러 프로세스들을 조금씩 실행하기 때문에 waiting time이나 turnaround time이 길어질 것이고, q가 크면 waiting time등이 줄어들거라고 생각하지만, 사실은 선형적으로 나타나는 현상은 아니라는 것을 보여줍니다. 적절한 q는 CPU burst들의 80%를 커버할 수 있는 정도의 q가 적절하다고 말합니다. 즉, 대부분의 process들은 한 번의 q에 실행이 완료될 정도는 되야한다는 것입니다. *그래야 context switch의 양도 줄이고 효율적
Multilevel Queue
지금까지는 RQ가 하나인 경우만을 살펴봤습니다. Multilevel queue는 RQ가 두 개 이상인 경우를 말합니다. 예를 들어 foreground와 background용 RQ를 따로 만들 수 있습니다. 각각의 queue에 들어간 프로세스들은 영구적으로 해당 queue에 있어야하며, 각각의 queue는 서로 다른 scheduling algorithm들을 가질 수 있습니다. 예를 들어 foreground는 RR, background는 FCFS로 설정할 수 있는 것입니다.
만약 CPU가 하나이고 RQ가 두 개 이상인 경우 CPU는 어떤 프로세스를 실행해야할까요? 이 경우 여러 방법이 있습니다:
- Fixed priority scheduling - 각 RQ의 우선순위를 설정하고 고정합니다. 앞선 예시에서는 foreground가 모두 실행된 후 background를 실행하는 것이 됩니다. 하지만 이 경우 Starvation문제가 발생할 수 있습니다.
- Time slice - CPU의 scheduling 자원을 각각의 queue에 나눕니다. 예를 들어 10번 프로세스를 실행할 수 있다면 8번은 foreground에서, 2번은 background에서 실행합니다.

위 예시는 서로 우선순위가 다른 queue들을 관리하는 예시입니다.
Multilevel Feedback Queue
Multilevel Feedback Queue는 일반 multilevel queue와는 다르게 queue간의 이동이 허용됩니다. 이는 서로 다른 우선순위를 갖는 queue들 사이로 이동할 수 있다는 의미이고, 이는 곧 프로세스의 우선순위가 변동될 수 있음을 말합니다. 앞서 말했던 aging이 그 예시입니다. Multilevel-feedback-queue scheduler를 사용할 시 고려해야할 내용은 아래와 같습니다:
- number of queues
- scheduling algorithms for each queue
- method used to determine when to upgrade a process
- method used to determine when to demote a process
- method used to determine which queue a process will enter when that process needs sevice
아래는 Multilevel-feedback-queue를 사용하는 경우의 예시입니다:
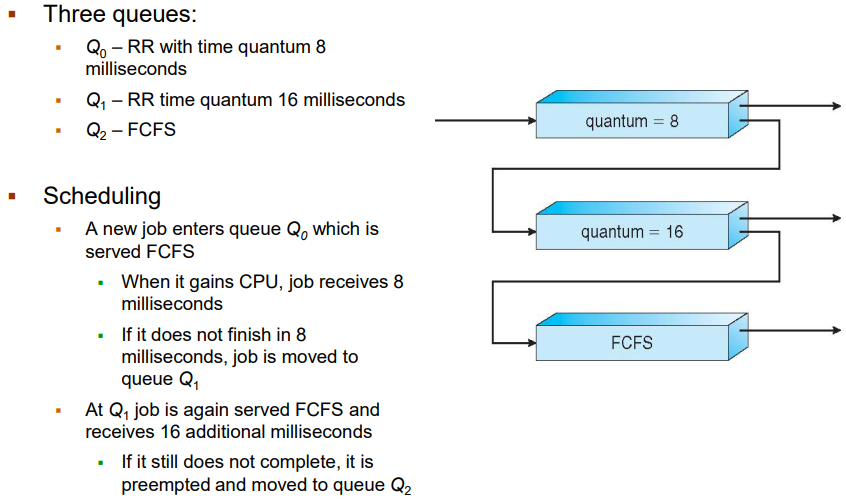
위 예시는 q=8인 RR queue와, q=16인 RR queue, FCFS를 따르는 queue로 3개의 queue를 이용한 경우입니다. 우선 Q0에 먼저 프로세스가 들어오고 만약 한 번에 끝나지 않은 프로세스의 경우는 아래의 Q1으로 내려보냅니다. Q1에서도 한 번에 끝내지 못하는 프로세스의 경우는 FCFS를 따르는 Q2로 보내집니다. 이는 CPU를 조금 사용하는(예: I/O-bound process) 프로세스에게 더 우선순위를 주는 scheduler라고 볼 수 있습니다.
Thread Scheduling
user thread와 kernel thread는 앞선 thread에서 봤듯, 다르게 다뤄집니다. 지금까지 process를 기준으로 scheduler를 본 것은 1process-1thread 상황에서 성립하는 것이며, 만약 multithreads를 허용한다면 scheduling의 단위는 process가 아닌 thread가 됩니다.
kernel thread는 OS scheduler에 의해 관리되며, user thread의 경우는 user level에 위치하는 thread library에 의해 관리되며 LWP 위에서 user thread가 동작하도록 합니다.
이때 하나의 프로세스 안에서의 thread들 간의 scheduling을 process-contention scope (PCS)라고 부르며, CPU의 사용을 두고 kernel thread끼리 경쟁하는 것을 system-contention scope (SCS)라고 부릅니다.
하지만 Linux나 Mac OS X와 같은 OS는 PTHREAD_SCOPE_SYSTEM만을 허용하며, PCS를 허용하지 않습니다.아래의 예시는 Pthread에서 scheduling API를 사용하는 예시입니다:

*prediction of next CPU burst time에 대한 예상 시나리오 (made by GPT)
좋아요! SJF(Shortest Job First)는 이름 그대로 작업 시간(Burst Time)이 짧은 작업부터 먼저 실행하는 방식인데, 실제 운영체제에서는 burst time을 미리 알 수 없기 때문에 예측을 통해 추정합니다.
이걸 더 잘 이해할 수 있도록 예측 기반 SJF 스케줄링 시나리오를 하나 만들어서 설명해볼게요.
🌟 시나리오: 동영상 편집 서버
💻 배경:
한 방송국의 서버는 여러 작업(예: 영상 필터 적용, 자막 입히기, 영상 인코딩 등)을 처리해야 합니다. 각 작업의 처리 시간은 다르지만, 과거 기록을 통해 “비슷한 요청이면 보통 얼마 정도 걸린다”는 데이터를 가지고 있습니다.
🧠 시스템 설정:
- OS는 SJF 스케줄링을 쓰는데, burst time은 과거 데이터 기반으로 예측합니다.
- 예측 공식 (지수 평균법 사용):
τn+1=α⋅tn+(1−α)⋅τn\tau_{n+1} = \alpha \cdot t_n + (1 - \alpha) \cdot \tau_n
- 여기서:
- tnt_n = 실제 실행 시간 (이번에 측정된 burst time)
- τn\tau_n = 이전 예측값
- α\alpha = 0.5 (최근 기록과 이전 예측을 반반 가중치로 사용)
🧾 작업 목록:
| A (영상 필터) | 8 | 10 |
| B (자막 입히기) | 4 | 3 |
| C (인코딩) | 6 | 5 |
🧮 Step 1: 첫 번째 실행 후 예측값 갱신
예를 들어 위 작업들이 한 번씩 실행된 후, 다음 실행에 앞서 새로운 예측값을 만듭니다.
τA,new=0.5⋅10+0.5⋅8=9τB,new=0.5⋅3+0.5⋅4=3.5τC,new=0.5⋅5+0.5⋅6=5.5\tau_{\text{A,new}} = 0.5 \cdot 10 + 0.5 \cdot 8 = 9 \\ \tau_{\text{B,new}} = 0.5 \cdot 3 + 0.5 \cdot 4 = 3.5 \\ \tau_{\text{C,new}} = 0.5 \cdot 5 + 0.5 \cdot 6 = 5.5
🧮 Step 2: 다음 스케줄링 (SJF 예측 기반)
- 다음 번 실행 때는 예측된 burst time이 가장 짧은 순서로 스케줄링
- 새로운 예측값 기준으로 실행 순서:
📌 요점 요약
- OS는 실제 burst time을 모르므로 예측값을 사용
- 지수 평균법으로 예측하면, 최근 경향도 반영하고 안정성도 확보 가능
- SJF는 예측값이 짧은 작업을 먼저 실행함으로써 평균 대기 시간과 turnaround time을 줄이려고 함
- 만약 예측이 부정확하면 starvation(긴 작업이 계속 밀림)이 발생할 수도 있음 → 이건 aging 같은 기법으로 보완 가능
'[학교 수업] > [학교 수업] Operating System' 카테고리의 다른 글
| [Operating System] Chapter 6: Synchronization (0) | 2025.05.10 |
|---|---|
| [Operating System] Chapter 4: Threads (2) | 2025.04.11 |
| [Operating System] Chapter 3: Processes (1) | 2025.04.05 |
| [Operating System] Chapter 2 & 3: Processes | Week 4 (0) | 2025.03.29 |
| [Operating System] Chapter 2: Operating-System Structures | Week 3 (0) | 2025.03.24 |