
https://gmongaras.medium.com/yolox-explanation-mosaic-and-mixup-for-data-augmentation-3839465a3adf
YOLOX Explanation — Mosaic and Mixup For Data Augmentation
The fourth and final article in my YOLOX explanation series where I talk about how YOLOX augments data for better performance.
gmongaras.medium.com
위 글의 한국어 번역입니다.
Data Augmentation
데이터 증강(data augmentation)은 모델이 일반화(generalization)하도록 돕는 방법입니다. 데이터를 증강하면, 모델은 이미지에서 객체를 판별할 때, 소수의 특징에만 의존하지 않고 새로운 특징들을 찾아 인식해야 합니다. YOLOX는 데이터에 대한 일반화를 돕기 위해 아주 효과적인 증강 기법들을 사용합니다. 이 글에서는 YOLOX가 사용하는 최고의 데이터 증강 두 가지를 다룹니다.
Mosaic
Mosaic 데이터 증강은 YOLOv4에서 처음 소개되었고, CutMix 데이터 증강의 개선판 입니다. Mosaic의 아이디어는 매우 단순합니다. 4장의 이미지를 가져와 하나의 이미지로 결합합니다. Mosaic은 네 이미지를 resize하고, 서로 이어 붙인 다음 이어 붙인 큰 이미지에서 무작위로 잘라내기(cutout)을 수행해 최종 Mosaic 이미지를 얻습니다.
YOLO 알고리즘에서 Mosaic 증강을 수행할 때의 어려움 중 하나는 최종 이미지를 만들 때 bbox를 신경 써야 한다는 점입니다. 이 작업은 그리 어렵지 않습니다. bbox를 resize하고 이동하면 되기 때문입니다. 다만, 이미지를 이어 붙이고 cutout을 만든 뒤 박스들을 어디로 옮겨야 하는지를 정하는 과정이 좀 번거롭긴 합니다.
다음은 네 장의 이미지와 생성될 최종 이미지 크기가 주어졌을 때, 최종 Mosaic 이미지를 만드는 단계들입니다:
- Image resize:여기서는 최종 출력 이미지의 모양으로 resize한다.
- 모든 이미지를 하나로 결합: resize된 4개 이미지를 새 이미지의 네 모서리에 배치한다.
- bbox를 올바른 위치에 배치
- 무작위 컷아웃을 수행하는데, 컷아웃의 크기는 우리가 원하는 최종 이미지 크기와 동일하다. 컷아웃은 네 이미지가 결합된 어디에서나 선택될 수 있지만, 최종 이미지를 조금 더 낫게 만들기 위해 일부 제약을 둘 수 있다.
- 컷아웃 영역 밖의 bbox 제거
- 컷아웃에 의해 잘린 나머지 bbox는 resize.
다음의 네 장의 이미지가 있고, 최종 이미지 크기를 256 x 256 으로 원한다고 할 때, 이 과정은 다음과 같이 동작합니다:

1. 이미지를 최종 이미지 크기(256 x 256)로 resize합니다. 이 단계는 여러 방식으로 수행할 수 있지만, 이미지의 종횡비를 구한 뒤 수동으로 resize할 수 있습니다. 이 종횡비는 bbox를 resize할 때 중요합니다. bbox도 이미지가 resize된 같은 비율로 resize해야하기 때문입니다.

모든 이미지를 하나로 결합합니다. 이를 위해, 3x512x512 모양의 0으로 채운 tensor를 만들고, 각 이미지를 각 코너에 오버레이합니다. 아래의 이미지에서 보듯 bbox들이 엉망이므로, 정확한 위치로 이동시킵니다.

3. bbox를 이동하는 것은 꽤 쉽습니다:
- 좌상단 이미지의 바운딩 박스는 이동 필요 없음
- 우상단 이미지의 바운딩 박스는 오른쪽으로 256만큼 이동
- 좌하단은 아래로 256픽셀 이동
- 우하단은 아래로 256, 오른쪽으로 256 이동
bbox를 256만큼 이동하려면, bbox 배열의 x 또는 y 값에 256을 더하면 됩니다.

4. 이미지의 무작위 컷아웃을 수행합니다. 이미지 어디에서나 무작위 컷아웃을 하게 두면, 컷아웃이 주로 한 두개의 이미지만을 포함하게 되는 문제가 있습니다. 하지만 우리는 네 이미지 모두가 포함되길 원합니다. 이를 위해, 최종 이미지 차원의 제곱근 범위(예: 16~240) 안 어디에서나 컷아웃을 선택할 수 있습니다. 이는 해당 글의 저자가 수동으로 설정한 조건으로, 해당 조건이 다소 작을 수 있습니다. 따라서 원하는 조건을 찾을 때까지 값의 제약을 바꿔가며 실험할 수 있습니다.
해당 글의 저자가 컷아웃을 만든 방식은 다음과 같습니다:
최종 이미지 차원의 제곱근(16)과 현재 결합 이미지 차원의 절반 사이에서 무작위 점을 골라 컷아웃의 좌상단 코너로 사용합니다. 그 다음 이 점에 256을 더해 컷아웃의 우하단 위치를 얻습니다. 이렇게 하면, 컷아웃이 최대 이미지 차원을 넘지 않고, 우리가 원하는 경계 안에 머무르게 됩니다.

5. 컷아웃 밖의 bbox를 제거합니다. 대부분의 bbox가 컷아웃 영역 밖에 있습니다. 이 문제를 다루기 위해, 먼저 컷아웃 밖의 bbox를 모두 제거하되, 조금이라도 컷아웃 안에 들어오는 박스들은 남겨둡니다.

하지만 여전히 컷아웃 밖에 일부 bbox가 남아있음을 볼 수 있습니다. 이들을 아예 없애버릴 수도 있지만, 그 방식의 문제는 모델이 우리가 원하는 바를 제대로 학습하지 못한다는 점입니다. 우리는 모델이 서로 다른 물체를 구분하기 위해 다양한 특징을 학습하길 원하므로, 컷아웃에 완전히 들어오지 않더라도 남겨둘 필요가 있습니다.
6. 컷아웃 내부에 남은 모든 bbox를 resize합니다. 남은 bbox들을 처리하기 위해, 이들을 컷아웃 내부로 이동시키고, 각 박스를 이동한 만큼 리사이즈합니다. 최종 결과는 아래와 같이 보입니다:

한편, 아주 작은 bbox들(예: 좌상단의 샌드위치)도 이미지에 보존될 수 있습니다. 이 물체는 일반적인 샌드위치가 가진 모든 특징을 담고 있지 않기 때문에, 모델이 이를 샌드위치로 인식하려면 더 강한 일반화 능력이 필요합니다.
Mixup
Mixup은 원래 분류(classification) 작업을 위해 만들어졌지만, 객체 탐지(object detection)에서도 여전히 매우 잘 작동합니다. Mixup은 기본적으로 가중치 파라미터 λ에 따라 두 이미지를 평균내는 방식입니다. 보다 형식적으로, 논문은 Mixup을 다음 두 개의 수식으로 정의합니다:
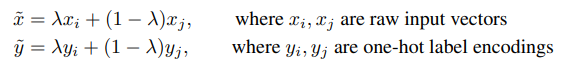
따라서, 두 이미지 x_i와 x_j를 결합하여 출력 이미지 x_tilde를 만들 수 있습니다. 다만, 이 증강은 레이블 할당을 염두에 두고 고안되었기 때문에, 원-핫 클래스 임베딩도 함께 평균합니다. 한편, 우리의 과제는 bbox와 관련 있으므로, bbox를 서로 평균내는 대신, 두 이미지의 주석(annotation)을 하나로 결합하기만 합니다. 즉, 모든 bbox들을 동일한 리스트로 합쳐 두 이미지의 모든 박스가 결합된 이미지에도 모두 속한다는 것을 나타냅니다.
논문에서는 λ 파라미터를 Beta 분포에서 샘플링할 것을 제안합니다:

논문은 alpha값을 0.2, 0.3, 0.4로 실험한 결과를 보여주는데, 해당 글의 저자가 직접해본 결과 평균이 0이나 1에 가까운 극단으로 치우치는 경향이 있었습니다. 이는 두 이미지를 진짜 평균한 결과라기 보다는 한쪽 이미지에 잡음이 조금 섞인 것처럼 보이는 결과가 된다는 뜻입니다. 온라인상에서는 alpha = 1.5가 더 잘 동작한다는 것이 나와있고, 저자는 더 나은 평균 이미지가 나왔다고 주장합니다.
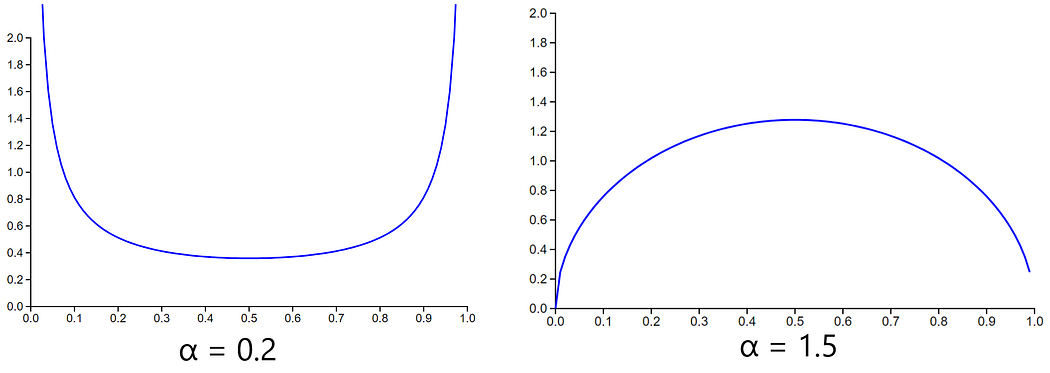
alpha = 1.5인 Beta 분포는 0.5 근처 값을 선호하는 반면, alpha = 0.2인 분포는 0과 1 근처 값을 선호하는 것으로 보여집니다.
Mixup의 결과는 다음과 같습니다:

객체 탐지에 Mixup을 구현하는 것은 어렵지 않고 아래의 몇 가지 기본 단계만을 필요로 합니다:
- 이미지를 동일한 크기로 리사이즈
- Beta 분포에서 λ 값을 샘플링
- 이미지 1의 모든 값을 λ만큼 곱함
- 이미지 2의 모든 값을 1−λ만큼 곱함
- 두 이미지를 더해 최종 이미지를 만듦
- 주석(annotations)을 결합해 / 최종 주석을 만듦
Mixup과 Mosaic은 YOLOX가 사용하는 두 가지 핵심 증강입니다. 해당 글이 YOLOX 동작에 관한 마지막 글입니다.