
https://huggingface.co/blog/moe#what-is-a-mixture-of-experts-moe
Mixture of Experts Explained
Chinchilla paper actually shows that for a fixed compute budget, it is better to train a smaller model on more data rather than training a larger model for fewer steps.
huggingface.co
What is a Mixture of Experts(MoE)?
일반적으로 모델의 규모(scale)은 더 나은 모델을 만들기 위한 가장 중요한 요소입니다. 만약 고정된 컴퓨터 예산이 주어졌을 때, 더 나은 모델을 만들고 싶다면, 큰 모델을 더 적은 단계(steps)로 훈련하는 것이 더 작은 모델을 많은 단계로 훈련하는 것 보다 더 낫습니다: 2024.12.31 - [[Deep daiv.]/[NLP]] - [Deep daiv.] NLP, 논문 리뷰 - Scaling Laws for Neural Language Models
[Deep daiv.] NLP, 논문 리뷰 - Scaling Laws for Neural Language Models
https://arxiv.org/abs/2001.08361 Scaling Laws for Neural Language ModelsWe study empirical scaling laws for language model performance on the cross-entropy loss. The loss scales as a power-law with model size, dataset size, and the amount of compute used
hw-hk.tistory.com
MoE(Mixture of Experts)는 dense 모델과 동일한 컴퓨팅 예산이 주어졌을 때, 훨씬 더 수월하게 scaling up 할 수 있도록 합니다. 즉, MoE 모델은 일반적인 dense 모델과 동일한 품질을 사전 훈련동안 훨씬 빠르게 달성할 수 있습니다. MoE는 transformer models을 기준으로 다음의 두 가지 요소로 구성됩니다:
- Sparse MoE layers: Transformer에서 dense FFN(feed forward network) 계층들 대신에 sparse MoE 계층들이 사용됩니다. MoE 계층은 특정 수의 "전문가들"(예: 8개)을 가지며, 여기서 각 전문가들은 하나의 신경망을 의미합니다(이때의 신경망은 FFN을 말하지만, 때로는 더 복잡한 네트워크이거나 MoE 그 자체일 수도 있습니다).
- A gete network ot router: 이것은 어떤 토큰들이 어떤 전문가에게 보내질지를 결정합니다. 예를 들어 아래의 이미지에서, 토큰 "More"은 두 번째 전문가(FFN)에게 보내지고, 토큰 "Parameters"는 첫 번째 네트워크로 보내집니다. 이때 반드시 하나의 네트워크만 통과하지 않고, 하나 이상의 전문가에게 토큰을 보낼 수도 있습니다. 어떻게 토큰을 전문가들에게 라우팅할지는 MoE를 다룰 때 매우 중요하며, router는 학습 가능한 파라미터로서 네트워크의 나머지 부분들과 사전 훈련됩니다.

정리하자면, Transformer에서 MoE는 모든 FFN 계층을 대체하며, MoE는 gate network와 특정 수의 전문가들로 구성됩니다. 비록 MoE들이 밀집(dense) 모델들에 비해 효율적인 사전 훈련과 더 빠른 추론같은 다양한 이점들을 제공하지만 다음과 같은 challenges들이 존재합니다:
- Training: MoE들은 연산 효율적인 사전 훈련을 가능하게 하지만, 다음과 같은 이유로 fine-tuning시에 일반화나 과적합에 대한 문제가 존재합니다:
- Routing의 불안정성으로 인해 일반화에 문제가 있을 수 있습니다. 사전 훈련 때는 다양한 주제(뉴스, 코드, 소설 등)를 배워서 라우터가 전문가들에게 골고루 일을 시켰지만, fine-tuning 단계에서 특정 주제(예: 코딩)에만 데이터가 쏠린다면(distribution shift), 모델 전체의 능력을 활용하지 못하고, 일부 전문가만 편협하게 학습되어 일반화가 약해질 수 있습니다.
- 혹은 라우터가 특정 전문가(예: expert 1, 2)에만 계속 데이터를 보낸다면, 특정 전문가는 계속 학습되는 반면, 나머지 전문가는 학습의 기회를 얻지 못하고 도태(starvation)됩니다. 이렇게 되면 라우터는 모델의 최고의 성능을 내기 위해 학습되므로, 점점 라우팅이 학습이 된 전문가 쪽으로 쏠리게 되어 모델의 전체 능력을 사용하지 못하게 됩니다.
- 한편, 일반적인 밀집(dense) 모델은 모든 데이터가 모든 파라미터를 업데이트합니다. 하지만, MoE는 데이터마다 업데이트되는 파라미터가 다릅니다. fine-tuning dataset 자체가 작은데, 그 마저도 여러명의 전문가들이 나눠서 학습해야 하므로, 전문가 개개인이 학습할 데이터의 양이 절대적으로 부족해져서, 학습이 충분히 되지 않거나(Underfitting), 소수의 샘플에 과적합(Overfitting)될 수 있습니다.
- Inference: 비록 MoE가 많은 파라미터들을 가질지라도, 그것들 중 일부만이 추론에 사용됩니다. 이는 동일한 수의 파라미터를 가진 밀집(dense) 모델에 비해 훨씬 더 빠른 추론을 가능하게 합니다. 하지만, 모든 파라미터들은 RAM에 로드되어야 하며, 그래서 메모리 요구사항이 높습니다. 예를 들어, Mixtral 8x7B 같은 MoE가 주어졌을 때, 47B 파라미터 모델을 수용할 충분한 VRAM이 필요합니다(왜 8x7=56B가 아니라 47B일까요? 이는 FFN 계층만이 개별 전문가들로 취급되며, 나머지 모듈들을 전문가들이 서로 공유하기 때문에, 모든 파라미터에 대해서 x8을 해야하는건 아닙니다).
A Brief History of MoEs
MoE의 뿌리는 1991년 논문 https://www.cs.toronto.edu/~hinton/absps/jjnh91.pdf에서 나옵니다. 해당 아이디어는 앙상블 아디이어와 유사하며, 별도의 네트워크들로 구성된 전문가들은 서로 다른 입력 공간에서 전문화되어, 각각의 네트워크들은 훈련 데이터들의 서로 다른 subset들을 처리합니다. 이때 전문가에 대한 선택, 즉 gating network는 각 전문가에 대한 가중치를 결정하며, 훈련하는 동안 전문가들과 gating network 모두 훈련됩니다.
그 후, 2010년에서 2015년 사이에, 다음의 두 가지 연구 분야들이 이후의 MoE 발전에 기여했습니다:
- Experts as components: 전통적인 MoE에서는 전체 시스템 자체가 gating network와 다수의 전문가로 구성됩니다. 하지만, https://arxiv.org/abs/1312.4314는 더 깊은 네트워크들의 구성 요소로서의 MoE를 탐구합니다. 이것은 다층 네트워크 내의 계층들로서 MoE들을 갖는 것을 허용하며, 모델이 거대해지면서 동시에 효율적인 모델이 되는 것을 가능하게 합니다.
- Conditional Computation: 전통적인 네트워크는 모든 입력들이 모든 계층들을 통과하여 모든 입력 데이터를 처리합니다. 하지만, 이때 Yoshua Bengio는 입력 토큰에 기반하여 구성 요소들을 동적으로 활성화하거나 비활성화하는 접근법들을 연구했으며, 현대의 MoE에서의 gating network의 기반이 됩니다.
위와 같은 연구들은 NLP에서 MoE를 사용하는 쪽으로 이끌었습니다. Shazeer et al., 2017은 이 아이디어를 LSTM으로 확장했습니다. 이는 sparsity를 도입함으로써 높은 규모에서도 매우 빠른 추론을 허용한 것입니다:

What is Sparsity?
sparsity는 conditional computation의 아이디어를 사용합니다. dense 모델들에서는 모든 파라미터가 모든 입력들에 대해 사용되는 반면, sparsity는 전체 시스템의 일부 부분들만 실행하도록 허용합니다. 해당 아이디어를 통해 모델의 크기를 연산을 크게 증가시키지 않고 확장할 수 있었으며, 이는 MoE 계층에서 수천 명의 전문가들이 사용되는 것으로 이어졌습니다. 하지만 이는 몇 가지 challenges들을 만듭니다.
예를 들어, 큰 배치 크기들이 보통 성능을 위해 더 낫지만, MoE들에서의 배치 크기는 데이터들이 활성화 된 전문가들을 통과할 때, 실질적으로 줄어듭니다. 만약 배치 입력이 10개의 토큰들로 구성된다면, 5개의 토큰들은 하나의 전문가에, 나머지 5개의 토큰들은 나머지 5명의 전문가들에 할당될 수 있으며, 이는 고르지 않은 배치 크기들과 underutilization으로 이어집니다.
이를 어떻게 해결할 수 있을까요? 어떤 전문가(E)들에게 입력의 일부를 보낼지 말지를 결정하는 것은 학습된 gating network(G) 입니다:

위와 같은 설정(가중합)에서는 모든 전문가들은 모든 입력들에 대해 실행됩니다. 하지만, 만약 G가 0이라면 어떻게 될까요? 만약 그런 경우라면, 각각의 전문가 연산들을 계산할 필요가 없으며 따라서 연산을 절약할 수 있습니다. 이때 gating network는 무엇일까요? 일반적으로는 softmax함수를 갖는 단순한 네트워크를 사용합니다:

위 네트워크는 입력을 어느 전문가에게 보낼지를 학습합니다. 한편, Shazeer는 또 다른 gating network를 연구했습니다. 이는 Noisy Top-k gating입니다. 해당 방법은 약간의 노이즈를 적용한 후, top-k개의 값들을 이용하는 것입니다:
1) 우선 노이즈를 적용합니다:

2) 오직 상위 k개만 선택합니다:

3) 소프트맥스를 적용합니다:

이를 통해 충분히 낮은 k(예: 1개 또는 2개)를 사용함으로써, 훨씬 더 빠르게 훈련하고 추론을 실행할 수 있습니다. 그렇다면 왜 노이즈를 더할까요? 이는 load balancing때문입니다.
Load balancing tokens for MoEs
이전에 얘기한 바와 같이, 만약 모든 토큰들이 단지 몇몇의 인기 있는 전문가들에게 보내진다면, 그것은 훈련을 비효율적으로 만들 것입니다. 일반적인 MoE 훈련에서, gating network는 대개 똑같은 소수의 전문가들을 활성화하는 것으로 수렴합니다. 이것을 self-reinforces라고 합니다. 선호되는 전문가들이 더 빨리 훈련되고, 따라서 더 많이 선택되는 것입니다. 이를 완화하기 위해, auxiliary loss가 추가될 수 있습니다. 해당 loss는 모든 전문가들이 대략적으로 동등한 수의 훈련 예제를 받을 수 있도록 장려합니다.
MoEs and Transformers
Transformer는 파라미터 수를 늘려 성능을 향상시킨 매우 명확한 사례입니다. 구글은 MoE를 적용한 GShard를 통해 600B 이상으로 transformer를 확장했습니다. GShard는 하나 건너 하나씩 FFN 대신 Top-2 gating을 사용하는 MoE 계층을 encoder와 decoder에 사용합니다:
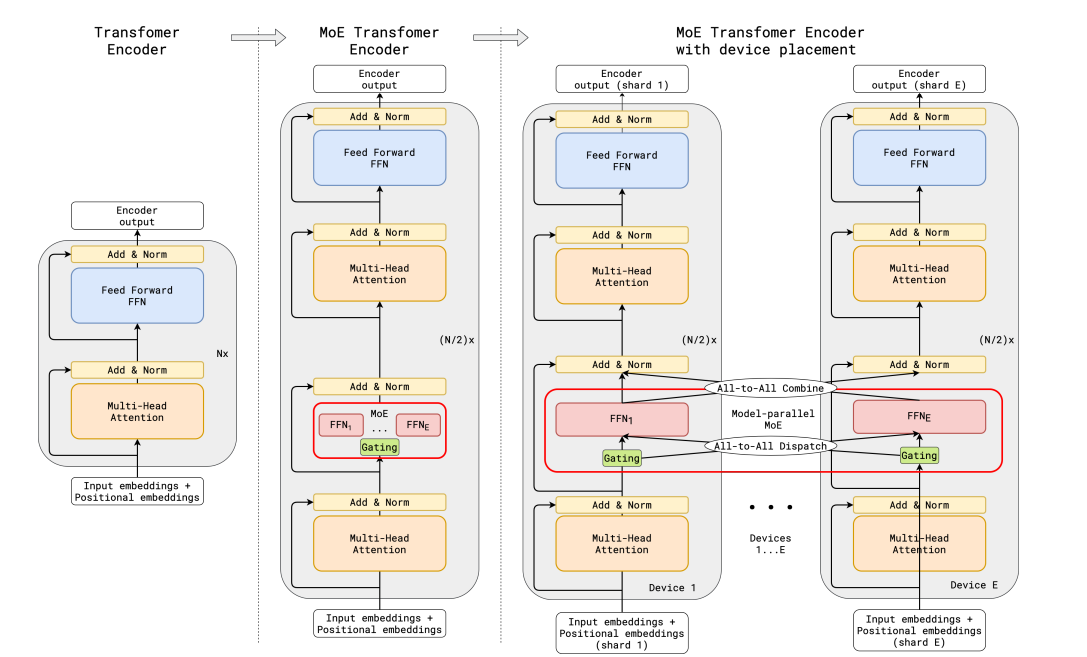
이는 대규모 컴퓨팅에서 꽤 유익한데, 다중 장치로 확장할 경우, MoE 계층은 장치들에 걸쳐 공유되는 반면, 모든 다른 계층들은 복제되기 때문입니다. 자세한 내용은 이후 Making MoEs go brrr에서 서술합니다.
큰 규모에서 균형잡힌 부하와 효율성을 유지하기 위해, GShard의 저자들은 앞서 논의한 auxiliary loss를 포함하여 몇 가지 변경사항들을 적용했습니다:
- Random Routing: top-2 설정에서, top-1 전문가는 deterministic하게 선택하지만, top-2 전문가는 가중치에 비례하는 확률로 선택합니다.
- Expert capacity: 얼마나 많은 토큰들이 한 전문가에 의해 처리될 수 있는지에 대한 임계값을 설정할 수 있습니다. 만약 두 전문가들이 용량에 도달하면, 그 토큰은 넘친것으로 간주되고, residual connection을 통해 다음 계층으로 보내집니다(혹은 아예 버려집니다). 그렇다면 왜 expert capacity가 필요할까요? 모든 텐서들의 shape이 컴파일 시간에 정적으로 결정되지만, gating network를 통해서 runtime에 얼마나 많은 토큰들이 각 전문가들에 갈지 결정되기 때문에, 미리 용량을 고정할 필요가 있었습니다.
Switch Transformers
비록 MoE들이 많은 가능성들을 보여주었지만, 그것들은 훈련 및 fine-tuning 불안정성들로 어려움을 겪습니다. 이때 switch transformer는 해당 주제를 깊게 파고드는 연구였습니다. 해당 저자들은 GShard에서처럼, FFN 계층을 MoE 계층으로 교체합니다. 이때 MoE 계층은 두 개의 입력들을 받으며, 4명의 전문가들이 존재하는 switch transformer 계층입니다. 적어도 두 명의 전문가를 사용한다는 초기 아이디어와 대조적으로, switch transformer는 그것보다 단순화된 단일 전문가(single-expert) 전략을 사용합니다.
Note: 두 개의 입력을 받는다는 것은 어떤 의미인가? 이는 MoE가 서로 다른 데이터를 동시에(parallel)하게 처리할 수 있다는 것을 보여주는 예시입니다(실제로는 1,024개, 2,048개의 토큰이 한 번에 들어오고, 수백 명의 전문가에게 흩뿌려져서 동시에 처리됩니다). 예를 들어, MoE에 "I love"라는 두 토큰이 switch transformer 계층에 도착하면, "I"는 전문가 A에게, "love"는 전문가 B에게 처리되며, 이 과정은 동시에 일어납니다. 즉, 배치 안에 들어있는 여러 토큰들이 라우터에 의해 쪼개져서, 서로 다른 전문가에게 배달되어 각자 따로따로 처리된다는 뜻입니다.
다음은 switch transformer layer의 그림입니다:

해당 접근 방법들은 다음과 같은 효과를 갖습니다:
- 라우터의 연산이 줄어듭니다.
- 각 전문가의 배치 크기가 적어도 절반으로 줄어듭니다.
- 이 말은 이전 방식(Top-2 gating)과 비교했을 때 일이 절반으로 줄어든다는 뜻입니다. 기존의 방식은 토큰 하나가 들어오면, 가장 똑똑한 전문가 2명을 골라서 둘 다에게 일을 시킵니다. 하지만 switch transformer는 토큰 하나당 전문가 1명에게만 보냅니다. 즉, 기존에는 한 데이터당 2번씩 처리하던 것을 1번만 처리하게 바꿨으므로, 전문가 개개인이 처리해야할 데이터 묶음(배치)의 크기가 절반으로 줄어든다는 것입니다. 덕분이 속도가 빨라질 수 있습니다.
- 통신 비용(Communication costs)이 줄어듭니다.
- MoE에서의 통신 비용은 데이터를 이쪽 GPU에서 저쪽 GPU로 옮기는 데 걸리는 시간과 자원을 의미합니다. 이는 MoE에서 특히 중요한 문제인데, 일반적인 dense 모델은 크기가 작으면 GPU 하나에 다 들어갈 수 있습니다. 하지만 MoE는 파라미터 수가 매우 많기 때문에 여러 대의 GPU에 쪼개서 저장해야 합니다. 예를 들어, GPU A는 expert 1, 2, 3, 4와 라우터를 가지고 있으며, GPU B는 expert 5, 6, 7, 8을 가지고 있다고 했을 때,
- 라우터에서 입력 토큰을 expert 7번이 처리하라고 판단한다면, GPU A는 하던 일을 멈추고, 이 토큰 데이터를 케이블을 통해 GPU B로 전송해야 합니다. 그 후 GPU B에서 계산을 마치면, 원래 주인이던 GPU A로 결과를 돌려보내야하며, 이를 통신 비용이라고 합니다.
- 통신 비용은 이후에 언급한 내용들에 의해 줄어들 수 있습니다(정밀도 낮추기, 전문가 용량 제한, 단일 전문가 선택).
Switch transformer는 다음과 같은 공식을 통해 전문가 용량을 측정합니다:

우선 배치 내의 토큰 수를 전문가 수로 균등하게 나눕니다. 이때 만약 1보다 큰 capacity factor를 사용한다면, 이는 토큰들이 완벽하게 균형 잡히지 않을 때를 위한 버퍼를 제공하는 것입니다. 하지만 버퍼를 통해 용량을 늘리는 것은 더 비싼 inter-device 통신 비용으로 이어집니다. 따라서 trade-off를 반드시 고려해야합니다. 참고로 switch tranformer는 1-1.25의 capacity factor에서 잘 동작합니다.
Note: capacity는 컴파일 타임에 텐서의 shape을 결정합니다. 만약 capacity factor를 작게 두어서 텐서의 크기를 작게 두면, 장비들간의 통신 비용은 줄어들지만(이동하는 데이터의 크기가 작기 때문에), expert의 capacity를 넘어서는 token에 대해서는 skip(residual connection)되기 때문에 성능은 떨어집니다. 반면에 capacity factor를 크게 두어서 텐서를 크게 만들어놓으면, 어느정도의 불균형한 expert 호출에도 강건하게 overflow 없이 처리할 수 있어서 성능은 좋아지지만, 통신 비용이 늘어난다는 단점이 있습니다.
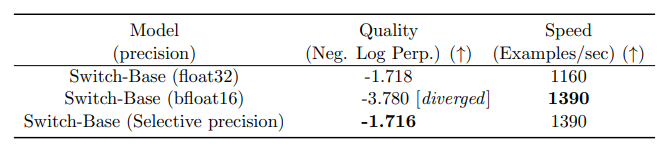
또한 Switch transformer의 저자들은 각 switch 계층에 대해 이전에 언급한 load balancing loss를 보조 손실로 두어 전체 모델 손실에 더해집니다. 이 손실은 균일한 라우팅을 장려하며 hyperparameter를 통해 가중치를 부여할 수 있도록 설계했습니다. Switch transformer의 저자들은 또한 selective precision을 적용합니다. expert들은 bfloat16으로 훈련하며, 나머지 연산들에 대해서는 전체 정밀도(full precision)를 사용합니다.
더 낮은 정밀도(bfloat16)는 프로세서들 간의 통신 비용, 연산 비용, 그리고 텐서를 저장하기 위한 메모리를 줄여줍니다. 사실 초기 실험에서는 전문가들과 라우터 모두 bfloat16으로 학습했지만, 불안정한 훈련을 산출했습니다. 이는 라우터 때문인데, 라우터가 지수 함수를 가지기 때문에, 더 높은 정밀도가 필요했기 때문입니다. 따라서 이런 불안정성을 완화하기 위해, 전체 정밀도를 라우터에 대해서 사용합니다:
Stabilizing training with router Z-loss
이전에 논의한 balancing loss는 불안정한 학습으로 이어질 수 있습니다. dropout과 같은 방법을 통해 안정화를 달성할 수는 있지만 이는 성능을 떨어뜨릴 수 있습니다. router z-loss는 ST-MoE에서 소개된 방법으로 품질 저하 없이 gating network로 들어가는 큰 logit들에 페널티를 줌으로써 훈련 안정성을 향상시킵니다. 이 손실은 값들의 절대적 크기가 더 작아지도록 유도하기 때문에, 값이 overflow가 발생할 확률이나 roundoff errors들이 줄어들 수 있습니다.
https://arxiv.org/abs/2202.08906
ST-MoE: Designing Stable and Transferable Sparse Expert Models
Scale has opened new frontiers in natural language processing -- but at a high cost. In response, Mixture-of-Experts (MoE) and Switch Transformers have been proposed as an energy efficient path to even larger and more capable language models. But advancing
arxiv.org
What does an expert learn?
ST-MoE의 저자들은 encoder experts들이 토큰들의 그룹이나 얕은 개념들에 전문화된다는 것을 확인했습니다. 또한 decoder experts들은 아예 덜 전문화되어 있었습니다. 즉, 사람들은 흔히 각 experts들이 하나의 언어나 문법적인 개념에 있어서 전문화되는 것을 상상할 수 있겠지만, 실제로는 정반대의 일이 일어나는 것입니다(token routing과 load balancing 때문에, 어떤 주어진 언어에 전문화된 단일 전문가는 나올 수 없습니다).

How does scaling the number of experts impact pretraining?
더 많은 전문가들은 향상된 샘플 효율성과 더 빠른 속도로 이어질 수 있지만, 전문가들의 개수가 늘어나면 늘어날 수록 (특히 256개나 512개가 넘어가면) 점점 이득이 줄어듭니다. 반대로 추론을 위해서는 더 많은 VRAM이 필요해집니다.
아래의 내용은 serving에 대한 내용입니다...
Fine-tuning MoEs
MoE를 fine-tuning할 때는 과적합에 신경써야 합니다. sparse model들은 dense model들에 비해 더 과적합되는 경향이 있기 때문입니다. 이를 해결하기 위해 전문가들 그 자체 내부에서 dropout을 사용하거나 또 다른 다양한 일반화 방법론을 적용해야 합니다. 한편 fine-tuning을 하는데 있어서 auxiliary loss를 사용할지 말지도 중요합니다. ST-MoE의 저자들은 aux loss를 끄고 fine-tuning을 실험했는데, 품질은 크게 영향받지 않았습니다.
Switch transformer에서는 sparse model이 dense model에 비해 다운스트림 태스크들에서, 특히 추론 중심(reasoning-heavy) 태스크들에서 더 못한다는 것을 발견했습니다. 반면에, 지식 중심의 태스크들에서(예: TriviaQA)는 sparse model이 매우 잘 수행하는 것을 발견했습니다. 또한 더 적은 수의 전문가들이 fine-tuning을 수행하는 데 있어서 도움이 되었다는 것과, 그 모델이 큰 태스크에 대해서는 잘했지만, 작은 태스크에 대해서는 잘 못했다는 것을 발견했습니다.

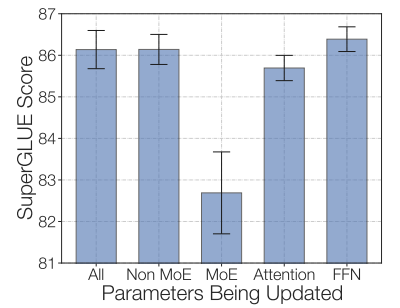
만약 non-expert 가중치를 얼리고, MoE 계층만을 업데이트를 한다면, 이는 거대한 성능 하락으로 이어집니다. 반면, MoE 계층만 얼리는 것은 모든 파라미터를 업데이트하는 것만큼이나 잘 동작했습니다. 이는 속도를 높이며, 메모리를 줄이는 것을 도울 수 있습니다. 이는 다소 직관에 반합니다. 파라미터의 80%가 MoE 계층들에 있기 때문입니다. 하지만, expert 계층은 매번 나타나는 것이 아니며, 각 토큰이 계층당 기껏해야 두 명의 전문가만을 보기 때문에, 다른 파라미터들을 업데이트하는 것보다, MoE 파라미터를 업데이트하는 것이 훨씬 더 적은 계층들에 영향을 미치는 것입니다.
sparse MoE를 fine-tuning할 때 고려해야할 마지막 부분은 하이퍼 파라미터 설정입니다. 일반적으로 sparse model들은 더 작은 배치 크기와 더 높은 학습률일 때 더 잘 학습이 되는 경향이 있습니다.

When to use sparse MoEs vs. dense models?
전문가들은 높은 처리량을 갖는 시나리오들에 대해 매우 유용합니다. 사전 훈련을 위해서 고정된 컴퓨팅 예산이 주어진 경우에도 sparse model이 효과적입니다. 반면 VRAM이 거의 없는 상황에서는 dense 모델이 더 나을 수 있습니다.
Making MoEs go brrr
초기의 MoE 연구는 MoE 계층들을 branching 설정으로 제시했고, 이는 느린 연산으로 이어졌습니다. GPU는 branching을 위해 설계되지 않았으며, 네트워크 대역폭이 병목이 되어 속도가 느려졌습니다.
Parallelism
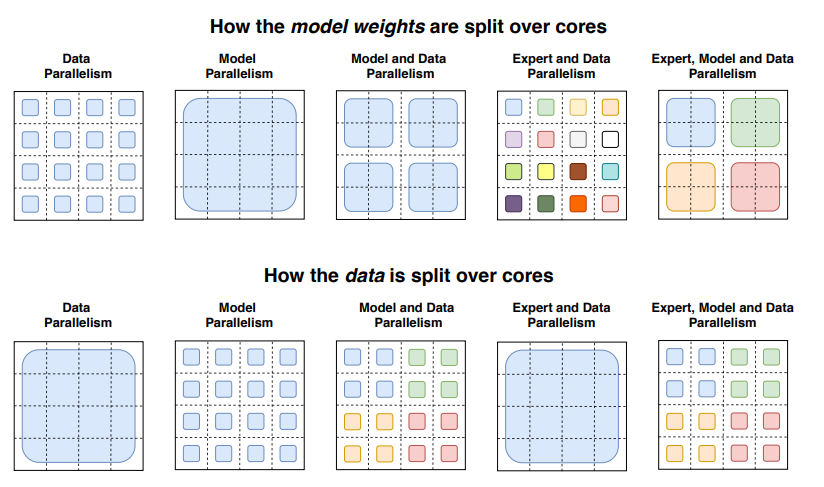
병렬화는 MoE의 속도를 높이기 위한 매우 좋은 방법입니다:
- Data parallelism: 똑같은 가중치들이 모든 코어에 걸쳐 복제되고, 데이터가 코어들에 걸쳐 분할됩니다.
- Model parallelism: 모델이 코어들에 걸쳐 분할되고, 데이터가 코어들에 걸쳐 복제됩니다.
- Model and data parallelism: 모델과 데이터들을 코어들에 걸쳐 분할할 수 있습니다.
- Expert parallelism: 전문가들이 서로 다른 worker들에 배치됩니다. 만약, 데이터 병렬화와 결합된다면, 각 코어는 서로 다른 전문가를 가지고, 데이터는 모든 코어에 걸쳐 분할됩니다.
Capacity Factor and communication costs
capacity factor를 늘리는 것은 품질을 높이지만, 통신 비용과 activations의 메모리는 증가시킬 수 있습니다. 만약 GPU의 통신이 느리다면, 작은 capacity factor를 사용해야합니다.
Serving Techniques
MoE를 배포할 때 가장 큰 단점은 거대한 수의 파라미터입니다. 이를 해결하기 위한 방법은 다음과 같습니다:
- Distillation: Switch tranformer의 저자들은 MoE를 다시 그것에 대응하는 dense 모델로 증류함으로써, 30-40%의 sparsity gain을 유지할 수 있었습니다.
- Routing modification: 전체 문장이나 태스크를 하나의 전문가에게 라우팅하도록 고정하는 것입니다.
- Aggregation of experts: 이 기법은 전문가들의 가중치를 병합하여, 추론 시 파라미터 수를 줄입니다.
More on efficient training
https://arxiv.org/abs/2505.03531
Faster MoE LLM Inference for Extremely Large Models
Sparse Mixture of Experts (MoE) large language models (LLMs) are gradually becoming the mainstream approach for ultra-large-scale models. Existing optimization efforts for MoE models have focused primarily on coarse-grained MoE architectures. With the emer
arxiv.org
https://arxiv.org/abs/2211.15841
MegaBlocks: Efficient Sparse Training with Mixture-of-Experts
We present MegaBlocks, a system for efficient Mixture-of-Experts (MoE) training on GPUs. Our system is motivated by the limitations of current frameworks, which restrict the dynamic routing in MoE layers to satisfy the constraints of existing software and
arxiv.org