
https://arxiv.org/abs/2401.04088
Mixtral of Experts
We introduce Mixtral 8x7B, a Sparse Mixture of Experts (SMoE) language model. Mixtral has the same architecture as Mistral 7B, with the difference that each layer is composed of 8 feedforward blocks (i.e. experts). For every token, at each layer, a router
arxiv.org
Mixtral of Experts.
Abstract.
Mixtral 8x7B는 Sparse Mixture of Experts, SMoE로 Mixtral 7B와 동일한 아키텍처를 공유하지만, 각 layer가 8개의 FFN 블록(experts)으로 구성된다는 차이점이 있습니다. 모든 토큰에 대해 router network는 현태 상태를 입력으로 받아 처리하고, 그 출력을 결합하기 위해 두 명의 experts를 선택합니다. 각 토큰은 오직 두 명의 experts만 거치지만, 선택된 experts는 매 타임스탭마다 달라질 수 있습니다. 결과적으로 각 토큰은 47B개의 파라미터에 접근할 수 있지만, inference 중에는 13B개의 활성 파라미터만을 사용합니다.
Introduction.
Mixtral은 대부분의 벤치마크에서 Llama2 70B, GPT-3.5 turbo를 능가하는 성능을 기록합니다. 모든 토큰에 대해 전체 파라미터의 일부만 사용하기 때문에, Mixtral은 낮은 배치 크기에서는 더 빠른 추론 속도를, 큰 배치에서는 더 높은 처리량을 제공합니다. 앞서 말했듯, Mixtral은 sparse MoE로서, FFN 블록이 8개의 서로 다른 파라미터 그룹 세트 중에서 선택하는 방식입니다.
모든 layer에서 모든 토큰에 대해, router network는 토큰을 처리하고 그 출력을 결합하기 위해 해당 그룹 중 두 개의 experts를 선택합니다. 이 기법은 모델이 토큰 당 전체 파라미터 세트의 일부만 사용하므로, 비용과 지연 시간을 제어하면서 모델의 파라미터 수를 늘릴 수 있게 합니다(전체 모델의 파라미터 수가 늘어도 실질적으로 추론 시에 activation되는 파라미터의 수는 작기 때문에, 효과적으로 파라미터의 수를 늘릴 수 있습니다).
(...MoE와 관련없는 얘기, 어떻게 학습했고, 어떻게 사용할 수 있는지...)
Architectural details.
주어진 입력 x에 대한 MoE 모듈의 출력은 전문가 네트워크들의 가중 합(weigthed sum)에 의해 결정됩니다. 거기서 가중치들은 gating network의 출력에 의해 주어집니다. 즉, n개의 expert networks {E0, E1, ..., En-1}가 주어졌을 때, experts layer의 출력은 다음과 같습니다:
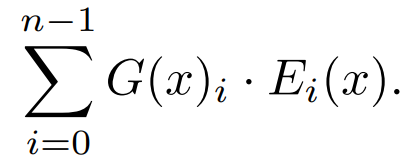
여기서 G(x)_i는 i번째 experts에 대한 gating network의 n차원 출력을 나타내며, E_i(x)는 i번째 experts network의 출력입니다. 만약 gating network가 sparse하다면, 게이트가 0인 전문가들의 출력을 계산하는 것을 피할 수 있습니다. G(x)를 구현하는 방법은 많지만, 단순하고 성능이 좋은 것은 Linear layer를 통해 나온 결과에 softmax를 취해 logit을 구한 후 top-k개의 logits들을 구하는 방법입니다:
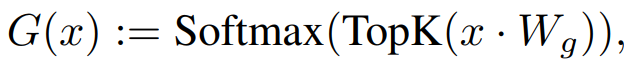
이때 사용하는 k는 각 토큰을 처리하기 위해 사용되는 연산의 양을 조절하는 하이퍼 파라미터입니다. 만약 k를 고정한 채로 n을 늘린다면, 연산 비용을 효과적으로 일정하게 유지하면서 모델의 파라미터 수를 늘릴 수 있습니다. 이는 모델의 총 파라미터 수와 개별 토큰을 처리하는 데 사용되는 파라미터의 수를 분리하여 생각할 수 있도록 합니다.
MoE 계층들은 고성능의 특화된 커널(kernel)을 이용하여 단일 GPU들 위에서 효율적으로 실행될 수 있습니다. 예를 들어, Megablocks(Gale et al., 2022)https://arxiv.org/abs/2211.15841에서의 MoE 계층은 FFN 연산들을 큰 sparse matrix multiplication으로 형 변환을 수행합니다.
MegaBlocks: Efficient Sparse Training with Mixture-of-Experts
We present MegaBlocks, a system for efficient Mixture-of-Experts (MoE) training on GPUs. Our system is motivated by the limitations of current frameworks, which restrict the dynamic routing in MoE layers to satisfy the constraints of existing software and
arxiv.org
또한 MoE의 각 experts들은 Model parallelism을 통해 혹은 Expert parallelism을 통해 다수의 GPU들에 분산될 수 있습니다. 이로 인해 MoE layer의 실행동안, 특정 expert에 의해 처리되도록 선택된 토큰들은 처리를 위해 대응하는 GPU로 routing되고, 그 expert의 출력은 원래 토큰 위치로 반환합니다. 이때 개별 GPU들에 걸쳐 workload를 고르게 분산시키는 것이 필수적이기 때문에, load balancing이 필수적입니다.
한편, transformer 모델에서, MoE layer는 토큰마다 독립적으로 적용되며 tranformer의 FFN sub-block들을 대체합니다. expert는 SwiGLU로 구성되며, experts의 activation 개수 K=2로 설정합니다. 이를 종합하여 출력 y에 대해 다음과 같이 계산됩니다:
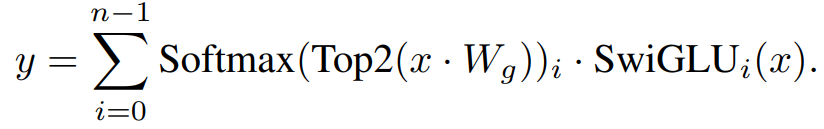
이는 모든 FFN sub-block들을 MoE layer로 대체한다는 것을 제외하면 GShard 아키텍처와 유사합니다(GShard는 하나 건너 블록마다 MoE layer를 사용합니다).
Results.

Mixtral은 다양한 벤치마크에 대해 Llama2 70B를 능가합니다. 특히 수학이나 코드에서 우수한 성능을 보입니다.

위 그림을 통해서 비용-성능 스펙트럼에서 Mixtral과 다른 모델들을 비교할 수 있습니다. Sparse MoE 모델로서, Mixtral은 각 토큰에 대해 오직 13B개의 활성 파라미터만을 사용합니다. 이는 5배 더 낮은 활성 파라미터들로, 대부분의 카테고리에 걸려 Llama2 70B를 능가합니다.
(... 이후 다른 모델들과의 비교, 아무튼 좋다는 뜻 ...)
Routing analysis.
해당 논문의 저자들은 훈련 동안 일부 experts들이 어떤 특정 도메인들에 전문화되었는지를 확인했지만, 주제에 기반한 전문가들의 배정에 대해서 명확한 패턴을 찾지 못했습니다. 예를 들어, 모든 계층에서 experts 배정의 분포는 매우 유사했습니다:

오직 DM Mathematics에 대해서만 미미하게 특이한 experts분포를 보입니다. 이는 router가 수학에 대해서 어떤 구조화된 행동을 보여준다는 것을 시사합니다. 아래의 그림 8.은 다른 도메인(코드, 수학, 영어)로부터의 텍스트 예시입니다:

위 그림은 파이썬의 "self"나 영어의 "Question" 같은 단어들이 종종 같은 expert를 통해 routing 된다는 것을 보여줍니다. 또한 코드의 들여쓰기(indentation) 토큰들을 항상 같은 전문가들에게 할당됩니다. 또한 연속적인 토큰들이 종종 같은 전문가들에게 할당된다는 것을 확인할 수 있습니다. 이는 어느 정도의 지역성이 있으며, expert parallelism을 수행할 때 높은 지역성을 가진 입력의 경우 특정 experts들로 쏠림이 발생할 가능성이 높다는 것을 시사합니다. 반대로 이 지역성은 caching을 위해 활용될 수도 있습니다.
https://arxiv.org/abs/2401.06066
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
In the era of large language models, Mixture-of-Experts (MoE) is a promising architecture for managing computational costs when scaling up model parameters. However, conventional MoE architectures like GShard, which activate the top-$K$ out of $N$ experts,
arxiv.org
DeepSeekMoE.
Abstract.
MoE는 계산 비용을 어느 정도로 관리하며 모델의 파라미터를 확장할 때(scaling up) 아주 좋은 아키텍처입니다. 그러나 GShard 같은 기존의 MoE 아키텍처들(N명의 experts 중 상위 K명을 활성화하는 아키텍처)은 완전히 전문화된 expert를 보장하는데 어려움을 겪습니다. 즉, 각 experts들이 겹치지 않고 완전히 전문화된 지식을 습득하는데 어려움을 겪는다는 것입니다. 이에 DeepSeekMoE는 다음과 같은 전략을 사용하여 위 문제를 해결합니다:
- experts들을 더 세밀하게 분할하고, 더 많은 experts들을 활성화함으로써 더 유연한 조합을 허용합니다.
- Ks명의 shared experts로 격리하여, 공통 지식을 포착합니다. 이를 통해 routed experts들 내의 중복을 완화합니다.
이는 DeepSeekMoE 2B가 GShard 2.9B와 동등한 성능을 달성하게 해주며, DeepSeekMoE 16B는 오직 40%의 연산량만으로 Llama2 7B와 동등한 성능을 낼 수 있게 해줍니다.
Introduction.
충분한 훈련 데이터가 존재할 때 파라미터의 개수를 증가시키거나 계산량을 늘리는 방향으로 언어 모델을 확장하는 것은 더 강력한 모델들을 만드는데 있어서 좋은 방법임은 최근의 연구와 관행들로 입증되었습니다. 그러나 모델을 극도로 큰 규모로 확장하려는 것은 지나치게 높은 계산 비용을 초래할 수 있습니다. 이를 고려할 때 MoE는 꽤 인기있는 해결책이 되어 왔습니다. 이는 계산 비용을 적당한 수준으로 유지하면서 파라미터 확장을 가능하게 하기 때문입니다.
기존의 MoE 아키텍처들은 transformer 내의 FFN들을 MoE layer로 대체합니다. 각 MoE layer는 다수의 experts들로 구성되며, 구조적으로는 FFN과 동일합니다. 각 토큰은 하나 또는 두 명의 experts들에 할당됩니다. 이때 해당 MoE layer는 다음과 같은 문제가 존재합니다:
- Knowledge Hybridity: 기존의 MoE 관행들은 제한된 수의 experts(예: 8 또는 16)을 사용하며, 이는 특정 전문가에게 많은 양의 지식을 학습하도록 유도합니다.
- Note: 기존의 MoE 모델들의 experts의 수는 세상에서 배워야하는 지식에 비하면 너무 작다는 뜻입니다. FFN은 지식을 저장하는 부분인데, 학습으로부터 해당 expert가 A에 대해서 배운 후, 다음 batch에서 B에 대해서 배운다면, 해당 FFN은 B에 대한 지식으로 tuning이 되어있을 것입니다. 이렇게 되면 A와 B에 대한 지식을 동시에 활용하지 못하게 되며, 이를 논문에서 "hard to utilize simultaneously"라고 표현한 것입니다.
- 따라서 DeepSeekMoE에서는 experts를 기존의 8-16명에서 64-128명으로 늘리는 것입니다. 이를 통해 서로 다른 지식이 섞이지 않고, 각자 맡은 분야만 확실하게 팔 수 있으며, 지식들을 동시에 활용할 수도 있습니다.
- Knowledge Redundancy: 서로 다른 전문가들에게 할당된 토큰이 여러 experts에 걸쳐있는 공통된 지식이 필요할 수 있습니다. 그렇게되면, 다수의 experts들이 공유된 지식을 습득하는 방향으로 수렴할 수 있고, 그들 각각의 파라미터 안에서 experts 파라미터들의 중복을 초래합니다.
이러한 문제들은 기존 MoE 방법들이 완전 전문화된 experts를 만드는데 실패하도록 만들며, MoE 모델들의 이론적 상한선에 해당하는 성능에 도달하는 것을 방해합니다. 이를 해결하기 위해 DeepSeekMoE는 다음과 같은 두 가지 전략을 사용합니다:
- Fine-Grained Expert Segmentation: 파라미터의 수를 일정하게 유지하면서(계산량은 유지), 전문가들을 FFN의 intermediate hidden dimension을 쪼갬으로써 더 세밀하게 분할합니다. 이를 통해 더 많은 세분화된 experts들을 사용할 수 있으며, 더 유연하고 적응력있는 experts들의 조합을 가능하게 합니다.
- Shared Expert Isolation: 특정 expert를 shared expert로서 동작하게 합니다. 이는 항상 활성화되며, 다양한 문맥들에 걸쳐 공통 지식을 포착하고 통합하는 것을 목표로 합니다. 이를 통해 routed experts들 사이의 지식 중복이 완화됩니다. 이는 파라미터의 효율성을 향상시키고, 각 routing된 전문가가 전문화될 수 있도록 유지합니다.
(... 다른 모델과의 성능 비교 ...)
Preliminaries: MoE for Transformers
우선 일반적인 MoE 아키텍처에 대해 설명합니다. 다음은 Transformer 언어 모델에서 transformer block을 나타냅니다:

T는 sequence length를 , Self-Att()는 self-attention 모듈을, FFN()은 feed-forward 모듈을 말합니다(간결함을 위해서 layer norm은 생략합니다.). MoE 언어 모델을 구축하는 방법은 보통 transformer 내의 FFN들을 MoE layer로 대체하는 것입니다. MoE layer는 다수의 experts들로 구성되며, 거기서 각 experts들은 구조적으로 FFN과 동일합니다. 그 후 각 토큰은 한 명 또는 두 명의 experts에게 할당됩니다. 만약 l-th FFN이 MoE로 대체된다면, hidden feature h는 다음과 같이 표현됩니다:

N은 experts의 수이며, FFN_i는 i-th experts를 말합니다. 이때 g가 sparse하다는 것이 중요합니다. 이는 N개중 오직 K개의 gate value들이 0이 아님을 의미합니다. 이는 MoE layer에서의 계산 효율성을 보장합니다. 즉, 각 토큰은 오직 K명의 experts들에게만 할당되고 계산됩니다.
DeepSeekMoE Architecture.

위 그림 2. 에서 보여지듯, DeepSeekMoE는 두 가지 주요 전략을 사용합니다: 1) fine-grained expert segmentation, 2) shared expert isolation.
Fine-Grained Expert Segmentation.
experts의 수가 제한된 시나리오에서, 특정 expert에게 할당된 토큰들은 다양한 유형의 지식을 포괄할 가능성이 더 높습니다(즉, 하나의 expert가 다양한 유형의 지식을 저장하고 있을 가능성이 experts의 수가 작으면 높다는 것을 의미). 결과적으로, 해당 토큰은 다른 유형의 지식들을 동시에 활용할 수 없게 됩니다. 그러나, 만약 각 토큰이 더 많은 experts들에게 routing될 수 있다면, 다양한 유형의 지식들이 각각 따로 학습될 수 있습니다. 이는 각 expert가 높은 수준의 전문화를 유지할 수 있으며, experts들에 걸쳐 더 집중된 지식 분포를 만들 수 있습니다.
이를 위해, experts의 파라미터 수와 계산 비용을 일정하게 유지하면서, experts들을 더 세밀하게 분할합니다. 이는 활성화된 expert들의 더 유연하고 적응력 있는 조합을 가능하게 합니다.
구체적으로는 그림2(a)에 보이는 전형적인 MoE 아키텍처 위에, 각 experts FFN의 hidden dimension의 차원을 1/m으로 줄임으로써 m개의 더 작은 experts들로 분할합니다. 이는 조합론적인 관점에서, experts들의 조합적 유연성을 실질적으로 향상시키는데, 예를 들어, N=16이라면, 전형적인 top-2 routing은 120가지의 가능한 조합을 만들 수 있는 반면, 각 expert에 대해 m=4라면(N=64, K=8), 44억개 이상의 잠재적 조합을 산출할 수 있습니다.
Shared Expert Isolation.
기존의 routing 전략에서는, 서로 다른 experts들에게 할당된 토큰들이 어떤 공통 지식이나 정보를 필요로 할 수 있습니다. 결과적으로, 이는 다수의 전문가들이 공유된 지식을 습득하는 방향으로 수렴하도록 합니다. 이는 expert parameter들의 중복을 초래합니다. 그러나, 만약 다양한 문맥들에 걸친 공통 지식을 포착하고 통합하는 데 전념하는 shared expert가 있다면, 다른 routed experts들 사이의 파라미터 중복은 완화될 수 있습니다.
이를 위해 추가적으로 Ks명의 experts들을 격리하여 shared expert로서 동작하도록 합니다. 이는 router 모듈과 관계없이, 각 토큰은 이 shared expert들에게 무조건 할당됩니다. 일정한 계산 비용을 유지하기 위해, 다른 routed experts들 중 활성화된 experts들의 수는 Ks만큼 감소됩니다:

Load Balance Consideration.
자동으로 학습된 routing 전략들은 load imbalance 문제에 직면할 수 있으며, 이는 두 가지 문제를 일으킬 수 있습니다:
- routing collapse: 이는 모델이 항상 오직 소수의 experts들만 선택하여 다른 experts들이 충분한 훈련을 받는 것을 막습니다.
- computation bottlenecks: 만약 experts들이 다수의 GPU에 분산되어 있다면, load imbalance는 연산 병목을 악화시킬 수 있습니다(하나의 GPU에 대해 computation이 쏠리고, 다른 GPU는 idle한 상황).
routing collapse를 막기 위해 expert-level balance loss를 사용합니다:

이에 더해 device-level balance loss를 사용합니다:

computation bottleneck을 완화하는 것을 목표로 한다면, expert-level balance는 강하게 지키는 것은 불필요합니다. load balance에 대한 과도한 제약은 모델의 성능을 저하하기 때문입니다. device-level balance loss는 장치들에 걸쳐 균형 잡힌 연산을 보장하는 것을 목표로 합니다. 실제로는 작은 expert-level balance loss factor를 사용하여 routing collapse 문제를 해결하며, 더 큰 수준의 device-level balance loss factor를 사용하여 장치들에 걸친 균형 잡힌 연산을 촉진합니다.
Validation Experiments.
(... 실험 설정 및 다른 모델과의 비교 ...)
Analysis on Expert Specialization.

위 그림은 추론 시, 가장 확률이 높은 상위 expert를 강제로 꺼버리고 성능 변화를 측정한 것입니다. DeepSeekMoE의 성능이 훨씬 급격하게 떨어졌는데, 이는 해당 expert가 가진 지식이 유일무이해서 다른 전문가로 대체가 안 된다는 뜻입니다. 즉, experts들이 각자의 영역에 고도로 특화되어 있음을 증명합니다(GShard는 성능 하락이 적었는데, 이는 experts들끼리 지식이 중복되어 있어 대체가 가능하다는 뜻입니다).

그림 5.는 활성화되는 routed experts의 수를 7개에서 3개까지 줄였을 때의 loss입니다. experts를 4개만 활성화해도 GShard(더 많은 expert parameters를 활성화)와 대등한 성능을 냅니다. 이는 DeepSeekMoE가 필요한 지식을 정확하게 가져옴을 나타냅니다.
(... scaling up에 대한 얘기 ...)