
해당 글은 건국대학교 김기천 교수님의 컴퓨터네트워크1 수업 내용을 정리한 글입니다.
Types of Errors
오류란, 송신측에서 0을 보냈는데 수신측에서 1로 받거나, 1을 보냈는데 0으로 받는 상황을 말합니다. 데이터 전송 시 발생하는 오류는 크게 두 가지가 존재합니다:
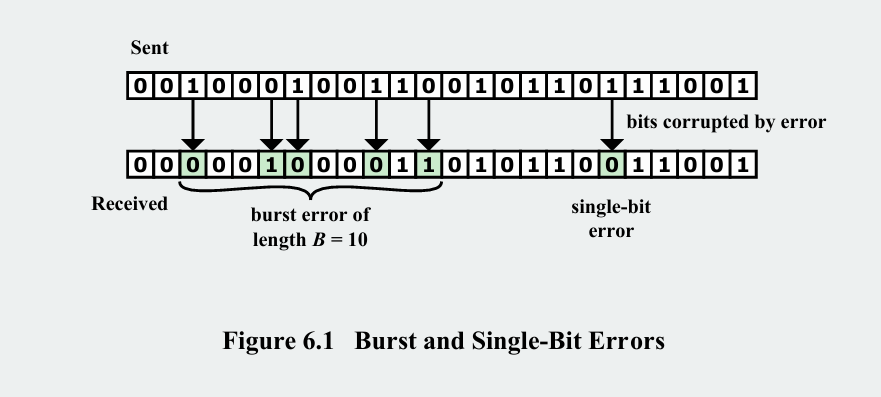
1) 단일 비트 오류(Single bit errors): 주변 다른 비트에는 영향을 주지 않고 오직 한 비트만 변경되는 고립된(isolated) 오류입니다. 주로 열 잡음과 같은 white noise 환경에서 발생할 수 있습니다.
2) 버스트 오류(Burst errors): 연속된 B개의 비트 구간 내에서 첫 번째 비트와 마지막 비트, 그리고 그 사이의 임의 개수 비트들이 손상되는 오류입니다. 예를 들어, 10bit burst error라고 해서 10비트가 전부 뒤집힌 것이 아니라, 10비트 구간의 시작과 끝 비트가 오류이고 그 사이는 멀쩡할 수도, 추가 오류가 존재할 수도 있습니다. 이는 순간적인 전압 상승과 같은 impulse noise나, 무선 통신 환경에서의 fading 현상(신호 세기 약해짐)에 의해 주로 발생합니다. 데이터 전송률(data rate)이 높을수록 burst error의 영향을 더 커질 수 있습니다.
실제 유선 및 무선 통신 환경에서는 단일 비트 오류 보단는 버스트 오류가 훨씬 더 일반적입니다. 따라서 대부분의 현대 오류 감지 코드(특히 CRC)는 이 버스트 오류를 감지하는 데 특화되어 있습니다.
Error detection
데이터는 frame이라는 비트의 연석된 시퀀스(덩어리) 단위로 전송됩니다:
Pb: 비트 오류율(BER, Bit Error Rate)입니다. 즉, 전송된 비트 하나가 오류 상태로 수신될 확률입니다.
P1: 하나의 프레임이 오류 없이 성공적으로 수신될 확률입니다.
P2: 오류 감지 알고리즘을 사용했음에도 불구하고, 수신측이 오류를 감지하지 못하는 프레임이 도착할 확률입니다.
P3: 오류 감지 알고리즘이 성공적으로 오류를 감지해낸 프레임이 도착할 확률입니다.
모든 오류 감지 기술의 목표는 P2를 0에 가깝게 만들고, 오류 발생 시 P3를 1에 가깝게 만드는 것입니다. P2가 발생하면 시스템은 데이터가 손상된 줄 모르고 사용하게 되어 심각한 문제를 일으킵니다. 당연하게도, Pb가 높아지거나 프레임의 길이(L)이 길어질수록, 프레임의 오류가 하나라도 포함할 확률이 높이지므로 P1은 감소합니다.
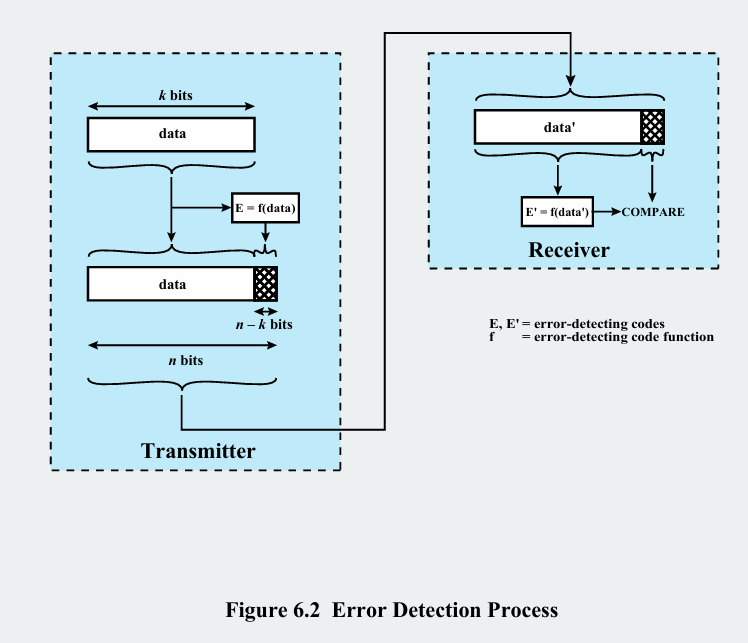
전송할 원본 데이터 k비트가 있습니다. 이는 미리 약속된 함수 f(오류 감지 알고리즘)를 사용하여 이 데이터로부터 오류 감지 코드(E)를 계산합니다(예: 체크섬, CRC값). 이 코드 E는 n-k 비트이며, 원본 데이터 뒤에 덧붙여져 총 n비트의 프레임을 구성해 전송합니다. 수신측은 n 비트 프레임을 수신하며, 수신한 데이터 부분(data')을 송신측과 똑같은 함수 f에 입력하여 새로운 오류 감지 코드 E'를 계산합니다. 그 후 프레임과 함꼐 실려온 E와 방금 계산한 E'을 비교합니다.
Parity Check
패리티 검사는 가장 간단하고 고전적인 오류 감지 방식입니다. 이는 데이터 블록 끝에 단 1비트의 패리티 비트를 추가하는 방식입니다:
1) 짝수 패리티(even parity): 데이터 비트와 패리티 비트를 모두 포함한 총 1의 개수가 짝수(even)가 되도록 패리티 비트(0 또는 1)를 정합니다. 주로 동기식 전송(synchronous transmission)에 사용됩니다. 예를 들어, 데이터가 10110이면, 패리티 비트는 1이 되어 10110"1"을 전송합니다.
2) 홀수 패리티(odd parity): 총 1의 개수가 홀수가 되도록 패리티 비트를 정합니다. 주로 비동기식 전송(asynchronous transmission)에 사용됩니다. 데이터가 10110이면, 패리티 비트는 0이 되어 10110"0"을 전송합니다.
만약, 2개, 4개, 6개 등 짝수 개의 비트에 동시에 오류가 발생하면, 1의 개수는 여전히 짝수(또는 홀수)를 유지하므로 오류를 전혀 감지할 수 없습니다(이는 P2의 시나리오 입니다).

위 그림은 1차원 패리티의 한계를 개선한 2차원 패리티 검사입니다. 이는 데이터 비트들을 2차원 행렬 형태로 배치한 후 각 행의 끝에 해당 행의 패리티 비트를 추가하고, 각 열의 끝에 해당 열의 패리티 비트를 추가합니다.
(b)의 경우는 모든 행과 열의 패리티가 정상인 상황입니다.
(c)는 단일 비트 오류로, 해당 비트가 속한 행의 패리티가 불일치 하고 열의 패리티도 불일치 하게 됩니다. 수신측은 오류가 발생한 행과 열의 교차점을 특정하여, 해당 비트를 다시 뒤집음으로써 오류를 수정(correction)할 수 있습니다.
(d)는 수정 불가능한 오류입니다. 2개 이상의 비트에 오류가 발생하면, 여러 행/열의 패리티가 깨져 오류를 '감지'할 수는 있지만, 정확한 오류 위치를 특정할 수 없어 '수정'은 불가능할 수 있습니다. 만약 4개의 오류가 직사각형 꼭짓점 형태로 발생하면 감지조차 할 수 없습니다.
The Internet Checksum
이는 IP, TCP, UDP 등 다수의 인터넷 표준 프로토콜에서 실제로 사용하는 오류 감지 방식입니다. 송신측은 데이터를 16비트 word 단위로 나누어, 모두 1의 보수 덧셈(두 수를 부호 없는 이진 정수처럼 더합니다. 그 후 carry가 발생하면 최하위 비트에 더해줍니다)으로 더합니다. 그리고 그 최종 합계의 1의 보수(비트 반전)를 구하여 프레임의 체크섬 필드에 저장합니다. 수신측은 프레임의ㅣ 모든 16비트 word(데이터 + 체크섬 필드까지 포함)를 1의 보수 덧셈으로 모두 더합니다. 만약 오류가 없었다면, 그 결과는 모든 비트가 1이 됩니다(FFFF).

Cyclic Redundancy Check(CRC)
CRC는 현대 통신에서 가장 널리 사용되고 강력한 오류 감지 코드 중 하나입니다. 송신측은 k비트의 원본 데이터 블록이 주어지면 (n-k) 비트의 FCS라는 것을 생성하여 데이터 뒤에 붙입니다(n=frame). 이 FCS는, 데이터와 FCS가 합쳐진 전체 프레임이 미리 정해진 어떤 수(약수)로 정확히 나누어 떨어지도록 수학적으로 계산된 값입니다. 수신측은 수신한 전체 프레임을 그 미리 정해진 수로 나눕니다. 만약 나머지가 0이면, 오류가 없는 것으로 간주합니다. 나머지가 0이 아니면 오류가 감지된 것입니다.
여기서 말하는 나눗셈과 미리 정해진 수는 일반적인 십진수 산술이 아닙니다. 미리 정해진 수는 생성 다항식(Generator Polynomial)이라고 부릅니다. 나눗셈은 modulo-2 산술에 기반한 다항식 나눗셈이며, 이는 하드웨어에서 XOR 연산으로 매우 빠르게 구현됩니다.
modulo-2 연산은 이진수 덧셈을 carry 없이 수행하는 것으로, 이는 논리 연산자인 XOR과 정확히 동일합니다. 한편, 다항식은 모든 비트열을 더미 변수 X에 대한 다항식으로 표현한 것을 말합니다. 비트가 1인 자리의 X의 거듭제곱 항만 남깁니다. 예를 들어, 11001은 X^4 + X^3 + X^0 으로 표현됩니다.

위 그림은 예시입니다. 데이터 D(X)에 FCS의 (최고) 비트 수(이 경우 5)만큼 0을 덧붙입니다(수학적으로 X^5를 곱하는 것). 이를 생성 다항식(generator polynomial) P(X)로 나눕니다. 나눗셈 과정에서 뺄셈은 XOR을 사용합니다. 이떄 발생하는 몫 Q(X)는 사용하지 않고 버립니다. 최종적으로 남는 나머지 R(X)가 바로 송신자가 데이터 뒤에 붙여 보낼 FCS가 됩니다(비트 열로 01110).

위 그림은 수신측에서 FCS를 통해 에러를 detection하는 과정까지 그림으로 나타낸 예시입니다. 수신측에서 전체 frame에 생성 다항식을 나누어서 얻은 나머지를 확인하며, 나머지가 00이므로 해당 frame은 에러가 없다고 판단할 수 있습니다.
Forward Error Correction
지금까지 다룬 오류 감지(detection)는 오류를 발견하면 해당 데이터를 버리고 재전송(retransmission)을 요구하는 방식(ARQ)이 일반적입니다. 하지만 무선 통신과 같은 환경에서는 두 가지 큰 문제가 있습니다:
1) 채널 품질이 나빠 BER이 매우 높습니다.
2) 위성 통신은 전파 지연(propagation delay)이 매우 깁니다.
따라서 이런 환경에서는 재전송 없이, 수신측이 받은 비트들만 가지고 스스로 오류를 수정(correction)할 필요가 있습니다. 이를 순방향 오류 정정(Forward Error Correction, FEC)이라고 합니다. k비트의 원본 데이터를 훨씬 더 많은 잉여 비트를 추가하여 n 비트(n>k)의 코드워드(codeword)로 매핑하여 전송합니다. 이 추가된 잉여 비트(정보)를 이용해 오류를 수정합니다.

송신측은 k비트 원본 데이터를 FEC 인코더 입력합니다. 인코더는 n 비트의 codeword를 생성하여 전송합니다. 수신측은 (오류가 포함될 수 있는) n 비트 codeword를 수신하여 FEC 디코더에 입력합니다. 디코더는
1) 오류가 없는 경우 원본 데이터(k-bit)를 복원하여 출력합니다.
2) 수정 가능한 오류의 경우 디코더가 codeword의 잉여 비트를 이용해 오류를 수정한 후, 원본 데이터를 복원하여 출력합니다.
3) 감지는 되지만 수정은 불가능한 오류의 경우는 폐기합니다.
Block Code Principles
FEC를 구현하는 block code의 성능을 정의하는 기본 원리는 다음과 같습니다:
1) Hamming distance: d(v1, v2)는 같은 길이(n-bit)의 두 이진 시퀀스 v1, v2에서 서로 다른 비트의 개수를 의미합니다. 예를 들어, v1 = 10110, v2 = 00010 이면, 첫 번째와 세 번째 비트가 다르므로 해밍거리는 2입니다. FEC 코드에서 유효한 codeword들 간의 최소 해밍 거리가 클수록, 더 많은 오류를 감지하고 수정할 수 있습니다(예: 최소 해밍 거리 = 3이면 1비트 오류 수정 또는 2비트 오류 감지가 가능합니다).
2) Redundancy: 원본 데이터 비트 k 대비 추가된 잉여 비트 n-k의 비율, 즉 (n-k) / k 입니다.
3) code rate: 전체 비트 n 대비 원본 데이터 비트 k의 비율, k / n 입니다. 이 값은 FEC를 위해 얼마나 많은 추가 대역폭이 필요한지를 나타냅니다. Rate 1/2코드는 k/n = 1/2라는 의미이며, 원본 데이터 1비트를 보내기 위해 총 2비트를 전송해야 함을 뜻합니다.

위 그림은 FEC를 사용하는 궁극적인 이유인 coding gaing을 보여줍니다. FEC를 사용하면 (비록 대역폭 오버헤드는 발생하지만) 훨씬 더 열악하고 잡음이 많은 채널 환경에서도, 코딩을 사용하지 않을 때와 동일한 수준의 높은 통신 신뢰도(낮은 BER)를 확보할 수 있습니다.
'[Konkuk Univ. 3rd] > [Computer Network1]' 카테고리의 다른 글
| [Computer Network1] 08 - Multiplexing (0) | 2025.12.04 |
|---|---|
| [Computer Network1] 07- Data Link Control Protocols (0) | 2025.11.06 |
| [Computer Network1] 05 - Signal Encoding Techniques (1) | 2025.10.11 |
| [Computer Network1] 04 - Transmission Media (0) | 2025.10.09 |
| [Computer Network1] 03 - Data Transmission (1) | 2025.10.04 |