
해당 글은 건국대학교 지서원 교수님의 컴퓨터 비전 수업 내용을 정리한 글입니다.
Perspective Projection.
원근 투영은 3차원 공간의 객체를 원근 투영 방식을 통해 2차원 이미지 평면(image plane)으로 변환하는 것을 말합니다. 이 과정에서 깊이 정보(depth info.)는 사라지며, 2차원 센서 배열의 각 지점은 입사광(incident light)을 기록합니다:

Image: 2d array of light.
디지털 이미지는 빛을 기록한 2차원 배열(2d array) 형태의 행렬로 정의할 수 있습니다. 그리고 해당 행렬을 구성하는 각각의 단일 지점을 픽셀(pixel)이라고 정의합니다.
하나의 pixel은 고유한 2차원 좌표를 가지며, 빛의 강도(amount of light)를 나타내는 값(intensity)을 보유합니다. pixel value가 클수록 밝은 상태(more light)를 의미하며, 값이 작을수록 어두운 상태(less light)를 의미합니다:

pixel value는 빛이 전혀 없는 0(검은색)부터 센서가 수용할 수 있는 최대 한계치(흰색) 사이로 제한됩니다. 데이터 표현 범위는 일반적으로 byte 단위에 맞춘 0에서 255 사이의 정수형 배열, 혹은 0에서 1 사이의 floating point 배열을 사용합니다.
How to record color?
색상을 기록하기 위해 전자기파 스펙트럼 중 400nm(보라색)에서 700nm(빨간색) 파장 대역에 해당하는 가시광선 영역을 활용합니다. color image는 빛의 삼원색인 RGB 모델을 기반으로 하며, 이는 3차원 색상 큐브(color cube) 형태로 도식화 할 수 있습니다:

이미지 센서는 입사광(incoming light)을 받아들일 때 bayer color pattern 필터층을 통과시켜 특정 픽셀마다 단일 색상(R, G, B 중 하나)의 빛 패턴만을 기록합니다:
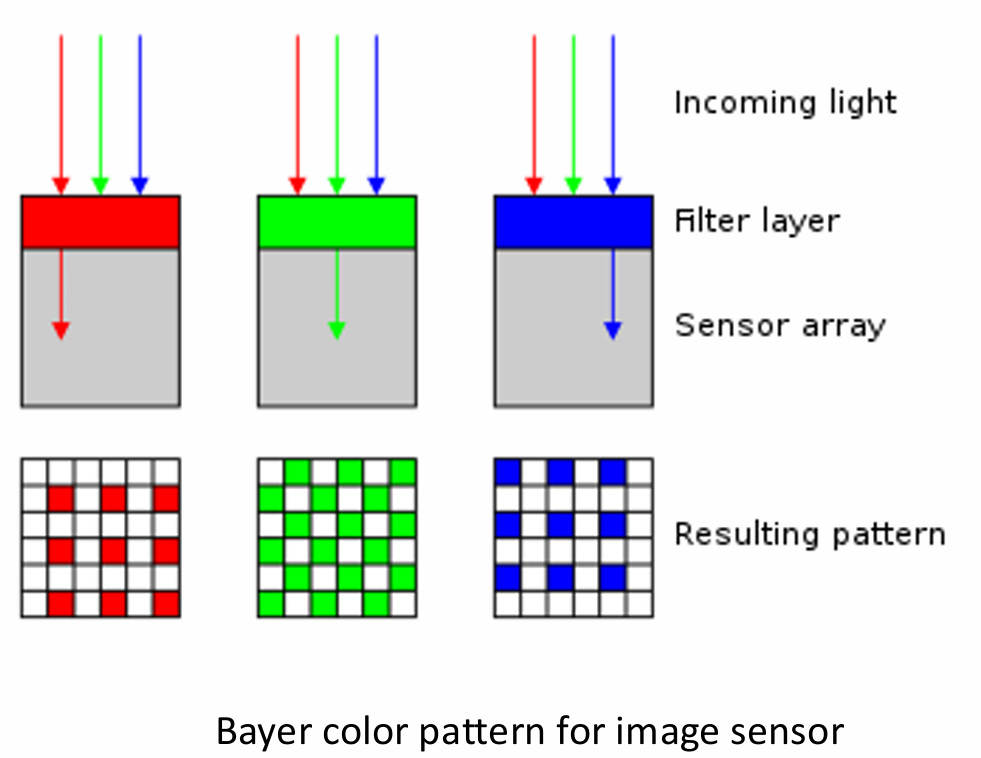
이러한 방식 때문에 RAW 카메라 파일 단계에서는 각 채널별로 누락된(missing) 정보가 존재합니다. 최종적인 color image를 생성하기 위해서는 보간(interpolation) 연산을 통해 비어있는 R, G, B 채널 정보를 유추하고 채워 넣습니다(이때 #G > #R, #B 인 것은 인간의 시각 인식을 고려한 것이며, 사람은 green에 대해서 더 민감합니다):

Color image: 3d tensor in color space.
color image는 2차원 형태의 색상 배열을 넘어, 색상 채널(channel) 축이 추가된 3차원 텐서(tensor)의 형태로 정의됩니다. 이미지는 red, green, blue의 개별 채널로 분리될 수 있으며, 분리된 각 채널은 intensity 값을 담은 독립적인 2차원 배열로 작동합니다:

How do computer store them?
컴퓨터의 물리적 메모리는 거대한 1차원 배열(1d array) 구조로 이루어져 있습니다. 따라서 2차원 이상의 tensor 데이터를 메모리에 저장할 때는 배열을 평면화하는 기준이 필요하며, 대표적으로 두 가지 방식을 사용합니다:
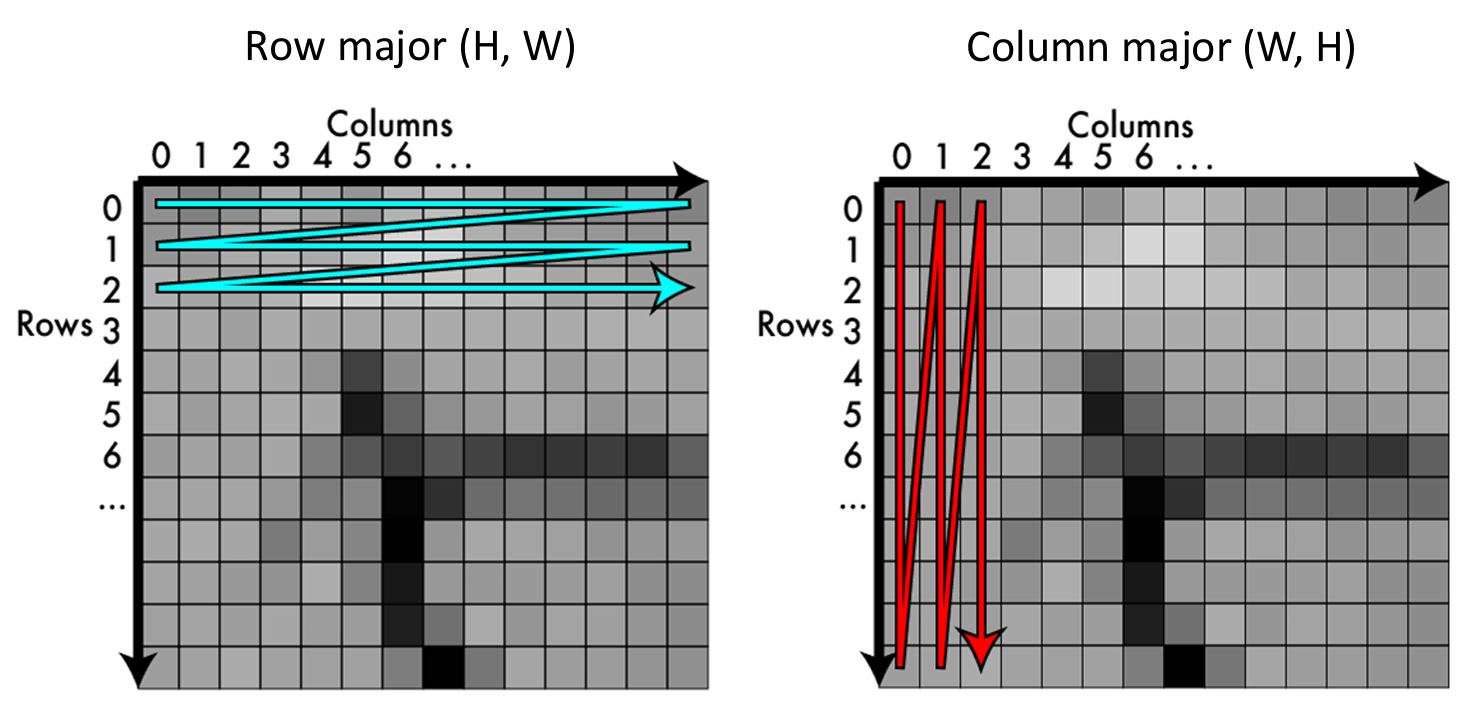
- 행 우선 방식(row major, HxW): 데이터를 행(rows) 방향을 따라 가로로 먼저 읽어 순차적으로 저장하는 방식입니다. 모든 width index를 방문하면 height index가 +1이 된다.
- 열 우선 방식(column major, WxH): 데이터을 열(columns) 방향을 따라 세로로 먼저 읽어 순차적으로 저장하는 방식입니다. 모든 height index를 방문하면, width index가 +1이 된다.
대부분의 프로그래밍 언어는 데이터를 메모리에 저장할 때 row major(HxW) 방식을 기본적으로 채택하고 있습니다. 한편 3d tensor인 color image를 메모리에 배치할 때 채널을 다루는 방식에 따라 두 가지 형태로 나눌 수 있습니다:

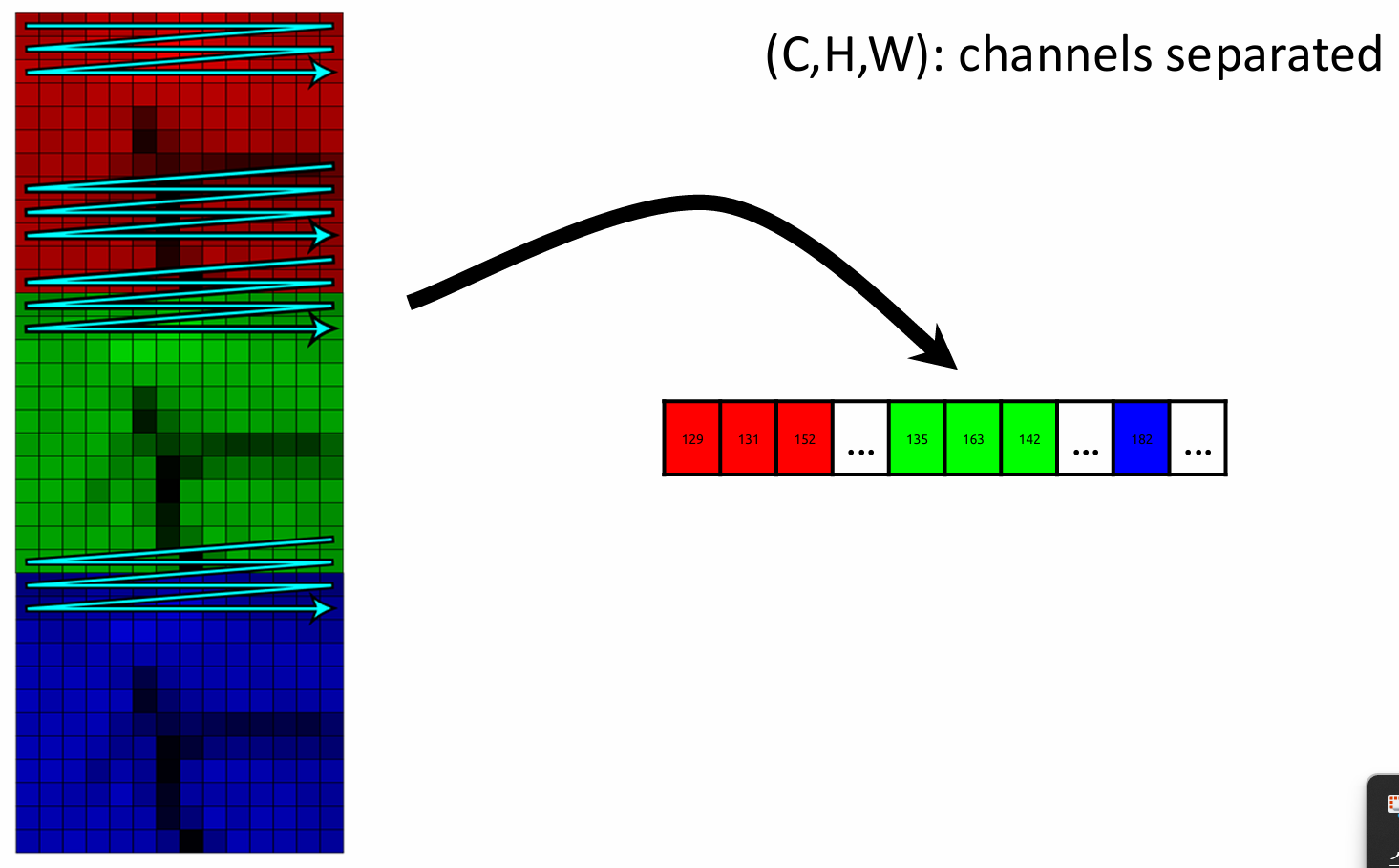
- (H,W,C) 구조 (interleaved): R, G, B 채널 값이 픽셀 단위로 교차되어 저장됩니다.
- (C,H,W) 구조 (seperated): 채널 별로 데이터가 완전히 분리되어 저장됩니다.
Image as a 2D function.

이미지는 수학적으로 2차원 함수(f(x,y))로 정의할 수 있습니다. 이러한 이미지에 적용할 수 있는 변환(transforms)은 크게 두 가지로 분류됩니다:

- 필터링(filtering): 픽셀의 값(intensity) 자체를 변경하는 작업입니다. 수식으로는 g(x) = h(f(x))로 표현됩니다.
- 워핑(warping): 픽셀의 좌표(coordinates) 위치를 변경하는 기하학적 작업입니다. 수식으로는 g(x) = f(h(x))로 표현됩니다.
Point processing.
filtering은 대상 픽셀과 그 이웃(neighbors) 픽셀들의 값을 특정 함수에 통과시켜 새로운 픽셀 값으로 대체하는 과정입니다. 수식 g(x) = h(f(x))에서 f(x)는 입력 이미지, g(x)는 출력 이미지이며, h는 픽셀 x의 이웃 영역(예: 3x3 주변 픽셀들)에 대해 정의된 연산자(operator)입니다:
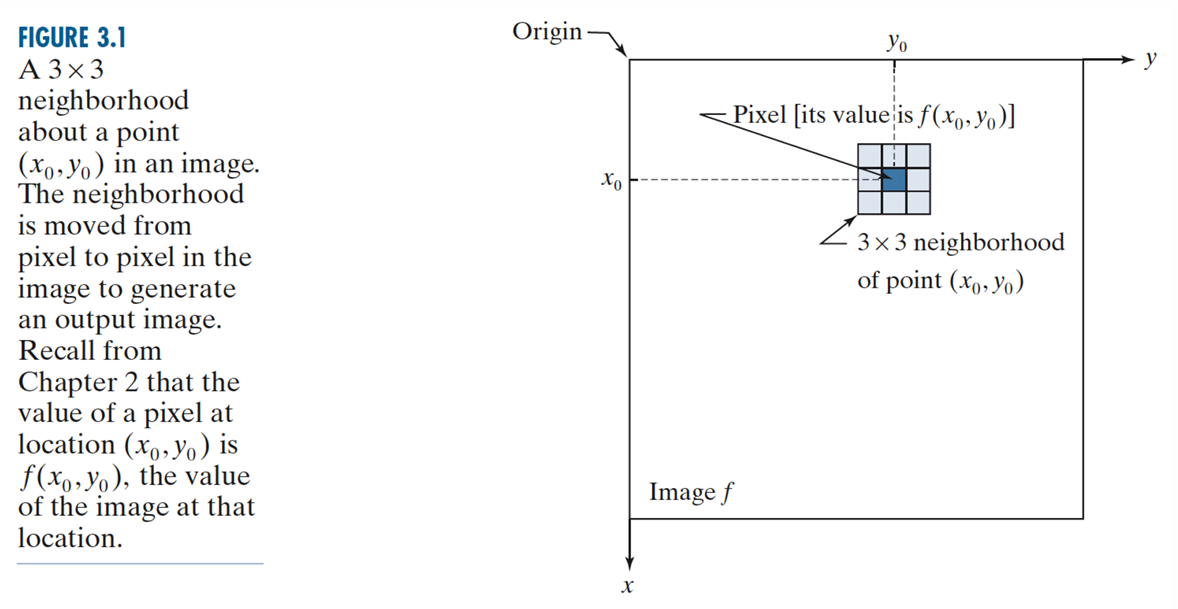
filter라는 명칙은 원래 주파수 도메인(frequency domain)에서 특정 주파수 성분을 통과시키거나 변형, 거부하는 처리 방식에서 빌려온 용어입니다. computer vision에서 다루는 filtering은 주파수가 아닌 이미지 평면 그 자체(2D plane)에서 직접 연산이 이루어지므로, 이를 구분하기 위해 spatial filtering 이라고 부릅니다.
What types of image filtering can we do?


filtering 연산은 크게 두 종류로 나뉩니다:
- point operation: 출력되는 픽셀의 값이 오직 대응하는 단일 입력 픽셀의 값에 의해서만 결정되는 처리 방식입니다. 이를 point processing이라고 합니다.
- neighborhood operation: 출력되는 픽셀의 값이 해당 픽셀뿐만 아니라 주변(neighborhood) 픽셀들의 값까지 함께 고려하여 결정되는 처리 방식입니다. 이는 앞서 언급된 filtering에 해당합니다.
point processing의 예시는 다음과 같습니다:

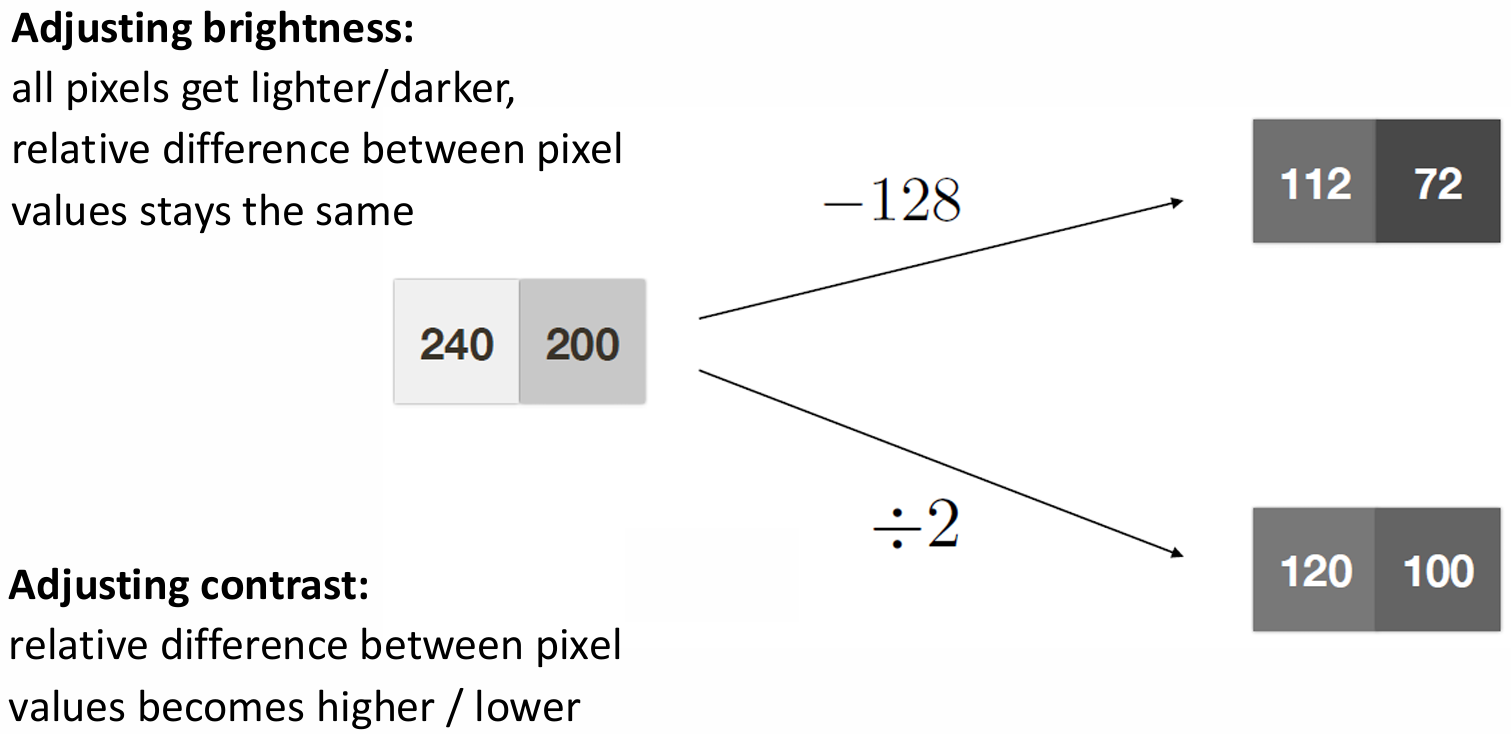
Brightness vs. contrast.
밝기(brightness)는 이미지의 평균적인 intensity 수준을 의미합니다. 모든 픽셀 값에 동일한 상수를 더하거나(+), 빼서(-) 조절합니다. 픽셀 값들 사이의 상대적인 차이(격차)는 그대로 유지된 채 전체적으로 밝아지거나 어두워집니다:

대비(contrast)는 픽셀 값들 사이의 상대적인 차이를 의미합니다. 모든 픽셀 값에 동일한 상수를 곱하거나(x), 나누어(/) 조절합니다. 연산 결과에 따라 픽셀 값들 사이의 상대적인 격차가 더 커지거나(대비 증가), 작아지게(대비 감소) 됩니다:

이 두 개념은 헷갈리기 쉬우며, brightness를 밝게 하거나 어둡게 한다는 것은 두 픽셀 사이의 상대적인 차이를 유지하며 값 자체를 키우거나 줄이는 것이고, contrast를 늘리거나 줄이는 것은 두 픽셀 사이의 상대적인 차이 자체를 늘리거나 줄이는 것을 의미합니다:
Intensity transformation.
point processing에서 공간 도메인의 연산자 수식인 g(x) = h(f(x))는 픽셀의 위치 좌표를 생략하고 명암 값의 변화에만 집중하여 s = h(r)로 단순화할 수 있습니다. 여기서 r은 입력 명암, s는 출력 명암을 나타내며, 함수 h를 명암 변환 함수(intensity transformation function)라고 정의합니다. 명암 변환 함수는 입력된 명암 r을 계산하여 새로운 출력 명암 s로 변환하는 역할을 수행합니다:

(a) 함수는 특정 구간을 강조하는 contrast stretching이며, (b) 함수는 이진화에 사용되는 thresholding 함수입니다. (a)의 경우 original diff(contrast) = r0 - k 이지만, transformed diff(contrast) = T(r0) - T(k)가 되며, 이는 original diff 보다는 큽니다.
power-law (gamma) transformation.
거듭제곱 변환은 s = cr^γ(c와 γ는 양의 상수) 형태의 수식으로 정의됩니다:
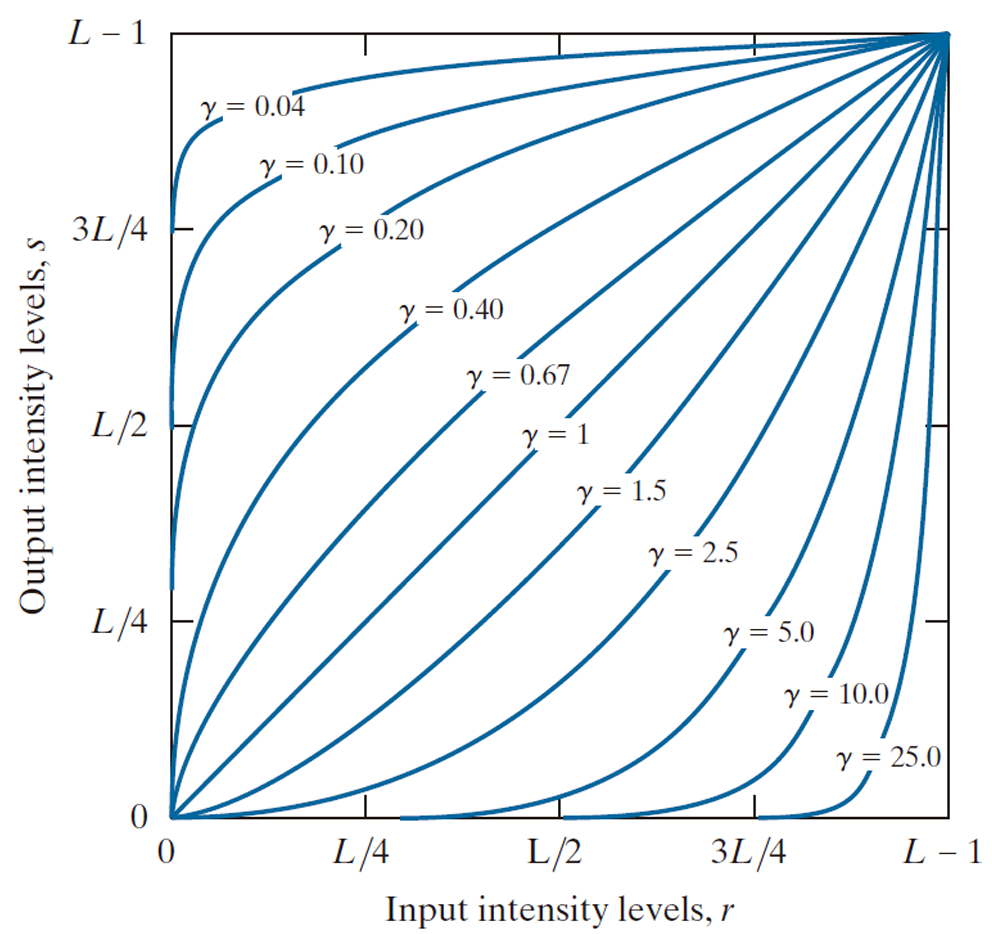
- γ값이 1보다 작은 소수(fractional)일 경우: 입력 이미지의 좁은 어두운 명암 범위를 출력 이미지에서는 더 넓은 밝은 명암 범위로 확장시킵니다.
- 반대로 γ값이 더 클 경우 이와 반대되는 효과(어둡게 만듦, 밝은 영역의 대비 증가)를 냅니다.


왼쪽 그림의 경우는 MRI 로 촬영된 골절된 척추 사진으로, 전체적으로 어두운 이미지에 γ < 1을 적용하여 어두운 영역에 숨겨진 구조적 디테일을 시각적으로 향상시킵니다. 오른쪽 그림의 경우 빛이 너무 바래서 형태 구분이 모호한 항공 사진에 γ > 1을 적용하여 밝은 부분에 대한 대비를 개선하고 객체의 형태를 더 뚜렷하게 만듭니다.
More complex transformation functions.

단일 수식으로 전체 명암을 일괄 조절하는 방식 외에, 특정 좌표점 (r1, s1), (r2, s2) 등을 기준으로 구간을 나누어 각 구간마다 서로 다른 선형 함수를 적용하는 방식도 가능합니다. 한편, 점의 개수를 늘려 복잡한 형태의 구간 분할을 생성할 수 있으며, 이를 통해 사용자가 특정 명암 구간의 대비만을 선택적으로 극대화하거나 억제할 수 있습니다.
'[Konkuk Univ. 4th] > [Computer Vision]' 카테고리의 다른 글
| [Computer Vision] Feature detection(Cont.) (0) | 2026.04.20 |
|---|---|
| [Computer Vision] Feature detection (0) | 2026.04.20 |
| [Computer Vision] Edge detection (0) | 2026.04.20 |
| [Computer Vision] Image resizing (0) | 2026.04.19 |
| [Computer Vision] Linear filtering (0) | 2026.04.19 |