
해당 글은 건국대학교 지서원 교수님의 컴퓨터 비전 수업 내용을 정리한 글입니다.
Creating a panorama: using very wide-angle lens
한 번에 넓은 장면을 찍는 가장 직관적인 방법은 시야각이 넓은 초광각 렌즈(Ultra Wide)나 어안 렌즈(Fisheye, 8mm 등)을 사용하는 것입니다. 초점 거리가 짧은 렌즈를 쓰면 더 많은 배경을 한 장에 담을 수 있습니다:

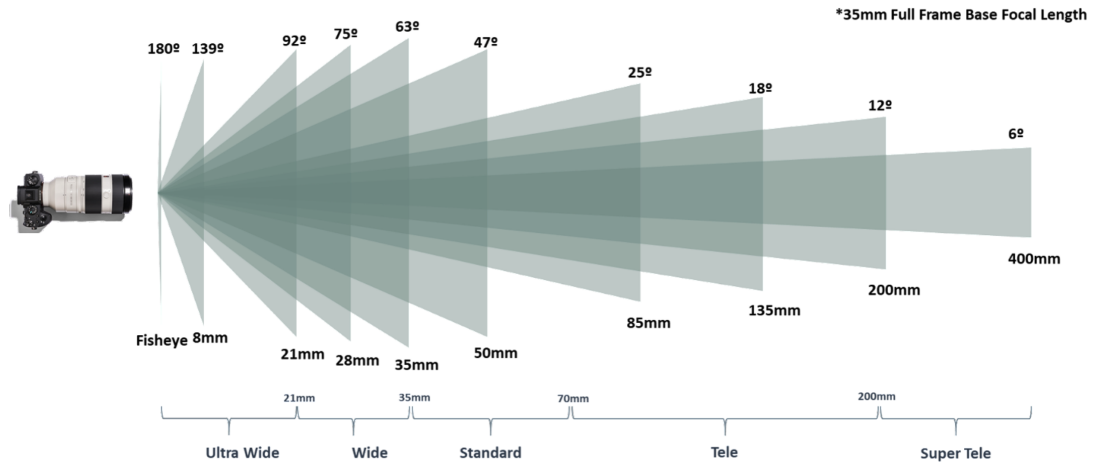
하지만 렌즈 만으로 화각을 넓히는 데는 물리적인 한계가 있습니다. 따라서 그 다음 방법은 stitching입니다.
Creating a panorama: stitching multiple images
stitching은 여러 장의 개별 사진을 찍은 뒤 하나로 이어 붙이는 기술입니다:

What we need to stitch multiple images.
컴퓨터가 여려 장의 사진을 완벽하게 하나로 이어 붙이려면 반드시 다음과 같은 것들을 수행해야 합니다:

- How to match images: 첫 번째 과제는 서로 다른 구도에서 찍힌 두 사진 속에서, 현실 세계의 '동일한 위치'에 해당하는 지점을 찾아 연결하는 것입니다. 위 그림의 빨간 화살표처럼, 왼쪽 사진의 산봉우리와 오른쪽 사진의 산봉우리가 같은 곳임을 컴퓨터가 인식할 수 있도록 고유한 특징점을 찾아내야 합니다.

- How to align images: 두 사진에서 짝이 맞는 지점들을 찾았다면, 시점의 차이로 인해 어긋난 사진들을 겹치게 만들어야 합니다. 이를 위해 한 사진을 다른 사진의 시점에 맞게 기하학적으로 변형하고 왜곡(warping)하는 수학적 규칙(transformation matrix)를 찾아내어 두 사진을 나란히 정렬합니다.

- How to blend images: 이미지가 겹치는 경계선 부분이 어색하지 않게, 두 이미지 사이의 intensity 차이를 줄여서 자연스럽게 섞어줍니다.
파노라마 이미지를 만드는 법을 배우면 computer vision의 뼈대가 되는 low/middle level algorithm을 모두 경험해볼 수 있습니다:
- How to detect interest points.
- How to decribe small patches about such points.
- How to find matches between pairs of such points on two images.
- How to find geometric transformations from one image the the other.
- How to warp one image to the other to align them.
- How to blend the images together to make the panorama.
Harris Corner Detector.

성공적인 pixel pair의 matching을 위해서는 한 이미지의 특정 patch가 다른 이미지에서도 오직 딱 한 곳하고만 매칭이 되어야 합니다. 이를 수학적으로 찾는 방법이 Harris Corner Detector입니다. 우선 위와 같은 이미지가 있을 때, 어떤 patch가 가장 unique한 patch가 될까요?

기본적으로 위 이미지에서 하늘과 같이 flat 한 지역은 unique한 patch로서 활용될 수 없습니다. 이는 variation이 적고, 다른 하늘을 가르키는 patches들과 matching될 수 있기 때문입니다(위 이미지에는 sky patch가 너무 많습니다).

edge는 flat region보다는 unique하지만, 조금 부족합니다. edge 방향으로 patch를 움직이면 matching될 수 있는 후보 patch들이 너무 많기 때문입니다. 이는 variance가 한 방향으로만 나타나기 때문입니다.

그런 의미에서 corner는 매우 좋은 patch입니다. 두 방향에서의 intensity diff. 가 있어서 주변에 비슷한 후보 patch가 존재하지 않기 때문입니다. 그렇다면 어떻게 컴퓨터에게 corner를 찾게 시킬 수 있을까요? patch(small window)를 이용하고, intensity의 차이를 보면 알 수 있습니다:

- flat region: flat한 영역은 window 내에서 어느 방향으로도 변화가 존재하지 않습니다.
- edge: window 내에서 오직 한 방향으로의 변화만이 존재합니다.
- corner: window 내에서 두 방향 이상으로의 변화가 존재합니다.
Detecting corner (a.k.a PCA)
corner를 검출하는 전체적인 과정은 주성분 분석(PCA)의 수학적 원리와 사실상 동일한 궤를 가지고 있습니다. 알고리즘은 다음의 5단계로 정의됩니다:
- Compute image gradients over small region
- Subtract mean from each image gradient
- Compute the covariance matrix at each pixel
- Compute the eigenvectors and eigenvalues
- Use threshold on eigenvalues to detect corners
Detection corner: step 1
1단계에서는 단일 픽셀이 아닌 일정 크기의 작은 region(window) 단위로 image gradient(using sobel filter)를 구합니다.

그리고 추출한 Ix, Iy를 2차원 좌표평면에 산점도로 투영하면 해당 영역의 특성을 시각적으로 해석할 수 있습니다:

- flat region: 평탄한 영역은 pixel intensity 변화가 거의 없기 때문에, 모든 gradient vector가 원점(0,0) 근처에 조밀하게 군집되어 있는 분포를 보입니다.
- edge: edge 영역에서 추출한 분포는 특정 방향으로 gradient 값들이 길게 늘어선 타원 형태를 나타냅니다. 이 타원 분포의 장축과 단축을 분석하면, 행렬 기하학적 특성인 edge direction과 magnitude를 역산할 수 있습니다.
- corner: corner는 다중 edge가 교차하는 지점이므로, gradient 산점도 역시 여러 방향을 향해 넓게 분산된 형태르 보입니다.
Detection corner: step 2

2단계는 구해진 gradient data 집합에서 평균값을 빼는 과정입니다. 이는 통계적 전처리로서 데이터의 중심을 원점으로 이동시키며, 신호 처리 관점에서는 의미 없는 DC offset을 제거하는 것과 같습니다.
한편, 분산을 정량화하기 위해 PCA 개념을 사용합니다. 데이터의 분산이 가장 극대화되는 방향이 첫 번째 주성분(Principle component)이 되며, 이에 직교(orthogonal)하면서 다음으로 큰 분산을 갖는 방향이 두 번째 주성분이 됩니다. 수학적으로 이는 Ax = λx 형태의 고유값(eigenvalues) 문제로 귀결되며, 공분산 행렬의 고유벡터(eigenvectors)가 주성분 방향을, 고유값(eigenvalues)가 그 방향으로의 분산 크기를 정의하게 됩니다.
다음은 mean subtraction의 중요성을 시각화한 것입니다:

위 그림 (a)에서는 평균이 차감되지 않은(non-centered) 데이터에서 주성분 축(P1, P2)이 데이터 군집의 원점으로부터의 거리에 왜곡되어 실제 분산형태를 정확히 분할하지 못하는 문제가 발생합니다. 반면 (b)는 원점으로 중심이 정렬된(centered) 데이터에서 P1과 P2가 데이터의 실제 형태를 정확하게 관통하는 orthogonal basis로 올바르게 작동합니다.
* harris corner detector가 다루는 데이터는 픽셀의 intensity 자체가 아니라 밝기의 변화량(gradient)이기 때문에, mean subtraction을 안 해도 됩니다. 자연 이미지의 경우 국소적인 window patch 내부를 관찰해보면, 픽셀 밝기가 증가하는 부분(+ gradient)과 감소하는 부분(- gradient)이 혼재되어 나타납니다. 이로 인해 window 내 gradient의 기대값은 0에 매우 가깝게 수렴합니다.
* Cov(X, Y) = E[XY] - μxμy에서 μx와 μy가 0에 수렴한다면, 공분산은 단순한 제곱합과 교차곱의 합인 E[XY]만으로 근사할 수 있습니다. 즉, window를 sliding할 때마다 pixel gradient으 평균을 계산하고 이를 다시 모든 픽셀 값에서 빼는 O(N)의 추가 연산고ㅘ 메모리 접근 병목을 제거할 수 있습니다.
Detection corner: step 3
3단계에서는 각 픽셀 위치에서 주변 픽셀들의 gradient를 종합하여, 2x2 크기의 공분산 행렬 H(x)를 구성합니다:


이 행렬의 원소들은 Ix^2, IxIy, Iy^2의 가중치 합으로 이루어집니다. 이 작은 2x2 structure tensor 내부의 해당 patch(window)의 모든 기하학적 정보가 압축되어 담기게 됩니다. 이때 w(x,y)는 window function입니다. 단순히 사각형 창 내부 픽셀에만 1의 가중치를 주고, 외부를 0으로 자르는 극단적인 box filter를 사용할 수도 있으나, 노이즈에 대한 강건성을 확보하고 중심 픽셀의 영향력을 극대화하기 위해 보통 중심부가 볼록한 gaussian 가중치를 사용합니다.
Detection corner: step 4
pixel patch로부터 구성한 공분산 행렬 H에서 eigenvalues와 eigenvectors를 계산합니다. 두 개의 eigenvalue λ1, λ2를 2차원 평면에 찍어보면 다음과 같습니다:

flat region은 두 방향 모두 gradient의 분산이 없는 λ1, λ2 ~ 0 상태입니다. edge는 한 방향으로만 분산이 극대화된 상태로, λ1 >>λ2은 수평 edge, λ1 << λ2는 수직 edge를 의미합니다(λ1는 x방향, λ2는 y방향). corner는 두 eigenvalues λ1, λ2값이 모두 유의미하게 큰 λ1, λ2 >> 0 상태입니다.
Detecting corner: step 5
5단계에서는 도출된 λ1, λ2들에 threshold를 적용해 corner를 최종적으로 확정합니다. λ1, λ2 2차원 평면에서 두 값이 모두 높은 우상단 구역을 corner로 판별하며, 이 분포를 단일 scalar 점수로 압축할 cornerness score가 필요합니다:

가장 직관적인 cornerness response funtion은 가장 작은 eigenvalue를 사용하는 것입니다. 위 그림에 나온 수식을 통해 cornerness를 정의하며, 이 최소값이 미리 설정한 threshold값을 초과하면 corner로 확정 짓습니다.
이 외에도 다양한 cornerness response function들이 존재하며 이는 다음과 같습니다:

eigenvalues들을 직접 구하는 것은 연산량이 매우 많이 듭니다. 따라서 행렬식(determinant)와 대각합(trace)로 우회하여 R 함수를 정의하면, 2x2 행렬의 행렬식(ad-bc)과 대각합(a+d)은 단순 스칼라 사칙연산만으로 structure tensor의 eigen feature들을 완벽히 대변할 수 있기 때문입니다.
다음은 예시입니다:


λmax를 이용하면, 한 방향이라도 intensity 변화가 존재하면 response가 존재하기 때문에, 가로/세로 방향의 edge가 모두 detection됩니다. 반면에 λmin을 사용하면, 두 방향 모두에서 intensity 변화가 존재해야 response가 존재하기 때문에, 다음과 같이 corner에서만 response가 강하게 발생합니다.
다음은 λmin과 똑같은 효과를 내면서, 계산 효율성을 잡은 다른 방법의 예시입니다:

Harris detector
harris detector를 정리하면 다음과 같습니다:

- 미분 연산: 이미지의 x방향, y방향 gradient Ix, Iy를 구합니다.
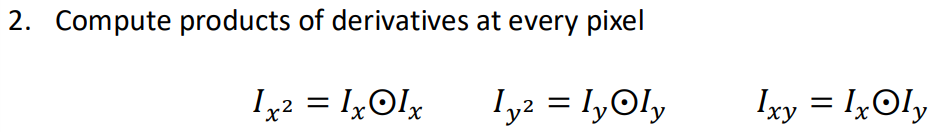
- 미분값의 곱 연산: 각 pixel에서 Ix^2, Iy^2, IxIy를 구합니다.

- gaussian blurring(주변 픽셀 합산): 2번의 결과에 gaussian filter를 적용하여, 주변 픽셀들의 가중치 합이 반영된 tilde들을 구합니다. 이 과정이 노이즈를 줄이고 window 내의 공분산 성분을 모으는 역할을 합니다.
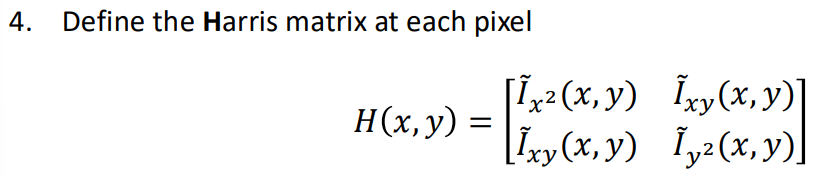
- harris matrix 구성: 각 픽셀 위치마다 3번에서 구한 값들로 2x2 공분산 행렬 H를 구합니다.

- response function R 계산, NMS 처리: determinant와 trace를 이용해 cornerness score를 계산하고, R값이 기준치(threshold)를 넘는 곳을 찾고, 그 중에서도 주변보다 점수가 가장 높은 local maxima만 남기고 나머지는 지웁니다.
다음은 예시입니다:





Properties of Harris corner detector.
harris corner detector는 다음과 같은 특징을 갖습니다:
- Translation invariant(평행 이동 불변성)? yes. 이미지를 옆으로 옮겨도 corner는 그대로 corner로 인식됩니다.
- Rotation invariant(회전 불변성)? yes. 공분산 행렬의 고유값은 이미지가 회전해도 변하지 않으므로, 이미지를 돌려도 동일한 corner를 찾을 수 있습니다.
- Scale invariant(크기 불변성)? NO. 아래의 그림을 보면 알 수 있습니다:

작은 scale에서는 명확한 corner였던 지점이 이미지를 크게 확대해버리면, corner를 찾기 위해 설정해둔 작은 window 창 안에서 이것이 corner가 아니라 단순한 직선(edge)으로 보여지게 됩니다.
'[Konkuk Univ. 4th] > [Computer Vision]' 카테고리의 다른 글
| [Computer Vision] Feature description, Feature matching (0) | 2026.04.20 |
|---|---|
| [Computer Vision] Feature detection(Cont.) (0) | 2026.04.20 |
| [Computer Vision] Edge detection (0) | 2026.04.20 |
| [Computer Vision] Image resizing (0) | 2026.04.19 |
| [Computer Vision] Linear filtering (0) | 2026.04.19 |