
해당 글은 건국대학교 지서원 교수님의 컴퓨터 비전 수업 내용을 정리한 글입니다.
Linear filters.
선형 필터(linear filters)는 입력 이미지 f와 필터(kernel or mask) w 간의 곱의 합(sum-of-product) 연산을 수행합니다. 커널 w의 크기는 연산이 적용되는 이웃(neighborhood)의 범위를 정의하며, 커널 내부의 계수(coefficient)는 필터의 본질적인 특성을 결정합니다. 출력 픽셀 값 g(x, y)를 도출하는 수학적 정의는 다음과 같습니다:


위 그림은 3x3 크기의 kernel을 사용한 spatial filtering의 작동 방식을 도식화하여 설명합니다. 좌표계 설정 시, 원본 이미지의 원점은 좌측 상단의 위치하지만, kernel의 원점은 kernel의 중심에 위치합니다. 공간적으로 대칭 형태인 kernel의 중심에 원점을 배치하는 것은 linear filtering의 수식을 간결하게 작성할 수 있게 합니다.

이미지 내의 국소적 패턴(local pattern)이 filter의 형태와 유사할 때, filter의 반응(reponse)이 가장 극대화됩니다. linear filtering의 수식을 보면, 임의의 두 벡터간의 correlation을 구하는 식과 동일하며, 이는 filter(kernel)과 원본 이미지의 일정 영역간의 유사도를 계산하는 것과 같습니다. 따라서 image에서 원하는 pattern을 찾기 위해서는 찾고자하는 pattern과 똑같은 kernel을 만들어서 correlation 연산을 수행하면 찾을 수 있습니다(그리고 CNN에서 kernel의 coefficient를 학습하는 것은 특정한 task에 맞는 정보를 추출하기 위해 kernel의 패턴을 학습하는 것으로 해석할 수 있습니다):

Linear filters: computational cost.
linear filtering에 필요한 계산량을 산술적으로 분석합니다. 픽셀 좌표 (x,y)마다 필터 크기인 m x m 번의 곱셈 연산이 수행됩니다. 따라서 입력 이미지가 n x n 픽셀일 경우, 전체 filtering을 위한 총 곱셈 연산 횟수는 m^2 x n^2 가 됩니다:

Linear filters: boundary effect.
spatial filtering 시 kernel이 이미지의 가장자리에 도달하면, kernel의 일부가 이미지 영역 밖으로 벗어나 연산에 필요한 데이터가 부족해지는 문제가 발생합니다. 이를 해결하기 위한 각 padding 기법은 정보 손실과 왜곡(artifact) 사이의 trade-off를 가집니다:

- Ignore: 커널이 이미지 영역을 완전히 벗하나지 않는 내부 픽셀에 대해서만 연산을 수행합니다. 입력 이미지가 N x N, kernel size K x K 일 때, 출력 이미지의 크기는 (N - K + 1) x (N - K - 1)로 축소됩니다. 존재하지 않는 데이터를 인위적으로 생성하지 않으므로 데이터의 순수성은 유지되지만, filtering을 반복할수록 spatial dimension이 지속적으로 감소하며 가장자리 정보가 유실됩니다.

- Padding with Zero: 이미지의 외부 테두리를 모두 0으로 채워 연산합니다. 출력 이미지의 크기를 입력과 동일하게(N x N) 유지할 때 주로 사용됩니다(padding size p = floor(kernel size)). 구현이 단순하지만, 이미지의 가장자리와 padding된 0 사이의 급격한 강도 변화(step edge)를 인위적으로 만들어냅니다. 이는 주파수 도메인에서 고주파 성분을 강제로 주입하는 것과 같아, smothing이나 미분 필터 적용 시 경계선이 검게 변하는 등의 artifact가 발생합니다.

- Padding with Replication: 가장자리에 위치한 픽셀 값을 이미지 밖으로 그대로 복사하여 연장합니다. zero padding이 유발하는 급격한 단절을 방지하여 인위적인 고주파 노이즈 생성(+ 가장자리가 어두워지는 것)을 억제합니다. 그러나 경계 픽셀의 값이 바깥으로 끌리는(smearing) 현상이 발생할 수 있습니다.

- Padding with Reflection: 이미지의 가장자리를 거울처럼 삼아 내부 픽셀 값을 대칭적으로 반사시켜 외부를 채웁니다. 신호의 연속성(continuity)과 미분 가능성을 가장 자연스럽게 유지하는 방법입니다. 경계 부근에서 텍스처나 패턴의 흐름이 유지ㅣ되므로, 실질적인 컴퓨터 비전 태스크에서 가장 우수한 시각적, 수학적 결과를 도출합니다.
Linear filters: correlation and convolution.
다음은 correlation과 convolution 연산의 차이입니다:
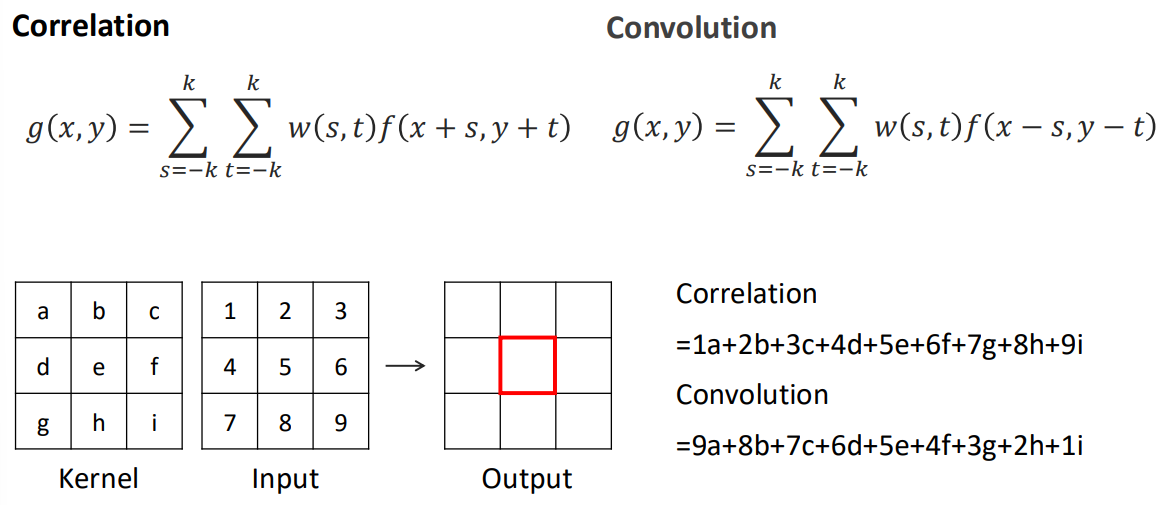
수식에서 볼 수 있듯, convolution은 kernel의 index가 반전(-s, -t)되어 연산됩니다(따라서 convolution을 image에 적용하려면 kernel이나 image 중 하나를 flip해야 correlation과 똑같이 동작합니다). 3 x 3 행렬 예시에서 correlation은 1a + 2b + 3c + ... 순으로 곱해지지만, convolution은 역순인 9a + 8b + 7c + ... 로 곱해지는 차이를 보입니다. 다음은 unit impulse 패턴을 활용하여 correlation과 convolution 연산의 메커니즘 차이를 1-D와 2-D로 도식화한 예시입니다:


convolution은 다음과 같은 수학적 성질을 갖습니다:


기본적으로 convolution 연산은 linear하기 때문에, additivity와 homogeneity를 만족합니다. 추가적으로 이동 불변성(shift invariance)를 만족하는데, 이는 입력 이미지의 절대적인 위치가 이동하더라도, 필터가 반응하는 결과물은 위치만 이동할 뿐 그 값은 동일하게 유지되는 것을 말합니다. 이는 convoluton 연산에 절대 좌표 값이 이용되지 않고, 상대 좌표 값만이 사용되기 때문입니다. 이를 그림으로 나타내면 다음과 같습니다:

pixel coordinate에 따라 operation이 달라지지 않기 때문에 만족하는 성질입니다. 그렇다면 반대로, 선형성(additivity, homogeneity)와 shift invariant 특징을 갖는 어떠한 연산이든, 궁극적으로 convolution의 형태로 표현할 수 있습니다.
Efficient Implementation: separability.
2차원 함수 w(x,y)가 두 개의 1차원 함수의 곱인 w_1(x), w_2(y)로 완벽히 쪼개질 수 있으면, 이 필터를 separable하다고 말합니다. m x n 크기의 커널이 m x 1 크기의 열벡터 c와 n x 1 크기의 행벡터 r의 외적(outer product)으로 도출될 수 있다면, 해당 커널은 분리 가능합니다:

* separable하다는 것이 2-D kernel이 symmetric하다는 것은 아닙니다. c = [a, b, c]^T, r = [d, e, f]^T라고 했을 때, cr^T = w의 elements들을 분석하면 알 수 있습니다.
예를 들어 다음과 같은 convolution 연산이 있을 때 다음과 같이 계산할 수도 있습니다:





이렇게 두 벡터의 외적으로 분리할 수 있는 kernel의 경우 분리하여 계산하면 연산 효율성이 극대화됩니다. 크기가 NxN인 이미지에 대해서 KxK 크기의 필터를 적용할 경우를 비교합니다:


표준 방식은 각각의 픽셀(N x N)에 대해서 각각 K x K 번의 곱셈이 필요합니다. 하지만 분리 방식은 두 번의 1차원 연산이 이뤄지므로, 각각의 픽셀(N x N)에 대해서 각각 K + K 번의 곱셈이 필요합니다. 또한 메모리에 저장해야할 필터의 계수(coefficient)는 표준 방식의 경우 K^2개이지만, 분리 방식의 경우는 2K개만 필요합니다.
Smoothing and sharpening.
box filter 혹은 mean filter라 불리는 이 filter는 filter 내의 모든 pixel에 동일한 가중치를 부여하는 방식입니다. center pixel의 값을 주변 이웃 pixel들의 평균값으로 대체하여 이미지를 부드럽게 만듭니다. 3x3 filter의 경우 모든 칸의 값이 1/9이며, filter 내부 계수의 총합은 항상 1이 되어야합니다(합이 1이어야 filtering 후에도 이미지의 전체적인 밝기가 유지됩니다).

한편, filter의 크기가 커질수록 더 넓은 영역의 평균을 구하게 되므로 이미지가 훨씬 더 강하게 흐려지는(blurring) 것을 확인할 수 있습니다:

Smoothing with Gaussian filter.
mean filter와 달리 위치에 따라 다른 가중치를 부여합니다. 중심에 가까운 pixel일수록 높은 가중치를 주고, 중심에서 멀어질수록 가중치를 적게 부여합니다:


정규분포를 으미하는 2차원 연속 함수 G(x,y)를 기반으로 하며, 이 연속 함수를 이산적인 픽셀 좌표에 대입하여 filter mask를 생성합니다. 이대 표준편차 σ가 flatten의 정도를 결정합니다. σ가 2일 때보다 5일 때 종모양의 곡선이 더 넓게 퍼지며, 이는 주변 픽셀의 영향을 더 폭넓게 반영하여 더 강한 blur 효과를 낸다는 것을 의미합니다:

이 두 필터링의 차이 예시는 다음과 같습니다:





Sharpening.
blurring이 픽셀 간의 차이를 줄여 이미지를 부드럽게 만든다면, sharpening은 반대로 픽셀 간의 밝기 차이(edge)를 극대화하여 이미지를 또렷하게 만듭니다. sharpening filter는 원본 이미지 크기를 2배로 강조한 filter(중앙값이 2인 행렬)에서 평균 필터(모든 값이 1/9인 행렬)을 빼는 방식으로 구성됩니다. 즉, 하나의 커널 안에서 원본 - 흐려진 이미지의 연산이 동시에 일어나도록 설계된 것입니다. 필터 계수의 총합은 1이 유지되어 전반적인 밝기는 변하지 않습니다:

sharpening의 예시는 다음과 같습니다:



Unsharp masking.
unsharp masking(unsharp한 부분은 masking한 고주파 성분만 있는 것)는 다음과 같은 방식으로 만들어집니다:
- 원본 이미지를 의도적으로 흐리게(blur) 만듭니다.
- 원본 이미지에서 흐려진 이미지를 뺍니다. 이 결과물을 unsharp mask라고 부르며, 이미지의 윤곽선(고주파 성분)만 남게 됩니다.
- 추출된 마스크를 원본 이미지에 다시 더해줍니다.

1차원 신호로 봤을 때 unsharp mask는 다음과 같습니다:

이 unsharp mask는 원본 이미지에서 gaussian filtering을 적용한 이미지를 뺀 것이므로, 이를 difference of gaussian, DoG라고 부릅니다. 한편, 선명화 가중치(α 또는 k)를 너무 높게 설정하여 과도하게 선명화하면 노이즈가 심하게 증폭되고 경계선 주변에 밝고 부자연스러운 테두리가 생기게 됩니다:

'[Konkuk Univ. 4th] > [Computer Vision]' 카테고리의 다른 글
| [Computer Vision] Feature detection(Cont.) (0) | 2026.04.20 |
|---|---|
| [Computer Vision] Feature detection (0) | 2026.04.20 |
| [Computer Vision] Edge detection (0) | 2026.04.20 |
| [Computer Vision] Image resizing (0) | 2026.04.19 |
| [Computer Vision] Point processing (0) | 2026.04.15 |