
해당 글은 건국대학교 지서원 교수님의 컴퓨터 비전 수업 내용을 정리한 글입니다.
Feature Description
두 이미지를 매칭하여 파노라마 이미지를 만들거나 객체를 추적하려면 두 단계가 필요합니다:

- 특징점 검출: 양쪽 이미지에서 산봉우리와 같은 interest points들을 각각 찾아냅니다. 이는 harris corner detector나 LoG 연산 등을 통해 수행가능합니다.

- 대응점 찾기: 왼쪽 이미지의 1번 점이 오른쪽 이미지의 어떤 점과 대응되는지 짝(corresponding pairs)을 찾는 과정입니다. 이 matching을 수행하기 위해서는 각 interest points들 주변의 image patch를 computer가 계산할 수 있는 형태의 feature vector로 변환하여 묘사(describe)해야 한다는 것입니다.
interest points 주변의 patch를 어떻게 묘사해야 할까요? 가장 중요한 원칙은 "유사한 내용을 담고 있는 patch들은 그 descriptor(feature vector) 역시 서로 유사해야 한다"는 점입니다. 이 벡터들 간의 거리를 계산하여 matching을 수행할 것이기 때문입니다.
Why is difficult?
feature vector를 그냥 단순히 pixel intensity로 두고 matching을 수행하면 안됩니다. 예를 들어:

다음과 같이, 동일한 물체라도 빛의 반사, 그림자, 조명의 색온도 등에 따라 컴퓨터가 인식하는 pixel의 절대적인 색상 및 밝기 값은 완전히 다르게 나타납니다. 또한:

다음과 같이, 물체를 찍는 카메라의 시점(viewpoint)에 따라 색상은 서로 다른 크기(scale)로 찍히거나, 평행 이동(translation)하고, 회전(rotation)된 상태로 왜곡되어 나타납니다.
Pixel value
가장 단순하고 원초적인 방법은 pixel values 자체를 사용하는 것입니다. 예를 들어:

3x3 크기의 image patch가 있다면, 그 안에 있는 9개의 픽셀 밝기 값을 그대로 한 줄로 이어 붙여서 9차원의 vector of intensity values로 변환할 수 있습니다. 이 방법은 이미지의 외형(밝기)과 기하학적 형태(크기, 각도)가 전혀 변하지 않은 완벽히 통제된 상황에서는 아무 문제 없이 작동합니다. 고해상도 이미지를 작게 downsampling한 뒤 그 픽셀 값들을 벡터 형태로 reshape하는 과정은 매우 단순하고 연산 속도가 빠릅니다.
하지만 이는 다음과 같이 절대적인 밝기(absolute intensity) 변화에 매우 취약합니다. 위와 같이 동일한 책 표지라도, 방에 불을 켜서 전체 픽셀 값이 밝아지거나 그림자가 지면, 두 픽셀 벡터 간의 SSD는 극단적으로 벌어집니다. 그리고 컴퓨터는 이를 완전히 다른 patch로 인식하게 됩니다.
그렇다면 픽셀의 절대적인 밝기 값에 어떻게 robust하게 할 수 있을까?
Image gradient
밝기 변화 문제를 해결하기 위해 pixel differences, 즉 gradient를 사용합니다:

이는 전체 이미지에 밝기 상수 C가 더해지더라도, 인접한 픽셀끼리 빼버리면 (I_{x+1} + C) - (I_{x} + C) = I_{x+1} - I_{x} 가 되어 조명 변화가 완벽하게 상쇄될 수 있습니다. 즉, invariant to absolute intensity를 확보할 수 있습니다.

하지만 이는 이미지가 살짝만 회전하거나, 늘어나거나, 찌그러지는 등 기하학적 왜곡(deformation)이 발생하면 픽셀들의 위치가 1:1로 어긋나기 때문에 매칭이 완전히 실패할 수 있습니다.
그렇다면 어떻게 deformation에 robust하게 할 수 있을까?
Color histogram
위치가 어긋나는 것이 문제라면, 아예 픽셀의 위치 정보를 무시해 버리면 됩니다:

patch 내부에 있는 픽셀들의 색상 분포(histogram)만 세어보는 방식입니다. 이 방식은 이미지가 아무리 회전하고 크기가 변해도 색상의 비율 자체는 변하지 않으므로 scale/rotation에 불변합니다.

하지만 histogram의 치명적인 단점은 spatial layout 정보를 완전히 잃어버린다는 것입니다. 사자의 눈 사진을 완전히 섞어버려도, 원래 사자의 눈 사진과 똑같은 histogram이 나옵니다.
그렇다면 어떻게 공간적인 배치 정보를 어느 정도만 살릴 수 있을까?
Spatial histogram
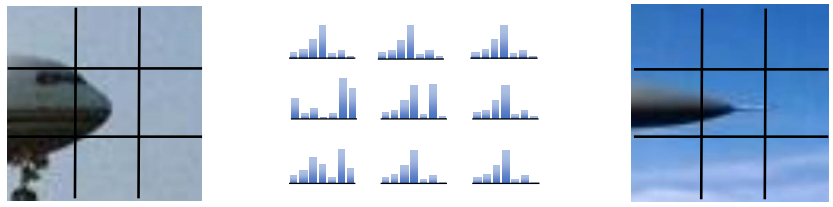
spatial histogram은 앞선 방법들의 장점만 타협한 방법입니다. 위 그림에서 비행기의 코 부분을 통째로 histogram으로 만드는 대신, 이미지를 3x3 cells로 분할한 뒤, 각 칸마다 독립적인 histogram을 구합니다. 이렇게 하면 "왼쪽 위에는 하늘색이 맑고, 오른쪽 아래에는 비행기 동체 색이 많다"는 식의 대략적인 공간 배치를 유지하면서도, 각 칸 내부에서의 미세한 픽셀 이동(deformation)에는 강건해집니다.
이 방법은 미세한 찌그러짐은 버틸 수 있지만, 카메라가 아예 90도, 180도로 크게 돌아가 버리는 global rotation에는 취약합니다. 위 예시에서 비행기 코 부분이 위를 향하도록 하면 격자 내의 분포가 완전히 뒤바뀌기 때문입니다.
그렇다면 어떻게 회전에 대해 완벽하게 불변성(completely invariant)을 가질 수 있을까?
Orientation normalization

위 이미지에서 산봉우리(interest point)의 patch가 주어지면, 컴퓨터는 가장 먼저 이 patch 내부의 pixel들이 전체적으로 어느 방향으로 가장 많이 흘러가고 있는지(지배적인 gradient 방향)를 계산합니다. 그리고 patch 자체를 아예 그 지배적인 방향(예: 화살표가 위를 향하도록)이 기준점(canonical orientation)이 되도록 회전시켜 버립니다.
이렇게 정규화(normalization)를 거치면, 카메라를 거꾸로 들고 사진을 찍든 비스듬히 찍든 간에, 컴퓨터는 항상 동일하게 정렬된 똑같은 patch를 바라보게 되므로 완벽한 회전 불변성을 얻게 됩니다.
Scale-Invariant Feature Transform(SIFT)
SIFT는 feature를 찾는 detector 역할과 그 feature를 vector로 만드는 descriptor의 역할을 모두 수행하는 패키지입니다. 이 파이프라인은 다음과 같습니다:
- Scale-space strema detection
- Keypoint localization
- Orientation assignment
- Keypoint descriptor
Scale-space extrema detection

원본 이미지에 blurring의 강도(σ)를 2^{1/4}배씩 점진적으로 증가시키며 연속된 gaussian blurred image들을 만듭니다. 이후, 인접한 gaussian images들을 픽셀 단위로 서로 뺍니다. 그 결과 도출되는 것이 오른쪽의 DoG(Difference of Gaussian) pyramid입니다. 연산이 매우 무거운 LoG 필터를 직접 씌우는 대신, gaussian image 간의 단순 뺄셈으로 LoG를 근사하는 것입니다.
다음은 gaussian image와 DoG 이미지의 시각적 차이입니다:


가우시안 피라미드에서 DoG 스케일(Scale)의 물리적 의미
가우시안 피라미드에서 서로 다른 sigma를 가진 두 이미지를 빼서(Difference) 만드는 DoG(Difference of Gaussian) 필터는, 그 빼는 기준이 되는 sigma의 절대적인 크기에 따라 탐지하는 객체의 크기가 완벽하게 달라집니다.
- 작은 스케일의 DoG (예: 작은 sigma_1 - 작은 sigma_2):
- 필터의 폭(퍼짐 정도)이 매우 좁습니다.
- 따라서 이미지 내의 아주 작은 객체, 미세한 텍스처, 얇은 선, 혹은 자잘한 코너들에 강하게 반응합니다. (예: 멀리 있는 군중의 얼굴, 나뭇잎의 잎맥 등)
- 큰 스케일의 DoG (예: 큰 sigma_3 - 큰 sigma_4):
- 큰 sigma로 인해 이미 잔자잘한 디테일은 모두 뭉개져(Blurred) 사라진 상태에서 두 이미지를 뺍니다.
- 이때 만들어지는 DoG 필터는 폭이 매우 넓으므로, 화면을 크게 차지하는 거대한 객체나 굵직한 덩어리(Blob) 형태에만 집중적으로 반응합니다. (예: 화면 가까이에 있는 거대한 건물 실루엣, 큰 해바라기 전체의 형태 등)
결론적으로: 컴퓨터는 내가 찾고자 하는 객체가 화면에 몇 픽셀 크기로 맺혀 있는지 모릅니다. 따라서 피라미드의 아래층(작은 DoG)부터 위층(큰 DoG)까지 훑어 올라가며, "작은 필터에는 반응하지 않던 덩어리가 큰 필터를 씌우는 순간 반응이 폭발한다면, 이 객체는 큰 물체다"라고 그 물체의 고유 스케일(Characteristic Scale)을 역추적하는 것입니다.
DoG를 거치면 변화가 없는 밋밋한 배경(저주파 성분)은 0으로 소거되어 회색으로 변하고, 객체의 edge나 corner 등 고추파 성분만 뚜렷하게 남게 됩니다. DoG pyramid가 완성되면, 2차원 공간(x,y)과 1차원 scale(σ)이 결합된 3차원 scale space에서 극댓값과 극솟값을 찾습니다:

어떤 픽셀(가운데 x 표시)이 진정한 interest point 후보가 되려면, 동일한 스케일의 주변 8개 픽셀은 물론이고, 한 단계 위 스케일의 9개 픽셀, 한 단계 아래 스케일의 9개 픽셀 등 총 26개의 이웃 픽셀 전부와 비교하여 그 값이 가장 크거나 가장 작아야합니다.
앞뒤 스케일(위/아래 층)과 비교하는 이유
이것이 SIFT가 크기 불변성(Scale-Invariance)을 달성하는 핵심입니다. 특정 픽셀이 진짜 특징점이 되려면, 현재 보고 있는 이미지 평면(x, y) 상에서 상하좌우 주변 8개 픽셀보다 값이 커야(혹은 작아야) 할 뿐만 아니라, 필터의 크기를 키웠을 때(위층 스케일)와 줄였을 때(아래층 스케일)의 값보다도 커야 합니다.
- 만약 앞뒤 스케일을 비교하지 않고 (x, y)에서만 극댓값을 찾는다면, 코너의 '위치'는 알 수 있어도 그 코너의 '진짜 크기'는 영원히 알 수 없습니다.
- 필터 크기(sigma)를 조절하며 앞뒤 스케일과 비교하여 피크(Peak)를 찍는다는 것은, "이 객체의 크기와 필터의 크기가 완벽하게 일치하는 지점을 찾았다"는 수학적 선언입니다.
keypoint localization
1단계에서 찾은 수많은 후보 중 수학적으로 불안정한 가짜 interest points들을 제거합니다. DoG의 response의 절댓값 |D(x)|이 threshold(일반적으로 0.03)보다 낮은 후보는 contrast가 너무 낮아 노이즈에 쉽게 흔들릴 수 있으므로 탈락 시킵니다:
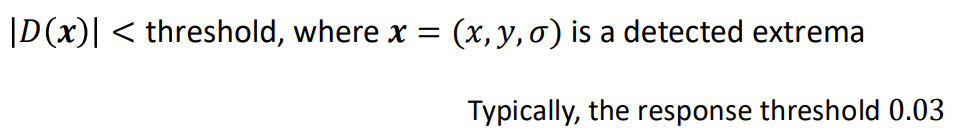
절댓값을 사용하는 이유 (명암비 필터링)
DoG 연산 결과인 D(x)는 양수(+)가 될 수도 있고 음수(-)가 될 수도 있습니다.
- 양수(+) 피크: 어두운 배경 위에 있는 밝은 점(Bright blob)일 때 발생합니다.
- 음수(-) 피크: 밝은 배경 위에 있는 어두운 점(Dark blob)일 때 발생합니다.
- 컴퓨터 비전에서 어두운 점이든 밝은 점이든 둘 다 훌륭한 특징점(Feature)입니다. 우리가 노이즈로 간주하고 버려야 할 것은 색상이 배경과 구분이 안 되는 흐리멍덩한 점(Low Contrast)입니다. 따라서 점이 밝은지 어두운지(부호)는 무시하고, 오직 배경과의 명암 차이 강도(Magnitude)만 평가하기 위해 절댓값 |D(x)|에 임계값(Threshold)을 적용하는 것입니다.
그 후 harris corner detection을 적용합니다. 2x2 Hessian matrix H를 구성하고, 그 고유값들의 비율 r을 검사합니다. 계산 효율성을 위해 고유값을 직접 구하지 않고, Trace와 Det을 이용한 수식을 적용합니다. 이 값이 특정 기준(일반적으로 r = 10에 해당하는 값)을 초과하면, 한쪽 방향으로만 에너지가 큰 불안정한 edge로 판정하여 탈락시킵니다:

해리스 코너 검출기 vs SIFT의 H 행렬 (구조적 차이)
A. 해리스 코너의 H 행렬 (구조 텐서, Structure Tensor)
해리스 알고리즘에서 코너를 찾기 위해 구하는 행렬은 원본 이미지의 1차 미분(Gradient)을 이용합니다.
- 원본 이미지 $I$에 대해 x방향 미분(I_x)과 y방향 미분(I_y)을 구합니다.
- 이 값들을 곱하여 I_x^2, I_y^2, I_x I_y 텐서 성분을 만듭니다.
- 특정 윈도우 패치 내에서 가우시안 가중치 w(x,y)를 주어 모두 합산합니다.이 행렬은 그래디언트가 어느 방향으로 분산되어 있는지 그 기하학적 분포를 나타냅니다

B. SIFT의 H 행렬 (헤시안 행렬, Hessian Matrix)
반면 SIFT의 행렬은 원본 이미지가 아니라 DoG 피라미드 이미지 D(x,y)의 2차 미분을 사용합니다.
- DoG 이미지 $D$의 픽셀 값들을 이용하여 중앙 차분법 등으로 2차 미분값들을 구합니다.
- D_{xx} = D(x+1, y) + D(x-1, y) - 2D(x, y)
- D_{yy} = D(x, y+1) + D(x, y-1) - 2D(x, y)
- D_{xy} = (D(x+1, y+1) - D(x-1, y+1) - D(x+1, y-1) + D(x-1, y-1)) / 4
- 이 스칼라 값들을 조합하여 2x2 헤시안 행렬을 만듭니다.
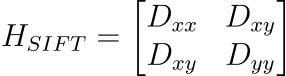
왜 굳이 H 행렬을 구하는가?
SIFT의 극댓값 탐색을 거치면 꼭짓점(코너)뿐만 아니라 건물의 윤곽선 같은 길쭉한 선(Edge) 위에서도 극댓값이 나오는 치명적인 문제가 발생합니다. 긴 선은 좌우로 이동할 때는 구분이 안 되므로 특징점으로 쓰면 안 됩니다.
이 길쭉한 선 위에서는 한 방향(수직 방향)으로만 2차 미분 곡률(Curvature)이 크고, 선을 따라가는 방향으로는 곡률이 0에 가깝습니다. 즉, H_{SIFT}의 고유값 두 개 중 하나(lambda_{max})는 매우 크고, 하나(lambda_{min})는 매우 작게 나옵니다.
이를 판별하기 위해 대각합(Trace)과 행렬식(Det)을 이용한 비율 검사식 {Trace^2(H)}/{Det(H)} 을 계산하고, 이 비율이 너무 크면 불안정한 선(Edge)으로 간주하여 즉시 탈락시키는 것입니다.
다음은 예시입니다:

Orientation assignment
방향 정규화를 통해 이미지가 회전하더라도 동일하게 매칭될 수 있도록 고유한 회전 각도를 부여합니다:

살아남은 특징 특징점의 scale에 해당하는 gaussian blurred image를 가져옵니다. 노이즈가 제거된 이 이미지의 인접 픽셀 차이를 이용해 특징점 주변 영역의 gradient 크기(magnitude)와 gradient 방향(direction)을 계산합니다:

그 후 gradient magnitude와 direction을 이용해 360도를 10도씩 36개의 bin으로 나눈 histogram을 만듭니다. 이때 단순히 픽셀의 개수를 세는 것이 아니라, 두 가지 가중치를 곱하여 막대를 쌓아 올립니다:
- gradient magnitude: edge가 강할수록(변화량이 클수록) 투표권을 크게 줍니다.
- gaussian weight: 중심(특징점 위치)에서 가까운 픽셀일수록 더 큰 영향을 미치도록 만듭니다(이때 gaussian의 sigma는 feature point scale의 1.5배를 사용합니다).

그 후 histogram에서 highest peak를 찾습니다:

이 막대의 각도가 바로 해당 특징점을 대표하는 지배적인 방향이 됩니다. 이때 최고점의 80% 높이를 넘는 또 다른 peak가 있다면, 알고리즘은 그 각도를 가지는 특징점을 하나 더 만들어냅니다. 즉, 위치와 크기는 완전히 같지만 방향만 다른 쌍둥이 특징점이 생성되는 것입니다. 결과적으로 detection 단계는 각 점에 대해 위치(x,y), 스케일(sigma), 방향(theta) 라는 4개지 속성값을 반환하며 종료됩니다.
아래는 예시입니다:

Keypont descriptor
이는 이 점은 다른 이미지의 점과 수학적으로 비교하기 위해 벡터로 변환하는 단계입니다. 이는 다음 4단계로 구성됩니다:
- 특징점을 중심으로 16x16 픽셀 크기의 window를 떼어옵니다.
- 이를 다시 4x4 픽셀 크기의 작은 sub-block 16개로 분할합니다.
- 각 4x4 블록 내부에서 8개 방향을 가진 histogram을 각각 구합니다.
- 픽셀이 가진 원래 각도에서, 앞서 구했던 특징점의 지배젹인 방향을 빼줍니다. 즉, 지배적인 방향을 0도(북쪽)로 고정시키고 나머지 픽셀들의 방향을 상대적인 각도로 재정렬하는 것입니다.
이후 빞의 밝기 변화에 robust하게 하기위해 벡터의 길이를 1로 정규화하고, 너무 튀는 값은 0.2로 잘라낸(clamp) 뒤 다시 정규화하는 후처리를 거칩니다.
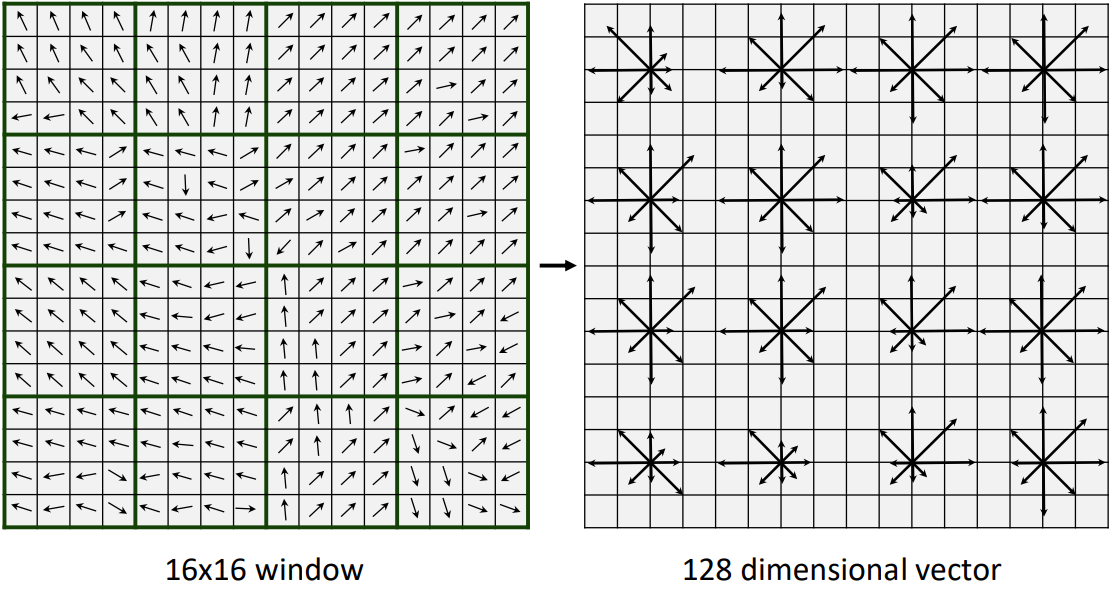
위 그림은 16개의 window에서, 각각 8방향의 magnitude값을 표현해서, 16x8 차원의 벡터로 만들 수 있습니다.
Properties of SIFT
SIFT는 다음과 같은 특징을 갖습니다:
- Change of viewpoint: 이미지가 평면 밖으로 최대 30도 정도 틀어지는 3D 시점 변화를 견딜 수 있습니다. 이는 histogram과 orientation normalization을 적용하기 때문입니다.
- Change of Illumination의 변화를 다룰 수 있습니다: 앞선 정규화 과정들과 변화량을 사용한다는 점 덕분에 극단적인 명암 변화에도 강건하게 특징을 유지합니다.
- Velocity: 실시간 처리가 가능할 정도로 연산 최적화(DoG)가 잘 되어 있습니다.
다음은 예시입니다:


Feature matching
두 개의 특징점이 주어졌을 때 이들이 같은 객체인지 판별하는 가장 원초적인 방법은 두 128차원 벡터 간의 L2 norm을 구하는 것입니다:

두 벡터를 빼서 그 차이의 절댓값이 가장 0에 가까운 짝을 찾는 방식이며, 이를 NN, Nearest Neighbor Search라고 합니다.

하지만 위와 같은 예시는 NN search가 갖는 한계를 보여줍니다. 왼쪽 이미지의 특정 울타리 기둥 f1을 오른쪽 이미지에서 찾으려고 할 때, 오른쪽 이미지에는 똑같이 생긴 울타리 기둥 f2, f'2가 수십 개나 존재합니다. 이 경우 1등 matching point f2와 2등 matching point f'2의 거리가 거의 비슷하게 나오며, 컴퓨터는 어떤 것이 진짜 짝인지 확신할 수 없게 됩니다(high uncertainty, low entropy).
NNDR, Nearest Neighbor Distance Ratio
이를 해결하는 방식이 NNDR입니다. 이는 절대적인 거리가 아니라, 1등과 2등의 거리 비율을 봅니다:

d1을 가장 가까운 특징점(1등)까지의 거리라고 하고, d2를 두 번째로 가까운 특징점(2등)까지의 거리라고 했을 때, NNDR = d1/d2로 정의할 수 있습니다:
- Case A: 산봉우리처럼 독특한 곳은 1등 d1과의 거리는 매우 가깝고, 2등 d2는 매우 다르게 생겼을 것이므로, 거리가 멉니다. 따라서 d1/d2 비율이 0.5 등 작은 값이 나옵니다.
- Case B: 1등 d1도 똑같이 생겼고, 2등 d2도 똑같이 생겼으므로 두 거리가 비슷합니다. 따라서 d1/d2 비율이 0.9나 1.0에 가깝게 나옵니다.
즉, DDNR 값이 특정 임계값(예: 0.8)보다 큰 경우는 1등과 2등의 차이가 없는 모호한 가짜 매칭이므로 아예 버리는 것입니다. 결과적인 매칭 알고리즘은 다음과 같습니다:

다음은 ratio test를 했을 때와 안 했을 때의 pair 결과입니다:




이미지 1의 특징점 A에게 가장 유사한 특징점을 물어봐서 이미지 2의 B가 나왔다고 가정했을 때, 매칭을 확정하기 전에, 반대로 이미지 2의 B에게 가장 유사한 특징점이 이미지 1의 A인지를 확인합니다. 만약 B가 이미지 1의 다른 점인 C를 지목한다면 이 둘의 매칭은 일방적인 것이므로 파기합니다. 오직 서로가 서로를 1순위로 지목할 때(Consistency)만 최종 대응점을 승인하는 것을 Bi-directional consistency check라고 합니다:

'[Konkuk Univ. 4th] > [Computer Vision]' 카테고리의 다른 글
| [Computer Vision] Feature detection(Cont.) (0) | 2026.04.20 |
|---|---|
| [Computer Vision] Feature detection (0) | 2026.04.20 |
| [Computer Vision] Edge detection (0) | 2026.04.20 |
| [Computer Vision] Image resizing (0) | 2026.04.19 |
| [Computer Vision] Linear filtering (0) | 2026.04.19 |