
0. Singly LinkedList (단일 연결 리스트)
단일 연결 리스트는 LinkedList 의 한 종류입니다.
2024.04.19 - [자료구조 및 알고리즘] - 자료구조 및 알고리즘 7 - LinkedList 에서 설명한 LinkedList 와 동일한 자료구조입니다.
자세한 설명은 위 글을 보면 되고, 여기에 추가적인 메소드들을 더해 구현해보겠습니다.
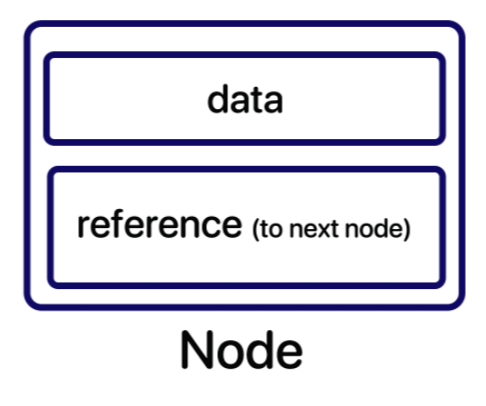
1. Node
public class Node<E> {
E data;
Node<E> next; // 다음 노드를 가르키는 래퍼런스 변수
Node(E data){
this.data = data;
this.next = null;
}
}
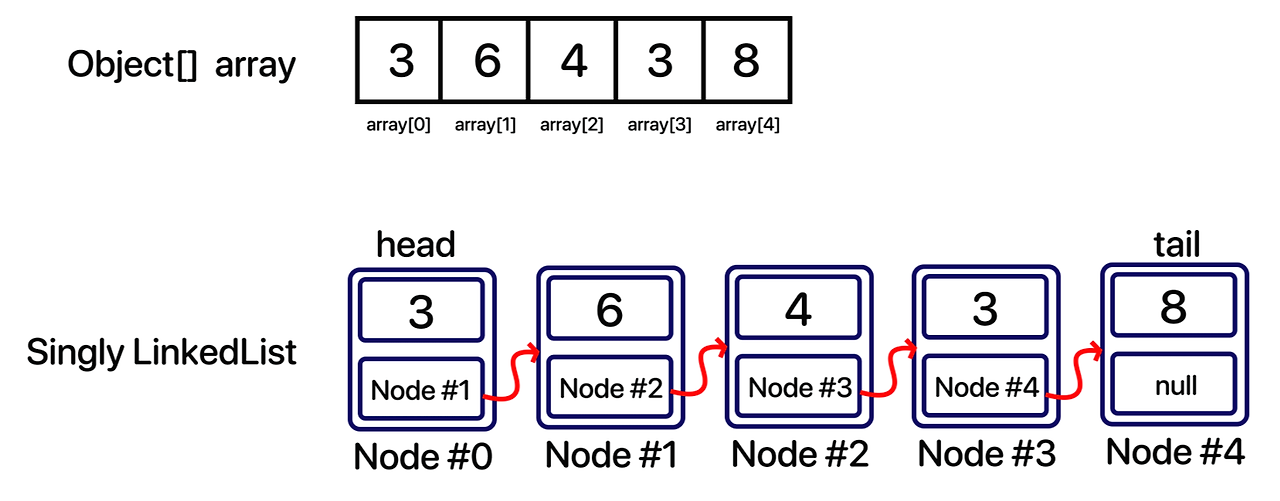
2. Singly LinkedList
import Interfaces.List;
import java.lang.reflect.Array;
import java.lang.reflect.InvocationTargetException;
import java.util.Arrays;
import java.util.Comparator;
public class SlinkedList<E> implements List<E> {
private Node<E> head; // 리스트의 첫 노드
private Node<E> tail; // 리스트의 마지막 노드
private int size; // 요소의 개수, 노드의 개수
// 생성자
SlinkedList(){
this.head = null;
this.tail = null;
this.size = 0;
}
// 특정 위치의 노드를 반환하는 메소드
public Node<E> search(int index){
// index 범위가 넘어가는 경우 예외 반환
if(index < 0 || index > size)
throw new IndexOutOfBoundsException();
// 탐색의 시작을 헤드 노드로 합니다.
Node<E> x = head;
// index 번째 노드를 순차적으로 찾아 나갑니다.
for(int i=0; i<index; i++){
x = x.next;
}
// index 번째 노드를 반환합니다.
return x;
}
// 기본 add(E e) 가 addLast(E e) 와 똑같은 의미입니다.
@Override
public boolean add(E e) {
addLast(e);
return true;
}
private void addLast(E e) {
// 요소가 하나도 없는 경우
if(size == 0){
// 요소가 하나도 없는 경우에 마지막에 넣는것은 처음에 넣는것과 같다.
addFirst(e);
}
// 요소가 하나라도 있는 경우
else{
Node<E> newNode = new Node<>(e);
// 기존 꼬리 노드의 다음 노드로 새 노드를 저장한다.
tail.next = newNode;
// 새 꼬리 노드는 새 노드가 된다.
tail = newNode;
size++;
}
}
private void addFirst(E e) {
// 요소가 하나도 없는 경우
if(size == 0){
Node<E> newNode = new Node<>(e);
// 새로 생긴 노드가 헤드 노드이자 꼬리 노드이다.
head = tail = newNode;
size++;
}
// 요소가 하나라도 있는 경우
else{
Node<E> newNode = new Node<>(e);
// 새로운 노드의 다음 노드가 기존 헤드 노드가 된다.
newNode.next = head;
// 새로운 헤드 노드로 새 노드가 된다.
head = newNode;
size++;
}
}
@Override
public void add(int index, E e) {
// index 범위가 넘어가는 경우 예외 반환
if(index < 0 || index > size)
throw new IndexOutOfBoundsException();
// 가장 처음 노드로 넣을 경우
if(index == 0)
addFirst(e);
// 가장 마지막 노드로 넣을 경우
else if(index == size)
addLast(e);
// 가운데 노드로 넣을 경우
else{
Node<E> newNode = new Node<>(e);
// 해당 index - 1 에 해당하는 노드, 새롭게 생긴 노드의 이전 노드
Node<E> prevNode = search(index - 1);
// 새 노드의 다음 노드로 이전 노드의 다음 노드를 저장
newNode.next = prevNode.next;
// 이전 노드의 다음 노드로 새 노드를 저장
prevNode.next = newNode;
size++;
}
}
// 가장 앞 요소를 삭제
public E remove(){
// 삭제할 요소가 없으면 예외 반환
if(size == 0)
throw new IndexOutOfBoundsException();
// 삭제할 요소가 한 개라도 있는 경우
else{
// 헤드 노드를 임시로 저장할 노드
Node<E> headNode = head;
// 헤드 노드의 data 값을 반환해주기 위해 임시 변수 생성
E element = headNode.data;
// 헤드 노드로 기존의 헤드 노드의 다음 노드를 저장
head = headNode.next;
// 기존 헤드 노드의 모든 데이터들 삭제
headNode.data = null;
headNode.next = null;
// 사이즈 감소
size--;
// 만약 이번 삭제로 인해 요소가 하나도 남지 않았으면,
// 즉, 삭제한 요소가 head 이자 tail 일 때
if(size == 0)
// tail 도 null 로 저장
tail = null;
// 삭제에 성공하면 삭제된 노드의 데이터 반환
return element;
}
}
// 원하는 요소를 삭제
@Override
public boolean remove(Object o) {
if(size == 0)
throw new IndexOutOfBoundsException();
// 헤드의 요소를 삭제하고 싶다면
if(head.data.equals(o)){
remove();
return true;
}
else{
Node<E> x = head.next;
Node<E> prevNode = head;
while(x != null){
if(x.data.equals(o)){
break;
}
prevNode = x;
x = x.next;
}
if(x == null){
return false;
}
else{
// 이전 노드의 다음 노드로 삭제되는 노드의 다음 노드를 저장
prevNode.next = x.next;
// 삭제되는 노드의 데이터 삭제
x.next = null;
x.data = null;
// 요소개수 감소
size--;
return true;
}
}
}
// 해당 인덱스의 요소를 삭제
@Override
public E remove(int index) {
// index 범위가 넘어가는 경우 예외 반환
if(index < 0 || index >= size)
throw new IndexOutOfBoundsException();
if(index == 0)
return remove();
else {
// search() 를 통해 index 의 요소를 찾는다.
Node<E> prevNode = search(index - 1);
// 삭제하고자 하는 노드가 꼬리 노드일 경우
if(index == (size - 1)){
// 꼬리 노드 임시 저장
Node<E> tailNode = tail;
// 삭제 노드의 data 반환을 위한 data 임시 저장
E element = tailNode.data;
// 기존 꼬리 노드의 값들 삭제
tailNode.data = null;
tailNode.next = null;
// 이전 노드가 꼬리 노드가 된다.
prevNode.next = null;
tail = prevNode;
// 삭제되는 노드의 data 반환
return element;
}
else{
// 삭제되는 노드 임시 저장
Node<E> deleteNode = prevNode.next;
// 삭제되는 노드의 data 반환을 위해 data 임시 저장
E element = deleteNode.data;
// 이전 노드의 다음 노드로 삭제되는 노드의 다음 노드를 저장
prevNode.next = deleteNode.next;
// 삭제되는 노드의 값들 삭제
deleteNode.data = null;
deleteNode.next = null;
// 삭제되는 노드의 data 반환
return element;
}
}
}
@Override
public boolean contains(Object o) {
// 헤드 노드부터 탐색 시작
Node<E> x = head;
for(; x != null; x = x.next){
// 찾으면 true 반환
if(x.data.equals(o))
return true;
}
// 끝까지 찾아도 없으면 false 반환
return false;
}
@Override
public int size() {
return size;
}
@Override
public E get(int index) {
return search(index).data;
}
@Override
public void set(int index, E e) {
search(index).data = e;
}
@Override
public boolean isEmpty() {
return size == 0;
}
@Override
public int indexOf(Object o) {
// 헤드 노드 부터 순차 탐색
Node<E> x = head;
// 끝 노드까지 탐색
for(int i=0; i<size; i++){
// 해당 노드의 data 가 o 와 같다면
if(x.data.equals(o))
// i 반환
return i;
// 다르다면 다음 노드로 넘어간다.
else
x = x.next;
}
// 끝까지 찾아도 없다면 -1 반환
return -1;
}
@Override
public void clear() {
for(Node<E> x = head; x != null;){
Node<E> nextNode = x.next;
x.data = null;
x.next = null;
x = nextNode;
}
head = tail = null;
size = 0;
}
@SuppressWarnings("unchecked")
public SlinkedList<? super E> clone() throws CloneNotSupportedException {
// Object 클래스의 clone() 메소드를 통해 일단 얕은 복사를 수행한다.
SlinkedList<? super E> clone = (SlinkedList<? super E>) super.clone();
clone.head = null;
clone.tail = null;
clone.size = 0;
// 깊은 복사
Node<E> x = head;
for(int i=0; i<size; i++){
clone.add(0, x.data);
x = x.next;
}
// 클론 배열 반환
return clone;
}
// 노드의 data 들을 배열로 만들어 Object[] 로 반환
public Object[] toArray(){
// 헤드 노드부터 탐색 시작
Node<E> x = head;
// 반환할 배열 생성
Object[] array = new Object[size];
for(int i=0; i<size; i++){
array[i] = x.data;
x = x.next;
}
return array;
}
/*
스트림을 통한 배열의 생성이 더 안정적이고 다양한 타입으로 만들 수 있다는 점에 유리하다.
SomeClass[] sarray = Stream.generate(() -> new SomeClass(x.data)).limit(10).toArray(SomeClass::new);
제너릭 타입이 이는 클래스는 배열생성이 불가하기 때문에 Node<E>[] 은 생각하지 않아도 된다.
하지만 제너릭 타입이 없는 클래스의 배열 생성에서 Object 로 얕은 복사를 수행하는 것은 꽤나 도전적이다.
만약 Wrapper 클래스가 아닌 사용자 임의 클래스 배열이라면 이는 불가하기 떄문이다.
따라서 Stream 을 통해 만들어주는 것이 효율적, 효과적이다.
TODO : 익명함수, Stream, lambda 표현식 배울 필요가 있음.
*/
@SuppressWarnings("unchecked")
public <T> T[] toArray(T[] a) {
// 복사해야 하는 배열의 크기가 size 보다 작으면 size 만큼의 T 타입 배열 만들어주기
if(a.length < size){
a = (T[]) Array.newInstance(a.getClass().getComponentType(), size);
}
// 얕은 복사를 이용하며 배열 수정
Object[] ojt = a;
Node<E> x = head;
for(int i=0; i<size; i++){
ojt[i] = x.data;
x = x.next;
}
return a;
}
// Comparable 을 상속해서 Comparator 가 필요가 없다면
// Comparator 에 null 값을 넣어도 된다.
public void sort(){
sort(null);
}
// toArray 의 object 타입 배열 반환을 통해 배열을 받고
// Arrays.sort 를 통해 정렬한다.
@SuppressWarnings({"unchecked", "rawtypes"})
public void sort(Comparator<? super E> c){
Object[] a = this.toArray();
Arrays.sort(a, (Comparator) c);
Node<E> x = head;
for(int i=0; i<size; i++){
x.data = (E) a[i];
x = x.next;
}
}
}
추가 공부: Stream, 익명 함수, 제너릭 바운더리, 리플렉트, super.clone() ...
'[JAVA] > 자바[JAVA] 자료구조 구현' 카테고리의 다른 글
| 자바[JAVA] 자료구조 구현 6 - Stack (0) | 2024.05.02 |
|---|---|
| 자바[JAVA] 자료구조 구현 5 - Stack Interface (0) | 2024.05.02 |
| 자바[JAVA] 자료구조 구현 4 - 이중 연결 리스트 (0) | 2024.04.30 |
| 자바[JAVA] 자료구조 구현 2 - ArrayList (0) | 2024.04.26 |
| 자바[JAVA] 자료구조 구현 1 - List Interface (0) | 2024.04.26 |