
https://arxiv.org/abs/2411.15594
A Survey on LLM-as-a-Judge
Accurate and consistent evaluation is crucial for decision-making across numerous fields, yet it remains a challenging task due to inherent subjectivity, variability, and scale. Large Language Models (LLMs) have achieved remarkable success across diverse d
arxiv.org
Abstract.
이 논문에서는 다양한 분야에서 의사결정을 위해 정확하고 일관된 평가가 중요하지만, 주관성, 가변성, 규모의 문제로 인해 어려움을 겪고 있다는 점을 지적합니다. *사람을 활용한 평가나, 여러가지 객관적인 평가가 필요하지만 비용적인 측면, 물리적인 측면에서 완벽하게 수행하기란 불가능에 가까운 현실을 말합니다.
최근 대규모 언어 모델(LLM)이 다양한 분야에서 뛰어난 성과를 보이며, 복잡한 작업을 평가하는 데 있어 인간 전문가 대신 LLM을 평가자로 활용하는 "LLM-as-a-judge" 개념이 등장했씁니다. LLM은 다양한 데이터 타입을 처리하고, 확장 가능하며 비용 효율적이고 일관된 평가를 제공하는 능력을 가추고 있어 전통적인 전문가 기반 평가에 매력적인 대안이 될 수 있습니다.
그러나 LLM-as-a-judge 시스템의 신뢰성을 확보하는 것은 여전히 큰 도전 과제로 남아 있으며, 이를 위해 세심한 설계와 표준화가 필요합니다. 이 논문은 "어떻게 신뢰할 수 있는 LLM-as-a-judge 시스템을 구축할 수 있을까?" 라는 핵심 질문을 중심으로, 일관성 향상, 편향 완화, 다양한 평가 시나리오에 대한 적응 등의 신뢰성 강화 전략을 탐구합니다. *LLM의 특징 덕분에 전통적인 평가의 대안이 될 수 있지만, 평가 결과에 대한 신뢰성에는 여전히 의문점이 남아있는 대안입니다.
또한, 이러한 시스템의 신뢰성을 평가하기 위한 방법론과 이를 지원하기 위해 설계된 새로운 벤치마크를 제안합니다. *평가 모델의 신뢰성 확보와 별개로, 평가 모델의 평가 성능을 알 수 있는 벤치마크가 필요하기 때문입니다.
Introduction.
판단(judgement)이란, 보편적인 규칙 안에 담긴 특수한 대상을 생각하는 능력이다. 즉, 어떤 대상이 주어진 규칙에 속하는지를 구별하는 능력을 포함한다.
- 칸트, 『판단력 비판』 [43], 서론 IV, 5:179; 『순수이성비판』 [42], A132/B171.
최근 LLM은 기술 분야부터 인문학, 사회과학에 이르기까지 다양한 영역에서 뛰어난 성과를 보여주고 있습니다. 이러한 성과를 바탕으로, LLM을 평가자로 활용하는 "LLM-as-a-judge"라는 개념이 주목받고 있습니다. 여기서 LLM은 주어진 규칙의 범위 내에 어떤 것이 속하는지를 판단하는 역할을 맡습니다. LLM이 인간과 유사한 추론 및 사고 과정을 모방할 수 있는 능력 덕분에, 전통적으로 인간 전문가가 수행하던 역할을 대신하면서도 평가 수요 증가에 대응해 비용 효율적이고 확정 가능한 솔루션을 제공합니다.
예를 들어, 학술 논문 동료 평가(peer review) 과정에서 LLM-as-a-judge를 활용하면, 제출되는 논문의 수가 급증해도 전문가 수준의 판단을 유지할 수 있는 방안을 마련할 수 있습니다.
LLM 등장 이전에는 포괄적이면서도 확장 가능한 평가 사이의 균형을 맞추는 것이 지속적인 도전 과제였습니다. 즉, 이전의의 평가 방식에는 다음과 같은 단점들이 있었습니다:
- 주관적 전문가 평가: 전문가 주도 평가는 전체적인 상황과 미묘한 맥락을 잘 이해할 수 있어 가장 포괄적이지만, 비용이 많이 들고 확장하기 어렵고 일관성이 떨어질 수 있습니다.
- 객관적 자동 평가: BLEU나 ROUGE 같은 지표는 자동화되어 빠르고 일관된 평가를 제공하지만, 표면적인 어휘적 일치에 의존하여 이야기 생성이나 지시문 텍스트와 같은 복잡한 과제에서는 깊은 뉘앙스를 제대로 포착하지 못합니다.
이러한 한계를 극복하기 위해, LLM-as-a-judge는 전문가 평가의 정교함과 자동 평가의 확장성, 일관성을 결합하여 복잡하고 열린 평가 문제를 해결할 수 있는 유망한 방법으로 떠오르고 있습니다. 또한, LLM은 적절한 프롬프트 학습이나 미세 조정을 통해 멀티모달 입력도 처리할 수 있는 유연성을 가질 것으로 기대됩니다.
LLM-as-a-judge는 전문가 주도의 인간 평가나 기존 자동 평가지표에 비해 확장 가능하고 적응 가능한 평가 프레임워크로서 큰 잠재력을 가지고 있지만, 두 가지 주요 과제로 인해 채택에 어려움을 겪고 있습니다:
- 체계적인 검토 부재: LLM-as-a-judge에 대한 공식 정의의 부재, 단편화된 이해, 그리고 일관적이지 않은 사용 방식 등으로 인해 연구자와 실무자가 LLM-as-a-judge를 충분히 이해하고 효과적으로 활용하는데 어려움이 있습니다.
- 신뢰성 문제: LLM-as-a-judge를 단순히 사용한다고 해서 평가 결과가 정확하고 기존 기준에 부합한다는 보장이 없습니다. 시스템의 신뢰성을 확보하는 것이 중요한 문제로 남아 있습니다.
이 논문은 위 문제들을 해결하기 위해 LLM-as-a-judge에 관한 체계적인 리뷰를 제공하고, 신뢰할 수 있는 LLM-as-a-judge 시스템을 구축하기 위한 전략을 모색합니다.
- 정의와 분류: 먼저, LLM-as-a-judge를 공식적 및 비공식적으로 정의하면서 "LLM-as-a-judge란 무엇인가?"라는 기본 질문에 답합니다. 이어서 기존 방법들을 분류하고, "어떻게 LLM-as-a-judge를 사용할 것인가?"에 대해 탐구합니다.
- 신뢰성 향상 및 평가 방법론: "어떻게 신뢰할 수 있는 LLM-as-a-judge 시스템을 구축할 수 있을까?"라는 질문에 답하기 위해 두 가지 핵심 측면을 살펴봅니다.
- 신뢰성 향상을 위한 전략: LLM-as-a-judge 시스템의 성능을 최적화하기 위한 주요 전략을 검토합니다.
- 신뢰성 평가 방법론: LLM-as-a-judge 시스템을 평가하는 데 사용되는 지표, 데이터셋, 방법론을 조사하고, 잠재적인 평향의 원인과 완화 방법을 강조합니다. 이를 바탕으로 LLM-as-a-judge 시스템을 평가하기 위한 새로운 벤치마크도 소개합니다.
Background and Method.
LLM이 인간의 추론을 모방하고 사전에 정의돈 규칙에 따라 특정 입력을 평가하는 능력은 "LLM-as-a-judge"를 가능하게 했습니다. 이 모델들의 확장성, 적응성, 비용 효율성은 전통적으로 인간이 수행했던 평가 작업의 수가 증가하는 상황에서 이를 관리하기에 적합하게 만듭니다. 이러한 능력은 LLM을 다양한 평가 시나리오와 목표에 유연하게 활용하는 데 핵심적인 역할을 합니다.
초기에는 LLM의 주요 초점이 언어 생성과 이해에 있었습니다. 하지만 인간 피드백을 통한 강화 학습(RLHF)와 같은 훈련 패러다임의 발전으로 LLM은 인간의 가치와 추론 과정에 더 잘 맞춰지게 되었습니다. *GPT-3.5에 사용한 방법으로, 인간 피드백을 통해 모델이 인간 친화적으로 언어를 생성할 수 있도록 미세 조정했습니다. 이런 패러다임의 발전을 통해 LLM은 더이상 언어 생성만 하는 모델이 아닌 인간처럼 행동하는 역할도 수행할 수 있는 모델이 되었습니다.
이런 패러다임의 변화로 인해 LLM은 생성적 작업에서 평가적 역할로 전환될 수 있었습니다. 본질적으로 LLM-as-a-judge는 사전 정의된 규칙, 기준 또는 선호도에 따라 객체, 행동 또는 결정을 평가하기 위해 LLM을 사용하는 것을 의미합니다. 여기에는 다음과 같은 다양한 역할이 포함됩니다:
- 채점자(Graders)
- 평가자/검사자(Evaluators/Assessors)
- 비평가(Critics)
- 검증자(Verifiers)
- 심사관(Examiners)
- 보상/순위 모델(Reward/Ranking Models)
현재로서는 평가 작업에 효과적으로 LLM-as-a-judge를 사용하는 방법에 대한 정의가 대체로 비공식적이거나 모호하여 명확하고 공식적인 표현이 부족합니다. 따라서, LLM-as-Evaluator에 대한 공식 정의를 다음과 같이 시작합니다:
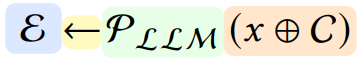
- E: LLM-as-a-judge 전체 과정에서 얻어진 최종 평가 결과. 이 결과는 점수, 선택된 라벨, 문장 등이 될 수 있습니다.
- Pllm: 해당 LLM에 의해 정의된 확률 함수이며, 생성은 auto-regressive 과정입니다.
- x: 평가 대상이 되는 입력 데이터로, 텍스트, 이미지, 비디오 등 어떤 형태든 가능합니다.
- C: 입력 x에 대한 context로, 보통 프롬프트 템플릿이나 대화 내 history 정보와 결합되어 사용됩니다.
- ⊕: 입력 x와 context C를 결합하는 연산자로, 이 연산은 문맥에 따라 x를 문장의 시작, 중간 또는 끝에 배치하는 등 다양한 방식으로 수행될 수 있습니다.
이 공식은 LLM-as-a-judge가 auto-regressive 생성 모델의 한 형태임을 반영합니다. 즉, 주어진 문맥을 바탕으로 다음 내용을 생성하고 그로부터 목표 평가를 얻어내는 과정을 설명합니다. 이는 평가 작업을 위해 LLM을 어떻게 활용하는지를 보여주며, 입력 설계, 모델 선택 및 훈련, 출력 후 후처리 등을 포괄합니다.
LLM-as-a-judge를 구현하는 기본 접근 방식은 위 공식에 따라 다음과 같이 분류할 수 있습니다:
- In-Context Learning
- Model Selection
- Post-processing Method
- Evaluation Pipeline

이 네 가지 방법은 그림 2.에 요약되어 있습니다. 이 파이프라인을 따르면 평가를 위한 기본적인 LLM-as-a-judge 시스템을 구축할 수 있습니다.
In-Context Learning
LLM-as-a-judge를 적용하기 위해, 평가 작업은 일반적으로 In-context Learning방식을 사용하여 정의됩니다. 이 방식은 모델의 추론과 판단을 안내하기 위해 지침과 예시를 제공하는 방법을 포함합니다.
[Deep daiv.] NLP, 논문 리뷰 - Language Models are Few-Shot Learners (GPT-3)
https://arxiv.org/abs/2005.14165 Language Models are Few-Shot LearnersRecent work has demonstrated substantial gains on many NLP tasks and benchmarks by pre-training on a large corpus of text followed by fine-tuning on a specific task. While typically tas
hw-hk.tistory.com
이 과정에는 주로 두 가지 측면이 존재합니다: 프롬프트(prompt)와 입력(input)의 설계
- 입력 설계(Input Design):
- 평가할 변수의 유형(텍스트, 이미지, 비디오 등)
- 입력 방식(개별, 쌍, 배치)
- 입력 위치(시작 부분, 중간, 끝 등)
- 프롬프트 설계(Prompt Design): 그림 2.에 설명된 네 가지 방법을 사용할 수 있습니다. 네 가지 방법은 다음과 같습니다.
- 점수 생성(Generating scores)
- 참/거짓 질문 해결하기(Solving Yes/No questions)
- 쌍별 비교하기(Conducting pairwise comparisons)
- 다지선다 선택(Making multiple-choice selections)
Generating scores
평가를 해당 점수로 나타내는 것은 직관적입니다. 하지만 평가에 사용되는 점수의 성격과 범위를 신중하게 고려해야 합니다.

- 점수 유형:
- 이산(discrete): 일반적으로 1~3, 1~5, 1~10 범위
- 연속(continuous): 0~1 또는 0~100 범위
- 점수 매기기 방법:
- 간단한 방법: 프롬프트에서 점수 범위와 주요 평가 기준을 설명하는 방법
- 예: "응답의 유용성, 관련성, 정확성, 세부 사항 수준을 평가해 주세요. 각 어시스턴트에게 1부터 10까지의 전체 점수를 부여합니다. 높은 점수는 더 나은 전반적인 성능을 나타냅니다."
- 복잡한 방법: 더 세부적인 평가 기준을 제공하는 방법
- 예: Language-Model-as-an-Examiner(Figure 3) 방식은 Likert 척도(1~3)를 사용해 정확성, 일관성, 사실성, 포괄성 등의 여러 차원에서 점수를 매깁니다. 그런 다음 이 4개 차원에 대한 점수를 기반으로 전체 품직ㄹ을 나타내는 1부터 5까지의 점수를 할당합니다.
- 간단한 방법: 프롬프트에서 점수 범위와 주요 평가 기준을 설명하는 방법
Solving Yes/no questions
참/거짓 질문 방식은 주어진 명제의 정확성 여부에 대한 판단만 요구합니다. 이 유형의 질문은 간단하고 직접적이며, 추가 비교나 선택 없이 두 가지 고정된 응답만을 제공합니다.

이 평가 방식은 다음과 같은 상황에서 자주 활용됩니다:
- 중간 과정 평가: 피드백 루프를 생성하여 자가 최적화 주기를 촉진합니다. 예를 들어, Reflexion에서는 자가 반영(verbal self-reflections)을 생성하여 미래 시도에 유용한 피드백을 제공합니다.
- 보상 시그널이 희소한 경우: 예를 들어, 성공/실패와 같은 이진 상태를 평가할 때, 자가 반영 모델은 현재 경로와 지속적인 기억을 사용해 세밀하고 구체적인 피드백을 생성합니다. *희소한 보상 시그널을 보충합니다.
- 자가 개선(self-improvement) 맥락: "수정 필요", "수정 불필요"등의 커스텀 문구를 평가하여 다음 주기로 넘어가는 데 도움을 줍니다.
- 지식 정확성 테스트 및 사실 확인: 주어진 질문과 관련된 지식 그래프 삼중항(엔티티, 관계, 엔티티)이 질문에 답변하기에 충분한지 평가하는 등. (예: "주어진 질문과 관련된 지식 그래프 삼중항이 당신이 질문하기에 충분한지 여부를 예/아니오로 답하십시오.")
Conducting pairwise comparisons
쌍별 비교(pairwise comparison)는 두 가지 선택지를 비교하여 어느 쪽이 더 우수하거나 특정 기준에 더 부합하는지를 선택하는 방법을 의미합니다. 이는 "예/아니오"와 같은 단순한 판단이 아니라 두 가지 옵션 중 하나를 선택하는 결정을 내리는 과정입니다.

주관적인 판단 또는 객관적 기준에 근거할 수 있으며, 이는 상대적 평가(relative evaluation)에 해당합니다. 주요 활용 분야: 쌍별 비교는 여러 옵션을 순위 매기거나 우선순위를 정하는 데 자주 사용됩니다. 여러 쌍의 비교를 통해 어느 선택지가 더 나은지 파악하거나 계층 구조를 설정할 수 있습니다.
쌍별 비교의 장점: 쌍별 비교는 다양한 분야에 큰 영향을 미친 잘 확립된 방법론입니다. 연구에 따르면, 쌍별 비교 상황에서 LLM과 인간 평가의 일치도가 점수 기반 평가보다 높다고 합니다. 또한 여러 연구에서 쌍별 비교 평가가 위치 일관성(positional consistency) 측면에서 다른 평가 방법보다 우수함을 입증했습니다.
쌍별 비교는 리스트별 비교(list-wise comparisons)와 같이 더 복잡한 관계 기반 평가 프레임워크로 확장될 수 있습니다. 이는 고급 순위 알고리즘 또는 데이터 필터링 등을 사용해 구현됩니다.
Making multiple-choice selections
다지선다 선택은 쌍별 비교나 예/아니오 판단처럼 상대적인 선택이나 단순한 참/거짓 판단을 요구하지 않고, 여러 옵션 중 가장 적절하거나 올바른 것을 선택하도록 합니다.

다지선다 선택이 갖는 특징은 다음과 같습니다:
- 참/거짓 질문보다 더 다양한 응답을 제공할 수 있으며, 더 깊은 이해나 선호도를 평가할 수 있습니다.
- 이 방법은 앞서 언급한 세 가지 방법보다 덜 자주 사용됩니다. *애초에 다지선다 문제를 평가할 일이 많이 없고(다른 평가 방식보다는...), 쌍별 비교를 여러번 수행하는 것과 유사하기 때문에, 한 번의 추론으로 좋은 성능을 내기 다른 방법보다는 어려울 것 같습니다.
Model Selection
General LLM
LLM-as-a-judge를 통한 평가 자동화를 위해 한 가지 효과적인 접근 방식은 인간 평가자 대신 GPT-4와 같은 고급 언어 모델을 사용하는 것입니다. 예를 들어, Li 등은 805개의 질문으로 구성된 테스트 셋을 만들고, GPT-4를 사용하여 text-davinci-003과 비교한 성능을 평가했습니다. 또 다른 예로 Zheng 등은 8가지 일반적인 분야에 걸쳐 80개의 다중 라운드 테스트 질문을 설계하고, GPT-4를 사용하여 모델의 응답을 자동으로 점수화했습니다.
이러한 방식에서 GPT-4 기반 평가자는 전문 인간 평가자와 비교해 높은 정확도를 보였으며, 평가에서 일관성과 안정성이 뛰어나다는 것이 입증되었습니다. 하지만 사용된 일반 LLM이 지시사항 준수 능력이나 추론 능력에 제한이 있을 겨우, LLM-as-a-judge 방법의 효과가 크게 영향을 받을 수 있습니다. *LLM의 성능이 부족하다면 LLM-as-a-judge 방법이 효과적이지 않을 수 있음을 시사합니다. 즉, 평가의 신뢰도가 LLM의 성능에 의존적입니다.
Fine-tuned LLM
그러나 외부 API에 의존하여 평가를 수행할 경우, 프라이버시 유출에 대한 우려가 생기며 API 모델의 불투명성은 평가 재현성을 저해할 수 있습니다. 따라서 후속 연구들은 쌍별 비교나 등급을 매기기에 중점을 두어 특화된 어어 모델을 미세 조정할 것을 권장합니다.
예시 연구들:
- PandaLM: Alpaca 지시사항과 GPT-3.5 주석을 기반으로 데이터를 구축하고, LLaMA-7B를 평가자로서 미세 조정한 모델
- JudgeLM: 다양한 지시시항 세트와 GPT-4 주석을 통해 데이터를 구축하고, Vicuna를 확장 가능한 평가자 모델로서 미세 조정한 모델
- Auto-J: 여러 시나리오에 걸친 평가 데이터를 구축하여 생성형 평가자 모델을 훈련, 이 모델은 평가와 비평적 의견 모두를 제공하는 모델
- Prometheus: 수천 개의 평가 기준을 정의하고 GPT-4를 기반으로 피드백 데이터셋을 구축, 세부적인 평가자 모델을 미세 조정한 모델
파인튜닝된 평가자 모델의 일반적인 과정은 세 가지 주요 단계로 구성됩니다:
- 데이터 수집(Data Collection):
- 훈련 데이터는 일반적으로 세 가지 요소로 구성됨: 지시사항(instructions), 평가 대상(object), 그리고 평가(evaluations)
- 지시사항은 주로 지시사항 데이터셋에서 가져오며, 평가는 GPT-4나 인간 주석으로부터 얻음
- 프롬프트 설계(Prompt Design)
- 프롬프트 템플릿 구조는 평가 방식에 따라 달리짐(section 2.)
- 모델 파인튜닝(Model Fine-tuning)
- 설계된 프롬프트와 수집된 데이터를 사용하여 평가자 모델을 미세 조정함
- 일반적으로 지시사항 기반 파인튜닝(instruction fine-tuning) 패러다임을 따름
- 모델은 지시사항과 하나 이상의 응답을 받아, 평가 결과와 필요 시 설명을 포함하는 출력을 생성
*instruction fine-tuning패러다임에 대해 추가 공부 필요 + GPT를 활용한 주석 생성에 대한 공부 필요(데이터 합성?)
파인튜닝 후, 평가자 모델은 대상 객체를 평가하는 데 사용될 수 있습니다. 이러한 파인튜닝 모델은 보통 자체 설계된 테스트 셋에서 우수한 성능을 보이지만, 평가 능력에는 여러 한계가 존재합니다(section 4.2). 현재의 프롬프트 및 파인튜닝 데이터셋 설계는 종종 일반화가 부족한 평가 LLM을 만들어내어, GPT-4와 같은 강력한 LLM과 성능을 비교하기 어렵게 만듭니다.
Post-processing Method
LLM-as-a-judge가 생성한 확률 분포를 정제하여 정확한 평가를 제공하는 과정이 후처리입니다. 이 평가 형식은 In-context Learning 설계와 일치해야 하며, 추출된 평가의 신뢰성을 높이기 위한 절차를 포함할 수 있습니다. 후처리에는 주로 세 가지 방법이 있습니다:
- 특정 토큰 추출
- 출력 로짓 정규화
- 높은 반환 값을 가진 문장 선택
각 방법에 대해 설명하기 전에 각 방법은 객관적 질문 평가 시 상당한 한계가 있음을 유념해야 합니다. 예를 들어, 텍스트 응답 평가에서는 LLM의 응답에서 핵심 답변 토큰을 정확히 추출하지 목하면 잘못된 평가 결과가 초래될 수 있습니다. 이러한 후처리의 문제는 앞서 ICL 단계에서 사용한 프롬프트 설계와 모델의 지시사항 준수 능력과 밀접하게 관련되어 있습니다.
Extracting specific tokens
ICL 학습(section 2.)에서 보았듯이, 평가 대상이 점수 형태이거나 특정 옵션 선택, 혹은 예/아니오 응답 형태일 때, 규칙 매칭(rule-match)을 적용하여 확률 분포 반복 과정에서 생성된 응답에서 해당 토큰을 추출하는 것이 일반적입니다.
중요 고려 사항으로는 다음이 있습니다:
- 예/아니오 질문은 "수정 필요" / "수정 불필요" 와 같은 맞춤형 문구를 포함할 수 있으며, "위 답변은 추가 수정이 필요한가요?" 와 같은 질문도 포함됩니다.
- 입력 샘플을 프롬프트 템플릿에 넣었을 때, "수정 필요.", "결론: 수정 필요.", "예"와 같은 형태의 출력이 나올 수 있습니다. 이러한 응답 형식의 다양성은 일관되게 파싱(parse)하기 어렵게 만듭니다.
후처리 과정은 다음과 같습니다:
- 설계된 프롬프트와 입력 내용, 그리고 평가에 사용된 기본 모델(backbone model)에 따라 특정 토큰을 추출하는 규칙을 적용합니다.
- ICL 단계에서 출력 형식에 대한 명확한 지시가 없으면, 다양한 평가 표현이 나올 수 있습니다(예: "Reponse 1 is better" vs "The better one is response 1"). 이들은 동일한 선택을 전달하지만 형식이 달라 규칙 인식에 어려움을 줍니다.
- 단순 해결책으로는 "마지막 문장은 '더 나은 응답은...'으로 시작해야 한다"고 명확한 지시를 제공하거나, few-shot 전략을 사용하는 방법이 있습니다.
- 또한 일반 모델이 지시사항 준수 능력이 부족하면, 목표 평가 형식과 내용을 지시에 따라 생성하지 못해 후처리 규칙에 따라 추출하는 과정이 기대만큼 원활하지 않을 수 있습니다.
이를 통해 후처리 방법론의 중요성과 어려움을 이해할 수 있으며, 정확한 토큰 추출을 위해 명확한 프롬프트 설계와 모델의 지시사항 준수 능력이 필요함을 알 수 있습니다.
Normalizing the output logits
예/아니오 설정에서 중간 단계의 LLM-as-a-judge는 종종 출력 로짓(output logits)을 정규화하여 0과 1 사이의 연속적인 소수 형태의 평가값을 얻습니다. 이러한 방식은 에이전트 방법과 프롬프트 기반 최적화 방법에서도 매우 흔하게 사용됩니다. *이게 뭐지 ..?
예를 들어, Self-consistency와 Self-reflection 점수 계산이 있습니다.
자기 일관성(self-consistency) 및 자기 성찰(self-reflection) 점수는 MEvaluator의 한 번의 순전파 내에서 프롬프트 [(x⊕C), "Yes"]를 구성하고, 이전 토큰들에 조건화된 각 토큰의 확률 P(ti|t<i)을 구함으로써 효과적으로 얻을 수 있습니다.
auto-regressive 특성을 활용하여, 관련 토큰들을 확률을 aggregate해 자기 일관성 점수 ρSC 및 자기 성찰 점수 ρSR를 계산합니다. 최종 점수 ρj = ρSC,j * ρSR,j / z로 산출됩니다. 이때 z는 정규화 상수로, 전체 분포를 0과 1 사이로 조정하는 역할을 합니다.
ρSC와 ρSR은 다음과 같이 계산됩니다:

이 방법은 LLM이 스스로 평가하도록 할 때도 자주 사용됩니다. 예를 들어, LLM에게 "이 추론 단계가 맞습니까?" 라고 묻고 다음 단어가 "Yes"일 확률에 따라 보상하는 방식입니다.
Selecting sentences
특정 토큰을 선택하거나 출력 로짓을 정규화하는 것 외에도, LLM-as-a-judge가 추출하는 콘텐츠는 하나의 문장이나 문단일 수 있습니다. 이 방법은 특히 복잡한 추론 과정이나 긴 텍스트에서 가장 관련성 높은 문장이나 문단을 선택해 평가하는 데 유용합니다. 추출된 문장이나 문단은 후속 처리나 최종 평가에 사용될 수 있으며, 이는 LLM-as-a-judge의 판단을 더 구체적이고 명확하게 만드는 데 도움을 줍니다.
Evaluation Pipeline
세 가지 과정을 완료한 후 최종 평가 E를 얻게 됩니다. 입력부터 출력까지의 이 단계들은 함께 LLM-as-a-judge 평가 파이프라인을 형성하며, 이는 그림 2.에 나타나 있습니다. 이 파이프라인은 그림 7.에 제시된 네 가지 시나리오에서 일반적으로 적용됩니다:
- 모델에 대한 LLM-as-a-judge
- 데이터에 대한 LLM-as-a-judge
- 에이전트에 대한 LLM-as-a-judge
- 추론/사고에 대한 LLM-as-a-judge

LLM-as-a-judge for Models
일반적으로 LLM을 평가하는 가장 좋은 방법은 인간의 판단이지만, 인간 주석을 수집하는 것은 비용이 많이 들고, 시간이 오래 걸리며, 노동 집약적입니다. 따라서 강력한 LLM(보통 GPT-4, Cluade, ChatGPT와 같은 Closed-source model)을 LLM 평가의 자동화된 대리자로 사용하는 것이 자연스러운 선택이 되었습니다. 이는 적절한 프롬프트 설계를 통해 평가 품질과 인간 판단에 대한 일치성을 기대할 수 있습니다.
그러나 이러한 독점 모델들의 API를 호출할 때 비용 문제가 여전히 존재합니다. 이는 특히 대규모 데이터에 대한 모델 검증이 빈번할 때 문제가 됩니다. 게다가, Closed-source LLM-as-a-judge는 API뒤의 모델이 잠재적으로 변경될 수 있기 때문에 재현성이 낮아지는 단점이 있습니다.
이에 대한 해결책으로 최근 몇몇 연구들은 오픈 소스 대안을 모색하기 시작했습니다:
- SelFee: ChatGPT로부터 생성물, 피드백, 수정된 생성물을 수집하고, 이를 활용해 LLaMA모델을 미세 조정하여 비평 모델을 구축합니다.
- Shepherd: 온라인 커뮤니티와 인간 주석으로부터 얻은 피드백 데이터를 사용하여 단일 응답에 대한 비평을 출력할 수 있는 모델을 훈련합니다.
- PandaLM: LLM 지시문 튜닝 최적화를 위한 쌍별 비교를 수행하는 모델을 훈련합니다.
- Zheng et al. 2만 개의 쌍별 비교 데이터셋으로 Vicuna를 미세 조정하여, 오픈 소스 모델을 더 비용 효율적인 대리자로서 탐구합니다.
이러한 노력들은 Closed-source 모델의 비용 문제와 재현성 문제를 해결하고, 더 개방적이로 비용 효율적인 방법으로 LLM 평가를 수행할 수 있는 가능성을 보여줍니다.
LLM-as-a-judge for Data
데이터 주석(data annotation)은 원시 데이터에 관련 정보를 라벨링하거나 생성하는 과정을 의미하며, 이는 머신러닝 모델의 효율성을 높이는 데 사용됩니다. 하지만 이 과정은 노동 집약적이고 비용이 많이 듭니다. LLLM의 등장은 LLM-as-a-judge를 통해 복잡한 데이터 주석 과정을 자동화할 수 있는 전례 없는 기회를 제공합니다.
주요 내용 및 방법은 다음과 같습니다:
- 데이터 소스: 대부분의 LLM-as-a-judge가 평가해야 하는 데이터는 모델이 생성하거나 대규모로 수집된 데이터입니다.
- 모델 정렬(Alignment)
- 언어 모델은 먼저 인간의 지시에 맞추는(supervised fine-tuning) 과정을 거칩니다. 이후, 강화 학습 기술을 통해 인간의 선호도에 맞추는 작업이 시도되었습니다.
- 가장 성공적인 방법은 인간 피드백을 이용해 보상 모델을 훈련하고 PPO를 사용해 언어 생성 정책 모델(policy model)을 얻는 RLHF 프레임워크입니다.
- 그러나 PPO 훈련 패러다임은 복잡한 코딩과 하이퍼파라미터 튜닝이 필요하며, 네 개의 모델을 요구하는 등 훈련이 어렵습니다. 이로 인해 더 간단하고 직관적인 방법으로 언어 모델을 인간 선호도에 맞추는 방안이 탐구되고 있습니다. *RLHF 프레임워크 공부 필요
- LLM-as-a-judge 활용 사례
- LLM-as-a-judge를 사용하여 서로 다른 응답이 인간 선호도에 얼마나 부합하는지를 평가합니다. 예시로 general LLM(ChatGPT 등)을 사용하여 인간 선호도와 더 잘 일치하도록 합니다. Alpaca 프롬프트를 샘플링 쿼리로 사용하여 다양한 모델의 응답을 생성하고, 이를 LLM-as-a-judge가 평가하여 인간 선호 점수(보상 점수)를 얻어 새 언어 모델 훈련에 활용합니다.
- 또 다른 연구들은 Supervised Fine-tuning(SFT) 모델 자체를 평가자로 사용하기로 합니다. 예를 들어, 후속 수정된 프롬프트(hindsight-modified prompts) 나 원칙 기반 자기 정렬(principle-driven self-alignment) 을 포함한 더 나은 정렬 데이터셋을 생성합니다. *뭔 소리...
- 도메인 데이터 생성 및 평가
- 도메인 특화된 모델 훈련 데이터 부족 문제를 해결하기 위해, LLM-as-a-judge가 도메인 데이터 생성 및 평가에 활용됩니다.
- 예: WizardMath, Instruction Reward Model(IRM)을 평가자로 사용하여 세 가지 측면(정의, 정밀성, 완전성)에 걸쳐 발전된 지시문의 품질을 판단합니다. ChatGPT와 Wizard-E를 사용해 각 지시문에 대해 2-4개의 발전된 지시문을 생성하고, Wizard-E를 통해 이들 지시문의 품직을 순위화합니다. *IRM이 뭐지..
- 자체 학습(self-taught) 평가자
- LLM-as-a-judge에만 의존한 데이터 주석은 모델 성능의 빠른 향상과 함께 주석 데이터 가치가 감소하는 문제를 일으킵니다.
- Self-Taught Evaluator와 같은 접근 방식은 인간 주석 없이 합성 훈련 데이터를 활용하여 LLM-as-a-judge를 훈련시키는 방법을 제공합니다. 이 방법은 다음과 같은 순환 과정을 포함합니다:
- 라벨이 없는 지시문에서 시작
- 모델로부터 대조되는 출력(constrasting outputs)을 생성
- 이 출력을 사용해 추론 과정과 최종 판단을 생성하는 LLM-as-a-judge를 훈련
- 반복을 통해 평가자는 자신이 정제한 예측을 학습하며 지속적으로 개선됨
- *오류 누적은..? 자기가 합성한 데이터를 이용해 학습하면 오류가 누적되지 않나...
- 멀티 모달 데이터 평가
- 최근의 연구는 멀티모달 대형 언어 모델(MLLM)에서 시각-언어 불일치로 인한 환각(hallucination)을 해결하는 데 집중하고 있습니다.
- RLHF 및 사실 증강 RLHF(Factually Augmented RLHF)와 같은 기술을 사용해 모델 정렬(alignment)을 개선하고, 구조화된 정답 데이터와 이미지 캡션을 통합해 환각 감지 능력을 향상시킵니다. *사실 증강 RLHF..?
- MLLM-as-a-judge와 같은 벤치마크는 점수화, 쌍별 비교, 배치 순위 지정과 같은 작업을 통해 모델을 평가하며 인간 선호도 정렬의 한계를 보여줍니다.
- 지속적인 문제로는 편향(예: 위치, 장황함)과 환각 현상이 있으며, GPT-4V와 같은 고급 모델에서도 해당 도전 과제가 남아 있습니다. 쌍별 비교 작업이 인간 판단과 더 잘 맞지만, 점수화와 배치 순위 지정은 신뢰할 수 있는 배포를 위해 상당한 개선이 필요합니다. *MLLM-as-a-judge..?
LLM-as-a-judge for Agents
에이전트에 LLM-as-a-judge를 적용하는 방법에는 두 가지가 있습니다:
- 전체 과정 평가: 지능형 에이전트의 전체 과정을 평가하는 방법
- 특정 단계 평가: 에이전트 프레임워크 프로세스의 특정 단계에서 평가하는 방법
이 두 가지 접근 방식은 그림 8.에 간략히 설명되어 있습니다.

LLM-as-a-judge for Resoning/Thinking
추론(resoning)은 논리, 논증, 증거를 적용하여 결론을 도출하는 인지 과정으로, 의사결정, 문제해결, 비판적 분석과 같은 지적 작업의 중심에 있습니다. 추론은 본질적으로 판단보다 더 요구가 많고 다면적이지만, 논리적 일관성을 보장하고, 중간 단계를 정제하며, 결과의 명확성을 확보하기 위해 판단에 의존하는 경우가 많습니다. 이런 의미에서 LLM-as-a-judge는 LLM의 추론 능력을 향상시키는 데 필수적인 도구가 됩니다.
추론이나 사고 능력을 향상시키기 위한 LLM-as-a-judge의 역할은 두 가지 프레임워크로 이해할 수 있습니다: 훈련 시간과 테스트 시간
- 훈련 단계
- LLM-as-a-judge는 강화 학습 패러다임 내에서 보상 모델 또는 데이터 및 프로세스 평가자로 자주 작동합니다.
- 이를 통해 단계별 검증, 직접 선호 최적화(Direct Perference Opimizeation, DPO), 자기 정제(self-refinement)와 같은 매커니즘을 통해 고품질 추론 데이터셋을 생성할 수 있습니다. *DPO..?
- 테스트 단계
- LLM-as-a-judge는 최상의 추론 경로를 평가하고 선택하는 데 매우 중요합니다.
- 예를 들어, 여러 추론 결과를 생성하는 "Best-of-N" 생성 시나리오에서, 판단자는 가장 정확하고 일관된 응답을 결정합니다.