
Cycles Per Instruction (Throughput)
[Computer Architecture] Computer Abstractions & Technology | Week 2
Performance 컴퓨터의 성능을 결정짓는 요소들은 매우 많습니다. 그리고 성능을 보여주는 지표 또한 매우 많습니다. 이에 대해 살펴봅니다. Response Time and Throughput Response time(응답 시간): 응답 시간
hw-hk.tistory.com
앞선 글에서도 살펴봤듯, 평균 CPI는 가중 평균 CPI입니다.
이는 Instruction당 CPI x Instruction의 상대 빈도를 통해서 구할 수 있습니다.
예를 들어보겠습니다:
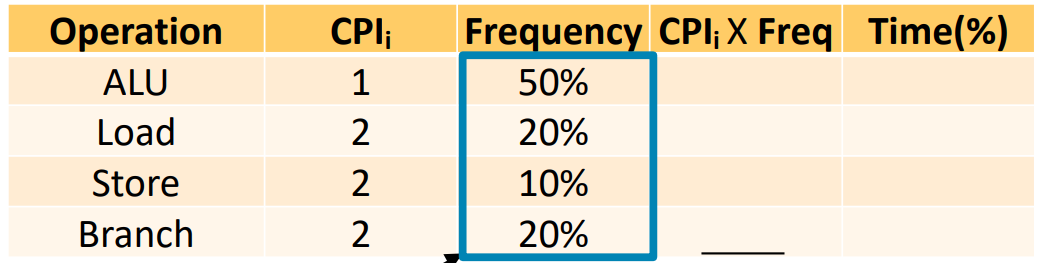
다음과 같은 경우 Avg. CPI는 뭘까요?
(weighted) Average CPI = ΣCPI x frequency
= (CPI_1 x freq_1) + (CPI_2 x freq_2) + (CPI_3 x freq_3) + (CPI_4 x freq_4)
= (1 x 0.5) + (2 x 0.2) + (2 x 0.1) + (2 x 0.2)
= 1.5
그냥 전체 CPI 수 / 명령의 종류 수 하여 Avg. CPI를 구한다면 이는 틀린것입니다. *(1 + 2 + 2 + 2) / 4 = 1.75
각 명령의 시간 점유율 또한 구해볼 수 있습니다.
각 명령당 CPU Time = CPI x IC x Clock_period 이므로,
Clock_period는 같은 컴퓨터이기에 같다고 두면, CPI x freq의 비율로 구할 수 있습니다.
ALU, Load, Store, Branch 명령 각각 33%, 27%, 13%, 27%를 차지함을 알 수 있습니다.
이를 통해 그냥 각 명령의 CPI만을 통해서 Time을 계산하는 것은 무의미함을 알 수 있습니다.
+ 왜 하는건진 모르겠지만 Branch Operation에 대해 짚고 넘어갑니다.
branch instruction은 if나 switch같은 조건 명령문을 말합니다. 이에 branch instruction은 기본으로 3cycles를 확보해놓는데, 조건을 판단하는 시간을 미리 확보해놓은 것입니다(만약 조건을 확인하지도 않고 넘어가면 안되기 때문에). 따라서 이상적인 경우 다른 명령들의 CPI가 1이라고 할 때 branch opertion은 CPI가 4인 것입니다.

이렇게 branch를 위해 3cycle을 확보해놓은 경우 Avg.CPI는 1.9입니다.
이는 미리 확보하지 않는 컴퓨터에 비해 1/1.9배, 즉 0.52배 빠릅니다. 즉 더 느려지는 것입니다.
*Instruction Count와 Clock period는 같을 것이기 때문에 Avg.CPI만을 통해 CPU time을 비교할 수 있습니다.
What Happened to Clock Rates and Why?
잠깐 집적회로 기술에 대해 살펴보고 가려고합니다.
CMOS IC(집적회로기술)에서 전력은 다음과 같은 식으로 정의됩니다:
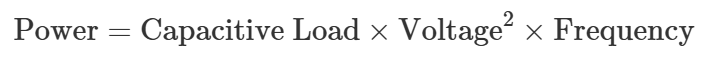
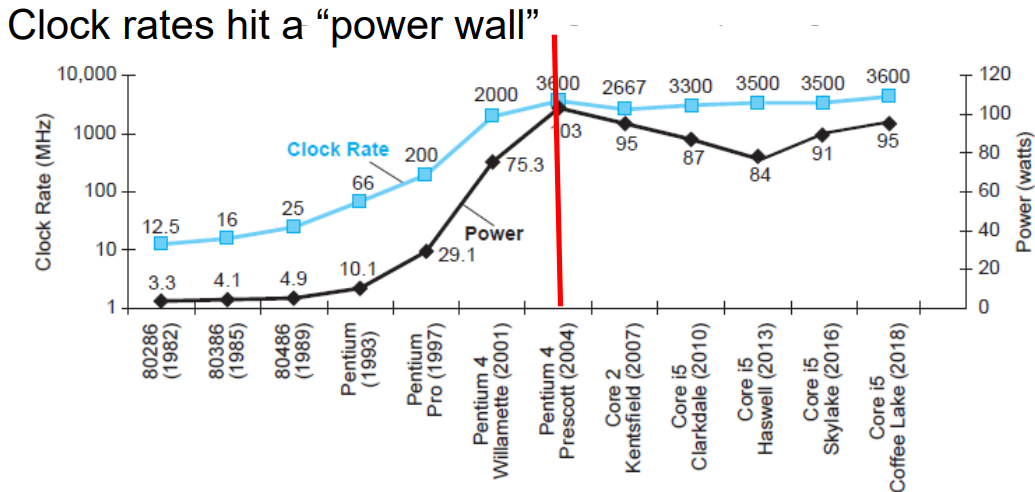
2000년대 초반까지는 기존의 Clock Rate가 낮았기 때문에 계속해서 높일 수 있었습니다. 하지만 frequency가 증가하면 발열이 일어나는 문제가 발생했고, 이를 해결하기 위해 전압을 기존 5v정도에서 1v정도로 낮췄습니다. 그렇게 하여 전력 소모를 어느정도 유지하면서 Clock Rate를 늘릴 수 있었는데, 어느 수준에 다다라서 더 올릴 수는 없게 되었습니다(전압을 1v이하로 낮추는 것은 불가능하기 때문에). 그렇게 Clock Rate는 power wall에 부딪혔고 성능을 올리기 위해서 core의 수를 늘리는 방향으로 진화했습니다.
이렇게 더 이상 전압을 낮출 수도 없고 열 때문에 clock rate도 올릴 수도 없는 상황에서
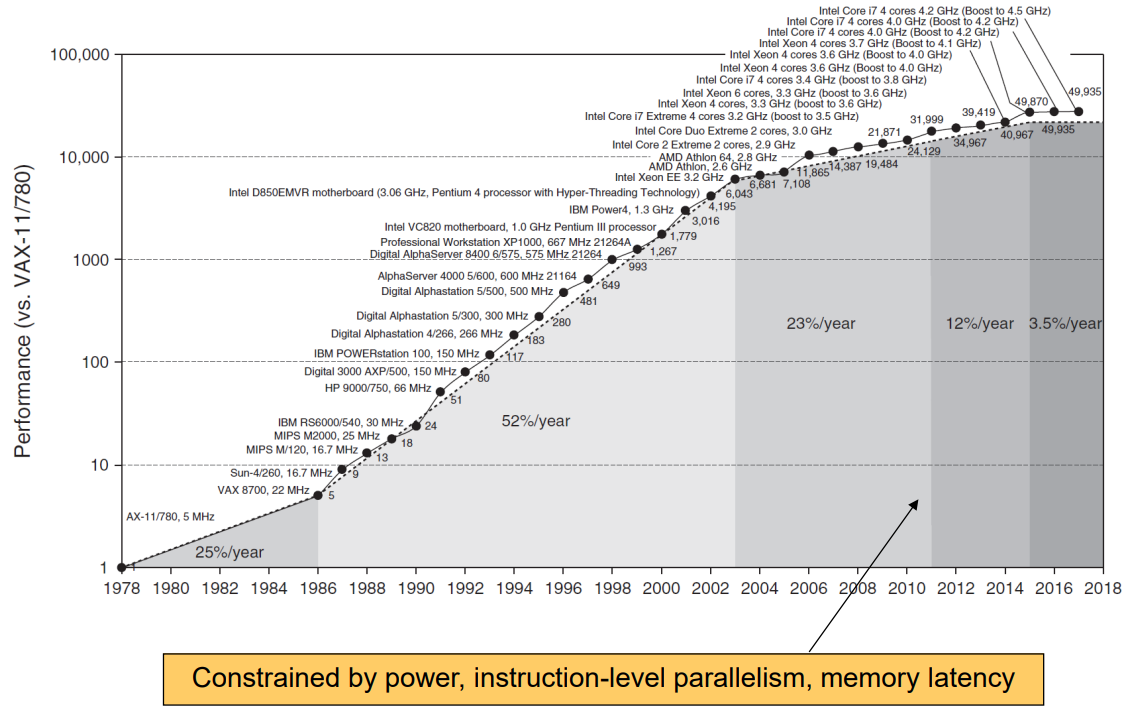
집적회로의 결함율과 면적의 관계에 의해 코어의 수를 무작정 늘릴 수도 없게 되었습니다.

그렇게 processor의 성능은 정체기를 맞았습니다.
Multiprocessors
이런 상황에서 CPU의 성능을 끌어올리기 위해서 parallel program의 개념이 출발했습니다. 즉, multi-core의 기능을 충분히 활용하기 위해서입니다. 하지만 parallel programming은 load balancing이나 data들 간의 communication과 동기화 문제들 등 많은 오버헤드들이 존재하기에 매우 프로그래밍하기 어렵다는 단점이 있습니다.
이런 parellel programming은 하드웨어 수준에서 다양한 명령들을 동시에 수행할 수 있다는 점에서 instruction수준의 parallelism과는 차이점이 있습니다.
SPEC CPU Benchmark
이렇게 CPU의 하드웨어적인 성능 뿐만 아니라 다양한 측면에서의 성능이 필요해짐에 따라 SPEC CPU Benchmark가 등장했습니다. SEPC은 Standard Performance Evaluation Corp이라는 회사가 만든 프로그램으로 다양한 평가 지표들이 존재합니다. 예를 들어 SPECspeed2017 integer의 경우 floating-point연산이 없는 CPU의 연산만을 평가하기 위한 프로그램입니다. 또한 SPECspeed2017 floating-point의 경우 FP연산만을 평가하기 위한 프로그램입니다.
Pitfall: Amdahl's law
이런 성능 평가에는 함정이 존재할 수 있습니다.컴퓨터의 한 측면이 개선되어도 그 한 측면의 개선의 크기에 비례하여 전체 성능이 향상되기를 기대하는 것입니다.
이런 함정을 피하기 위해 Amdahl's law가 등장했습니다.이는 다음과 같은 식으로 정리됩니다:

이를 해석하자면,
개선하지 않은 부분에 대해서는 성능 향상에서 제외시키고 개선을 한 부분에 대해서만 성능 향상에 적용을 해야한다는 뜻입니다.
예를 들어보겠습니다.

"만약 어떤 한 프로그램이 동작하는데 100초가 걸리는 기계가 있다고 가정해보자. 이때 곱셈 연산을 하는데만 80초가 소모되었다. 해당 프로그램을 4배 빠르게 실행시키기 위해서는 곱셈연산을 어느정도로 빠르게 향상시켜야할까?"
향상된 기계의 시간 T_new = 100s / 4배 = 25s 가 소요되어야합니다.이때 Amdahl's law에 의해 새로운 시간 T_new는 다음과 같이 정의됩니다.
100s / 4 = 25s= 20s(unaffected) + 80s(affected) / improvement factor
80s / improvement factor = 5s
improvement factor = 16
즉 곱셈 연산을 16배 성능 향상시켜야 가능합니다.그렇다면 해당 프로그램을 수행하는 시간을 5배 빠르게는 가능할까요?
정답은 불가능입니다.만약 5배 빠르게 하고 싶다면 T_new가 20s인데, 곱셈연산이 아닌 다른 연산만 수행해도 20s이기 때문에곱셈 연산에 드는 시간을 0s로 줄여야합니다.
즉 Amdahl's law는 일정한 부분에 대한 성능 향상으로는 한계가 있을 수 있다는 점을 말합니다.
+ 이걸 왜 하는지 모르겠지만 또 ..
Fallacy: Low Power at Idle
일반적으로 낮은 데이터 load는 낮은 전력을 필요로한다 생각합니다.하지만 아닙니다.

위 그림에 나와있듯, load가 절반으로 줄었음에도 불구하고 전력 소모는 50% 줄지 않았습니다. 즉 Power와 Load가 선형관계를 갖지는 않는다는 것입니다.
여기서 말하고자 함은 성능을 위한 디자인과 전력 효율을 위한 디자인은 서로 다른 차원의 문제라는 것입니다.
Pitfall: MIPS as a Performance Metric
MIPS는 Millions of Instructions Per Second의 약자로 단위시간 동안 실행되는 백만개의 명령의 수입니다. 이는 얼핏보면 성능과 직결되어 보입니다. 단위 시간당 수행하는 명령의 수가 많으면 당연히 CPU Time도 줄어들거같기 때문입니다.
MIPS는 다음과 같이 정의됩니다.

(1) 이는 서로 다른 ISA의 차이를 반영하지 않습니다. *factor에 IC가 없기 때문에
(2) 또한 같은 컴퓨터 내의 다른 프로그램의 차이를 반영하지 않습니다. *같은 컴퓨터의 경우 CPI와 Clock rate가 같기 때문에, 이때 CPI는 Avg.CPI?
예를 들어보겠습니다.
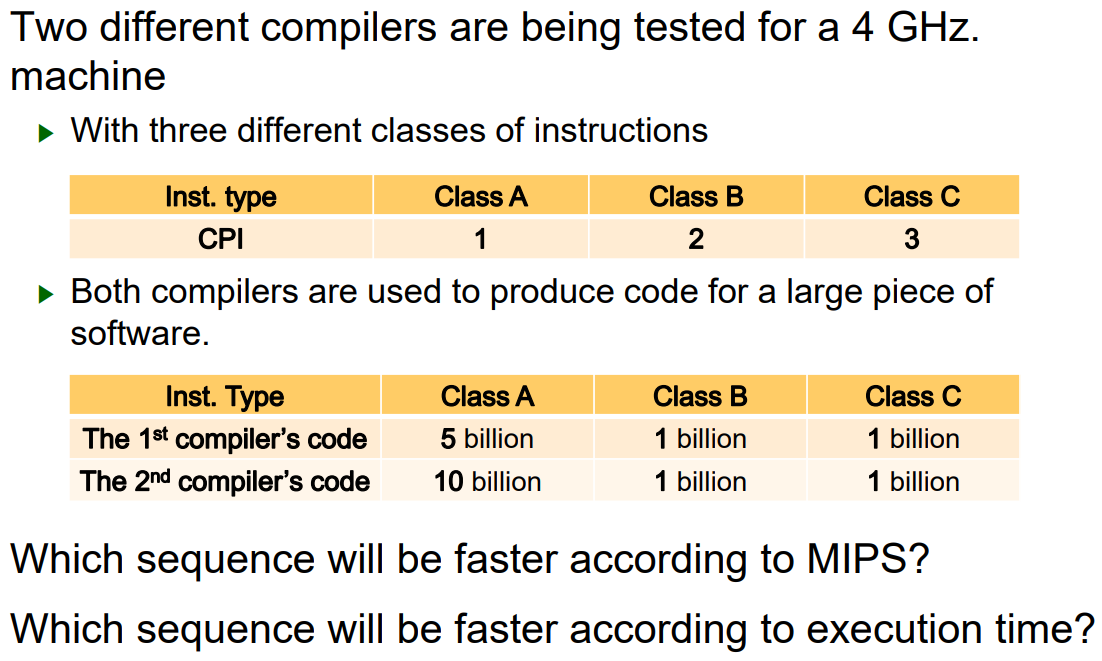
Ex_time_1 = (5 x 10^9 x 1 + 1 x 10^9 x 2 + 1 x 10^9 x 3) / 4 x 10^9 Hz = 2.5sec
Ex_time_2 = (10 x 10^9 x 1 + 1 x 10^9 x 2 + 1 x 10^9 x 3) / 4 x 10^9 Hz = 3.75sec
CPI_1 = (10 x 10^9) / (7 x 10^9) = 10 / 7
CPI_2 = (15 x 10^9) / (12 x 10^9) = 5 / 4
MIPS_1 = (7 x 10^9) / (2.5 x 10^6) = 2800MIPS
MIPS_2 = (12 x 10^9) / (3.75 x 10^6) = 3200MIPS
= MIPS, CPI는 2번 컴파일러의 코드가 우수하지만, 실행 시간의 측면에서는 1번이 우수하다.
즉, CPI나 MIPS는 성능에 대한 간접적인 지표는 되지만 Excution Time과 같이 직접적인 성능을 비교하는것과는 독립적으로 해석될 수도 있다.
'[학교 수업] > [학교 수업] Computer Architecture' 카테고리의 다른 글
Cycles Per Instruction (Throughput)
[Computer Architecture] Computer Abstractions & Technology | Week 2
Performance 컴퓨터의 성능을 결정짓는 요소들은 매우 많습니다. 그리고 성능을 보여주는 지표 또한 매우 많습니다. 이에 대해 살펴봅니다. Response Time and Throughput Response time(응답 시간): 응답 시간
hw-hk.tistory.com
앞선 글에서도 살펴봤듯, 평균 CPI는 가중 평균 CPI입니다.
이는 Instruction당 CPI x Instruction의 상대 빈도를 통해서 구할 수 있습니다.
예를 들어보겠습니다:
다음과 같은 경우 Avg. CPI는 뭘까요?
(weighted) Average CPI = ΣCPI x frequency
= (CPI_1 x freq_1) + (CPI_2 x freq_2) + (CPI_3 x freq_3) + (CPI_4 x freq_4)
= (1 x 0.5) + (2 x 0.2) + (2 x 0.1) + (2 x 0.2)
= 1.5
그냥 전체 CPI 수 / 명령의 종류 수 하여 Avg. CPI를 구한다면 이는 틀린것입니다. *(1 + 2 + 2 + 2) / 4 = 1.75
각 명령의 시간 점유율 또한 구해볼 수 있습니다.
각 명령당 CPU Time = CPI x IC x Clock_period 이므로,
Clock_period는 같은 컴퓨터이기에 같다고 두면, CPI x freq의 비율로 구할 수 있습니다.
ALU, Load, Store, Branch 명령 각각 33%, 27%, 13%, 27%를 차지함을 알 수 있습니다.
이를 통해 그냥 각 명령의 CPI만을 통해서 Time을 계산하는 것은 무의미함을 알 수 있습니다.
+ 왜 하는건진 모르겠지만 Branch Operation에 대해 짚고 넘어갑니다.
branch instruction은 if나 switch같은 조건 명령문을 말합니다. 이에 branch instruction은 기본으로 3cycles를 확보해놓는데, 조건을 판단하는 시간을 미리 확보해놓은 것입니다(만약 조건을 확인하지도 않고 넘어가면 안되기 때문에). 따라서 이상적인 경우 다른 명령들의 CPI가 1이라고 할 때 branch opertion은 CPI가 4인 것입니다.
이렇게 branch를 위해 3cycle을 확보해놓은 경우 Avg.CPI는 1.9입니다.
이는 미리 확보하지 않는 컴퓨터에 비해 1/1.9배, 즉 0.52배 빠릅니다. 즉 더 느려지는 것입니다.
*Instruction Count와 Clock period는 같을 것이기 때문에 Avg.CPI만을 통해 CPU time을 비교할 수 있습니다.
What Happened to Clock Rates and Why?
잠깐 집적회로 기술에 대해 살펴보고 가려고합니다.
CMOS IC(집적회로기술)에서 전력은 다음과 같은 식으로 정의됩니다:
2000년대 초반까지는 기존의 Clock Rate가 낮았기 때문에 계속해서 높일 수 있었습니다. 하지만 frequency가 증가하면 발열이 일어나는 문제가 발생했고, 이를 해결하기 위해 전압을 기존 5v정도에서 1v정도로 낮췄습니다. 그렇게 하여 전력 소모를 어느정도 유지하면서 Clock Rate를 늘릴 수 있었는데, 어느 수준에 다다라서 더 올릴 수는 없게 되었습니다(전압을 1v이하로 낮추는 것은 불가능하기 때문에). 그렇게 Clock Rate는 power wall에 부딪혔고 성능을 올리기 위해서 core의 수를 늘리는 방향으로 진화했습니다.
이렇게 더 이상 전압을 낮출 수도 없고 열 때문에 clock rate도 올릴 수도 없는 상황에서
집적회로의 결함율과 면적의 관계에 의해 코어의 수를 무작정 늘릴 수도 없게 되었습니다.
그렇게 processor의 성능은 정체기를 맞았습니다.
Multiprocessors
이런 상황에서 CPU의 성능을 끌어올리기 위해서 parallel program의 개념이 출발했습니다. 즉, multi-core의 기능을 충분히 활용하기 위해서입니다. 하지만 parallel programming은 load balancing이나 data들 간의 communication과 동기화 문제들 등 많은 오버헤드들이 존재하기에 매우 프로그래밍하기 어렵다는 단점이 있습니다.
이런 parellel programming은 하드웨어 수준에서 다양한 명령들을 동시에 수행할 수 있다는 점에서 instruction수준의 parallelism과는 차이점이 있습니다.
SPEC CPU Benchmark
이렇게 CPU의 하드웨어적인 성능 뿐만 아니라 다양한 측면에서의 성능이 필요해짐에 따라 SPEC CPU Benchmark가 등장했습니다. SEPC은 Standard Performance Evaluation Corp이라는 회사가 만든 프로그램으로 다양한 평가 지표들이 존재합니다. 예를 들어 SPECspeed2017 integer의 경우 floating-point연산이 없는 CPU의 연산만을 평가하기 위한 프로그램입니다. 또한 SPECspeed2017 floating-point의 경우 FP연산만을 평가하기 위한 프로그램입니다.
Pitfall: Amdahl's law
이런 성능 평가에는 함정이 존재할 수 있습니다.컴퓨터의 한 측면이 개선되어도 그 한 측면의 개선의 크기에 비례하여 전체 성능이 향상되기를 기대하는 것입니다.
이런 함정을 피하기 위해 Amdahl's law가 등장했습니다.이는 다음과 같은 식으로 정리됩니다:
이를 해석하자면,
개선하지 않은 부분에 대해서는 성능 향상에서 제외시키고 개선을 한 부분에 대해서만 성능 향상에 적용을 해야한다는 뜻입니다.
예를 들어보겠습니다.
"만약 어떤 한 프로그램이 동작하는데 100초가 걸리는 기계가 있다고 가정해보자. 이때 곱셈 연산을 하는데만 80초가 소모되었다. 해당 프로그램을 4배 빠르게 실행시키기 위해서는 곱셈연산을 어느정도로 빠르게 향상시켜야할까?"
향상된 기계의 시간 T_new = 100s / 4배 = 25s 가 소요되어야합니다.이때 Amdahl's law에 의해 새로운 시간 T_new는 다음과 같이 정의됩니다.
100s / 4 = 25s= 20s(unaffected) + 80s(affected) / improvement factor
80s / improvement factor = 5s
improvement factor = 16
즉 곱셈 연산을 16배 성능 향상시켜야 가능합니다.그렇다면 해당 프로그램을 수행하는 시간을 5배 빠르게는 가능할까요?
정답은 불가능입니다.만약 5배 빠르게 하고 싶다면 T_new가 20s인데, 곱셈연산이 아닌 다른 연산만 수행해도 20s이기 때문에곱셈 연산에 드는 시간을 0s로 줄여야합니다.
즉 Amdahl's law는 일정한 부분에 대한 성능 향상으로는 한계가 있을 수 있다는 점을 말합니다.
+ 이걸 왜 하는지 모르겠지만 또 ..
Fallacy: Low Power at Idle
일반적으로 낮은 데이터 load는 낮은 전력을 필요로한다 생각합니다.하지만 아닙니다.
위 그림에 나와있듯, load가 절반으로 줄었음에도 불구하고 전력 소모는 50% 줄지 않았습니다. 즉 Power와 Load가 선형관계를 갖지는 않는다는 것입니다.
여기서 말하고자 함은 성능을 위한 디자인과 전력 효율을 위한 디자인은 서로 다른 차원의 문제라는 것입니다.
Pitfall: MIPS as a Performance Metric
MIPS는 Millions of Instructions Per Second의 약자로 단위시간 동안 실행되는 백만개의 명령의 수입니다. 이는 얼핏보면 성능과 직결되어 보입니다. 단위 시간당 수행하는 명령의 수가 많으면 당연히 CPU Time도 줄어들거같기 때문입니다.
MIPS는 다음과 같이 정의됩니다.
(1) 이는 서로 다른 ISA의 차이를 반영하지 않습니다. *factor에 IC가 없기 때문에
(2) 또한 같은 컴퓨터 내의 다른 프로그램의 차이를 반영하지 않습니다. *같은 컴퓨터의 경우 CPI와 Clock rate가 같기 때문에, 이때 CPI는 Avg.CPI?
예를 들어보겠습니다.
Ex_time_1 = (5 x 10^9 x 1 + 1 x 10^9 x 2 + 1 x 10^9 x 3) / 4 x 10^9 Hz = 2.5sec
Ex_time_2 = (10 x 10^9 x 1 + 1 x 10^9 x 2 + 1 x 10^9 x 3) / 4 x 10^9 Hz = 3.75sec
CPI_1 = (10 x 10^9) / (7 x 10^9) = 10 / 7
CPI_2 = (15 x 10^9) / (12 x 10^9) = 5 / 4
MIPS_1 = (7 x 10^9) / (2.5 x 10^6) = 2800MIPS
MIPS_2 = (12 x 10^9) / (3.75 x 10^6) = 3200MIPS
= MIPS, CPI는 2번 컴파일러의 코드가 우수하지만, 실행 시간의 측면에서는 1번이 우수하다.
즉, CPI나 MIPS는 성능에 대한 간접적인 지표는 되지만 Excution Time과 같이 직접적인 성능을 비교하는것과는 독립적으로 해석될 수도 있다.