
Instruction Set
Instruction set은 매우 다양한 종류가 있습니다. (1) 초창기 instruction sets는 매우 간단한 구현들로 이루어졌습니다. (2) 그러나 다양한 기능들을 추가한 instruction set인 CISC가 등장했습니다. 하지만 다양한 기능들을 구현하기 위해 명령 포맷을 가변 길이로 설정했기 때문에 디코딩하는데 시간이 매우 오래 걸렸습니다. (3) 이에 명령들의 포맷의 수를 줄이고, 간단한 명령들로만 이루어진 RISC구조가 등장했습니다. 이는 속도를 올리는데 집중한 구조였습니다.
The MIPS Instruction Set
해당 수업에서는 RISC의 대표적인 예시인 MIPS 기술에 대해 알아볼 것입니다.
Arithmetic Operations
어떤 두 수를 더하거나 빼는 경우 총 3개의 피연산자가 필요합니다. *two sources and one destination
add a, b, c # a gets b + c
위 예시는 b, c를 sources로 하여 연산의 결과를 a에 넣어주는 명령입니다. 모든 arithmetic operation들은 다음과 같은 형태입니다.
이렇듯 명령어 포맷을 간단하게, 통일되어 설정하는 것을 통해 구현을 쉽게 할 수 있었으며, 적은 비용으로 높은 성능을 달성할 수 있었습니다. *Design Principle 1: Simplicity favors regularity
C code:
f = (g + h) - (i + j);
Complied MIPS code:
add t0, g, h # temp t0 = g + h
add t1, i, j # temp t1 = i + j
sub f, t0, t1 # temp f = t0 - t1
Register Operands
Arithmetic instructions들은 register를 사용합니다. 그렇기에 register 피연산자에 대해 알아보겠습니다.
MIPS는 32개의 32-bit register file을 갖고있습니다. *32개의 register들을 5-bit로 표현할 수 있다는 특징이 중요합니다. 이런 한 register의 크기를 일반적으로 word라고 부릅니다. 즉, word는 CPU의 구조에 따라 달라질 수 있습니다. MIPS의 경우 word는 32-bit인 것입니다.
register operand는 일반적으로 $를 앞에 붙입니다:$t0, $t1, ..., $t9 for temporary values,$s0, $s1, ..., $s7 for saved variables
register는 공간이 작기 때문에 빠르게 데이터를 읽거나 쓰고, 접근할 수 있습니다. 반면 메모리의 경우는 매우 많은 수의 location들이 존재하며, 공간이 register에 비해 매우 크기 때문에 속도가 느립니다. *Design Principle 2: Smaller is faster
C code:
f = (g + h) - (i + j);
Compiled MIPS code:
add $t0, g, h # temp t0 = g + h
add $t1, i, j # temp t1 = i + j
sub f, $t0, $t1 # temp f = t0 - t1
# g, h, i, j를 register로 옮겨서 계산함을 고려한다면..
add $t0, $s1, $s2
add $t1, $s3, $s4
sub $s0, $t0, $t1
Memory Operands
메모리에는 매우 다양한 자료구조 및 데이터들이 존재합니다. 이런 데이터들을 연산하기 위해서는 register로 가져와야합니다. (1) 이때 memory에 있는 데이터를 register로 가져오는 것을 load, (2) 연산의 결과가 저장되어있는 register의 값을 memory로 옮기는 것을 store라고 부릅니다. *참고로 이는 MIPS의 특징입니다. MIPS는 RISC로 피연산자의 종류를 register만으로 줄임으로써 속도를 높일 수 있었습니다. 반면 CISC의 경우 피연산자의 종류를 memory까지 사용할 수 있도록 함으로써 강력한 기능을 제공했지만 속도가 줄어드는 단점이 있었습니다.
메모리의 주소는 byte (8-bit)단위로 이루어져있습니다. 그렇다면 word단위 (32-bit)로 주소를 본다면 주소는 4의 배수입니다. 즉, 0번째 주소 다음의 word는 4번째 주소인 것입니다.
MIPS는 Big Endian입니다. Endian은 저장되어있는 데이터를 읽는 방법에 대한 것입니다.
Big Endian의 경우 최우선바이트 (Most Significant Byte, MSB)가 word address인 것이고,
Little Endian의 경우 가장 왼쪽의 바이트 (Rightmost Byte)가 word address인 것입니다.
https://softtone-someday.tistory.com/20
[개념정리] 빅엔디안(Big Endian)과 리틀엔디안(Little Endian)
통신을 하다 보면 통신 패킷이 반대로 나갈 때가 있습니다. 예를 들면 1 2 3 4를 보냈는데 막상 받는 쪽에서 들어온 패킷은 4 3 2 1인 거죠 이는 컴퓨터 CPU의 데이터를 저장하는 순서에서 발생하는
softtone-someday.tistory.com
C code:
g = h + A[8];
Compiled MIPS code (A가 word단위 자료구조인 경우):
lw $t0, 32($s3) # load word
add $s1, $s2, $t0
*이때 32($s3)에서 32는 offset으로 한 단위가 word이고 8번째 데이터이므로, 8*4 = 32가 offset이 됩니다. 또한 $s3를 base register라고 부릅니다.
C code:
A[12] = h + A[8]
Compiled MIPS code:
lw $t0, 32($s3) # load word
add $t0, $s2, $t0
sw $t0, 48($s3) # store word
Register vs. Memory
register는 memory에 비해 빠릅니다. 그래서 memory에 있는 데이터를 register에 load한 후 연산하고, 그 결과를 memory로 store하는 것입니다. Compiler는 최대한 register를 잘 활용하는 것이 중요합니다. 즉, register 최적화는 매우 중요한 문제입니다. *예를 들어 만약 register에 load해야하는 데이터가 너무 많으면 가장 덜 쓰는 데이터를 memory로 옮겨둡니다.
Immediate Operands
Constant data를 이용하여 매우 빠르게 연산할 수 있습니다. 이 경우 빼기 연산은 지원되지 않습니다. *어짜피 add로 -1을 하면 되니까
addi $s3, $s3, 4
addi $s2, $s1, -1 # No subtract immediate instruction. Just use a negative constant
이렇게 흔하게 사용하는 연산을 빠르게 할 수 있도록 지원해주면 결과적인 성능과 속도가 좋아질 수 있습니다. 즉, 많이 사용하는 상수들을 4byte가 아닌 작게 만들어서 load없이 연산을 수행할 수 있도록 지원해줍니다. *Design Principle 3: Make the common case fast
The Constant Zero
MIPS register 0 ($zero)는 상수 0을 나타내고 이는 덮어씌어지지 않습니다. 이는 매우 유용한데 예를 들어 register안에서의 데이터 이동을 mov 명령어 대신 add와 $zero를 이용해서 수행할 수 있습니다.
add $t2, $s1, $zero # move between registers
이는 mov연산자를 추가로 만들지 않음으로써 RISC를 달성함을 알 수 있습니다.
Unsigned Binary Integers
.. 뭐 간단합니다. 최상위 비트를 부호 비트로 사용하지 않는 2진수 표현입니다. n개의 bit을 사용하는 경우 0부터 +2^n - 1까지 나타낼 수 있습니다.
2s-Complement Signed Integers
이것도 간단합니다. 최상위 비트를 부호 비트로 사용하는 2진수 표현입니다. n개의 bit를 사용하는 경우 -2^n-1부터 +2^n-1 - 1까지 나타낼 수 있습니다. 이때 부호 비트 0은 0을 포함한 양수를, 부호 비트 1은 음수를 나타냅니다.
음수를 표현할 때는 양수에서 보수(1->0 or 0->1)를 취한 후 1을 더해주면 됩니다. 예를 들어
+2 = 0000 0000 ... 0010
-2 = 1111 1111 ... 1101 + 1
= 1111 1111 ... 1110 이 됩니다.
Sign Extension
register file의 크기는 word, 즉 32-bit입니다. 그렇다면 그 자리에 word보다 작은 크기의 데이터가 들어오는 경우 남는 자리는 어떻게 처리해야할까요? 이는 부호 비트로 나머지를 채워주면 됩니다. 이를 sign extension이라고 부릅니다. 예를 들어
+2 = 0000 0010 -> 0000 0000 0000 0010
-2 = 1111 1110 -> 1111 1111 1111 1110
이는 addi, lb(load byte), lh(load halfword), beq, bne 등의 MIPS operation에서 사용됩니다.
MIPS-32 ISA
MIPS-32 ISA에는 다음과 같은 명령 카테고리가 존재합니다:
- Computational
- Load/Store
- Jump and Branch
- Floating Point
- coprocessor
- Memory Management
- Special
이를 구현하기 위해서 3개의 instruction format을 지원합니다:
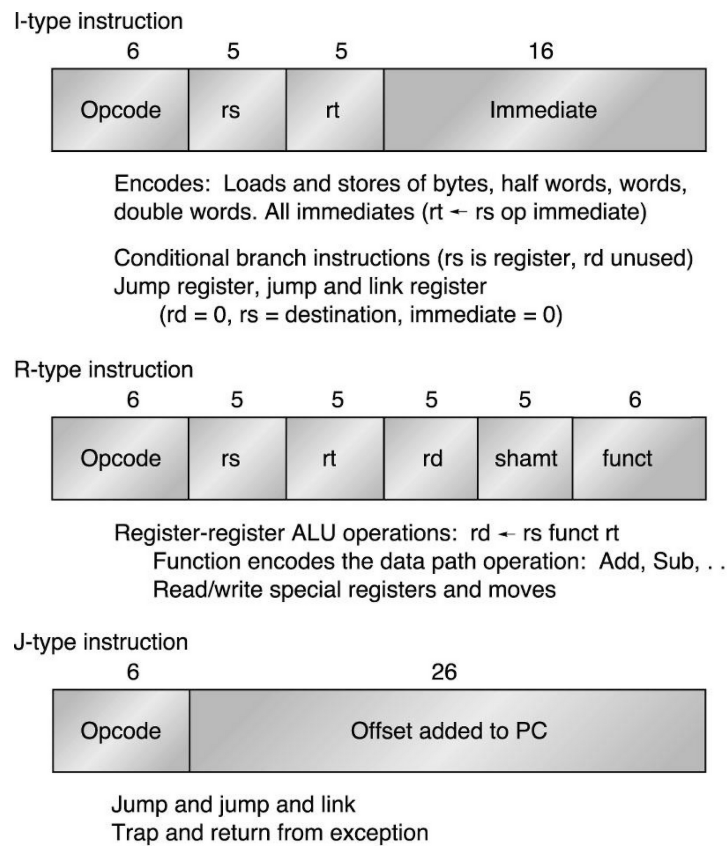
MIPS R-format Instructions
MIPS의 r-type은 다음과 같습니다:
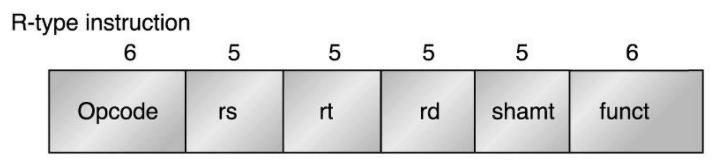
- op (6-bit): opcode. 명령을 나타내는 코드.
- rs (5-bit): 첫 번째 소스가 되는 레지스터 파일. *앞서 말했듯, 32개의 레지스터는 5개의 비트만으로 표현가능합니다.
- rt (5-bit): 두 번째 소스가 되는 레지스터 파일.
- rd (5-bit): 결과를 담는 레지스터 파일
- shamt (5-bit): shift 양 입니다. 이는 음수는 존재하지 않으며 5-bit이기에 0부터 31까지의 수를 담습니다. *어짜피 32가 넘어가면 register file의 크기상 의미가 없음
- funct (6-bit): function code. 실질적인 명령을 의미합니다. *r-format의 경우 opcode는 0이기에 funct에 실질적인 명령이 들어갑니다.
만약 다음과 같은 MIPS instruction이 존재한다면 다음과 같이 r-format으로 변경할 수 있습니다:
add $t0, $s1, $s2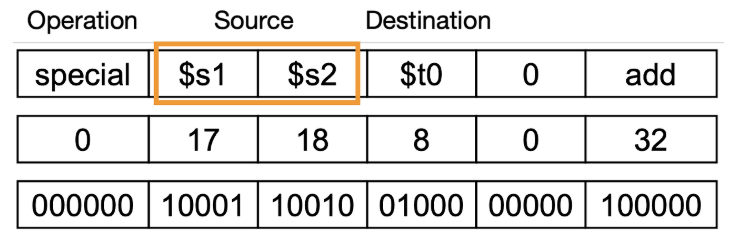
*이때 주의할 점은 assembly code에서는 destination, source1, source2 순서대로 나왔지만 R-format의 경우는 source1, source2, destination 순서이기 때문에 주의해야합니다.
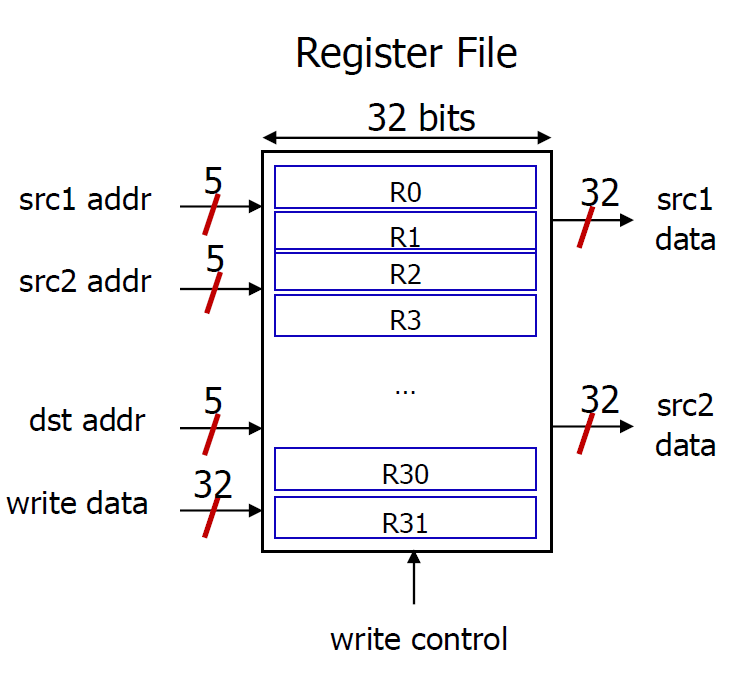
MIPS Register File
register file은 2개의 읽기 포트와 1개의 쓰기 포트로 이루어져있습니다. 그렇기 때문에 instruction들이 2개의 source와 하나의 destination을 갖는 것입니다.
- 레지스터는 메모리보다 빠르다.
- 그러나 레지스터의 수가 늘어나거나 포트의 수가 많아지면 집적도의 문제 때문에 속도가 느려진다.
- 레지스터의 주소는 5-bit로 접근가능하고, 이는 메모리로 접근하는 것보다 빠르고, code density의 관점에서도 유리합니다.
- 즉, 레지스터의 접근이 메모리의 접근보다 유리하다는 뜻이다.
Two Key Principles of Computers
1. instruction은 binary code로 표현되고 이는 데이터와 구분할 수 없습니다.
2. 프로그램도 데이터와 유사하게 binary code로 표현됩니다.
이는 binary number로 구성되어있는 파일로 프로그램을 넘겨주면, 잘 읽어들일 수 있다는 보장하에 상호 호환성이 있다고 볼 수 있습니다 (binary compatibility). 이런 호환성은 같은 ISA에서 이뤄질 수 있습니다.
Logical Operations

MIPS는 논리연산자도 제공합니다. *이때 NOT연산자는 nor을 통해 구현되는데 트릭을 통해 구현됩니다.
MIPS Shift Operations
R-format으로 나타내는데, shift연산의 경우는 source가 2개가 필요하지는 않기 때문에 하나의 source만을 사용합니다.
아래는 shift연산의 예시입니다:
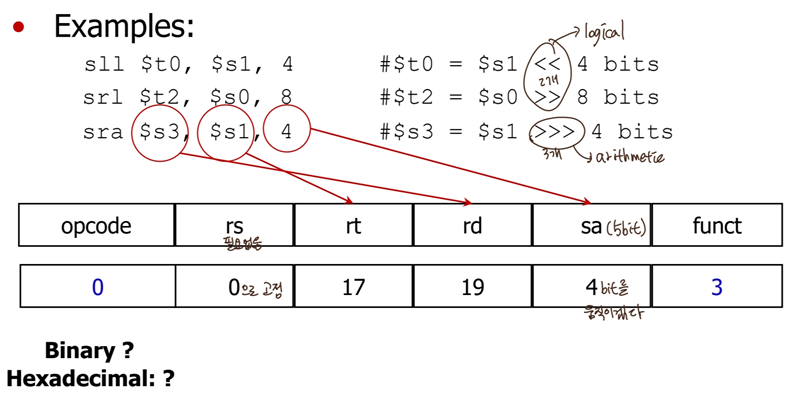
*sll의 경우, i만큼 이동했다면 2^i만큼 곱해진 값이 나옵니다. 반면 (unsigned의 경우에만) srl을 i만큼 이동했다면 2^i만큼 나눠진 값이 나옵니다.
아래는 bit-wise연산의 예시입니다:
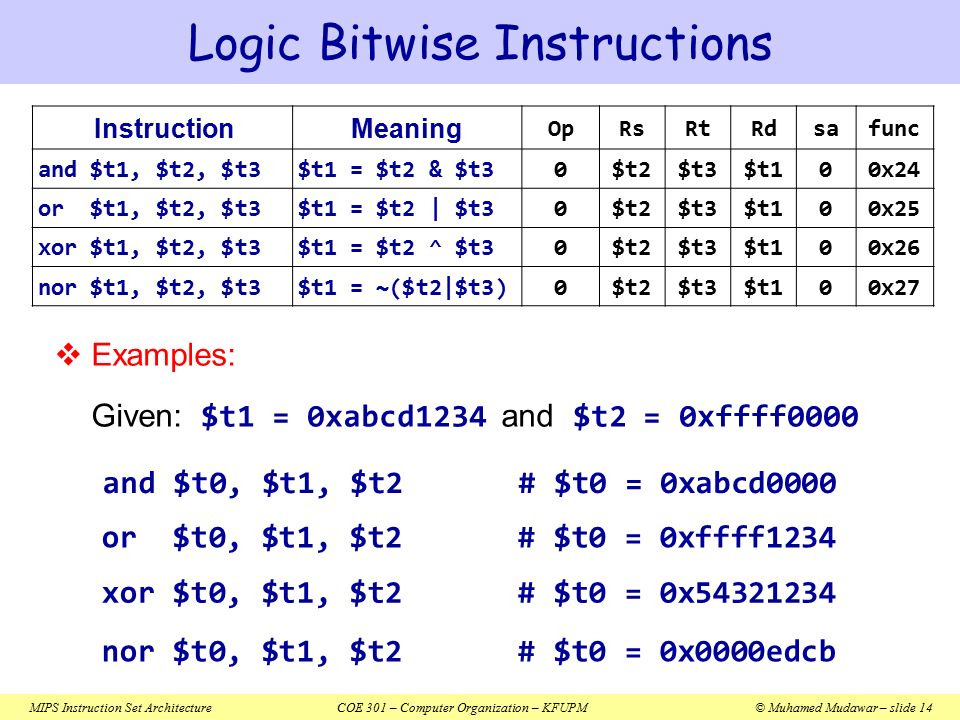
Not Operations
Not 연산자는 MIPS에서는 nor연산자를 통해 구현됩니다.
a NOR b == NOT (a OR b) 이므로 b를 $zero로 설정한다면,
a NOR 0 == NOT (a OR 0) == NOT a 가 됩니다.

'[학교 수업] > [학교 수업] Computer Architecture' 카테고리의 다른 글
Instruction Set
Instruction set은 매우 다양한 종류가 있습니다. (1) 초창기 instruction sets는 매우 간단한 구현들로 이루어졌습니다. (2) 그러나 다양한 기능들을 추가한 instruction set인 CISC가 등장했습니다. 하지만 다양한 기능들을 구현하기 위해 명령 포맷을 가변 길이로 설정했기 때문에 디코딩하는데 시간이 매우 오래 걸렸습니다. (3) 이에 명령들의 포맷의 수를 줄이고, 간단한 명령들로만 이루어진 RISC구조가 등장했습니다. 이는 속도를 올리는데 집중한 구조였습니다.
The MIPS Instruction Set
해당 수업에서는 RISC의 대표적인 예시인 MIPS 기술에 대해 알아볼 것입니다.
Arithmetic Operations
어떤 두 수를 더하거나 빼는 경우 총 3개의 피연산자가 필요합니다. *two sources and one destination
add a, b, c # a gets b + c
위 예시는 b, c를 sources로 하여 연산의 결과를 a에 넣어주는 명령입니다. 모든 arithmetic operation들은 다음과 같은 형태입니다.
이렇듯 명령어 포맷을 간단하게, 통일되어 설정하는 것을 통해 구현을 쉽게 할 수 있었으며, 적은 비용으로 높은 성능을 달성할 수 있었습니다. *Design Principle 1: Simplicity favors regularity
C code:
f = (g + h) - (i + j);
Complied MIPS code:
add t0, g, h # temp t0 = g + h
add t1, i, j # temp t1 = i + j
sub f, t0, t1 # temp f = t0 - t1
Register Operands
Arithmetic instructions들은 register를 사용합니다. 그렇기에 register 피연산자에 대해 알아보겠습니다.
MIPS는 32개의 32-bit register file을 갖고있습니다. *32개의 register들을 5-bit로 표현할 수 있다는 특징이 중요합니다. 이런 한 register의 크기를 일반적으로 word라고 부릅니다. 즉, word는 CPU의 구조에 따라 달라질 수 있습니다. MIPS의 경우 word는 32-bit인 것입니다.
register operand는 일반적으로 $를 앞에 붙입니다:$t0, $t1, ..., $t9 for temporary values,$s0, $s1, ..., $s7 for saved variables
register는 공간이 작기 때문에 빠르게 데이터를 읽거나 쓰고, 접근할 수 있습니다. 반면 메모리의 경우는 매우 많은 수의 location들이 존재하며, 공간이 register에 비해 매우 크기 때문에 속도가 느립니다. *Design Principle 2: Smaller is faster
C code:
f = (g + h) - (i + j);
Compiled MIPS code:
add $t0, g, h # temp t0 = g + h
add $t1, i, j # temp t1 = i + j
sub f, $t0, $t1 # temp f = t0 - t1
# g, h, i, j를 register로 옮겨서 계산함을 고려한다면..
add $t0, $s1, $s2
add $t1, $s3, $s4
sub $s0, $t0, $t1
Memory Operands
메모리에는 매우 다양한 자료구조 및 데이터들이 존재합니다. 이런 데이터들을 연산하기 위해서는 register로 가져와야합니다. (1) 이때 memory에 있는 데이터를 register로 가져오는 것을 load, (2) 연산의 결과가 저장되어있는 register의 값을 memory로 옮기는 것을 store라고 부릅니다. *참고로 이는 MIPS의 특징입니다. MIPS는 RISC로 피연산자의 종류를 register만으로 줄임으로써 속도를 높일 수 있었습니다. 반면 CISC의 경우 피연산자의 종류를 memory까지 사용할 수 있도록 함으로써 강력한 기능을 제공했지만 속도가 줄어드는 단점이 있었습니다.
메모리의 주소는 byte (8-bit)단위로 이루어져있습니다. 그렇다면 word단위 (32-bit)로 주소를 본다면 주소는 4의 배수입니다. 즉, 0번째 주소 다음의 word는 4번째 주소인 것입니다.
MIPS는 Big Endian입니다. Endian은 저장되어있는 데이터를 읽는 방법에 대한 것입니다.
Big Endian의 경우 최우선바이트 (Most Significant Byte, MSB)가 word address인 것이고,
Little Endian의 경우 가장 왼쪽의 바이트 (Rightmost Byte)가 word address인 것입니다.
https://softtone-someday.tistory.com/20
[개념정리] 빅엔디안(Big Endian)과 리틀엔디안(Little Endian)
통신을 하다 보면 통신 패킷이 반대로 나갈 때가 있습니다. 예를 들면 1 2 3 4를 보냈는데 막상 받는 쪽에서 들어온 패킷은 4 3 2 1인 거죠 이는 컴퓨터 CPU의 데이터를 저장하는 순서에서 발생하는
softtone-someday.tistory.com
C code:
g = h + A[8];
Compiled MIPS code (A가 word단위 자료구조인 경우):
lw $t0, 32($s3) # load word
add $s1, $s2, $t0
*이때 32($s3)에서 32는 offset으로 한 단위가 word이고 8번째 데이터이므로, 8*4 = 32가 offset이 됩니다. 또한 $s3를 base register라고 부릅니다.
C code:
A[12] = h + A[8]
Compiled MIPS code:
lw $t0, 32($s3) # load word
add $t0, $s2, $t0
sw $t0, 48($s3) # store word
Register vs. Memory
register는 memory에 비해 빠릅니다. 그래서 memory에 있는 데이터를 register에 load한 후 연산하고, 그 결과를 memory로 store하는 것입니다. Compiler는 최대한 register를 잘 활용하는 것이 중요합니다. 즉, register 최적화는 매우 중요한 문제입니다. *예를 들어 만약 register에 load해야하는 데이터가 너무 많으면 가장 덜 쓰는 데이터를 memory로 옮겨둡니다.
Immediate Operands
Constant data를 이용하여 매우 빠르게 연산할 수 있습니다. 이 경우 빼기 연산은 지원되지 않습니다. *어짜피 add로 -1을 하면 되니까
addi $s3, $s3, 4
addi $s2, $s1, -1 # No subtract immediate instruction. Just use a negative constant
이렇게 흔하게 사용하는 연산을 빠르게 할 수 있도록 지원해주면 결과적인 성능과 속도가 좋아질 수 있습니다. 즉, 많이 사용하는 상수들을 4byte가 아닌 작게 만들어서 load없이 연산을 수행할 수 있도록 지원해줍니다. *Design Principle 3: Make the common case fast
The Constant Zero
MIPS register 0 ($zero)는 상수 0을 나타내고 이는 덮어씌어지지 않습니다. 이는 매우 유용한데 예를 들어 register안에서의 데이터 이동을 mov 명령어 대신 add와 $zero를 이용해서 수행할 수 있습니다.
add $t2, $s1, $zero # move between registers
이는 mov연산자를 추가로 만들지 않음으로써 RISC를 달성함을 알 수 있습니다.
Unsigned Binary Integers
.. 뭐 간단합니다. 최상위 비트를 부호 비트로 사용하지 않는 2진수 표현입니다. n개의 bit을 사용하는 경우 0부터 +2^n - 1까지 나타낼 수 있습니다.
2s-Complement Signed Integers
이것도 간단합니다. 최상위 비트를 부호 비트로 사용하는 2진수 표현입니다. n개의 bit를 사용하는 경우 -2^n-1부터 +2^n-1 - 1까지 나타낼 수 있습니다. 이때 부호 비트 0은 0을 포함한 양수를, 부호 비트 1은 음수를 나타냅니다.
음수를 표현할 때는 양수에서 보수(1->0 or 0->1)를 취한 후 1을 더해주면 됩니다. 예를 들어
+2 = 0000 0000 ... 0010
-2 = 1111 1111 ... 1101 + 1
= 1111 1111 ... 1110 이 됩니다.
Sign Extension
register file의 크기는 word, 즉 32-bit입니다. 그렇다면 그 자리에 word보다 작은 크기의 데이터가 들어오는 경우 남는 자리는 어떻게 처리해야할까요? 이는 부호 비트로 나머지를 채워주면 됩니다. 이를 sign extension이라고 부릅니다. 예를 들어
+2 = 0000 0010 -> 0000 0000 0000 0010
-2 = 1111 1110 -> 1111 1111 1111 1110
이는 addi, lb(load byte), lh(load halfword), beq, bne 등의 MIPS operation에서 사용됩니다.
MIPS-32 ISA
MIPS-32 ISA에는 다음과 같은 명령 카테고리가 존재합니다:
- Computational
- Load/Store
- Jump and Branch
- Floating Point
- coprocessor
- Memory Management
- Special
이를 구현하기 위해서 3개의 instruction format을 지원합니다:
MIPS R-format Instructions
MIPS의 r-type은 다음과 같습니다:
- op (6-bit): opcode. 명령을 나타내는 코드.
- rs (5-bit): 첫 번째 소스가 되는 레지스터 파일. *앞서 말했듯, 32개의 레지스터는 5개의 비트만으로 표현가능합니다.
- rt (5-bit): 두 번째 소스가 되는 레지스터 파일.
- rd (5-bit): 결과를 담는 레지스터 파일
- shamt (5-bit): shift 양 입니다. 이는 음수는 존재하지 않으며 5-bit이기에 0부터 31까지의 수를 담습니다. *어짜피 32가 넘어가면 register file의 크기상 의미가 없음
- funct (6-bit): function code. 실질적인 명령을 의미합니다. *r-format의 경우 opcode는 0이기에 funct에 실질적인 명령이 들어갑니다.
만약 다음과 같은 MIPS instruction이 존재한다면 다음과 같이 r-format으로 변경할 수 있습니다:
add $t0, $s1, $s2
*이때 주의할 점은 assembly code에서는 destination, source1, source2 순서대로 나왔지만 R-format의 경우는 source1, source2, destination 순서이기 때문에 주의해야합니다.
MIPS Register File
register file은 2개의 읽기 포트와 1개의 쓰기 포트로 이루어져있습니다. 그렇기 때문에 instruction들이 2개의 source와 하나의 destination을 갖는 것입니다.
- 레지스터는 메모리보다 빠르다.
- 그러나 레지스터의 수가 늘어나거나 포트의 수가 많아지면 집적도의 문제 때문에 속도가 느려진다.
- 레지스터의 주소는 5-bit로 접근가능하고, 이는 메모리로 접근하는 것보다 빠르고, code density의 관점에서도 유리합니다.
- 즉, 레지스터의 접근이 메모리의 접근보다 유리하다는 뜻이다.
Two Key Principles of Computers
1. instruction은 binary code로 표현되고 이는 데이터와 구분할 수 없습니다.
2. 프로그램도 데이터와 유사하게 binary code로 표현됩니다.
이는 binary number로 구성되어있는 파일로 프로그램을 넘겨주면, 잘 읽어들일 수 있다는 보장하에 상호 호환성이 있다고 볼 수 있습니다 (binary compatibility). 이런 호환성은 같은 ISA에서 이뤄질 수 있습니다.
Logical Operations
MIPS는 논리연산자도 제공합니다. *이때 NOT연산자는 nor을 통해 구현되는데 트릭을 통해 구현됩니다.
MIPS Shift Operations
R-format으로 나타내는데, shift연산의 경우는 source가 2개가 필요하지는 않기 때문에 하나의 source만을 사용합니다.
아래는 shift연산의 예시입니다:
*sll의 경우, i만큼 이동했다면 2^i만큼 곱해진 값이 나옵니다. 반면 (unsigned의 경우에만) srl을 i만큼 이동했다면 2^i만큼 나눠진 값이 나옵니다.
아래는 bit-wise연산의 예시입니다:
Not Operations
Not 연산자는 MIPS에서는 nor연산자를 통해 구현됩니다.
a NOR b == NOT (a OR b) 이므로 b를 $zero로 설정한다면,
a NOR 0 == NOT (a OR 0) == NOT a 가 됩니다.