
Performance Issues
[Computer Architecture] Chapter 4: The Processor Part 1
Introduction 해당 글에서는 두 가지 MIPS의 구현에 대해 살펴봅니다:A simplified version - Single cycle; 하나의 명령을 하나의 cycle에서 처리하는 방법. *CPI = 1A more realistic pipelined versionMulti-cycle version Instructi
hw-hk.tistory.com
이전에 살펴봤던 Single Cycle Architecture는 성능상의 문제가 있습니다. 우선 가장 긴 instruction(=load)을 기준으로 cycle time을 잡기 때문에, load보다 더 빨리 끝나는 명령들은 남은 시간을 기다리기만 해야하는, 성능상의 문제가 있습니다. 하지만 그렇다고 해서 각기 다른 명령어에 대해서 다른 clock cycle time을 주는것은 매우 어렵습니다(hardware적으로). 또한 가장 긴 instruction을 기준으로 cycle time을 잡는것은 Making common case fast라는 RISC의 원칙에도 위배됩니다. *가장 흔한 명령을 가장 빠르게 만들어도 막상 실행할때는 가장 긴 명령을 기준으로 실행되기 때문에 빨리 끝내봤자 의미가 없다.
따라서 Pipeline을 통해 성능을 개선할 수 있습니다.
Overview Pipeline
pipeline은 여러 개의 instructions들을 한 번에 수행할 수 있게 해주는 방법입니다. 이를 빨래 예시를 들어 설명하겠습니다. 우선 빨래를 세탁기, 건조기, 빨래 개기 이렇게 3단계로 나눈다고 했을때, single cycle architecture를 그림으로 나타내면 다음과 같습니다:

이를 pipeline으로 처리하면 다음과 같습니다:
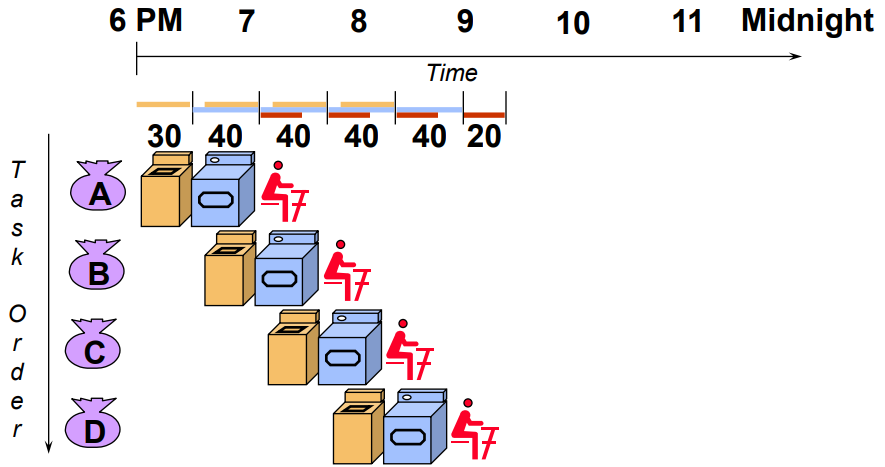
pipeline을 통해 서로 다른 부분을 동시에 진행함으로써 더 빨리 끝낼 수 있습니다. pipeline의 특징은 다음과 같습니다:
- Pipeline은 singtask에 대한 latency를 단축시켜주지는 않습니다. 즉, 하나의 task에 소모되는 시간을 줄여주는 것은 아닙니다. 단지 동시에 수행할 수 있는 일들을 동시에 처리함으로써 throughput을 높여줍니다.
- Pipeline rate(clock cycle)는 가장 느린 pipeline stage를 기준으로 합니다.
- Potential speedup = # pipe stages. 이는 이상적인 upper bound로, filling이나 draining, unbalanced instruction등의 제약조건들에 의해 달성할 수는 없습니다. 위 예시에 따르면 # pipe stages = 3이기 때문에 가능한 최대 speed up은 3배입니다.
MIPS pipeline
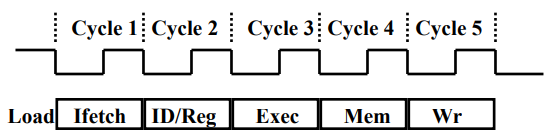
MIPS에서 사용하는 pipeline의 stage는 다음과 같습니다:
- IF: Instruction fetch from memory
- ID: Instruction decode & register read
- EX: Excute operation or calculate address
- MEM: Access memory operand
- WB: Write result back to register

Single cycle, Multiple cycle, vs. Pipeline
single cycle은 하나의 cycle에 하나의 명령의 모든 단계들을 수행하는 것으로 CPI = 1입니다. 반면 Multiple cycle은 하나의 명령에 대해서 필요한 cycle의 수가 반드시 하나가 아니기에 CPI = 1보다 큽니다. 단 clock cycle은 pipeline과 마찬가지로 가장 느린 sub-instruction을 기준으로 합니다.
반면 pipeline은 여러 instruction들을 겹침으로써 성능을 높였습니다: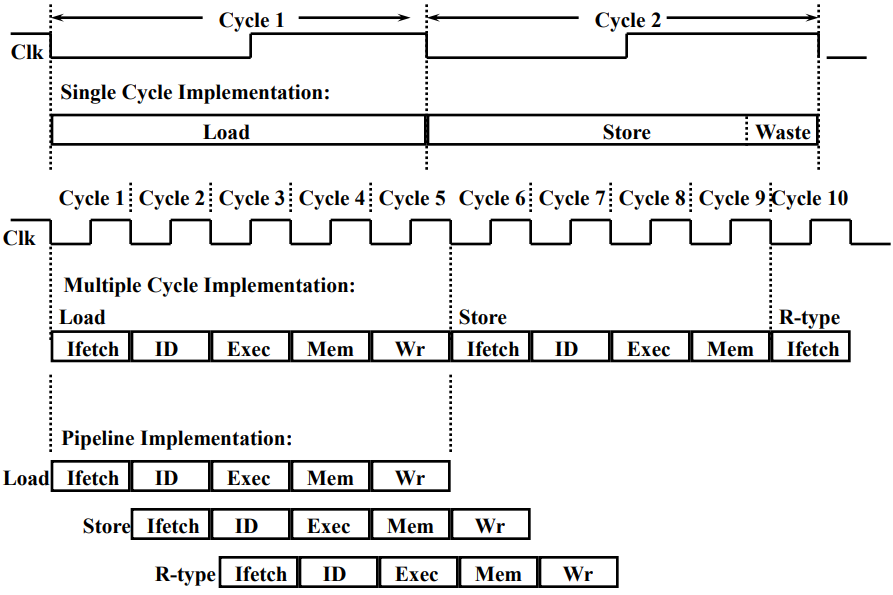
Pipeline Performance
single cycle 대비 pipeline의 성능을 비교하면 다음과 같습니다:

가장 마지막 질문에 대해서 답하기 전에, 우선 ideal speedup은 이전에 말했듯이 # pipeline stage입니다. 즉 MIPS에서는 5배가 최대입니다:

하지만 pipeline stage들이 unbalance하면(어떤 stage는 100ps, 어떤 stage는 200ps라면, clock cycle은 200ps가 될 것이고, 100ps stage가 끝나면 100ps는 그냥 기다려야합니다. 이를 unbalance하다고 합니다), speedup은 ideal한 상황에 비해 작아질 것입니다.
또한 fill, drain(이는 pipeline하나를 채우기까지 걸리는 시간을 말합니다. 예를 들어 pipeline stage가 5단계라면, 가장 처음 4stage까지는 어떤 결과도 나오지 않고 pipeline을 채우기만 합니다. 그 후 5번째 stage부터 한 stage당 하나의 결과씩 나오게 됩니다(CPI = 1))에 의해서도 성능이 낮아집니다
Why pipeline?
그럼에도 불구하고 왜 pipeline일까요?
그럼에도 불구하고 pipeline이 더 좋기 때문입니다:

MIPS Pipelined Datapath
MIPS pipelined datapath는 다음과 같습니다(추후 더 늘어납니다):

여기에 각각의 단계를 끊어주기 위한 register를 달아줍니다. 하나의 clock이 끝나면 그 stage의 결과를 다음 stage 사이에 있는 register에 넣어줍니다. 이를 통해 이전 cycle의 결과를 hold해놓을 수 있습니다:
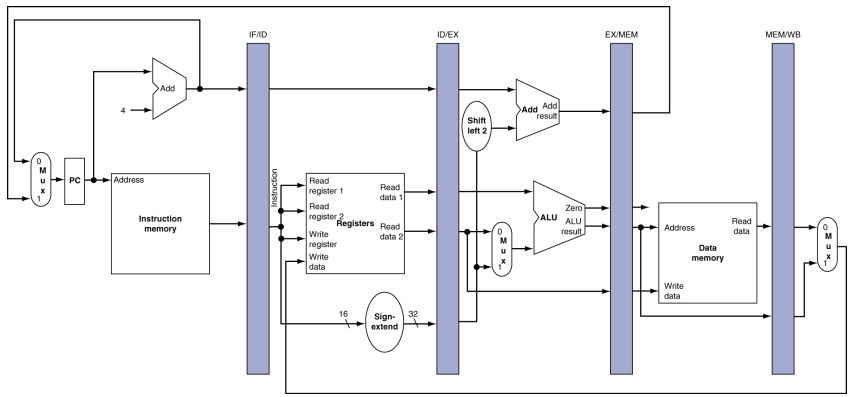
diagram
pipeline의 과정을 그리는 두 가지 view가 있습니다.
(1) Single-clock-cycle diagram: 이는 하나의 cycle의 관점에서 모든 pipeline stage를 살펴보는 diagram입니다.
(2) Multi-clock-cycle diagram: 이는 여러 개의 cycle의 관점에서 pipeline stage들을 살펴보는 diagram입니다.

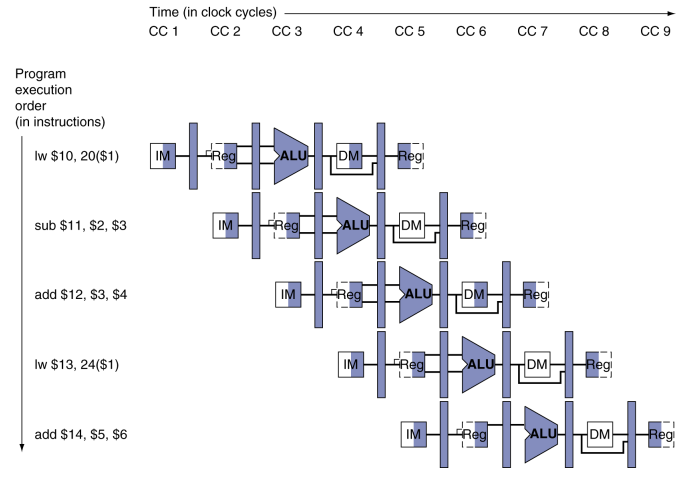
If for Load ...
만약 load명령을 수행하는 경우 pipeline의 구조상 문제가 발생할 수 있습니다. load는 WB단계에서 reigster에 값을 적어야하는데, WB단계에서의 write reigster address는 load명령을 fetch했을 때의 write register address가 아닌 그 이후의 address이기 때문에 잘못된 공간에 값을 넣을 수 있습니다:

그래서 이를 해결하기 위해서는 write address를 계속 끌어서 WB까지 가져와야합니다:

Why pipeline? for performance!

일단 pipeline이 가득 차기만 하면, 매 stage당 하나의 instruction씩 완료됩니다. 즉, CPI = 1이 됩니다.
MIPS pipeline datapath additions/mods
각 stage 사이에 들어있는 register들을 state register라고 부르며 양옆에 있는 stage의 이름을 따서, IF/ID, ID/EX, ... 으로 불립니다. 그리고 각 state register들은 이전 stage의 결과들을 저장하고, 다음 stage가 되면 이를 꺼내 다음 stage의 입력으로 넘겨줌으로써 각 stage들을 구분하는 역할을 수행합니다:

Pipeline Control
지금까지는 data에 대해서만 살펴봤습니다. 그렇다면 control signal들은 어떻게 되야할까요? 각각의 stage마다 필요한 control signal들은 서로 다릅니다. 따라서 각 stage 사이에 존재하는 register들은 control signal까지 저장해야합니다. 그리고 해당 stage가 되면 그 stage에 맞는 control signal을 보내고, 나머지 control signal들은 다음 stage를 위한 register에 그대로 저장됩니다:


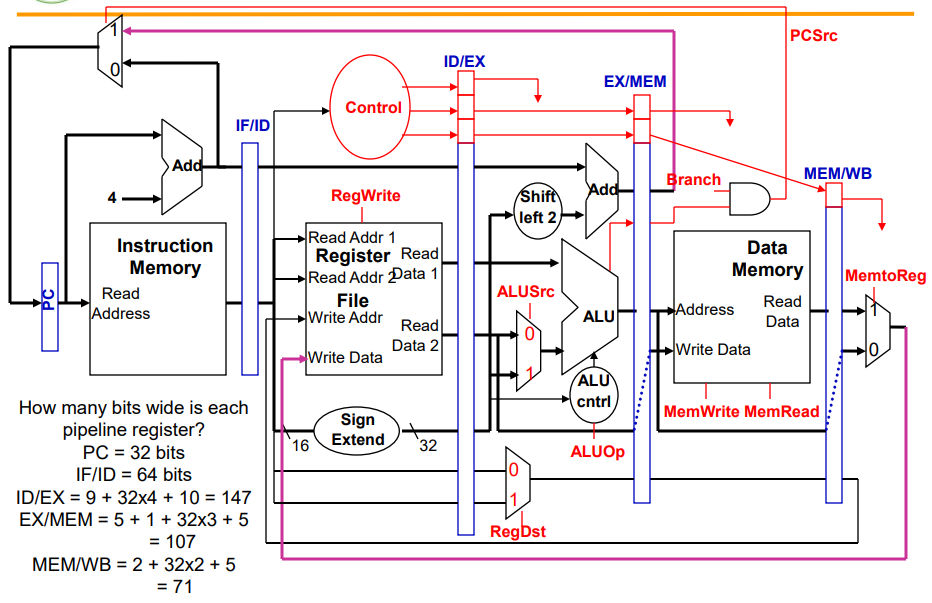
아래의 그림은 pipelined control의 bit수를 나타낸 것입니다:
'[학교 수업] > [학교 수업] Computer Architecture' 카테고리의 다른 글
| [Computer Architecture] Chapter 4: The Processor Part 4 (1) | 2025.06.04 |
|---|---|
| [Computer Architecture] Chapter 4: The Processor Part 3 (0) | 2025.06.03 |
| [Computer Architecture] Chapter 4: The Processor Part 1 (4) | 2025.05.12 |
| [Computer Architecture] Chapter 3: Arithmetic for Computers (0) | 2025.04.09 |
| [Computer Architecture] Instructions: Language of the Computer part 2 | Week 5 (0) | 2025.04.03 |