
https://arxiv.org/abs/2312.16610
Efficient Deweather Mixture-of-Experts with Uncertainty-aware Feature-wise Linear Modulation
The Mixture-of-Experts (MoE) approach has demonstrated outstanding scalability in multi-task learning including low-level upstream tasks such as concurrent removal of multiple adverse weather effects. However, the conventional MoE architecture with paralle
arxiv.org
Motivation.
MoE는 모델의 표현력을 늘리는 좋은 방법이지만 Naive MoE같은 경우는 experts들을 모두 activate하고 그 결과를 gate network의 결과를 이용해 weighted sum하는 방식이기 때문에 계산 비용이 매우 큽니다. 한편 sparse MoE같은 경우는 gate network의 top-k의 결과에 해당하는 expert만 activate하기 때문에 계산 효율성이 좋습니다. 그러나 sparse MoE는 activated # params의 수가 줄어들 뿐이지 전체 params의 수는 늘어납니다. 따라서 edge device에 장착하기에는 부담스러울 수 밖에 없습니다.
또한 기존의 MoE는 expert 하나하나가 매우 크기 때문에, expert의 수를 쉽게 조절할 수 없으며 gate network에 의존적으로 expert를 운용해야합니다.
따라서 해당 논문에서는 간단한 Affine transform을 통해 MoE를 구현하고자 합니다. 이를 통해 edge device에서도 MoE와 유사한 성능을 낼 수 있으며, expert가 매우 간단한 구조이기 때문에 쉽게 expert의 수를 조절할 수 있습니다.
한편, expert를 선택하는 gate network로 그냥 MLP가 아닌 Monte Carlo Dropout을 이용하여 uncertainty를 구하고 이를 기반으로 expert를 선택하는 방식으로 바꿨습니다. 이를 통해 더욱 강건하고 MLP에 의존하지 않는 routing network를 만들 수 있습니다.
Proposed Methods.

우선 각각의 이미지를 encoder를 통해 feature로 만든 다음 제안한 모듈인 MoFME에 입력합니다. routing network인 UaR(uncertainty-aware router)은 MLP W_r을 갖고 있으며 다음과 같은 수식으로 통해 expert를 선택합니다:

이렇게 나온 routing output을 expert의 output인 e(x)와 곱해줌으로써 MoE layer의 최종적인 output을 만들 수 있습니다:

이때 r(x)는 MC dropout을 통해 만들어집니다. MC dropout은 dropout을 이용해 모델의 불확실성을 통계적으로 얻는 방법입니다. router의 MLP에 dropout을 적용하여 N번 inference를 수행하고, N번의 결과에 대해 r(x)의 평균과 분산을 구합니다. 이렇게 되면 inference를 여러 번 하는 것이기 때문에 inference speed의 측면에서 손해를 볼 수 있지만 router의 MLP를 한 번 통과하는 데 그렇게 시간이 많이 들지 않기 때문에 속도 측면에서의 손해는 크지 않습니다.
https://tech.onepredict.ai/e0db8c3e-0225-4b2a-8691-1f9e34d01915
Uncertainty와 Bayesian, 그리고 Monte Carlo Dropout
Uncertainties in Deep Learning Algorithms
tech.onepredict.ai
이렇게 r(x)에 대한 평균과 분산을 구한 후, 마지막 inference를 해서 r(x)를 구한 후 해당 r(x)의 값이 평균으로부터 얼마나 떨어졌는지를 Mahalanobis distance를 통해 구합니다. 이는 분산을 이용하여 "맥락"을 파악하고, 그 맥락에 따른 "거리"를 측정하는 방법입니다. 아무튼, r(x)의 값이 평균보다 크다면(mahalanobis distance가 크다면), 평소보다 더 강하게 해당 expert를 사용해야한다고 routing을 한 것이기 때문에 강한 가중치를 부여하며, r(x)의 값이 평균과 비슷하다면(mahalanobis distance가 작다면), 이는 평소정도의 중요도로 expert를 사용해야한다고 routing을 한 것이라고 판단합니다. 수식은 다음과 같습니다:

https://angeloyeo.github.io/2022/09/28/Mahalanobis_distance.html
마할라노비스 거리 - 공돌이의 수학정리노트 (Angelo's Math Notes)
angeloyeo.github.io
즉, r(x)는 MC dropout을 통해 얻어진 평균과 분산을 통해 mahalanobis distance를 얻고, 해당 거리값을 r(x)로 사용하여 가중치를 부여합니다.
한편, expert는 affine transform에 해당합니다. 이때는 gamma와 beta가 사용되며 이 두 값은 입력 x에 따라 달라지는 값입니다:

따라서 expert의 결과는 다음과 같습니다:

MoFME를 한 번에 나타내면 다음과 같습니다:

마지막에 FFN을 넣어줌으로써 각 expert들의 결과를 섞어주고 fusion하는 기능을 추가합니다.
참고로 Affine Transform만으로도, 즉, 입력에 따라 gamma와 beta값만을 정하고 이를 단순하게 입력에 곱하고 더하는 것 만으로도 충분히 expert의 역할을 수행할 수 있는지 수학적으로 분석해보겠습니다(그렇게 대단한건 아니지만).
router가 task별로 라우팅을 잘 한다는 가정하에, 우선 task별로 gamma와 beta가 달라집니다. 이는 task decoupling된 expert가 존재한다는 의미이기 때문에 MoE의 가정과 동일합니다. 한편 expert의 결과를 마지막에 FFN을 통해 묶어주기 때문에 expert의 결과를 앙상블하는 효과도 낼 수 있습니다.
이때 공유하는 FFN의 weight matrix를 W라고 할 때, 입력 x에 대해 expert는 다음과 같은 출력을 냅니다:

이를 공유하는 weight W에 대해 곱하기 때문에:

위와 같이 각 expert마다 서로 다른 weight W'을 곱하고, 각 expert마다 서로 다른 bias b'을 더한 것과 같은 효과를 냅니다. 즉, 하나의 공유하는 weight W만 이용해서 expert마다 서로 다른 weight matrix W'을 곱한것과 같은 효과를 내는 것입니다.
Optimization Objective.
MoE를 학습할 때 가장 중요한 문제는 expert를 골고루 쓰는 문제입니다. 예를 들어, 학습 초기에 임의의 expert를 선택하여 해당 expert에 해당하는 MLP가 loss를 줄이는 방향으로 "이미" 학습이 되었다고 가정하면, 다른 iteration에 router는 loss를 줄이는 방향으로 학습이 되어있기 때문에 이전 iteration에서 loss를 줄이는 방향으로 "이미" 학습되어있던 expert를 "또" 선택할 수 있습니다. 이렇게 되면 학습이 소수의 expert에만 들어가게 되고, 이는 expert들의 불균형으로 이어지며, expert들을 늘려서 표현력을 늘리고 싶어도 선택되는 expert들을 그에 비해 매우 소수가 되어, 표현력의 upper bound가 생길 수 있습니다.
이렇듯 router의 선택 균형이 매우 중요한데, 이를 강제하기 위해 해당 논문의 저자는 loss에 balance term을 넣었습니다:

이때 v_i(x)는 router가 선택한 expert이면 1, 아니면 0을 출력하는 indicator함수입니다. 이를 해석해보면, 선택된 expert에 대한 r(x)의 값의 합이 크면 loss가 커지는 것입니다. 즉, top-k를 통해 선택된 r(x)의 가중치들의 합이 매우 크다면, top-k안에 들어간 expert들이 차지하는 중요도가 나머지 expert들에 비해 매우 크다는 뜻이 됩니다. 다시 말해 가중치가 top-k의 expert들에 쏠린 것입니다. 따라서 이에 대해 loss 함수를 만들어줌으로써 가중치를 평평하게 만들어주고자 합니다.
한편, router의 MLP로부터 얻을 수 있는 불확실성, 즉 router r(x)가 만들어내는 분포의 분산이 매우 크면, router의 결과를 신뢰할 수 없게 됩니다(이는 평평한 결과와는 아에 다른 측면). 따라서 분산에 대해 loss를 만들어주어서 router의 불확실성을 줄이는 방향으로 학습하고자 합니다:
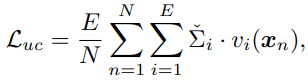
v_i(x)는 위와 똑같은 indicator이며, 이를 해석하면, 선택된 expert에 대해 (공)분산이 크다면 loss를 크게 주는 term입니다. 즉, expert를 선택할 때, MC dropout을 하면서 큰 폭으로 "이랬다 저랬다(=분산이 크다)"하며 선택했다면 loss를 크게 주고, "확실이 이거야!(=분산이 작다)"하며 선택했다면 loss를 작게 주는 것 입니다.
이를 모두 고려하여 최종적인 loss를 만듭니다:

Results.

그림 1. 은 일반적인 MLP만을 이용해서 expert를 선택하는 기존의 routing방식보다 MC Dropout을 통해 routing하는 방식이 task를 더 잘 라우팅할 수 있다는 것을 증명합니다.

표 1. 은 제안된 모델이 파라미터의 수는 매우 작으면서도 성능은 어느정도 유지하거나 더 좋은 방법임을 보여줍니다.

표 2. 는 기존의 MoE와 파라미터의 수와 추론 속도를 비교한 표 입니다. MC dropout을 사용하기 때문에 router의 MLP에 대해 inference를 N번 수행함에도 불구하고 속도가 기존 MoE에 비해 더 빠르다는 것을 알 수 있습니다. 이는 expert가 MoE에 비해 훨씬 light-weight이기 때문입니다.