
https://arxiv.org/abs/2004.01888
FairMOT: On the Fairness of Detection and Re-Identification in Multiple Object Tracking
Multi-object tracking (MOT) is an important problem in computer vision which has a wide range of applications. Formulating MOT as multi-task learning of object detection and re-ID in a single network is appealing since it allows joint optimization of the t
arxiv.org
Motivation.
Multi-object tracking(MOT)에서 가장 중요한 task는 object detection과 re-ID(해당 객체의 ID, 일반적으로 object의 이미지를 conv layer를 통해 embedding한 값을 사용)을 계산하는 것입니다. 하지만 지금까지의 MOT 방법론에서는 object detection을 가장 우선적으로 수행한 뒤, detection의 결과를 이용해서 re-ID를 얻는식으로 이뤄졌습니다.
re-ID를 얻기 위해서는 객체가 어디 있는지를 파악한 후, object의 bbox에 해당하는 image feature들을 conv net에 넣어서 객체의 외형에 관한 ID값을 얻는 것입니다. 그렇기 때문에 기존에는 object detection이 우선적인 task이며, re-ID를 얻는 것은 그 이후에 얻어지는 secondary task가 된 것입니다.
그렇게 되면 re-ID는 앞선 task인 detection에 강하게 의존할 수 밖에 없으며 이는 "unFair"합니다. 따라서 해당 논문에서는 re-ID와 object detection을 "Fair"하게 다루기 위해 intermediate feature를 이용해서 서로 다른 head를 이용해 병렬적으로 처리합니다.
이 논문에서 해결하는 이슈는 다음과 같습니다:
(1) anchor에 강하게 의존하는 것을 해결합니다: 기존의 방법들은 object의 anchor를 먼저 추출한 다음 re-ID feature를 추출합니다. 하지만 만약 anchor가 부정확하게 설정된다면 re-ID를 쓸모없어지며, anchor 자체가 모호성을 가지고 있습니다. 하나의 anchor에 여러개의 object들이 할당될 수도 있으며, 여러개의 anchor에 하나의 object들이 있을 수 있습니다. 즉 anchor당 하나의 re-ID를 할당하는 식의 강한 의존성은 (re-ID에 관련한)성능을 저하시킬 수 있습니다. 해당 논문에서는 anchor-based detector가 아닌 CenterNet을 이용하여 anchor가 아닌 center point를 예측하는 방식으로 이뤄집니다.
(2) re-ID와 detection은 성격이 다른 task임을 이용합니다: 기존의 방법들은 cascade한 방식으로 두 task가 이뤄졌기 때문에, 두 task간의 feature들을 공유했습니다. 즉 anchor의 feature들을 이용하여 re-ID를 추출했습니다. 하지만 이는 두 task의 성질이 아에 다름을 고려하지 않았습니다. re-ID feature의 경우는 같은 class에 해당하는 서로 다른 object들을 구분하기 위해서 동작해야하지만, detection feature들은 서로 다른 object들을 같은 class에 할당하는 방향으로 동작해야합니다. 이 둘의 차이가 충돌하며 성능을 저하시킬 수 있습니다.
(3) re-ID의 차원을 줄입니다: (이는 re-ID와 detection을 병렬로 처리함으로써 해결하는 이슈는 아니긴 합니다) 지금까지는 같은 class의 object들 사이에서도 object들을 구분하기 위해 높은 차원을 가지는 re-ID feature들을 사용했습니다. 이는 상대적으로 detection에서 사용하는 feature의 차원에 비해 큰데, loss는 파라미터의 개수가 큰 쪽으로 잘 흐르기 때문에 re-ID의 MLP가 detection에 비해 상대적으로 더 잘 학습되는 상황이 발생합니다. 즉, detection의 성능이 줄어들며, re-ID는 detection의 성능에 의존적이기 때문에 모든 성능이 떨어지는 상황이 발생하는 것 입니다. 따라서 re-ID의 차원을 줄여, detection과 re-ID feature extraction task사이의 경쟁 뿐만 아니라, 계산 효율성(re-ID의 차원이 줄기 때문에 관리하는 MLP의 크기가 줄어든다)의 측면에서 이득을 볼 수 있습니다.
Overview.

Backbone Network.
ResNet-34를 이용하여 encoding을 수행하며, 변형된 Deep Layer Aggregation(DLA, 무슨 모델인지 정확이는 모름)을 사용합니다. 이는 Feature Pyramid Network(FPN)과 유사한 형태이며, up-sampling에는 deformable attention을 넣습니다.
https://herbwood.tistory.com/18
FPN 논문(Feature Pyramid Networks for Object Detection) 리뷰
이번 포스팅에서는 FPN 논문(Feature Pyramid Networks for Object Detection)을 리뷰해보도록 하겠습니다. 이미지 내 존재하는 다양한 크기의 객체를 인식하는 것은 Object dection task의 핵심적인 문제입니다. 모
herbwood.tistory.com
Heatmap Head.
detection은 CenterNet을 이용하기 때문에 object의 center를 예측할 수 있는 heatmap이 필요합니다. 이때 GT bbox의 좌표가 x1, x2, y1, y2라면 (c_x, c_y) = ((x1 + x2)/2, (y1 + y2)/2)로 구합니다. 그 후 Encoder-decoder를 통해 나온 feature map은 원본 image 대비 1/4되었기 때문에 이를 고려하여 보간(interpolation)해줍니다:
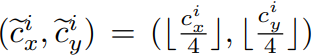
이렇게 얻어진 center를 기준으로 gaussian-like target을 만들어줍니다:

이에 대한 loss는 focal loss를 사용합니다:

https://woochan-autobiography.tistory.com/929
CV - Focal loss
목차 Focal Loss의 필요성 Focal Loss Cross Entropy Loss를 안쓰고 Focal Loss를 쓰는 이유 Balanced Cross Entropy Loss를 안쓰고 Focal Loss를 쓰는 이유 Focal Loss 적용 RetinaNet = Focal Loss + FPN FPN(Feature Pyramid Network) Object De
woochan-autobiography.tistory.com
Box Offset and Size Heads.
bbox에 관한 예측은 bbox의 size = (bbox width, bbox height)과 offset = (x offset, y offset)을 출력합니다. 이에 대한 loss는 다음과 같습니다:
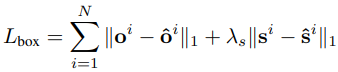
Re-ID Loss.
해당 논문에서는 re-ID feature를 classification task를 통해 학습합니다. re-ID의 feature 차원은 128차원으로, 학습중에는 GT위치에 해당하는 feature를 뽑아 학습에 사용할 re-ID를 추출합니다. 이렇게 추출된 re-ID를 FFN을 통과시켜 K(# of classes)차원의 확률 분포로 바꾼뒤, GT class에 해당하는 one-hot vector와의 CE loss를 구합니다:

결과적으로 다음과 같은 loss함수를 얻습니다:

위 식은 detection과 identity task에서의 예측 오차를 가우시안 잡음이라고 가정했을 때, negative log-likelihood를 loss함수로 사용한 것입니다. 이때 standard variance sigma를 exp(w)로 사용하면 다음과 같은 loss함수가 나오게 됩니다. 이때 w는 학습가능한 파라미터입니다.
Online Inference.
NMS는 heatmap에 3x3 max pooling을 돌려 지역 최대값을 객체 중심으로 사용하는 방법을 이용합니다. tracklet을 유지하는 방법은 Deep-SORT에서 사용한 방법과 유사하게 kalman filter를 통해 예측한 object의 다음 위치와 모델이 예측한 위치 사이의 Mahalanobis 거리와 re-ID의 cosine similarity의 가중 평균을 통해 유사도를 측정하고, 일정한 기준치(=0.4)를 넘어가면 같은 객체라고 판단합니다.
이렇게 해서 matching이 되지 않은 객체들은 IoU matching을 통해 다시 matching을 수행합니다. kalman filter의 예측 위치와 모델의 예측 위치에 대해 IoU score가 일정한 기준치(=0.5)가 넘으면 같은 객체로 판단하며, 30 frame이상 tracklet에서 matching이 안된 객체는 제거합니다.
Results.

그림 2. 는 실험 결과는 아니지만 centerNet이 re-ID를 추출할 때 좋다는 점을 설명합니다. 기존의 anchor-based 방식은 하나의 anchor에 두 object가 들어가거나(a), 여러개의 anchor에 하나의 object가 들어가는 경우(b)가 발생합니다. 하지만 object의 center만을 예측하는 경우에는 그런 경우가 없어서 re-ID를 추출하기 편합니다.
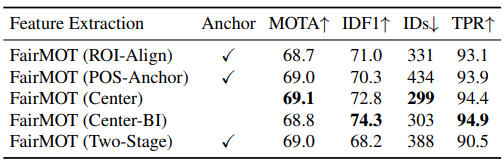
표 1. 은 anchor-based 방식이 tracking 성능의 입장(ID switching 등)에서, 즉 re-ID의 성능의 측면에서 center 기반의 방식보다 더 안좋은 성능을 보임을 나타냅니다.


표 4와 5. 는 backbone 모델로서 DLA-34모델이 다른 모델들에 비해 더 나은 성능을 보여줌을 나타냅니다.

표 6. 은 re-ID의 차원에 따른 성능의 차이를 보여줍니다. dim이 512인 경우 detection과의 경쟁이 발생하기 때문에 detection 성능이 re-ID의 차원이 64인 경우보다 더 떨어집니다. 반면 dim이 512인 경우에 비해 re-ID의 차원이 작은 경우 re-ID의 성능으로 인해 발생하는 문제들이 줄어듬을 알 수 있습니다(IDs가 줄어듬).
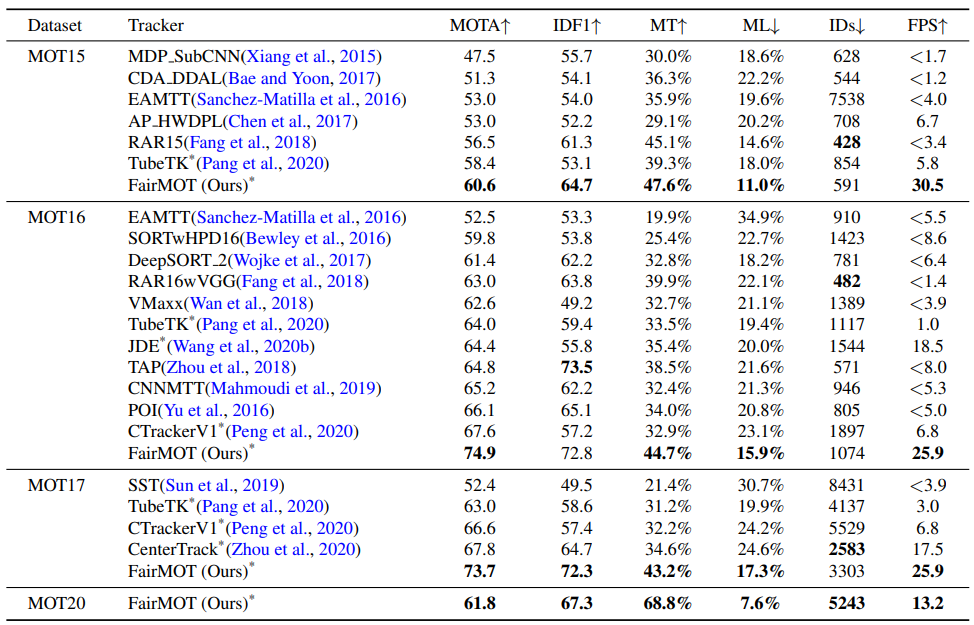
표 10. 은 다른 SOTA 모델들에 비해 제안된 모델이 속도에서도 성능에서도 우월하다는 것을 나타냅니다.