
https://arxiv.org/abs/2003.12063
Memory Enhanced Global-Local Aggregation for Video Object Detection
How do humans recognize an object in a piece of video? Due to the deteriorated quality of single frame, it may be hard for people to identify an occluded object in this frame by just utilizing information within one image. We argue that there are two impor
arxiv.org
Motivation.
VOD에서 말하는 문제는 동일하다. 하나의 frame에서는 (motion blur나 camera defocusing으로 인해) 정확히 식별할 수 없는 경우 다른 frame의 정보를 이용해서 강건한 detection을 수행하고 싶습니다. 이때 사람이 직관적으로 사용하는 정보는 크게 두 가지 입니다:
(1) Global Sementic Information: 일반적으로 사람이 해당 물체가 무엇인지 모를 때는 다른 frame에서 해당 물체와 의미적으로 유사하다고 판단하는 물체를 찾습니다. 이때 사용하는 정보를 global sementic information이라고 부르며, 이는 현재 frame에서 굳이 가까운 frame일 필요가 없으며 전역적인 측면에서 의미적으로 유사한 정보를 찾는 것이기 때문입니다.
(2) Local Localization Information: 하지만 global sementic information만을 사용하면 문제가 발생할 수 있습니다. 예를 들어, 검은 상자 앞에 검은 고양이가 지나가는 경우, 해당 고양이의 위치를 알기 위해서는 전역적인 측면에서의 의미적으로 유사한 정보를 찾기 보다는 현재 frame에서 가까운 frame에서 해당 고양이가 어디 있었는지를 알아야합니다. 즉, 지역적인 측면에서 어디에 있었는지에 대한 위치 정보를 찾는 것이 중요합니다. 따라서 이때 사용하는 정보를 local localization information이라고 부릅니다.
현재 VOD에서 사용하는 방법론들은 reference frame들에 대해서 이 둘의 개념을 혼용하며, 혹은 global sementic information만을 사용하는 경우가 많습니다. 따라서 해당 논문에서는 이 둘을 구분하여 사용합니다. 이때 이 두 개념을 혼용하여 사용해서, 그 물체가 무엇인지를 판별하는데 localization 정보를 사용하거나, 그 물체가 어디있는지를 판별하는데 sementic 정보를 사용하는 경우를 ineffective problem이라고 부릅니다.
한편, VOD task에서 사용하는 방법론들은 메모리의 문제나 추론 속도의 문제로 인해 많은 양의 frame들을 한 번에 참조할 수는 없습니다. 이렇게 충분하지 않은 frame들을 사용함으로써 발생하는 문제를 insufficient problem이라고 부릅니다. 해당 논문에서는 LRM(Long Range Memory) 모듈을 통해 해당 문제를 해결합니다. 아래는 insufficient problem을 보여주는 그림입니다:
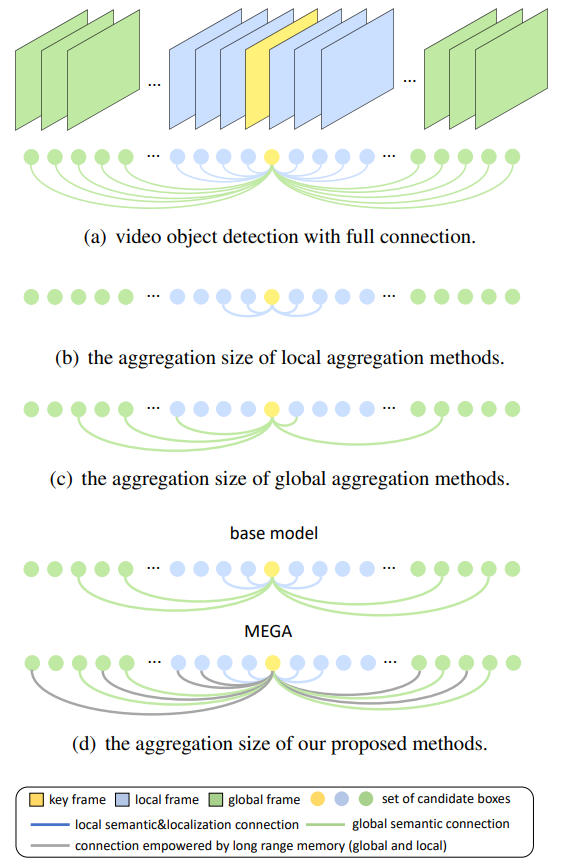
(a)의 경우는 메모리나 계산 비용으로 인해 실제로는 적용할 수 없으며, (b)나 (c)와 같이 일정한 개수의 frame들 만을 사용합니다. 하지만 MEGA의 경우는 기존 base model에서 사용하는 frame은 그대로 사용하면서 LRM을 통해 추가로 참조하는 frame들을 추가하여 참조하는 frame의 개수를 매우 많이 늘릴 수 있습니다.
Method.
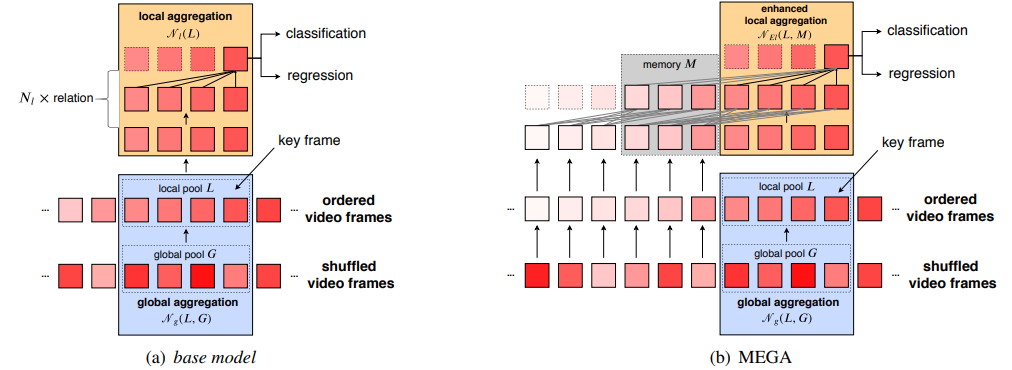
Preliminary.
기본적으로 해당 모델 또한 2-stage detector를 기준으로 합니다. (이유는 비슷하다:
[CoIn] 논문 리뷰 | Sequence Level Semantics Aggregation for Video Object Detection (Wu et al., 2019)
https://arxiv.org/abs/1907.06390 Sequence Level Semantics Aggregation for Video Object DetectionVideo objection detection (VID) has been a rising research direction in recent years. A central issue of VID is the appearance degradation of video frames cause
hw-hk.tistory.com
따라서 각 frame마다 RPN을 통해 instance를 뽑아준 후, Local frames과 Global frames들을 선택합니다. Local frame pool = L은 다음과 같이 일정한 hyperparameter taw에 대해 현재 frame 앞 뒤로 taw만큼의 frame을 선택합니다:

한편 Global frame pool = G는 일정한 frame의 개수 Tg개 만큼 랜덤하게 선택합니다:

또한 attention연산의 기본이 되는 relation module은 다음과 같습니다:
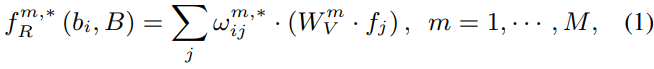
이때 *∈{L, N}은 local정보(=bbox의 x, y좌표)를 사용하거나 사용하지 않거나를 선택합니다. 만약 선택한다면 x와 y좌표를 encoding하여 더해줌으로써 위치 정보를 넣어줍니다. global sementic information을 사용할 때는 RoI의 위치가 중요한 것이 아닌 그 물체가 의미적으로 어떤 물체인지가 중요하기 때문에 *에 N을 넣고, local localization information을 사용할 때는 RoI의 위치를 통해 해당 물체의 위치가 어디인지를 파악하는 것이 중요하기 때문에 *에 L을 넣습니다. 참고로 sementic information을 사용할 때 위치정보를 넣어주면 불필요한 정보로 인해 성능이 떨어지는 경우가 있습니다.
이렇게 relation module의 결과를 multi-head로 수행하기 때문에 각 head의 결과를 concat한 후, residual connection을 달아줍니다:

Memory Enhanced Global-Local Aggregation.
우선 global 정보와 local 정보를 aggregation하기 위해 relation module에 L과 G를 넣어 attention해줍니다:
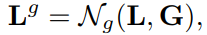
이를 stacking하여 사용하기 때문에, stack의 개수를 Ng라고 했을 때 다음과 같이 쓸 수 있습니다:
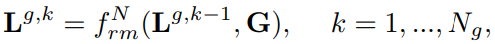
*=N으로 global과 local을 합칠 때는 지역적인 정보가 중요한 것이 아닌, local의 정보와 global한 sementic의 정보를 합치는 것이 중요합니다. 따라서 L 대신 N 을 사용합니다.
이렇게 얻어진 globalization된 local feature Lg를 self-attention합니다:
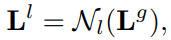
이를 stacking하여 사용하기 때문에, stack의 개수를 Nl이라고 했을 때 다음과 같이 쓸 수 있습니다:
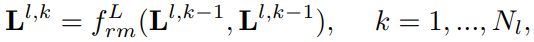
*=L으로 local끼리의 정보를 학습할 때는 위치 정보가 중요하기 때문에 N대신 L을 넣어줍니다. 이렇게 추출된 결과는 RPN의 출력으로서 동작합니다. 이를 통해 ineffection problem은 해결할 수 있었지만, frame의 개수가 부족해서 생기는 insufficient problem은 해결할 수 없습니다. 따라서 이를 해결하기 위해 새로운 모듈 LRM을 도입합니다(지금까지는 base model).
Long Range Memory for insufficient problem.
attention을 수행하는데에 있어서 sequence를 반복적으로 처리하는 경우 KV caching을 통해 계산 효율성을 높일 수 있습니다. https://huggingface.co/blog/kv-cache
KV Cache from scratch in nanoVLM
Thanks for this great article! I'm learning a lot from the nanoVLM project. I'm not an expert in gen ai but I noticed the attention calculation example seems to be missing the scaling √(d_k). Is this intentional for simplification? d_k = K.shape[-1] atte
huggingface.co
이 개념을 여기에도 적용할 수 있는데, local feature들을 sliding window방식으로 반복하여 attention하기 때문입니다. 만약 k-1번째 frame에서 detection을 수행해야하기 때문에 local pool = {k-1-taw부터 k-1번째 frames}에 대해 attention(relation module)을 수행합니다. 그 후 k번째 frame에 대해서 detection을 수행할 때의 local pool = {k-taw부터 k번째 frames}에 대해 attention을 수행해야합니다. 그렇다면 k-taw번째 frame부터 k-1번째 frame에 대해서는 중복되는 frame에 대한 feature를 생성해야합니다.
이런 중복을 해결하기 위해, 중복되는 intermediate feature들을 memory에 저장하며 이를 LRM이라고 부릅니다. 그냥 local pool에서 selection하는 frame의 개수를 M만큼 늘려서 attention을 수행하면 O((L+M)^2)의 시간복잡도이지만, intermediate feature를 M만큼 저장해 놓는다면 O(Lx(L+M))의 시간복잡도가 듭니다.
또한 intermediate feature들은 또 그 전 frame들의 정보를 담고 있기 때문에, L+M 만큼의 pool을 사용하는 것 보다 실질적으로 더 큰 pool을 사용하는 효과가 발생합니다(memory안에 있는 M개의 feature를 만들때 M개의 feature들의 이전의 local pool을 이용해서 만들었을 테니까 M개의 feature를 현재 frame에 대해 사용하면, 현재 frame은 local pool + memory의 정보 뿐만 아니라 memory의 feature들을 만들 때 사용했던 "그때의 memory"의 정보까지 사용할 수 있습니다. 하지만 현재 frame에서 멀 수록 정보가 희석된다는 문제는 발생하긴 합니다).
이렇게 참조하는 frame의 개수가 매우 많이 늘어남으로써 insufficient problem을 해결할 수 있습니다. 아래는 자세한 알고리즘입니다:

이때 M에 대해서는 gradient가 흐르지 않도록 주의해야합니다. M은 이미 계산된 feature이기 때문에 이를 tuning하면 학습이 불안정해질 수 있습니다.
Results.


표 1과 2. 는 제안한 방법론이 다른 SOTA모델들에 비해 더 나은 성능임을 보여줍니다.

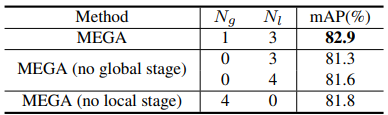
표 3과 4. 는 각각 base model과 MEGA의 성능 비교와 global stage와 local stage에 대한 ablation study의 결과입니다. 이 두 표들은 MEGA의 각 모듈들이 모두 필요함을 보여줍니다.