
https://arxiv.org/abs/2407.19650
Practical Video Object Detection via Feature Selection and Aggregation
Compared with still image object detection, video object detection (VOD) needs to particularly concern the high across-frame variation in object appearance, and the diverse deterioration in some frames. In principle, the detection in a certain frame of a v
arxiv.org
Motivation.
Video 특성상 물체의 급격한 움직임에 의한 이미지의 열화(deterioration)와 같이 단일 frame의 detection만으로는 object를 detection할 수 없는 상황이 Video Object Detection(VOD) task에서는 많이 발생합니다. 이를 해결하기 위해서 VOD에서는 이전 frame의 feature들을 잘 selection한 후 현재 frame의 feature들과 잘 융합(aggregation)하는 방법을 적용합니다. 즉, VOD에서 frame들을 one-by-one으로 잘라서 그때 그때 이미지를 탐지하는 것은 동영상의 시간 정보를 충분히 활용하지 못하는 것입니다.
이때 aggregation하는 방법에는 많은 방법이 있지만, 가장 효과적인 방법은 단연 attention입니다. 하지만 attention은 sequence length에 제곱에 해당하는 계산 복잡도로 인해, 실시간 탐지에서는 잘 사용되기 힘든 메커니즘입니다. 예를 들어, 인접한 frame N개에 대해서, 각 frame마다의 object(# = M)들끼리의 관계를 attention하려면 O((NM)^2)에 해당하는 계산 복잡도가 발생합니다. 따라서 이전에는 작은 수의 proposal단위로 frame들에서 object들을 구한 후, attention을 통해 계산 복잡도를 줄이는 방법을 사용했습니다.
하지만 이 방법은 proposal(RoI)를 먼저 detection한 후, 이들에 대해 attention을 수행하는 2-stage detector 기반 attention같은 경우에는 real-time에 사용하기에 추론 시간의 측면에서 단점이 많습니다. 한편 attention을 detection에 성공적으로 정착시킨 모델인 DETR의 경우에는 reference frame들에 대해 모두 attention을 수행하면 위에서 말했듯 (NM)^2에 해당하는 엄청난 계산복잡도가 생길 수 있습니다. 뭐 decoder의 경우는 query의 개수를 줄임으로써 계산을 줄일 수 있지만, encoder는 줄일 수 없기 때문에 VOD에서 사용하기에는 무리가 있을 수 있습니다.
따라서 해당 논문에서는 one-stage detector인 YOLOX를 기반으로 VOD를 수행합니다. one-stage 기반은 two-stage에 비해 real-time에 적합하기 때문입니다. 하지만 sparse한 prediction을 수행하는 two-stage model이나 DETR과 달리 YOLO는 dense한 prediction을 수행하기 때문에 query의 개수, 즉 sequence의 길이가 매우 깁니다. 이는 DETR과 마찬가지로 계산 비용이 너무 크다는 결과로 이어질 수 있습니다. 이를 해결하기 위해 논문의 저자는 FSM이라는 기법을 통해 dense prediction을 N(~80)개 정도의 prediction만으로 줄입니다. 그 후 VOD에 맞게 적절히 변형된 attention인 FAM을 통해 frame과의 관계를 파악한 후 FAM의 결과를 이용해 최종적인 output을 만들어냅니다.
Our Design.

우선 key frame(detection하고자 하는 현재 프레임)을 보완하기 위해 referece frame들을 random하게 선택합니다. 그리고 이들을 base detector에 넣어 feature를 추출합니다.
FSM: Feature Selection Module.
앞서 말했듯, dense한 prediction을 그대로 attention할 수 없기 때문에 FSM을 통해 sparse한 prediction으로 바꿔줍니다. Feature Extraction(base detector)를 통과하여 나온 feature들에 3x3 conv layer를 두 층을 쌓아 각각 Reg, Cls, VOD Cls(VOD에서 사용할 예정인 Cls feature)를 뽑아줍니다. 그리고 Reg와 Cls에 대해서만 1x1 conv layer를 추가해 각각 IoU score와 classification score를 만들어줍니다.
그리고 classification score를 통해 만들어진 heatmap에서 Top-K + NMS나 threshold를 통해서 K개의 sparse prediction를 뽑아줍니다. 이때 top-k+NMS 방식은 foreground 예측만을 몰아서 선택하기 때문에 해당 논문에서는 detection recall이 상대적으로 좋지 않지만 foreground와 background예측을 골고루 선택할 수 있는 threshold 방식을 이용하여 sparse prediction을 추출합니다. 아래는 top-k+NMS방식과 threshold방식을 각각 사용했을 때의 FSM의 recall입니다:

FSM을 학습시킬 때, 원래는 base detector까지 gradient가 흐르도록 했었는데, 그렇게 되면 FAM의 feature들의 tunning으로 인해 base detector의 params 값들이 오염되어 전체적인 성능이 저하되는 현상을 발견했습니다. 따라서 해당 모델을 학습시킬 때는 base detector에 gradient가 흐르지 않도록 frozen하고 학습을 시킵니다. 그리고 FSM, FAM과 base detector를 부드럽게 연결시켜주기 위해 3x3 conv layer를 두 층 추가로 쌓아주고 같이 학습시켜줍니다.
그 후 FSM을 통해 걸러진 sparse prediction들의 Reg, VOD Cls feature들을 이용하여 FAM이라는 attention모듈에 넣습니다.
FAM: Feature Aggregation Module.
이렇게 얻어진 frame별 VOD Cls와 Reg feature들을 concat하고 Linear Projection시켜서 FAMc에 들어갈 query, key, value인 Qc, Kc, Vc와 FAMr에 들어갈 Qr, Kr, Vr을 만들어줍니다:

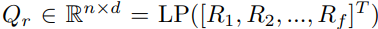
이때 C1, C2, ..., Cf는 각 frame f에 대해서 FSM을 통해서 걸러진 prediction feature들을 모은 matrix입니다(ai = # of predictions in i-th frame):

Ri도 마찬가지 입니다:

그 후 attention을 통해 Ac와 Ar을 만들어줍니다:

그리고 Vc나 Vr과 attention score를 곱해주면서, Ac와 Ar의 평균을 이용해서 attention score를 구합니다(자세한 내용은 없지만 아마 cls와 reg정보를 골고루 보기 위함?). 그 후 다시 V(c or r)를 concat해줍니다(이는 원본의 내용을 유지하기 위해):

이때, 일반적인 attention score로 attention을 수행한다면 동질성 문제(the homogeneity issue)가 발생할 수 있습니다. attention score는 query와 key의 성질이 비슷한 경우 높아집니다. 이는 곧 key frame의 object와 참조할만한 정보가 비슷하면 더욱 더 참조한다는 의미가 됩니다. 하지만 저희가 풀고자 하는 문제는 query에 열화가 발생한 경우입니다. 즉, query와 성질이 비슷한 것이 참조된다면, 참조되는 정보 또한 열화가 발생한 정보이기 때문에 실질적으로 도움이 안될 수 있습니다. 따라서 참조되는 정보의 cls confidense를 곱해줌으로써 참조하는 정보가 정확하게 식별되는 경우에 attention score가 높아지도록 수정합니다(Sq = the confidence of q-th proposal):

아래는 실제 데이터 예시입니다(Affinity manner가 수정된 버전):

위 그림에 따르면 일반적인 QK manner의 경우 key proposal과 마친가지로 열화가 발생한 것 만을 reference proposal로 추천하는 것을 볼 수 있습니다.
그 후, FAMc에 대해서만 Average pooling over reference features(A.P)를 추가합니다. 이는 Vc에 대해 layer normalization을 한 후 (cosine) similarity matrix를 만들어줍니다:

그 후 key frame의 Vc와의 유사도가 일정한 값을 넘는 경우에 해당하는 Vc의 feature들만 선택한 후 해당 feature들에 대해 averaging을 수행합니다. 그 후 key frame의 Vc와 concat하여 마지막 MLP를 통과해 최종 결과를 출력합니다.
attention에서 사용되는 softmax는 낮은 수준의 유사도를 갖는다면 아에 참조되지 않을 수 있기 때문에, 최대한 많은 frame의 정보들을 참조시키기 위해 A.P를 추가했습니다:
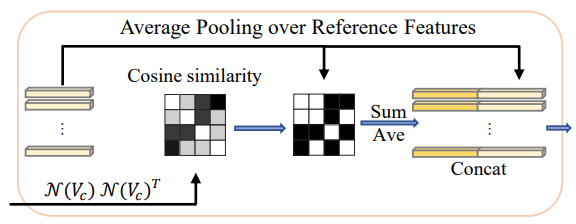
이렇게 나온 FAMc와 FAMr을 통해 나온 key frame의 feature를 이용해서 Cls와 IoU score를 보정합니다. bbox에 대한 reg은 base detector인 YOLOX의 결과를 그대로 사용합니다.
Results.

표 3. 은 제안된 모델(YOLOV++)가 다른 VOD model들에 비해 더 나은 성능의 모델임을 보여줍니다.
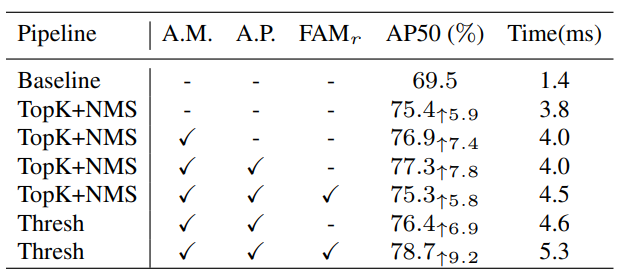
표 4. 는 Top-k+NMS방식으로 FSM을 수행하는 것 보다는 Threshold를 설정하는 방식이 최종 결과의 측면에서 더 좋다는 것을 보여줍니다. 또한 Affinity manner(attention)와 A.P를 동시에 수행하는 것이 성능의 측면에서 가장 좋은 방식임을 보여줍니다.
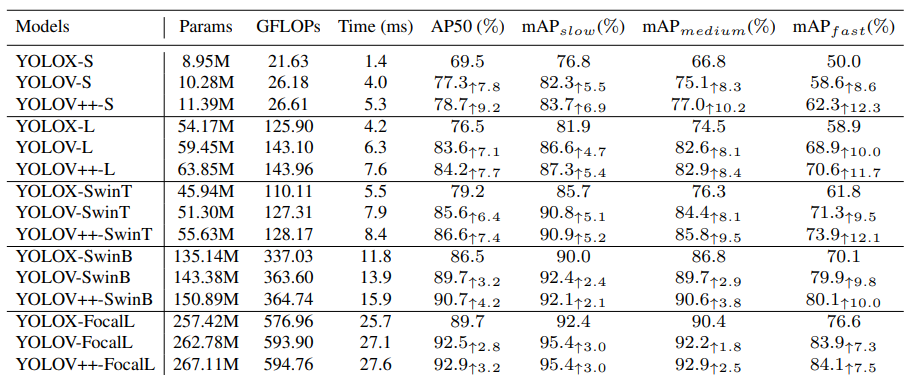

표 7과 8. 은 해당 방법론이 다른 모델에서도, 다양한 크기에 모델에서도 일반적으로 적용할 수 있는 방법론임을 보여줍니다.