
https://arxiv.org/abs/2109.03495
Temporal RoI Align for Video Object Recognition
Video object detection is challenging in the presence of appearance deterioration in certain video frames. Therefore, it is a natural choice to aggregate temporal information from other frames of the same video into the current frame. However, RoI Align, a
arxiv.org
Motivation.
VOD task에서의 문제점을 해결하기 위해서 지금까지 다른 frame의 정보들과 key frame(현재 frame)의 정보를 aggregation합니다. 이는 RoI(instance)단위로 이뤄집니다. 하지만 RoI자체는 하나의 frame에서 추출합니다. 즉, 지금까지는 하나의 frame에서 추출한 RoI feature들을 이용하여 다른 frame들의 RoI들의 정보들을 aggregation했는데, 해당 논문에서는 이때 frame당 뽑는 RoI도 여러개의 frame에서 뽑는 것이 더 낫다는 것을 보여줍니다.
RoI feature를 추출하는 방법이기 때문에 (다른 frame의 RoI들을 이용해 aggregation하는) 다른 방법론들에도 추가적으로 적용할 수 있습니다. RoI feature를 추출할 때는 현재 frame에서 근접한 frame에 대해서 수행하는데, 아래 그림은 기존의 RoI를 추출하는 과정과 제안한 방법론의 차이를 보여줍니다:
기존의 방법(a)은 하나의 frame에 대해서 RoI를 추출하는 반면, Temporal RoI Align(b)에서는 인접한 frame(support frame)에서 추출하고자 하는 RoI와 유사한 RoI를 이용해 여러 frame의 정보를 aggregation한 RoI를 추출합니다. 이를 통해 RoI 하나에도 열화에 강건한(robust) feature를 뽑을 수 있으며, 다른 방법론에 추가적으로 적용하면 성능을 더 끌어올릴 수 있습니다.
다른 얘기지만, support frame을 통해 RoI를 aggregation할 때, RoI feature를 뽑으려는 객체와 유사한 객체에 대한 RoI를 뽑아내면 사실상 같은 객체에 대한 정보를 반복해서 뽑는 것과 다를 것이 없습니다. 예를 들어, 위 그림과 같이 고양이에 대한 RoI feature를 뽑으려고 할 때, support frame에서 key frame에서의 고양이와 유사하게 생긴 고양이의 feature를 통해 증강한다면, 사실상 똑같은 feature를 두 번 얻는 것이고, 이는 그냥 key frame에서의 feature를 하나만 뽑는 것과 다를 바가 없다고 생각합니다. 즉, aggregation을 하는 이유가 key frame에서"도" 얻을 수 있는 정보가 아닌 key frame에서는 얻을 수 없고, 다른 frame에서는 얻을 수 있는 정보를 얻기 위함인데, 유사도만을 기준으로 사용하면 이를 달성할 수 없을 것입니다.
따라서 aggregation을 할 때 유사도도 중요하지만, 다양성(entropy)도 중요하다고 생각합니다. 이는 SELSA(Wu et al., 2019)에서 reference frames을 random하게 선택하는 것이 일반적으로 성능이 좋다는 것과 일맥상통합니다. 랜덤하게 reference frame을 선택하면 정보의 다양성을 어느정도 강제할 수 있기 때문입니다.
아무튼, 유사도는 SELSA(Wu et al., 2019)나 다른 MOT(Multi-Object Tracking) task에서 사용하는 re-ID와 같이 RoI feature들 사이의 cosine similarity를 사용합니다. 또한 해당 논문에서는 key frame과 인접하며, RoI feature를 뽑을 object와 유사한 object의 RoI feature를 이용해 증강하여 RoI feature를 뽑아냅니다.
Temporal RoI Align.

우선 key frame과 referece(support) frames 모두 CNN기반의 base model을 통해 feature map을 생성합니다(g_cnn() = CNN-based backbone model):
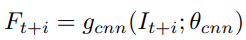
이 방법론 또한 2-stage detector를 기준으로 수행하며, key frame에 대해서 RPN을 거쳐 RoI를 뽑아냅니다. 그 후 각 RoI의 feature vector 하나 하나당 support frame과 cosine similarity를 구합니다. 그렇게 얻은 similarity matrix에서 유사도가 가장 높은 top-k(K=4)를 선택한 후 해당 자리에 위치한 support frame의 feature를 추출합니다(projection).
그렇게 얻은 K개의 feature들을 similarity를 기준 softmax를 통과시켜 합을 1로 만들어줍니다:
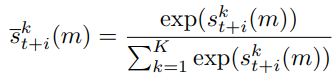
그 후 가중합하여, key frame의 RoI feature vector하나에 대응하는 support frame에서의 feature vector를 얻을 수 있습니다:

이 과정을 그림으로 나타내면 다음과 같습니다:

이렇게 나온 feature들과 key frame의 원래 RoI feature를 attention을 통해 aggregation해줍니다(Temporal Attentional Feature Aggregation).
Temporal Attention Feature Aggregation (TAFA).
TAFA의 구조는 다음과 같습니다:

이는 multi-head attention으로 우선 channel 차원으로 slicing을 수행합니다:

그 후 각 head마다 self-attention을 수행하는데, key frame feature map Xt를 query로, 나머지 support frame에서의 feature map인 Xt+i를 key로 하여 dot product를 수행합니다. 이를 통해 attention score를 만듭니다:
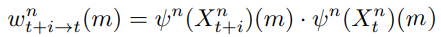
ψ(·)은 작은 embedding network로, 각 head마다는 가중치를 공유하지 않습니다. 이렇게 얻어진 attention score를 softmax함수에 넣어서:

합을 1로 만들어준다음, 가중합 해줍니다:

그 후 각 head의 결과를 concat하여 최종적으로 temporal 한 정보를 aggregation한 RoI feature를 만듭니다.
Results.

그림 5. 는 support frames을 어떤 전략으로 뽑아야 성능 향상에 도움이 되는지를 나타냅니다. (a)는 stride가 1이고, key frame과 인접한 frames들을 사용했을 때의 성능입니다. (b)는 같은 양의 frame을 선택할 때, frame들의 stride가 달라지면 성능이 어떻게 바뀌는지를 알 수 있습니다. (c)는 비디오 길이에 따라 균등하게 frame을 뽑을 때의 성능입니다. 이를 통해 최대한 멀리 멀리, 다양하게 support frame을 뽑는 것이 중요하며, key frame과 붙어있는 support frame을 사용하면 성능이 좋다고 보장할 수는 없다는 보여줍니다.

표 6. 은 해당 방법론을 다른 VOD 방법론에 적용시켜볼 수 있으며, SELSA에 추가로 붙일 때 성능이 가장 좋음을 보여줍니다.