
https://arxiv.org/abs/2401.09923
MAMBA: Multi-level Aggregation via Memory Bank for Video Object Detection
State-of-the-art video object detection methods maintain a memory structure, either a sliding window or a memory queue, to enhance the current frame using attention mechanisms. However, we argue that these memory structures are not efficient or sufficient
arxiv.org
Motivation.
VOD에서의 기존의 방법들은 Sliding window 방식이나 memory queue(reference frames들을 따로 담는 공간)을 유지하면서 하나의 frame에서 열화가 발생하여 detection을 못하는 경우 주변 frames들의 정보를 이용해서 detection의 강건함을 높일 수 있습니다. 하지만 이 방법에는 두 가지 단점이 있습니다:
(1) memory에 있는 frames의 모든 feature들을 다루기에는 computational cost가 너무 큽니다. 일반적으로 frames에 있는 feature(pixel단위든 instance단위이든)들을 한 번에 처리하기 위해 concatination하는데, 만약 relation mechanism을 attention으로 한다면, sequence length의 제곱에 해당하는 계산 복잡도가 들기 때문에 계산 효율성의 측면에서 부담이 됩니다.
(2) frame단위로 memory queue를 업데이트 하거나, sliding window를 움직이는데, 이는 고정된 frame의 개수만큼만 참조할 수 있기 때문에 한계가 있을 수 있습니다. frame단위의 업데이트는 장기 의존성 문제를 일으킬 수 있는데, 폐색이 일어나는 # of frames가 늘어난다면, sliding window든 memory queue든 memory에 들어있는 모든 frame들이 폐색이 일어난 frame일 수 있습니다. 이는 MEGA(Chen et al., 2020)에서 말한 insufficient problem과 유사한 문제입니다:
[CoIn] 논문 리뷰 | Memory Enhanced Global-Local Aggregation for Video Object Detection (Chen et al., 2020)
https://arxiv.org/abs/2003.12063 Memory Enhanced Global-Local Aggregation for Video Object DetectionHow do humans recognize an object in a piece of video? Due to the deteriorated quality of single frame, it may be hard for people to identify an occluded ob
hw-hk.tistory.com
이를 해결하기 위해서 해당 논문에서는 참조하는 정보를 frame단위가 아닌 feature단위로 구성하고, feature들을 모두 사용하는 것이 아닌 sampling하여 참조해야하는 정보들을 선택합니다. 이를 통해 frame의 정보들을 모두 한 번에 concat해서 사용하는 것 보다 계산 효율적으로 문제를 풀 수 있습니다. 또한 frame단위의 업데이트 대신 좀 더 finer-grained한 feature단위의 업데이트를 수행합니다. 아래는 sliding window 방식과 MEGA(Chen et al., 2020)에서 사용한 memory queue 방식, 제안된 방법론의 차이를 그림으로 보여줍니다:

Our Apporach.
Overview.
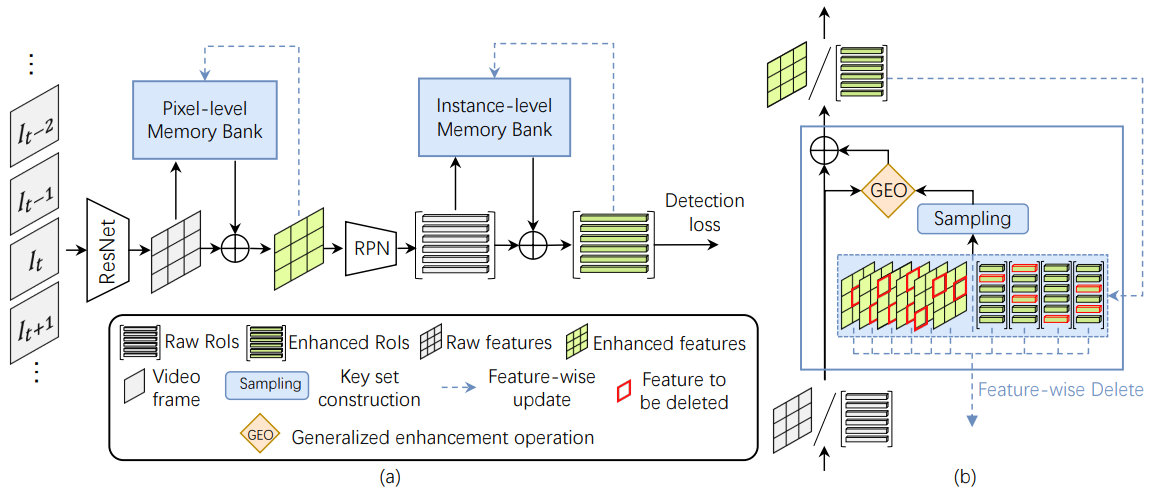
feature를 instance-level의 feature들에 대해서만 저장하는 것이 아닌 pixel-level의 feature들까지 memory에 저장하게 함으로써 참조의 다양성을 높였습니다. 입력의 모든 pixel에 대해서 feature들을 저장할 수는 없기 때문에, ResNet을 통해 downsampling을 수행하고, 해당 feature에 대해서 저장합니다.
이 방법론 또한 2-stage detector를 기준으로 만들었으며, Pixel-level 수준에서의 aggregation을 통과한 후, RPN을 거쳐 instance를 뽑아낸다음, instance-level 에서의 aggregation을 통과해 최종 결과를 뽑아냅니다.
Light-weight Key Set Construction.
앞서 말했듯, frame의 모든 feature들을 memory에 담아서 참조하면 computational cost가 너무 커져 부담이 생깁니다. 반면 feature 단위로 정보들을 저장한다면 상대적으로 더 많은 frame들의 정보를 저장할 수 있습니다. 이렇게 많은 feature들 중 중요한 정보만 뽑아내는 sampling 과정을 거쳐 현재 frame에 대해 정말 필요한 feature들을 제공할 수 있습니다. MB(=memory bank)에서 feature들을 sampling하여 K개의 feature들을 뽑아내는 과정을 다음과 같이 나타낼 수 있습니다:

이때 사용하는 sampling 전략은 다음의 세 가지 입니다:
(1) score ranking: pixel level의 feature에 대해서는 해당 위치의 classification score를, instance-level의 feature에 대해서는 해당 instance의 objectness를 랭킹 점수로 사용해서, top-k의 feature를 뽑아냅니다.
(2) frequency guided: 이는 score를 확률 분포로 사용하여서 feature들을 뽑아냅니다. 이는 top-k에 비해 상대적으로 score가 낮은 feature들도 뽑힐 수 있으며, 이는 reference feature들의 다양성의 측면에서 score ranking 방법에 비해 우수합니다.
(3) random selection: 랜덤하게 feature들을 선택합니다.
실제 논문의 구현에서는 단순함을 위해 pixel/instance-level에서의 sampling 전략으로는 random selection을 수행했습니다. 그리고 세 방법 모두 유의미한 성능 향상이 있었지만, random selection의 경우가 성능 향상이 가장 컸습니다. 그 이유로 논문의 저자들은 frame의 다양성을 얘기합니다. 앞선 두 방법(score ranking이나 frequency guided)은 classification score나 objectness를 기준으로 선택하기 때문에 가장 잘 나온 frame 하나에서 저장하는 feature들이 몰려서 나올 수 있습니다. 즉, frame 자체의 다양성이 떨어질 수 있습니다. 하지만 random selection은 reference "frames"들의 다양성을 어느 정도 보장하기 때문에 가장 성능이 좋았다고 분석했습니다(정보의 entropy).
이렇게 light-weight하게 reference feature를 구성하면, memory에서 가질 수 있는 feature의 개수(Nm)이 96k까지 늘릴 수 있습니다(반면, 존재하는 방법론들의 최대 Nm은 6k 정도). 이렇게 Nm의 개수를 최대한으로 늘리면 성능을 높일 수 있고, 만약 추론 속도가 더 중요한 경우는 Nm을 줄여 추론 속도를 높일 수도 있습니다.
Unified Multi-level Enhancement.
Generalizaed enhancement operation(GEO)는 사실 그냥 attention과 똑같습니다. 자세히 말하면 stacked multi-head self-attention입니다:

이때의 weight(attention score)는 다음과 같이 구합니다:

이를 multi-head로 수행한 후, 나온 결과를 concat한 다음 residual connection을 달아주면 다음과 같습니다:
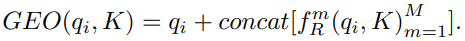
이를 Ng층 쌓으면 다음과 같습니다(h = ReLU):
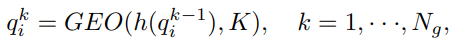
Feature-wise Updating Strategy.
memory에 있는 feature들을 업데이트하는 방법은 sampling과 유사합니다. 예를 들어, frequency guided로 update를 수행한다면 (1 - confidence score)나 (1 - objectness)를 이용해서 확률 분포를 만든다음, 낮은 score에 대해서 feature들을 뽑아내면 됩니다. 그 후 random하게 sampling 전략을 수행한다면, 새롭게 들어온 feature들 중 random하게 그 빈자리에 넣어 업데이트를 수행하면 됩니다.
Results.

표 1. 은 다른 VOD 방법론에 비해 제안된 방법론이 더 우수함을 보여줍니다.

표 3. 은 ablation study의 결과로, 이는 pixel-level reference와 instance-level reference를 모두 사용함으로써 상호 보완적인 기능을 수행함을 보여줍니다.

표 5. 는 light-weight key set의 중요성을 설명하는 표입니다. 이는 Nm, 즉 memory에 저장하는 feature의 개수가 커짐에 따라 추론 시간이 어떻게 변하는지를 보여줍니다. 이전에 사용했던 방법들(concatenation)은 Nm이 48k가 넘어가면 Out of Memory가 발생하는 반면 sampling 기법을 사용하면 Nm = 96k까지 다룰 수 있음을 보여줍니다.