
https://arxiv.org/abs/2305.13245
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
Multi-query attention (MQA), which only uses a single key-value head, drastically speeds up decoder inference. However, MQA can lead to quality degradation, and moreover it may not be desirable to train a separate model just for faster inference. We (1) pr
arxiv.org
Abstract.
Multi-query Attention(MQA)는 오직 단일 key-value 헤드만을 사용하여 decoder의 추론 속도를 급격하게 높여줍니다(https://arxiv.org/pdf/1911.02150). 하지만 MQA는 성능 저하로 이어질 수 있으며, 더 빠른 추론만을 위해 별도의 모델을 훈련하는 것은 바람직하지 않을 수 있습니다. 따라서 해당 논문에서는 1) 원래 사전 훈련량의 5%만을 사용하여, 기존의 multi-head 언어 모델의 checkpoints들을 MQA를 가진 모델들로 uptraining하는 방법을 제안합니다. 2) 또한 MQA의 일반화된 버전으로서, 중간정도의 key-value 헤드 수를 갖는 grouped-query attention(GQA)를 제안합니다.
Introduction.
Autoregressive decoder inference는 decoder 가중치들과 모든 attention key-value들을 매번 load해야한다는 점에서 transformer 모델들에게 매우 큰 오버헤드 입니다. 이때 key-value 값들을 매번 loading하는 오버헤드는 다수의 query head를 사용하기는 하지만, 단일 key-value head를 사용하는 MQA를 통해 많이 줄일 수 있습니다. 하지만, MQA는 성능 저하와 훈련 불안정성으로 이어질 수 있습니다. 이 논문은 다음과 문제를 해결하기 위한 두 개의 contribution을 포함합니다:
- Multi-head Attention(MHA)를 가진 언어 모델들의 checkpoints들로부터 uptraining을 통해 원래 훈련 연산량의 일부분만 사용함으로써 MQA를 사용할 수 있도록 합니다.
- MHA와 MQA의 중간에 해당하는 GQA를 통해 MQA만큼 빠르면서, MHA만큼의 성능을 달성합니다.
Method.
MHA 모델로부터 MAQ를 생성하는 것은 크게 두 가지로 이뤄집니다:
- converting the checkpoints
- additional pre-training to allow the model to adapt to its new structure
그림 1. 은 MHA checkpoints를 MQA checkpoints로 변환하는 과정을 보여줍니다:

단일 key-value head를 MHA에서 선택하거나, 처음부터 새로운 key-value head를 초기화하여 학습하는 것보다, mean pooling을 통해 단일 key-value head를 만드는 것이 더 나은 방법임을 발견했습니다. 그 후 변환된 checkpoints는 원래 훈련 단계들에 대해 매우 작은 비율(α) 만큼만 동일한 사전 훈련 레시피 위에서 학습됩니다.
이때 GQA-G G개의 그룹을 가진 그룹화된 query를 지칭합니다. GQA-1은 단일 그룹 그리고 단일 key-value head를 가지며, MQA와 동일합니다. 반면, GQA-H는 head의 수와 같은 그룹들을 가지며, MHA와 동일합니다. 그림 2. 는 GQA와 MQA, MHA를 비교한 그림입니다:

MHA checkpoints를 GQA checkpoints들로 변환할 때는 MQA와 비슷하게 해당 그룹 내의 모든 원래 heads들을 mean pooling 함으로써 각 그룹의 key-value head를 구축합니다. 중간 정도의 그룹 수는 interpolated model이 되는데, 이는 MQA보다 품질은 높지만 MHA보다 빠르다는 것을 의미합니다.
MHA에서 MQA로 가는 것은 H개의 key-value heads들을 단일 key-value head로 줄임으로써 key-value cache의 크기를 줄이고, 따라서 load되야 할 데이터의 양을 H배만큼 줄일 수 있습니다. 그러나, 더 큰 모델들은 일반적으로 head의 수를 확장하기 때문에, MQA는 더 공격적으로 메모리 대역폭과 용량 모두에 대해서 공격적인 삭감(aggressive cut)이 이뤄집니다.
Note: MQA를 사용한다는 것은 무조건 KV head를 딱 1개만 사용한다는 뜻입니다. 만약 모델이 커져 head의 수가 16개에서 128개로 늘어났다면, 기존에는 capacity나 대역폭의 측면에서 1/16으로 줄어들지만, 이제는 1/128으로 줄어들기 때문에, 모델의 크기가 커지면서 정보의 손실이 너무 커지며 표현력이 급격하게 떨어지는 단점이 있습니다. 따라서 GQA와 같이 일정한 비율로 그룹을 만든다면, 모델이 커져도 적절한 수의 KV head를 유지할 수 있습니다(예: 8개당 1개의 그룹이라면, 1/8만큼의 삭감비율을 모델의 크기가 커져도 유지할 수 있습니다).
또한 모델이 커지면 메모리 대역폭으로 인해 생기는 오버헤드보다는 계산량으로 인해 생기는 오버헤드가 더 큽니다. 대역폭으로 인해 loading하는 오버헤드는 내부 모델 차원에 대해 선형으로 확장되는 반면, FLOPs는 모델 차원의 제곱에 비례하여 커지기 때문입니다(따라서 MQA와 같이 극단적으로 메모리 loading 오버헤드를 줄일 필요 없이, GQA 정도로 타협하여 성능을 챙기는 것이 더 중요합니다).
마지막으로 MQA에서 대규모 모델들을 위한 sharding은 모델의 파티션의 수만큼 단일 key-value head를 복제합니다. 예를 들어, GPU 8개에 하나의 모델을 쪼개서 넣는 상황이라면, KV head는 하나밖에 없지만, 연산은 8개의 GPU에 모두 필요하기 때문에, 1개의 KV head를 모두 똑같이 복사해서 넣어줘야 합니다. 메모리를 아끼려고 1개로 head를 줄였는데, 결국 GPU 8개에 다 복사하느라 총 8개를 저장하는 꼴이 됩니다. 하지만 GQA-8을 사용한다면, 각 GPU는 서로 다른 KV head를 1개씩 가져감으로써 복사할 필요도 없이 각자 고유한 정보를 처리할 수 있는 것입니다.
Note: 한편, GQA는 encoder self-attention에는 적용되지 않습니다. encoder의 attention 연산은 이미 병렬로 연결되며, 메모리 대역폭으로 인한 오버헤드가 주요 병목이 아니기 때문입니다. decoder의 경우 단어 하나 뱉고, 멈추고, 단어 하나 뱉고, ... 하기 때문에 매번 메모리에서 과거 기록(KV cache)을 가져와야 하므로, 메모리 대역폭(loading)이 속도를 좌우합니다.
Experiments.
(... 실험 설정들 ...)

그림 3. 은 모든 데이터셋들에 걸친 평균 성능을 보여줍니다. GQA는 MQA에 가까운 속도를 기록하며, MHA에 가까운 성능을 달성합니다.

그림 4.는 checkpoint 변환을 위한 서로 다른 방법들의 성능을 비교합니다. mean pooling이 가장 잘 작동하는 것으로 보이며, 단일 head를 선택하는 것 그리고 무작위 초기화를 하는 것이 뒤따릅니다. 직관적으로 이는 사전 훈련된 모델로부터 정보가 보존되는 정도에 따라 정렬됨을 알 수 있습니다.
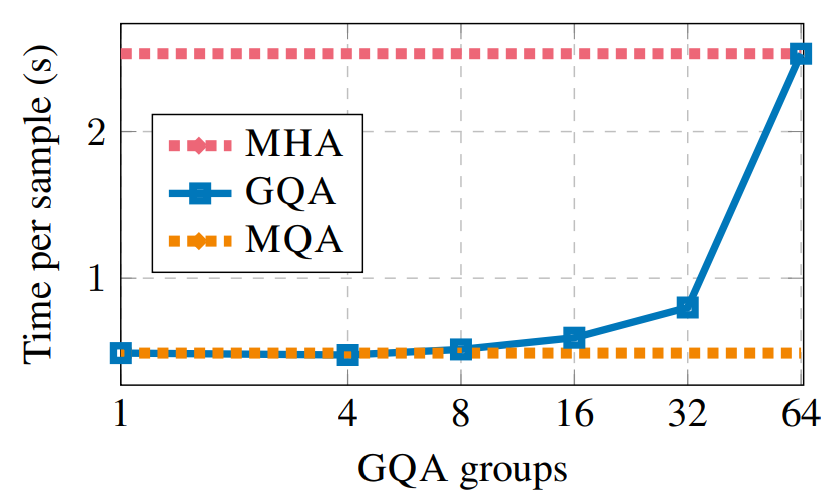
그림 6.은 GQA 그룹의 수가 추론 속도에 미치는 효과를 보여줍니다. 더 큰 모델들에 대해 KV cache로부터 오는 메모리 대역폭 오버헤드는 덜 중요합니다. 반면 KV heads의 수가 늘어남에 따라 loading해야 하는 KV head의 수가 늘어나며, 더 이상 loading으로 인한 오버헤드가 계산으로 인한 오버헤드에 비해 작지 않기 때문에 속도가 점점 느려집니다. 정리하면, MQA로부터 그룹의 수를 늘리는 것은 초기에는 완만한 속도 저하만을 초래하지만, MHA에 더 가까이 이동함에 따라 점점 비용이 증가합니다. 해당 논문에서는 8개의 그룹을 적절한 타협점으로 선택합니다.
Related Work.
해당 연구는 decoder 품질과 추론 시간에 발생하는 KV 값들을 loading하는 것으로부터 오는 메모리 대역폭 오버헤드 사이의 더 나은 trade-off를 달성하는 데 초점을 맞춥니다. MQA는 loading 오버헤드를 줄이는 것을 목표로 하여 처음 제안된 아키텍처입니다. 또한 후속 연구를 통해 MQA는 특히 긴 입력들에 대해 도움이 된다는 것이 밝혀졌습니다(사실 당연한 얘기. MHA은 이전 context들을 담기 위해서는 각 head별로 저장되어 있는 KV 값들을 모두 메모리에 올려야하지만, MQA는 이전 context를 담기 위해 메모리에 올려야하는 KV 값의 크기가 작기 때문에, 오히려 KV 값의 크기를 늘릴 수 있습니다. 이는 곧 LLM이 참조할 수 있는 context 길이의 증가로 이어집니다).
(... Flash attention, Quantization, Layer-sparse cross-attention 등등 overhead를 줄이기 위한 연구들 소개 ...)