
1. Deep Learning
딥러닝은 심층학습입니다. 통계를 기반으로 하는 머신러닝 알고리즘보다 데이터의 복잡한 패턴을 파악하기에 더욱 용이합니다.
딥러닝은 인공지능의 한 분야로 대표적인 기계학습 방법론입니다.
Deep Learning Architecture 는 다음과 같습니다:

신경망은 뇌의 뉴런들이 상호 연결되어 경험으로부터 학습한느 두뇌의 생물학적 활동을 모형화 한 것입니다.
대표적인 신경망 아키텍처로는 MLP(* Multi-Layer Preceptron) 혹은 FFN 이라고 부르는(* Feed-Forward networks) 가 있습니다.
이 네트워크는 단순히 입력 값을 받아들이는 노드들로 구성된 입력층(* Input Layer)과 이전 층으로부터 입력 정보를 받아들이는 노드들로 구성된 전방향층(* Successive Layer)들로 구성됩니다.
인공신경망은 일반적으로 3가지의 인자를 이용하여 정의됩니다.
- 다른 층의 뉴런 간 연결 패턴
- 신경망 내 연경의 가중치를 갱신하는 학습과정
- 뉴런의 가중 입력을 출력으로 변환하는 활성화 함수
1.1 활성화 함수
입력 층으로부터 받은 신호를 가중치를 적용하여 비선형적인 형태로 변환하는 함수입니다.
활성화 함수로 선형 함수를 사용한다면 신경망의 층을 무한으로 나누어도 은닉층이 없는 신경망이므로 성능 향상 및 효율성의 측면에서 비선형함수를 활성화 함수로 사용합니다.
(* 만약, 활성화 함수가 선형이라면(* g: 활성화 함수, 선형) 입력 f가 있을 때(* f:선형), g(f) 가 선형이 됩니다. 그 다음에도 w1 * g(f) + w2 * g(f) + ... + b 도 선형이 되고 ,, 결과적으로 f 에 대한 선형이라는 결과가 나오므로, 단층 퍼셉트론과 다른점이 없게 됩니다.)
활성화 함수로 사용할 수 있는 함수들은 다음과 같습니다:
- 부호 함수: 주로 분류와 패턴인식에 사용되는 활성화 함수입니다.

부호 함수 - 양극성 시그모이드 함수(* 쌍곡탄젠트 함수): 주로 은닉층의 활성화 함수로 사용됩니다.

양극성 시그모이드 - 계단 함수: 주로 분류, 패턴인식, 퍼셉트론에 사용하는 활성화 함수입니다.
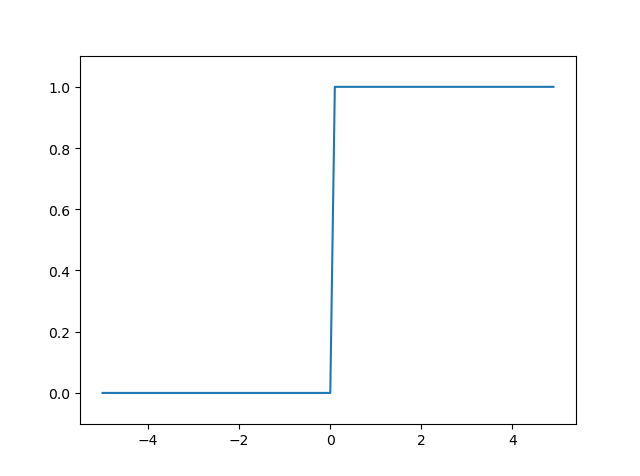
계단 함수 - 단극성 시그모이드 함수(* 로지스틱 함수): 이진 분류 모델에 주로 사용됩니다. 로지스틱 함수는 0과 1사이의 출력값을 가져 확률의 개념으로 해석 가능합니다.

단극성 시그모이드 - 소프트맥스 함수(* SoftMax func): 출력층의 활성화 함수로 사용됩니다. 출력의 총합이 1이기에 확률의 개념으로 해석할 수 있습니다. 일반적으로 분류 작업에서 클래스가 서로 상호 배타적인 경우에 우수한 성능을 보입니다.

소프트맥스 - ReLU 함수: 은닉층의 활성화 함수로 주로 사용됩니다. 계산의 효율성(* 미분이 쉬움), 기울기 소실 방지등 여러가지 장점으로 인해 은닉층을 활성화하기 위해 사용되고 있습니다.

ReLU 함수
2. PyTorch 를 이용한 간단한 예제
PyTorch 는 과거 Facebook 에서 개발한 딥러닝 프레임워크입니다. PyTorch는 텐서(* Tensor)라는 개념을 기반으로 하며, 이는 Numpy 배열과 유사하지만 딥러닝에 최적화된 기능을 제공합니다.
또한 PyTorch는 GPU가속을 지원하여 더 빠른 계산을 수행할 수 있습니다. 텐서를 GPU로 연산할 수 있도록 이동(* .to(device)) 시키면 PyTorch가 자동으로 GPU에서 계산을 수행하므로 대규모 데이터셋에 대한 학습 및 추론에서 처리 속도가 크게 향상됩니다.
PyTorch는 학습된 모델(* Pre-trained Model)의 저장 및 불러오기가 편합니다. 모델의 상태, 아키텍처 및 학습된 파라미터를 파일에 저장할 수 있습니다. 이를 통해 모델의 학습을 이어나가거나 타인과 모델을 공유하거나 실제 환경에 모델을 배포하는 것이 용이합니다.
2.1 간단한 Tensor 의 이용
먼저 Tensor 를 생성해서 연산을 해보겠습니다.
import torch
# Tensor 생성
x = torch.tensor([1,2,3])
y = torch.tensor([4,5,6])
# Tensor 연산 수행
z = x + y
print(z)
# output : tensor([5, 7, 9])
Tensor 를 생성하는 다양한 메소드들을 사용해보겠습니다.
# 0으로 채워진 텐서 생성
# (3,3) 행렬을 만들어봅니다.
zeros = torch.zeros(3, 3)
print('Zero Tensor:\n', zeros)
# output:
# Zero Tensor:
# tensor([[0., 0., 0.],
# [0., 0., 0.],
# [0., 0., 0.]])
# 1로 채워진 텐서 생성
# (3,3) 행렬을 만들어봅니다.
ones = torch.ones(3,3)
print('One Tensor:\n', ones)
# output:
# One Tensor:
# tensor([[1., 1., 1.],
# [1., 1., 1.],
# [1., 1., 1.]])
# 랜덤 값으로 텐서 생성
# (3,3) 행렬을 만들어봅니다.
random_tensor = torch.rand(3,3) # 0~1 의 값이 출력
print('Random tensor:\n', random_tensor)
# output:
# Random Tensor:
# tensor([[0.5393, 0.4428, 0.9126],
# [0.4178, 0.3803, 0.2738],
# [0.2552, 0.5564, 0.7773]])
# (정규 분포 내에) 랜덤 값으로 텐서 생성
# (3,3) 행렬을 만들어봅니다.
random_tansor = torch.randn(3,3)
print("\nRandom Tensor (정규 분포):\n", random_tensor)
# output:
# Random Tensor (정규 분포):
# tensor([[ 0.9922, -0.2929, 2.7911],
# [ 0.0532, -0.2650, -0.3503],
# [ 0.5556, -0.7367, 0.7635]])
# 랜덤 정수 생성
random_tensor = torch.randint(0, 10, (10,)) # (10,) 은 10개의 원소를 갖는 1차원 배열
print('Random Tensor:\n', random_tensor)
# output:
# Random Tensor (정수):
# tensor([2, 4, 8, 7, 6, 5, 9, 0, 3, 6])
reshape() 를 통해 행렬의 모습을 변경할 수 있습니다.
# 범위 내 정수로 텐서 생성
range_tensor = torch.arange(0, 9)
# (3,3) 행렬로 바꿉니다.
range_tensor = range_tensor.reshape(3,3)
print("\nRange Tensor:\n", range_tensor)
# output:
# Range Tensor:
# tensor([[0, 1, 2],
# [3, 4, 5],
# [6, 7, 8]])
range_tensor = torch.arange(0, 8)
range_tensor.reshape(2, 2, 2) # 3차원
# output:
# tensor([[[0, 1],
# [2, 3]],
# [[4, 5],
# [6, 7]]])
torch.matmul() 을 통해 행렬 곱 연산을 수행합니다.
# 행렬 곱셈 수행
A = torch.arange(0,4).reshape(2,2)
B = torch.arange(4,8).reshape(2,2)
result = torch.matmul(A,B)
print(result)
# output:
# tensor([[ 6, 7],
# [26, 31]])
2.1 ReLU 함수 구현
ReLU는 딥러닝에서 가장 널리 사용되는 활성화 함수 중 하나입니다. ReLU 함수는 음수 값을 입력받으면 0을 출력하고, 양수 값을 입력받으면 그 입력 값을 그대로 출력합니다. 이 특성 때문에 ReLU는 특히 심층 신경망에서 비선형성을 도입하고, 학습 속도를 개선하는 데 매우 효과적입니다.
또한 이러한 특성은 모델이 죽은 뉴런 문제(* Dead Neuron Problem)을 일부 피하면서 효율적으로 학습할 수 있도록 돕습니다.
기울기 소실 문제와 ReLU 함수
참고기울기 소실 문제(Vanishing Gradient problem)는 역전파(Backpropagation) 알고리즘에서 처음 입력층(input layer)으로 진행할수록 기울기가 점차적으로 작아지다가 나중에는 거의 기울기의 변화가 없어지
velog.io
# PyTorch 로 구현한 ReLU
def relu(x):
return torch.max(torch.zeros_like(x), x)
# torch.zeros_like(x) 는 x의 행렬 형태와 똑같은 0 행렬을 만들어주는 메소드입니다.
# 각각의 값에 대해서 0보다 크면 살리고, 0보다 작으면 0으로 바꿉니다.
# 테스트 데이터
input_data = torch.randn(3, 3)
print("Input:", input_data)
output = relu(input_data)
print("ReLU output:", output)
# output:
# Input: tensor([[-1.1188, -0.8971, 0.1277],
# [ 0.9776, 1.2711, -0.2155],
# [ 0.4296, 0.0618, -0.3805]])
# ReLU output: tensor([[0.0000, 0.0000, 0.1277],
# [0.9776, 1.2711, 0.0000],
# [0.4296, 0.0618, 0.0000]])
torch.max() 대신 torch.where() 을 이용하여 만들 수도 있습니다.
# PyTorch로 구현한 ReLU(2)
def relu(x):
return torch.where(x>0, x, torch.tensor(0.0))
# 삼항 연산자와 비슷한 메소드
# 테스트 데이터
input_data = torch.randn(3, 3)
print("Input:", input_data)
output = relu(input_data)
print("ReLU output:", output)
# output:
# Input: tensor([[-2.6385, 0.5460, 1.1420],
# [-0.0189, -0.4908, 0.4155],
# [ 1.2610, -1.2585, -0.4528]])
# ReLU output: tensor([[0.0000, 0.5460, 1.1420],
# [0.0000, 0.0000, 0.4155],
# [1.2610, 0.0000, 0.0000]])
2.2 Sigmoid 함수 구현
Sigmoid 함수는 이진 분류에서 사용되는 활성화 함수입니다. 입력받은 값을 0과 1사이의 값으로 출력합니다. 입력받은 값이 0에 가까울수록 출력값은 0에 가까워지고, 입력받은 값이 무한대로 커질수록 출력값은 1에 가까워집니다.
sigmoid 는 이진 분류에서 사용되는 중요한 활성화 함수로, 입력받은 값이 클래스 1일 확률을 계산하는 데 사용됩니다.
# Sigmoid 함수 구현하기
def sigmoid(x):
return 1 / (1 + torch.exp(-x))
# 입력 특성
height = torch.tensor([160, 172, 155, 168, 180]).float() # 키 (단위: cm)
weight = torch.tensor([58, 63, 52, 70, 85]).float() # 몸무게 (단위: kg)
# 이진 레이블
labels = torch.tensor([0,0,0,1,1]) # 0: 정상, 1: 비만
# 가중치와 편향
weights = torch.tensor([-0.7, 1.7])
bias = 0.65
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 가중합 계산
inputs = torch.stack((height, weight), dim=1) # dim=1 이면 세로, dim=0 이면 가로이다.
# inputs.shape 는 (5,2) 이다.
weighted_sum = torch.matmul(inputs, weights) + bias
# weights 의 shape 이 (2,) 이기 때문에 weighted_sum 의 shape 은 (5,) 가 된다.
# 그래서 아래에 plot 을 그릴때 .numpy() 가 바로 된다.
# 만약 weights 가 (2,1) 이었으면 weighted_sum 의 shape 이 (5,1) 이 되고
# 아래서에 plot 을 그릴때 .numpy() 가 바로 안되고
# reshape(5,) 를 해주고 .numpy() 를 해줘야한다.(* 2-d 는 바로 .numpy() 가 안되니까)
# 시그모이드 함수를 적용하여 예측 확률 계산
predicted_probs = sigmoid(weighted_sum)
# Sigmoid 함수 그래프 시각화
x = np.linspace(-20, 20, 100)
y = sigmoid(torch.tensor(x, dtype=torch.float)).numpy()
# Seaborn으로 그래프 작성
plt.figure(dpi = 150)
sns.set(style="whitegrid")
plt.plot(x, y, color='blue', label='Sigmoid')
sns.scatterplot(x=weighted_sum.numpy(), y=predicted_probs.numpy(), hue=predicted_probs.numpy(), palette='coolwarm', legend=None)
plt.xlabel('Weighted Sum')
plt.ylabel('Predicted Probability')
plt.title('Sigmoid Function with Predicted Probability')
plt.legend()
plt.show()
2.3 Softmax 함수 구현
Softmax 함수는 입력값을 0과 1 사이의 값으로 정규화하고, 그 값들의 함이 1이 되도록 하는 함수입니다.
Softmax 함수의 수식을 살펴보면 분모에는 전체값을 더하고, 분자에는 그 중 하나의 값이 들어가 있는 것을 볼 수 있습니다. 지수 함수를 부시하고 보면 여러 값들 중에 하나의 값이 차지하는 비율을 의미함을 알 수 있습니다.
xi 가 갖는 값이 0과 1사이의 값이고, 모든 값의 합이 1이라는 의미를 다시 생각해보면,
이는 전체 값 중에서 xi가 갖는 확률값을 의미합니다. 그래서 Softmax 함수는 신경망 모델이 마지막 단계에서 출력한 값을 확률값으로 계산할 때 주로 사용됩니다. 다중 분류 문제에서 각 클래스가 정답일 확률을 추정하는 데 주로 사용됩니다.
이를 위해서 torch.sum() 메소드에 대해 알아야합니다.
torch.sum()
먼저 Tensor 를 생성해줍니다.
# 2x3 텐서 생성
x = torch.tensor([[1.0, 2.0, 3.0],
[4.0, 5.0, 6.0]])
print("원본 텐서 x:")
print(x)
print("텐서 크기:", x.shape)
# output
# 원본 텐서 x:
# tensor([[1., 2., 3.],
# [4., 5., 6.]])
# 텐서 크기: torch.Size([2, 3])
그 후 여러가지 파라미터를 조작하며 메소드를 파악해줍니다.
# dim = 1 로 합계 계산
sum_dim1 = torch.sum(x, dim=1)
print("dim=1로 합산한 결과:")
print(sum_dim1)
print("텐서 크기:", sum_dim1.shape)
# output:
# dim=1로 합산한 결과:
# tensor([ 6., 15.])
# 텐서 크기: torch.Size([2])
# 해석:
# dim=1 은 세로를 의미한다.
# 즉, 세로로 이동하면서 값을 더해준다.# dim=1로 합계 계산, keepdim=True로 유지
sum_dim1_keepdim = torch.sum(x, dim=1, keepdim=True)
print("dim=1로 합산한 결과 (keepdim=True):")
print(sum_dim1_keepdim)
print("텐서 크기:", sum_dim1_keepdim.shape)
# output:
# dim=1로 합산한 결과 (keepdim=True):
# tensor([[ 6.],
# [15.]])
# 텐서 크기: torch.Size([2, 1])
# 해석:
# keepdim 을 True 로 해주면
# x 의 dimension 을 유지하면서 sum 을 계산한다.
# keepdim 이 false 일때, 차원이 1차원이 된것과 차이점을 볼 수 있다.# dim=0로 합계 계산
sum_dim0 = torch.sum(x, dim=0)
print("dim=0로 합산한 결과:")
print(sum_dim0)
print("텐서 크기:", sum_dim0.shape)
# output:
# dim=0로 합산한 결과:
# tensor([5., 7., 9.])
# 텐서 크기: torch.Size([3])
# 해석:
# dim=0 은 가로를 의미한다.
# 가로로 이동하면서 sum 을 해준다.# dim=0로 합계 계산, keepdim=True로 유지
sum_dim0_keepdim = torch.sum(x, dim=0, keepdim=True)
print("dim=0로 합산한 결과 (keepdim=True):")
print(sum_dim0_keepdim)
print("텐서 크기:", sum_dim0_keepdim.shape)
# output:
# dim=0로 합산한 결과 (keepdim=True):
# tensor([[5., 7., 9.]])
# 텐서 크기: torch.Size([1, 3])
# 해석:
# x 의 차원을 유지하며 sum 을 해준다
torch.sum() 을 이용해 softmax 함수를 구현해줍니다.
# PyTorch로 구현한 Softmax
def softmax(x):
exp_x = torch.exp(x)
return exp_x / exp_x.sum(dim = 1, keepdim = True)
# 임의의 로짓 텐서
logits = torch.tensor([[2.0, 1.0, 0.1],
[0.5, 2.0, 1.0],
[0.2, 1.0, 3.0]])
# 소프트맥스 활성화 함수 적용
probabilities = softmax(logits)
# 확률 출력
print('직접 정의한 Softmax 확률값:\n', probabilities)
predicted_labels = torch.argmax(probabilities, dim=1) # 세로로 지나가면서, 가장 큰 값을 가진 원소의 위치를 출력
print('예측 레이블:\n', predicted_labels)
# output:
# 직접 정의한 Softmax 확률값:
# tensor([[0.6590, 0.2424, 0.0986],
# [0.1402, 0.6285, 0.2312],
# [0.0508, 0.1131, 0.8360]])
# 예측 레이블:
# tensor([0, 1, 2])
배움
dim
기울기 소실 문제(* 죽은 뉴런 문제)
'[Deep daiv.] > [Deep daiv.] 복습' 카테고리의 다른 글
| [Deep daiv.] TIL - 6. Word2Vec을 활용한 단어 임베딩 (1) | 2024.08.16 |
|---|---|
| [Deep daiv.] TIL - 2차 특강. 파이프라인과 하이퍼 파라미터 튜닝 (1) | 2024.08.11 |
| [Deep daiv.] TIL - 4.1 k-NN 알고리즘과 의사 결정 나무 (1) | 2024.08.11 |
| [Deep daiv.] TIL - 4강. 지도 학습(분류) (0) | 2024.08.11 |
| [Deep daiv.] TIL - 3.1 차원축소와 클러스터링 (0) | 2024.08.09 |