
1. k-NN 알고리즘
2024.03.19 - [머신러닝] - 머신러닝 공부 - 1 머신러닝에 대한 기본적인 이해와 KNN 알고리즘
머신러닝 공부 - 1 머신러닝에 대한 기본적인 이해와 KNN 알고리즘
1. 분류와 회귀 머신러닝(Machine Learning) 은 크게 두 종류로 나타낼 수 있습니다. 분류(Classification) 회귀(Regression) 분류 (Classification) 는 미리 정의된 가능성 있는 여러 클래스 레이블 중 하나를 예측
hw-hk.tistory.com
2024.03.22 - [머신러닝] - 머신러닝 공부 - 2 KNN Regression and Linear Model
머신러닝 공부 - 2 KNN Regression and Linear Model
1. K-NN Regression k-최근접 이웃 알고리즘은 회귀 분석에도 쓰입니다. mglearn.plots.plot_knn_regression(n_neighbors = 1) 을 통해 그림으로 확인 할 수 있고, n_neighbors 의 값을 바꿔서도 확인할 수 있습니다. 여러
hw-hk.tistory.com
에 너무나도 자세하게 적어놨습니다 !!
2. 의사 결정 나무
데이터들이 있을때, 결정 경계를 통해 클래스를 구분하는 방법입니다.
결정 경계?
의사 결정 나무는 불순도, 즉 지니계수가 낮아지는 방향으로 계속 분기를 하는데 분류의 경우 최종적으로는 높은 예측 정확도를 목표로 할 수 있을 것입니다.
예를 들어, 사람의 키와 몸무게를 특성으로 하고 클래스 0,1,2 로 분류하는 데이터셋이 있다고 하면,
의사 결정 나무는 각 특성들의 모든 데이터를 분기점을 고려해 두 개의 하위 그룹으로 나눴을 때의
가장 지니계수가 낮아지는 특성과 그 값을 분기점으로 선택합니다.

지니계수가 아니더라도, 엔트로피와 정보 이득을 바탕으로 결정경계를 나누기도 합니다.

장점
- 해석 / 설명이 가능하다.
- 데이터 전처리가 간단하다
- 비선형 관계도 포착할 수 있다.
단점
- 과적합 경향이 있다.
- 작은 데이터 변화에 민감하다.
- 최적화가 어렵다.(* max_depth 를 정해줘야 하니 최적의 모델을 찾기 어렵다.)
3. Metric
어떤 모델이 좋은 모델인가?
분류 문제에서는 정확도만을 좋은 모델의 기준이라고 생각한다면 안된다.
정확도는 (정답 개수 / 전체 테스트셋의 개수) 로 계산할 수 있다.
정확도 말고, 분류 모델의 성능을 측정할 수 있는 다양한 평가 기준이 있습니다.
정밀도(* Precision)
양성으로 판단한 것들 중에 실제로 양성인 것의 비율입니다. 다시 말해, 해당 모델이 얼마나 '정밀' 한지를 나타내는 지표입니다.


다음의 경우 Model A 의 정밀도는 (0 / 0 + 0) 으로 0입니다.(* 수학과 달리 분모가 0이면 0입니다.)
Model B 의 정밀도는 (3 / 5 + 3) 으로 37.5% 입니다.
Model A 의 정확도가 Model B 의 정확도보다 높지만, 정밀도의 측면에서는 떨어짐을 알 수 있습니다.
학습 데이터와 테스트 데이터의 정답 레이블의 편향성 때문에 한 쪽으로만 예측하는 모델도 높은 정확도를 갖을 수 있기 때문입니다.
재현율(* Recall), 민감도(* Sensitivity)
실제 양성인 것중 양성으로 판단한 비율입니다. 다시 말해. 양성에 대해서 얼마나 '민감' 하게 반응하는 지를 나타내는 지표입니다.

다음의 경우 Model A 의 재현율은 (0 / 0 + 3) 으로 0 입니다.
Model B 의 재현율은 (3 / 3 + 0) 으로 100% 입니다.
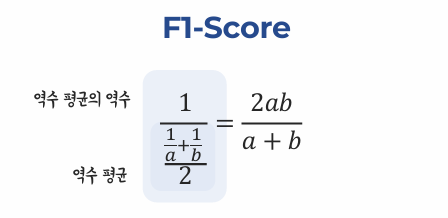
F1 Score
두 지표가 모두 중요하기 때문에 이 둘의 조화 평균인 F1-Score 를 평가 지표로 많이 사용합니다.
'[Deep daiv.] > [Deep daiv.] 복습' 카테고리의 다른 글
| [Deep daiv.] TIL - 6. Word2Vec을 활용한 단어 임베딩 (1) | 2024.08.16 |
|---|---|
| [Deep daiv.] TIL - 2차 특강. 파이프라인과 하이퍼 파라미터 튜닝 (2) | 2024.08.11 |
| [Deep daiv.] TIL - 4강. 지도 학습(분류) (0) | 2024.08.11 |
| [Deep daiv.] TIL - 3.1 차원축소와 클러스터링 (0) | 2024.08.09 |
| [Deep daiv.] TIL - 3. 비지도 학습 (0) | 2024.08.09 |
1. k-NN 알고리즘
2024.03.19 - [머신러닝] - 머신러닝 공부 - 1 머신러닝에 대한 기본적인 이해와 KNN 알고리즘
머신러닝 공부 - 1 머신러닝에 대한 기본적인 이해와 KNN 알고리즘
1. 분류와 회귀 머신러닝(Machine Learning) 은 크게 두 종류로 나타낼 수 있습니다. 분류(Classification) 회귀(Regression) 분류 (Classification) 는 미리 정의된 가능성 있는 여러 클래스 레이블 중 하나를 예측
hw-hk.tistory.com
2024.03.22 - [머신러닝] - 머신러닝 공부 - 2 KNN Regression and Linear Model
머신러닝 공부 - 2 KNN Regression and Linear Model
1. K-NN Regression k-최근접 이웃 알고리즘은 회귀 분석에도 쓰입니다. mglearn.plots.plot_knn_regression(n_neighbors = 1) 을 통해 그림으로 확인 할 수 있고, n_neighbors 의 값을 바꿔서도 확인할 수 있습니다. 여러
hw-hk.tistory.com
에 너무나도 자세하게 적어놨습니다 !!
2. 의사 결정 나무
데이터들이 있을때, 결정 경계를 통해 클래스를 구분하는 방법입니다.
결정 경계?
의사 결정 나무는 불순도, 즉 지니계수가 낮아지는 방향으로 계속 분기를 하는데 분류의 경우 최종적으로는 높은 예측 정확도를 목표로 할 수 있을 것입니다.
예를 들어, 사람의 키와 몸무게를 특성으로 하고 클래스 0,1,2 로 분류하는 데이터셋이 있다고 하면,
의사 결정 나무는 각 특성들의 모든 데이터를 분기점을 고려해 두 개의 하위 그룹으로 나눴을 때의
가장 지니계수가 낮아지는 특성과 그 값을 분기점으로 선택합니다.
지니계수가 아니더라도, 엔트로피와 정보 이득을 바탕으로 결정경계를 나누기도 합니다.
장점
- 해석 / 설명이 가능하다.
- 데이터 전처리가 간단하다
- 비선형 관계도 포착할 수 있다.
단점
- 과적합 경향이 있다.
- 작은 데이터 변화에 민감하다.
- 최적화가 어렵다.(* max_depth 를 정해줘야 하니 최적의 모델을 찾기 어렵다.)
3. Metric
어떤 모델이 좋은 모델인가?
분류 문제에서는 정확도만을 좋은 모델의 기준이라고 생각한다면 안된다.
정확도는 (정답 개수 / 전체 테스트셋의 개수) 로 계산할 수 있다.
정확도 말고, 분류 모델의 성능을 측정할 수 있는 다양한 평가 기준이 있습니다.
정밀도(* Precision)
양성으로 판단한 것들 중에 실제로 양성인 것의 비율입니다. 다시 말해, 해당 모델이 얼마나 '정밀' 한지를 나타내는 지표입니다.
다음의 경우 Model A 의 정밀도는 (0 / 0 + 0) 으로 0입니다.(* 수학과 달리 분모가 0이면 0입니다.)
Model B 의 정밀도는 (3 / 5 + 3) 으로 37.5% 입니다.
Model A 의 정확도가 Model B 의 정확도보다 높지만, 정밀도의 측면에서는 떨어짐을 알 수 있습니다.
학습 데이터와 테스트 데이터의 정답 레이블의 편향성 때문에 한 쪽으로만 예측하는 모델도 높은 정확도를 갖을 수 있기 때문입니다.
재현율(* Recall), 민감도(* Sensitivity)
실제 양성인 것중 양성으로 판단한 비율입니다. 다시 말해. 양성에 대해서 얼마나 '민감' 하게 반응하는 지를 나타내는 지표입니다.
다음의 경우 Model A 의 재현율은 (0 / 0 + 3) 으로 0 입니다.
Model B 의 재현율은 (3 / 3 + 0) 으로 100% 입니다.
F1 Score
두 지표가 모두 중요하기 때문에 이 둘의 조화 평균인 F1-Score 를 평가 지표로 많이 사용합니다.
'[Deep daiv.] > [Deep daiv.] 복습' 카테고리의 다른 글
| [Deep daiv.] TIL - 6. Word2Vec을 활용한 단어 임베딩 (1) | 2024.08.16 |
|---|---|
| [Deep daiv.] TIL - 2차 특강. 파이프라인과 하이퍼 파라미터 튜닝 (2) | 2024.08.11 |
| [Deep daiv.] TIL - 4강. 지도 학습(분류) (0) | 2024.08.11 |
| [Deep daiv.] TIL - 3.1 차원축소와 클러스터링 (0) | 2024.08.09 |
| [Deep daiv.] TIL - 3. 비지도 학습 (0) | 2024.08.09 |