
0. 지도 학습
2024.08.09 - [[Deep daiv.] 복습] - [Deep daiv.] TIL - 3. 비지도 학습
[Deep daiv.] TIL - 3. 비지도 학습
0. 기본 세팅 우선 한글 폰트를 설치하고, seaborn 에 한글 폰트를 설정을 해야합니다.# 한글 폰트 설치# 이 셀을 실행시키고 '런타임 > 세션 다시 시작'을 해주세요!sudo apt-get install -y fonts-nanum!sudo fc
hw-hk.tistory.com
데이터의 레이블 없이 데이터의 특성 분포를 파악하는 비지도 학습과는 달리,
지도 학습은 데이터의 레이블을 기반으로 패턴을 학습하고 예측하는 방법입니다.
레이블?
이때 레이블은 각 입력 데이터(특성) 에 대해 예측해야 하는 정답값입니다.
주성분 분석이나, 각종 클러스터링 방법으로 대표되는 비지도 학습은 정답 레이블이 없는 머신 러닝 기법입니다.
하지만, 분류나 회귀에 사용되는 지도 학습 기법들은 정답 레이블이 필수적입니다.
이번 TIL 에서는 k-NN 알고리즘과 의사결정 나무를 활용하여 분류 문제를 풀어보겠습니다.
1. 데이터 전처리
이번 TIL 에서는 피파22의 선수 데이터를 가지고 와서, 선수들의 주 포지션을 예측하는 문제를 풀어보겠습니다.
그러기 위해서 미리 다운 받아놓은 .CSV 데이터를 DataFrame 으로 바꿔줍니다.
import pandas as pd
import re
filepath = '...'
df = pd.read_csv(filepath, encording = 'utf-8')
df
결과

그 후 정답 레이블이 될 컬럼을 확인해줍니다. 그리고 정답 레이블의 분포도 살펴봅니다.
# 포지션 확인
unique_position = df['Best Position'].unique()
print(unique_position, '포지션 개수', len(unique_position), '개')
# ['CAM' 'CM' 'ST' 'LB' 'CDM' 'CB' 'RB' 'LM' 'RW' 'LW' 'CF' 'LWB' 'RM' 'RWB'
# 'GK'] 포지션 개수 15 개
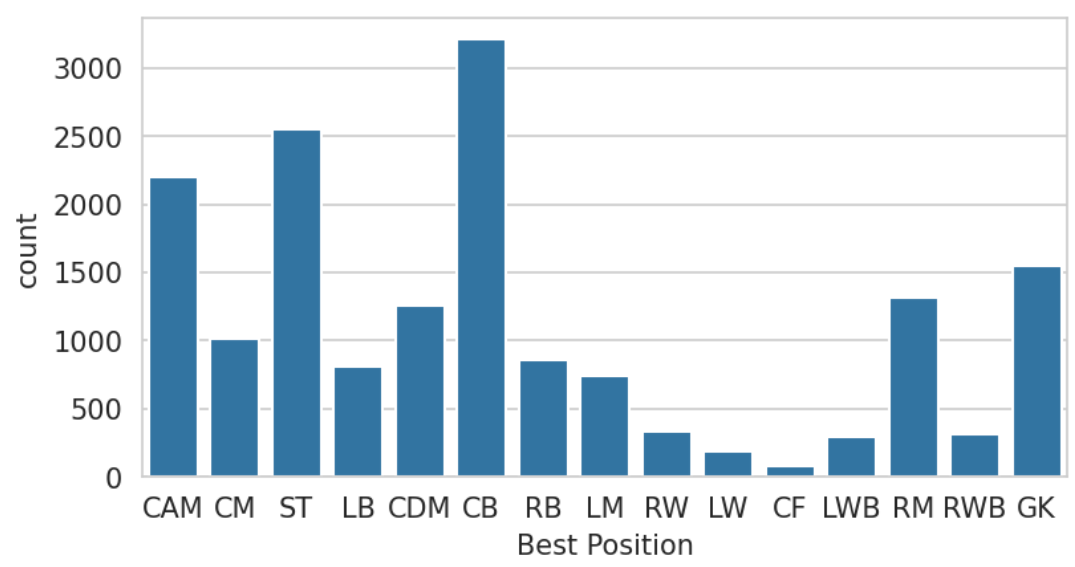
# 포지션별 카운트(Count Plot)
plt.figure(figsize = (6,3), dpi = 150)
sns.countplot(x = 'Best Position', data = df)
plt.show()
결과
그 후 레이블 인코딩을 합니다.
인코딩?
머신러닝/딥러닝을 할 때 문자열의 값들을 숫자형으로 인코딩하는 전처리 단계가 필요한 경우가 있습니다.
머신러닝을 통해 정답 레이블을 예측하는 경우, 기계가 문자열의 값을 출력으로 만들기는 어렵기 때문입니다.
이때, 사용하는 인코딩 방식은 크게 2가지가 존재합니다.
- Label Encoding
- One Hot Encoding
레이블 인코딩?
Label Encoding 이란 문자열의 unique값을 숫자로 바꿔주는 방법입니다.
예를 들어, 과일 변수를 인코딩하는 과정을 생각해봅시다.
from sklearn.preprocessing import LabelEncoder
fruit = ['바나나', '사과', '사과', '포도', '딸기', '포도', '바나나']
print(sorted(set(fruit))
encoder = LabelEncoder()
labels = encoder.fit_transform(fruit)
print(labels)
# outputs
# ['딸기', '바나나', '사과', '포도']
# [1 2 2 3 0 3 1]
print(encoder.classes_)
print(encoder.inverse_tranform([0, 1, 2, 3])
# ['딸기', '바나나', '사과', '포도']
# ['딸기', '바나나', '사과', '포도']
문제점
- 숫자값으로 변환되어 숫자의 ordinal 한 특성이 반영되어 독립적인 관측값간의 관계성이 생긴다.
- 숫자값을 가중치로 잘못 인식하여 값에 왜곡이 생길 수 있다.
이러한 특성들을 예측 성능의 저하를 일으키므로, 선형 회귀와 같은 ML알고리즘에서는 보통 적용하지 않습니다. 하지만 트리계열의 ML알고리즘에서는 숫자의 ordinal 한 특성을 반영하지 않으므로 레이블 인코딩은 문제가 되지 않습니다.
원-핫 인코딩?
One-Hot Encoding 은 긴 리스트의 형태로 구성된 변수들을 wide-type 으로 목록화하여 변수의 차원을 늘립니다. 이후 개별로 해당 컬럼이 맞으면 1 아니면 0 의 이진수를 갖습니다.
원-핫 인코딩은 sklearn의 OneHotEncoder 클래스로 쉽게 가능하나, 문자열에서 바로 변환은 되지 않기에, 라벨인코더를 통해 숫자로 변환 한 후 사용가능합니다.
from sklearn.preprocessing import OneHotEncoder
import numpy as np
fruit = ['바나나', '사과', '사과', '포도', '딸기', '포도', '바나나']
# Step1: 모든 문자를 숫자형으로 변환합니다.
encoder = LabelEncoder()
encoder.fit(fruit)
labels = encoder.transform(fruit)
# Step2: 2차원 데이터로 변환합니다.
labels = labels.reshape(-1, 1)
# Step3: One-Hot Encoding 적용합니다.
oh_encoder = OneHotEncoder()
oh_encoder.fit(labels)
oh_labels = oh_encoder.transform(labels)레이블인코딩(Label Encoding) vs 원핫인코딩(One-hot Encoding) 비교
컴퓨터는 인간의 언어를 이해하지 못한다. 우리가 컴퓨터에 한글을 입력한다 해도 컴퓨터가 받아들이는 것은 0과 1의 이진수로 이해를 하게된다. 따라서 우리가 머신러닝/딥러닝을 할 때 문자열
hye-z.tistory.com
아무튼.. 각 포지션에 대해서 레이블 인코딩을 실행합니다.(* 선형 회귀와 같은 ML을 사용하지는 않을것이니까)
# 데이터 레이블 인코딩
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
# 정답 레이블 인코딩
y = encoder.fit_transform(df['Best Position']);
y
# array([ 0, 4, 14, ..., 5, 5, 14])
그 후 ML에 사용할 특성들을 선택해줍니다.
주어진 데이터를 봤을 때, 포지션을 예측하기에 도움이 될만한 컬럼들은
컬럼 인덱스 27번 부터, 60번 까지입니다. (* Crossing ~ GKReflexes)
따라서 이를 바탕으로 학습 데이터를 생성합니다.
# 학습 데이터 생성 (.iloc)
X = df.iloc[:, 27:61].copy()
X
결과

학습 데이터가 될 행렬의 결측치를 확인해야합니다.
# 결측치 개수 확인
X.isnull().sum()
# Volleys, Curve 등 요소들이 37개의 결측치를 갖고,
# Marking 의 경우 15818 개의 결측치를 갖습니다.
Marking 의 경우는 결측치가 너무 많아, 아에 학습에 사용할 데이터로는 적합하지 않아보입니다.
따라서 Marking 컬럼은 drop 해줍니다.
그리고 나머지 결측이 있는 컬럼들은 보간을 해줍니다.
(* 보간을 해주는 방법은 정말 다양합니다. 그중 시계열 데이터의 값에 선형으로 비례하는 방식으로 결측치를 보간하겠습니다.)
https://rfriend.tistory.com/264
[Python pandas] 결측값 보간하기 (interpolation of missing values) : interpolate(), interpolate(method='time'), interpolat
지난번 포스팅에서는 Python pandas 의 dropna() method를 사용해서 - 결측값이 들어있는 행 전체 제거하기 - 결측값이 들어있는 열 전체 제거하기 방법을 알아보았습니다. 이번 포스팅에서는 Python pandas
rfriend.tistory.com
# 결측 데이터 보간
X.interpolate(axis = 1, inplace = True)
# 결측치 확인
X.isnull().sum()
# 결측치가 없습니다.
2. 학습-훈련 데이터셋 구축
사이킷 런에서 제공하는 train_test_split 을 이용하면 편리하게 구분할 수 있습니다.
test_size 에는 비율만 입력하면 임의로 학습 데이터와 훈련 데이터를 분리해줍니다.
직접 30% 를 분리해도 괜찮지만 랜덤하게 샘플링하려면 이 방법이 훨씬 편리합니다.
# 학습-훈련 데이터셋 분리
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 1201)
3. k-NN 알고리즘
k-NN 알고리즘을 이용하여 분류를 실행합니다.
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# k-NN 모델 초기화
neigh = KNeighborsClassifier(n_neighbors = 7)
# 모델 학습
neigh.fit(X_train, y_train)
# 예측
y_pred = neigh.predict(X_test)
# 정확도 출력
acc = accuracy_score(y_test, y_pred)
print('k-NN 모델의 정확도:', '%.4f' %acc)
# classification report 출력
report = classification_report(y_test, y_pred)
print('Classification Report:\n', report)
# outputs
'''
k-NN 모델의 정확도: 0.6717
Classification Report:
precision recall f1-score support
0 0.59 0.76 0.66 654
1 0.89 0.91 0.90 970
2 0.56 0.69 0.62 383
3 0.20 0.05 0.07 22
4 0.53 0.48 0.50 306
5 1.00 1.00 1.00 470
6 0.37 0.36 0.36 265
7 0.21 0.14 0.17 205
8 0.09 0.02 0.03 61
9 0.13 0.07 0.09 91
10 0.30 0.33 0.32 250
11 0.45 0.40 0.42 381
12 0.23 0.03 0.06 90
13 0.17 0.06 0.09 93
14 0.88 0.94 0.91 772
accuracy 0.67 5013
macro avg 0.44 0.42 0.41 5013
weighted avg 0.64 0.67 0.65 5013
'''
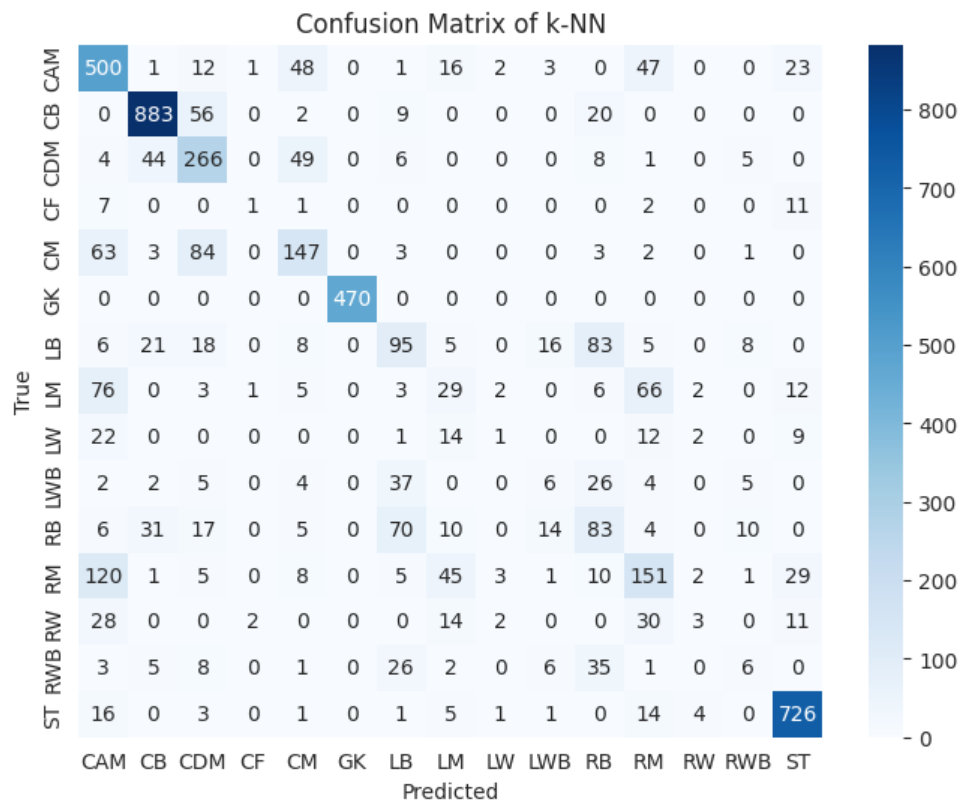
분류 리포트를 Confusion Matrix 를 통해 시각화 해보겠습니다.
conf_matrix = confusion_matrix(y_test, y_pred)
plt.figure(figsize = (8,6), dpi = 100)
sns.heatmap(data = conf_matrix, annot = True, fmt = 'd', cmap = 'Blues', xticklabels = encoder.classes_, yticklabel = encoder_classes_)
plt.xlabel('Predicted')
plt.ylabel('True')
plt.title('Confusion Matrix of k-NN')
plt.show()
결과
4. 의사 결정 나무
from sklearn.tree import DecisionTreeClassifier
# 의사 결정 나무
dt = DecisionTreeClassifier(max_depth = 10)
dt.fit(X_train, y_train)
y_pred = dt.predict(X_test)
acc = accuracy_score(y_test, y_pred)
print('Decision Tree 모델 정확도:', '%.4f' %acc)
# Decision Tree 모델의 정확도: 0.6318
배움
데이터 보간
인코딩과 다중 공선성
'[Deep daiv.] > [Deep daiv.] 복습' 카테고리의 다른 글
| [Deep daiv.] TIL - 2차 특강. 파이프라인과 하이퍼 파라미터 튜닝 (1) | 2024.08.11 |
|---|---|
| [Deep daiv.] TIL - 4.1 k-NN 알고리즘과 의사 결정 나무 (1) | 2024.08.11 |
| [Deep daiv.] TIL - 3.1 차원축소와 클러스터링 (0) | 2024.08.09 |
| [Deep daiv.] TIL - 3. 비지도 학습 (0) | 2024.08.09 |
| [Deep daiv.] TIL - 2. 동적 크롤링 (0) | 2024.08.09 |