
0. 개요
토픽 모델링은 문서 집합에서 주제를 찾아내기 위한 기술입니다.
토픽 모델링은 '특정 주제에 관한 문서에서는 특정 단어가 자주 등장할 것이다'라는 직관을 기반으로 합니다.
예를 들어, 주제가 '개'인 문서에서는 개의 품종, 개의 특성을 나타내는 단어가 다른 문서에 비해 많이 등장할 것입니다.
주로 사용되는 토픽 모델링 방법은 잠재 의미 분석(* LSA)와 잠재 디리클래 할당 기법(* LDA)이 있습니다.
1. 잠재 의미 분석(* Latent Semantic Analysis)
잠재 의미 분석(* LSA)은 주로 문서 색인의 의미 검색에 사용됩니다. 그래서 잠재 의미 인덱싱(* Latent Semantic Indexing, LSI)로도 알려져 있습니다.
LSA의 목표는 문서와 단어의 기반이 되는 잠재적인 토픽을 발견하는 것입니다.
잠재적인 토픽은 문서에 있는 단어들의 분포를 주도한다고 가정합니다.
LSA의 방법은 다음과 같습니다:
- 문서 모음에서 생성한 문서-단어 행렬(* Document Term Matrix, DTM)에서 SVD를 통해 단어-토픽 행렬(* Term-Topic Matrix)과 토픽-중요도 행렬(* Topic-Importance Matrix), 그리고 토픽-문서 행렬(* Topic-Document Matrix)로 분해합니다.
- 이때 Truncated SVD 를 사용하는데 절단의 정도인 t가 주제, 토픽의 개수가 됩니다. 이에 따라 U 행렬은 (문서 개수) x t 의 행렬이 되고, 각 행렬의 값 Udt는 문서 d가 토픽 t에 해당하는 정도가 됩니다.
- 그리고 V.T(* V 행렬의 전치행렬) 은 t x (단어의 개수) 의 행렬이 되는데, 이는 각 단어가 토픽에서 차지하는 비율을 의미합니다.
19-01 잠재 의미 분석(Latent Semantic Analysis, LSA)
LSA는 정확히는 토픽 모델링을 위해 최적화 된 알고리즘은 아니지만, 토픽 모델링이라는 분야에 아이디어를 제공한 알고리즘이라고 볼 수 있습니다. 이에 토픽 모델링 알고리즘인 LD…
wikidocs.net
2. 잠재 디리클레 할당(* Latent Dirichlet Allocation)
잠재 디리클레 할당(* LDA)은 대표적인 토픽 모델링 알고리즘 중 하나입니다.
잠재 디리클레 할당의 방법은 다음과 같습니다:
- 사용자가 토픽의 개수를 지정해 알고리즘에 전달
- 모든 단어들을 토픽 중 하나에 할당
- 모든 문서의 모든 단어에 대해 단어 w가 토픽을 가지고 있다는 가정에 의거, p(t|d), p(w|t) 에 따라 토픽을 재할당, 이를 반복, 이때 가정은 자신만이 잘못된 토피에 할당되어있고, 다른 모든 단어는 올바른 토픽에 할당된다는 것을 의미
p(t|d): 문서 d의 단어들 중 토픽 t에 해당하는 비율
이는 해당 문서에서 등장하는 다른 단어의 토픽이 해당 단어의 토픽이 될 가능성이 높음을 의미합니다.
p(w|t): 단어 w를 가지고 있는 모든 문서들 중 단어 w가 토픽 t에 할당된 비율
이는 다른 문서에 있는 단어 w에 할당된 토픽이 해당 단어의 토픽이 될 가능성이 높음을 의미합니다.
19-02 잠재 디리클레 할당(Latent Dirichlet Allocation, LDA)
토픽 모델링은 문서의 집합에서 토픽을 찾아내는 프로세스를 말합니다. 이는 검색 엔진, 고객 민원 시스템 등과 같이 문서의 주제를 알아내는 일이 중요한 곳에서 사용됩니다. 잠재 디…
wikidocs.net
3. 데이터 준비
sklearn 에서 뉴스 데이터를 가져옵니다.
from sklearn.datasets import fetch_20newsgroups
datasets = fetch_20newsgroups(shuffle=True, random_state=1,
remove=('headers', 'footers', 'quotes')) # 제목등의 데이터는 필요없음
documents = datasets.data
print(len(documents))
documents[0]
# output:
'''
11314
Well i'm not sure about the story nad it did seem biased. What\nI disagree with is your statement that
the U.S. Media is out to\nruin Israels reputation. That is rediculous. The U.S. media is\nthe most pro
-israeli media in the world. Having lived in Europe\nI realize that incidences such as the one described
in the\nletter have occured. The U.S. media as a whole seem to try to\nignore them. The U.S. is
subsidizing Israels existance and the\nEuropeans are not (at least not to the same degree).
So I think\nthat might be a reason they report more clearly on the\natrocities.\n\tWhat is a shame is
that in Austria, daily reports of\nthe inhuman acts commited by Israeli soldiers and the blessing\n
received from the Government makes some of the Holocaust guilt\ngo away. After all, look how the Jews are
treating other races\nwhen they got power. It is unfortunate.\n
'''
데이터를 받아온 후,
전처리를 위한 함수들을 정의해줍니다.
import re
import nltk
from nltk.corpus import stopwords
from gensim.parsing.preprocessing import preprocess_string
# 불용어 다운로드
nltk.download('stopwords')
# 문자와 띄어쓰기를 제외한 문자들을 삭제
def clean_text(d):
pattern = re.compile('[^a-zA-Z\s]')
text = re.sub(pattern, '', d)
return d
# 불용어 처
def clean_stopwords(d):
stop_words = stopwords.words('english')
return ' '.join([w.lower() for w in d.split() if w not in stop_words and len(w) > 3])
def preprocessing(d):
return preprocess_string(d) # 이걸 왜 쓰는지는 잘 ... 모르
가져온 데이터를 DataFrame 에 저장한 후,
결측치를 처리, 이전에 정의했던 함수들을 사용해 전처리 해줍니다.
import pandas as pd
news_df = pd.DataFrame({'article': documents})
len(news_df)
# output: 11314
news_df.replace("", float("NaN"), inplace=True)
news_df.dropna(inplace=True)
print(len(news_df))
# output: 11096
news_df['article'] = news_df['article'].map(clean_text)
news_df['article'] = news_df['article'].map(clean_stopwords)
tokenized_news = news_df['article'].map(preprocessing) # 해당 함수의 리턴값은 토큰들이다.
추가로,
문서에서 토큰의 개수가 1이하인 것들도 삭제해줍니다.
import numpy as np
drop_news = [index for index, sentence in enumerate(tokenized_news) if len(sentence) <= 1] # 문서에서 토큰의 개수가 1이하인 문서의 인덱스 추출
news_texts = np.delete(tokenized_news, drop_news, axis=0) # 해당 인덱스에 해당하는 값을 제거
print(len(news_texts))
# output: 10936
4. Gensim 을 이용한 토픽 모델링
토픽 모델링을 위해 BoW와 사전을 만들어줍니다.
from gensim import corpora
dictionary = corpora.Dictionary(news_texts) # 토큰 리스트를 이용해 사전을 구성
corpus = [dictionary.doc2bow(text) for text in news_texts] # BoW 생성
4.1 잠재 의미 분석을 위한 LsiModel
gensim의 LsiModel 을 불러와 토픽를 추출합니다.
from gensim.models import LsiModel
lsi_model = LsiModel(corpus, num_topics=20, id2word=dictionary)
topics = lsi_model.print_topics()
topics # 각 주제에 따른 단어들의 비중을 나타낸다.
# output:
'''
[(0,
'-0.994*"max" + -0.069*"giz" + -0.068*"bhj" + -0.025*"qax" + -0.015*"biz" + -0.014*"nrhj" + -0.014*"bxn" + -0.012*"nui" + -0.011*"ghj" + -0.011*"zei"'),
(1,
'0.381*"file" + 0.193*"program" + 0.169*"edu" + 0.162*"imag" + 0.130*"avail" + 0.126*"output" + 0.119*"includ" + 0.115*"inform" + 0.101*"pub" + 0.100*"time"'),
(2,
'-0.408*"file" + -0.335*"output" + -0.216*"entri" + 0.171*"peopl" + 0.153*"know" + -0.137*"onam" + -0.134*"program" + 0.131*"said" + -0.129*"printf" + -0.115*"char"'),
(3,
'-0.249*"imag" + -0.226*"edu" + 0.214*"output" + 0.165*"peopl" + 0.157*"know" + 0.155*"entri" + 0.153*"said" + -0.153*"avail" + -0.142*"jpeg" + -0.124*"pub"'),
(4,
'0.549*"wire" + 0.223*"ground" + -0.214*"jpeg" + -0.213*"file" + -0.169*"imag" + 0.164*"circuit" + 0.157*"outlet" + 0.139*"connect" + 0.129*"subject" + 0.126*"neutral"'),
(5,
'-0.400*"jpeg" + -0.345*"imag" + 0.276*"anonym" + -0.246*"wire" + 0.160*"privaci" + 0.156*"internet" + -0.151*"color" + 0.144*"post" + 0.125*"inform" + 0.123*"mail"'),
(6,
'0.460*"file" + 0.215*"wire" + -0.169*"output" + -0.158*"program" + -0.154*"edu" + 0.144*"anonym" + 0.141*"firearm" + -0.137*"widget" + 0.123*"jpeg" + -0.120*"entri"'),
...
'''
LSI 모델에서 최적의 파라미터,
즉 최적의 토픽 개수를 선정하기 위해 Topic Coherence 를 확인합니다.
Topic Coherence?
Coherence 는 주제의 일관성을 측정합니다.
해당 토픽 모델이, 모델링이 잘 되어있을 수록 한 주제 안에는 의미론적으로 유사한 단어가 많이 모여있기 마련입니다.
따라서 상위 단어간의 유사도를 계산하면 실제로 해당 주제가 의미론적으로 일치하는 단어들끼리 모여있는지를 알 수 있습니다.
Topic Coherence 가 나타내는 의미는 다음과 같습니다:
- 토픽이 얼마나 의미론적으로 일관성 있는지를 나타냅니다.
- 해당 값이 높을 수록 의미론적 일관성이 높다고 해석할 수 있습니다.
- 해당 모델이 얼마나 실제로 의미있는 결과를 내는지 확인하기 위해 사용합니다.
(* 이 외에 Perplexity 도 고려할 수 있습니다.)
LDA 파라미터튜닝을 도전해보자 - 데이터테크 기업 코어닷 투데이의 기술 블로그입니다
LDA 파라미터를 튜닝해보자!
coredottoday.github.io
from gensim.models.coherencemodel import CoherenceModel
min_topics, max_topics = 20, 25
coherence_scores = []
for num_topics in range(min_topics, max_topics):
model = LsiModel(corpus, num_topics=num_topics, id2word=dictionary)
coherence = CoherenceModel(model=model, texts=news_texts, dictionary=dictionary)
coherence_scores.append(coherence.get_coherence())
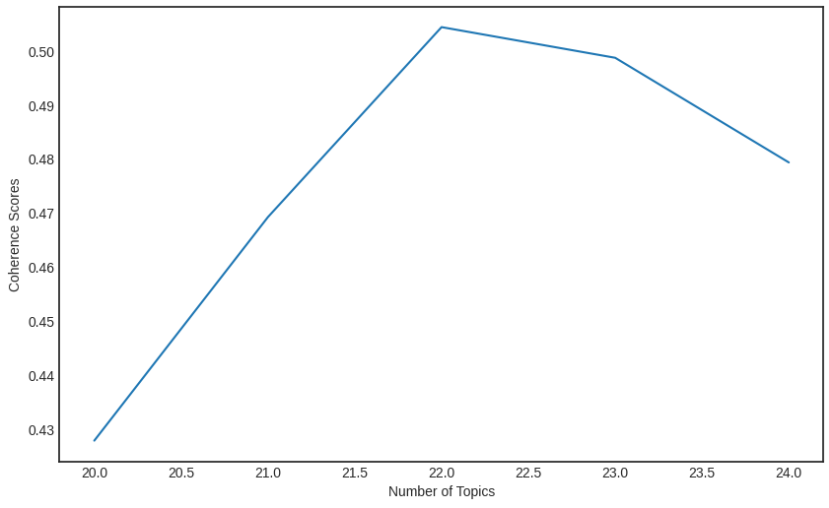
print(coherence_scores)
# output:
# [0.42781316312829015, 0.4692315755891694, 0.5044348575033509, 0.49875164809108913, 0.4793610918188969]
시각화를 위해 그래프로 그려봅니다.
import matplotlib.pyplot as plt
plt.style.use('seaborn-white')
x = [int(i) for i in range(min_topics, max_topics)]
plt.figure(figsize=(10, 6))
plt.plot(x, coherence_scores)
plt.xlabel('Number of Topics')
plt.ylabel('Coherence Scores')
plt.show()
결과
4.2 잠재 디리클레 할당을 위한 LdaModel
gensim의 LdaModel 을 불러와 토픽를 추출합니다.
from gensim.models import LdaModel
lad_model = LdaModel(corpus=corpus, num_topics=20, id2word=dictionary)
topics = lad_model.print_topics()
topics
# output:
'''
[(0,
'0.047*"imag" + 0.021*"disk" + 0.019*"jpeg" + 0.018*"drive" + 0.013*"format" + 0.009*"gif" + 0.008*"graphic" + 0.006*"pointer" + 0.006*"hard" + 0.006*"zionism"'),
(1,
'0.043*"game" + 0.013*"team" + 0.011*"plai" + 0.011*"score" + 0.009*"year" + 0.009*"church" + 0.008*"pitch" + 0.007*"detroit" + 0.006*"seri" + 0.005*"divis"'),
(2,
'0.020*"ground" + 0.015*"wire" + 0.008*"neutral" + 0.008*"kent" + 0.007*"greek" + 0.007*"outlet" + 0.007*"connect" + 0.006*"decenso" + 0.005*"panel" + 0.004*"citi"'),
(3,
'0.019*"health" + 0.015*"keyboard" + 0.013*"diseas" + 0.011*"medic" + 0.010*"infect" + 0.008*"pain" + 0.007*"patient" + 0.007*"caus" + 0.006*"doctor" + 0.006*"wire"'),
...
'''
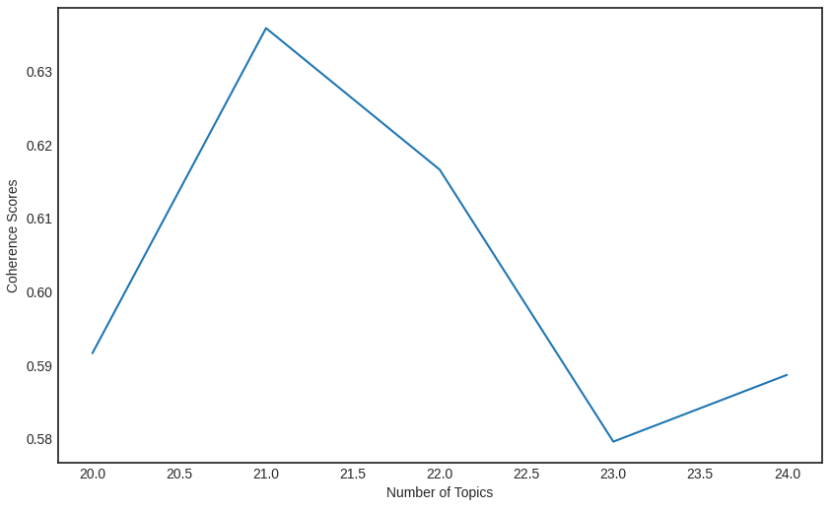
마찬가지로 coherence score 를 통해 최적의 토픽 개수를 찾습니다.
from gensim.models.coherencemodel import CoherenceModel
import matplotlib.pyplot as plt
min_topics, max_topics = 20, 25
coherence_scores = []
for num_topics in range(min_topics, max_topics):
model = LdaModel(corpus, num_topics=num_topics, id2word=dictionary, iterations=100, passes=10)
coherence = CoherenceModel(model=model, texts=news_texts, dictionary=dictionary)
coherence_scores.append(coherence.get_coherence())
plt.style.use('seaborn-white')
x = [int(i) for i in range(min_topics, max_topics)]
plt.figure(figsize=(10, 6))
plt.plot(x, coherence_scores)
plt.xlabel('Number of Topics')
plt.ylabel('Coherence Scores')
plt.show()
결과
5. 토픽 모델링 시각화
토픽 모델링 결과를 시각화하기 위해 pyLDAvis 를 다운받습니다.
!pip install pyLDAvis
그 후 시각화를 합니다.
import pyLDAvis.gensim
pyLDAvis.enable_notebook()
vis = pyLDAvis.gensim.prepare(lad_model, corpus, dictionary)
pyLDAvis.display(vis)
결과
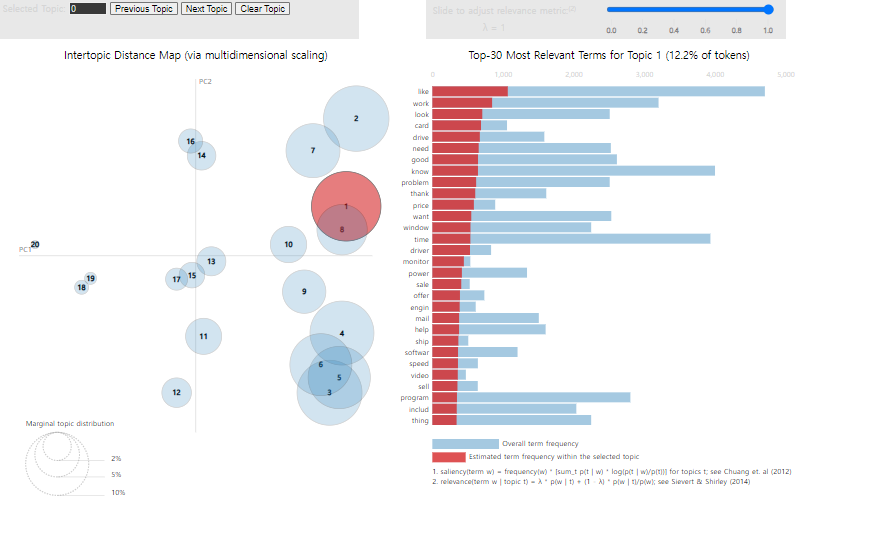
배움
Perplexity, Coherence
'[Deep daiv.] > [Deep daiv.] NLP' 카테고리의 다른 글
| [Deep daiv.] WIL, NLP - 6. 단어 임베딩 (1) | 2024.08.29 |
|---|---|
| [Deep daiv.] WIL, NLP - 7. Seq2seq with Attention (0) | 2024.08.29 |
| [Deep daiv.] WIL, NLP - 4. 의미 연결망 분석(Sematic Network Analysis) (0) | 2024.08.21 |
| [Deep daiv.] WIL, NLP - 3. 군집 분석 (0) | 2024.08.20 |
| [Deep daiv.] TIL & WIL - 5. 자연어 처리 & 텍스트 처리 (Contd.) (0) | 2024.08.14 |