
이전 글
2024.08.09 - [[Deep daiv.] NLP] - [Deep daiv.] NPL - 1. 텍스트 처리
[Deep daiv.] NPL - 1. 텍스트 처리
0. 텍스트 전처리 텍스트 전처리는 풀고자 하는 문제의 용도에 맞게 텍스트를 사전에 처리하는 작업입니다. 요리를 할 때 재료를 제대로 손질하지 않으면, 요리가 엉망이 되는 것처럼 텍스트에
hw-hk.tistory.com
1. 한국어 토큰화
한국어로 학습 데이터를 사용할 때는 언어의 특성으로 인해 추가로 고려해야 할 사항이 존재합니다.
한국어는 띄어쓰기를 준수하지 않아도 의미가 전달되는 경우가 많아 띄어쓰기가 지켜지지 않을 가능성이 존재합니다.
띄어쓰기가 지켜지지 않으면 정상적인 토큰의 분리가 이루어지지 않기 때문에, 한국어는 형태소라는 개념을 이용해 추가로 고려해주어야 합니다.
예를 들어, '그는', '그가' 등의 단어들은 같은 의미를 가리키지만 텍스트 처리에서는 다르게 받아들일 수 있어서 처리를 해줘야 합니다.
이를 위해 한국어 자연어 처리 라이브러리인 konlpy와 형태소 분석기 Mecab 이나 Okt 를 설치합니다.
# KoNLPy 설치
!pip install konlpy
# Okt 토크나이저 불러오기
from konlpy.tag import Okt
okt = Okt()
# 또는 Mecab 을 불러올 수 있습니다.
# Okt 에 비해 속도가 빠르고 정교하지만 따로 설치가 필요합니다.
!set -x \
&& curl -s https://raw.githubusercontent.com/konlpy/konlpy/master/scripts/mecab.sh | bash -x
1.1 단어 토큰화
한국어는 공백으로 단어를 분리해도 조사, 접속사 등이 남아 분석에 어려움이 있습니다.
따라서 이를 해결해줄 수 있는 한국어 토큰화는 조사, 접속사를 분리해주거나 제거합니다.
Okt 의 경우 기본적으로 okt.morphs() 를 사용합니다.
# Okt 토크나이저
text = '그날 밤, 나는 쉽게 잠을 이루지 못했다.'
tokens = okt.morphs(text)
print('Stemming 전 토큰:', tokens)
# Stemming 전 토큰: ['그날', '밤', ',', '나', '는', '쉽게', '잠', '을', '이루지', '못', '했다', '.']
# Stemming 후 토큰
stemmed_tokens = okt.morphs(text, stem = True)
print('Stemming 후 토큰:', stemmed_tokens)
Stemming 후 토큰: ['그날', '밤', ',', '나', '는', '쉬다', '잠', '을', '이루다', '못', '하다', '.']
명사 단어만 추출할 수도 있습니다.
# 명사 단어 추출하기
noun_tokens = okt.nouns(text)
print('명사 토큰:', noun_tokens)
# 명사 토큰: ['그날', '밤', '나', '잠']
정규표현식과 PoS 태깅도 가능합니다.
# 정규표현식을 활용한 텍스트 정제
import re
cleaned_text = re.sub('[^\w\s]', '', text) # \w: 단어, \s: 공백류의 단어들
print(cleaned_text)
# 그날 밤 나는 쉽게 잠을 이루지 못했다
# PoS 품사 태깅
pos_tokens = okt.pos(cleaned_text)
print('품사 태깅 토큰':, pos_tokens)
# 품사 태깅 토큰: [('그날', 'Noun'), ('밤', 'Noun'), ('나', 'Noun'),
# ('는', 'Josa'), ('쉽게', 'Verb'), ('잠', 'Noun'), ('을', 'Josa'),
# ('이루지', 'Verb'), ('못', 'VerbPrefix'), ('했다', 'Verb')]
2 Bag of Words
컴퓨터는 텍스트를 이해하지 못합니다. 컴퓨터가 텍스트를 이해할 수 있게 Embedding 을 해줘야 합니다.
즉, 인간이 이해하는 방식은 텍스트를 컴퓨터가 이해하는 방식인 숫자로 바꿔줘야 합니다.
임베딩(* Embedding) 은 텍스트 데이터 내의 단어나 문장과 같은 기호를 컴퓨터가 처리할 수 있는 숫자 형태인 벡터로 변환하는 것을 의미합니다.
예를 들어, 다음과 같은 텍스트가 주어졌을 때, 각 단어들은 다음과 같이 임베딩 될 수 있습니다.
text = '자연어 처리 분석이 정말 정말 재미있어요'
Embedding:
| 인덱스 | 0 | 1 | 2 | 3 | 4 | 5 |
| 텍스트 | 분석 | 이 | 자연어 | 재미있다 | 정말 | 처리 |
이때, 단어의 출현 빈도를 정리한 것을 Bag of Words, BoW 라고 합니다.
다시 말해, BoW 는 단어의 등장 순서를 무시하고, 단어의 개수를 카운트하는 방식입니다.
그러면, 위 예시를 BoW에 담는다면:
| 인덱스 | 0 | 1 | 2 | 3 | 4 | 5 |
| 텍스트 | 분석 | 이 | 자연어 | 재미있다 | 정말 | 처리 |
| 빈도 | 1 | 1 | 1 | 1 | 2 | 1 |
그렇다면 여러 문장들을 BoW에 담는다면:
# 문장 예제
sentences = ["자연어 처리 분석이 정말 정말 재미있어요.",
"저도 자연어 처리 분석이 재미있어요",
"저는 재미없어요. 집에 가고 싶어요.",
"저도 집 보내주세요."]
# 문서 내 단어 개수 카운트하기
from sklearn.feature_extraction.text import CountVectorizer # BoW
vectorizer = CountVectorizer(tokenizer = lambda x: okt.morphs(x, stem = True))
count_matrix = vectorizer.fit_transform(sentences); count_matrix.todense()
# 문서 내 단어 개수 카운트 결과 데이터프레임으로 출력
import pandas as pd
pd.DataFrame(count_matrix.todense(), columns = vectorizer.get_feature_names_out())
결과

하나의 row 는 하나의 문서에 해당하고,
하나의 문서를 하나의 벡터라고 생각한다면,
유사한 문서끼리는 유사한 벡터를 갖는다고 볼 수 있습니다.
3. TF-IDF
하지만, 이때 문제가 있습니다.
자주 사용되는 단어와 드물게 사용되는 단어가 같은 가중치를 갖는다는 것 입니다.
모든 문서를 통틀어서 적게 나오는 단어가 어느 한 문서에서만 집중적으로 나온다면,
그 단어는 그 문서를 대표하는 단어라고 볼 수 있습니다.
반대로,
모든 문서에서 동일한 비율로 나타나는 단어는 아무리 개수가 많다 하더라도,
그 단어의 중요도가 떨어진다 볼 수 있습니다.
즉, 모든 문서에서 자주 등장하는 단어의 영향력을 낮추는 것을 목표로 하는것이
TF-IDF(* Term Frequency - Inverse Document Frequency) 입니다.

위 예시에 대해 TF-IDF 를 계산한다면 다음과 같습니다.
# TF-IDF 벡터화
from sklearn.feature_extraction.text import TfidfVectorizer
stop_words = ['.'] # 분석에 방해가 된다고 판단해, 제거하고 싶은 토큰을 리스트에 추가합니다.
vectorizer = TfidfVectorizer(tokenizer = lambda x: okt.morphs(x, stem = True), min_df = 1,
stop_words = stop_words)
tfidf_matrix = vectorizer.fit_transform(sentences)
pd.DataFrame(tfidf_matrix.todense(), columns = vectorizer.get_feature_names_out())
결과

4. 코사인 유사도
코사인 유사도를 사용한다면 문서들 간의 유사도를 구할 수 있습니다.
코사인 유사도는 벡터의 방향성에 초점을 맞추고, 크기는 덜 중요시합니다.
특히, 텍스트 데이터 같이 크기보다는 요소 간의 관계가 중요한 분야에서 유용합니다.
또한 노름으로 나누어주기 때문에, 정규화하는 효과를 보입니다.
이는 벡터의 길이(예: 문서의 길이)가 다양할 때 특히 유용합니다.
따라서 위 예시를 코사인 유사도를 기반으로 하여 계산해보겠습니다.
from sklearn.metrics.pairwise import consine_similarity
cosine_ sim = cosine_similarity(tfidf_matrix)
import seaborn as sns
# 코사인 유사도 행렬을 히트맵으로 시각화
plt.figure(figsize=(8, 6),dpi = 300)
sns.heatmap(cosine_sim, annot=True, cmap='Blues', cbar_kws={'label': 'Cosine Similarity'})
plt.title('Cosine Similarity Heatmap')
plt.xlabel('Document Index')
plt.ylabel('Document Index')
plt.show()
결과

5. 실전
파리 올림픽 뉴스 데이터를 이용하여 유사 기사를 코사인 유사도를 기반으로 뽑아 보는 과제를 해보겠습니다.
import pandas as pd
import os
file_path = '/content/drive/MyDrive/Colab Notebooks/'
file_name = '최종_파리올림픽_네이버_뉴스_20240715_20240812.csv'
df = pd.read_csv(os.path.join(file_path, file_name))
다음과 같이 파리 올림픽 관련 기사 데이터를 DataFrame 으로 가져옵니다.
그 후, 텍스트를 깔끔하게 전처리해줍니다.
df['title_processed'] = df['title'].map(lambda text: re.sub('[^\w\s]', '', text)
각 문서들을 단어를 기반으로 벡터화 하는데
그냥 빈도수가 아닌 TF-IDF 를 이용해서 진행해줍니다.
이를 통해, 단어들의 중요도까지 고려해줍니다.
# TF-IDF 벡터화
vectorizer = TfidfVectorizer(tokenizer = lambda x: okt.morphs(x, stem = True), min_df = 10)
tfidf_matrix = vectorizer.fit_transform(df['title_processed'])
# TF-IDF 행렬 생성
X_tfidf = pd.DataFrame(tfidf_matrix.todense(), columns = vectorizer.get_feature_names_out())
X_tfidf
결과

이후 각 행벡터에 대해 코사인 유사도를 구해줍니다.
# 코사인 유사도 계산
from sklearn.metrics.pairwise import cosine_similarity
cosine_sim = cosine_similarity(tfidf_matrix)
cosine_sim
결과
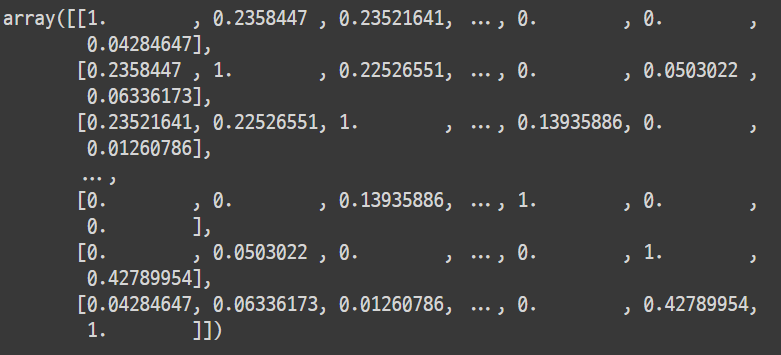
이를 이용해서 각 문서별로 가장 유사한 5개의 문서 인덱스를 가지고 올 수 있습니다.
# 각 문서별로 가장 유사한 5개의 문서 인덱스 가지고 오기
top_indices = {}
for i in len(cosine_sim):
sim_scores = list(enumerate(cosine_sim[i]) # 인덱스를 만들어 주는 enumerate()
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True) # 유사도가 높은 순으로 내림차순
sim_scores = [sim for sim in sum_scores if sim[0] != i] # 자기 자신은 항상 1이므로 제외
top_indices[i] = [sim[0] for sim in sim_scores[:5]] # Top 5 인덱스
results = {}
for idx, indices in top_indices.items():
results[df['title'][idx]] = [df['title'][i] for i in indices]
# 5개의 랜덤 인덱스 생성
random_indices = np.random.randint(len(results), size = 5)
# 결과 출력
for i in random_indices:
title_sample = df['title'][i]
similar_articles = results[title_sample]
print(f'{i} 제목: {title_sample}')
print('-' * 50)
print('\n'.join(similar_articles))
print('=' * 50) # 각 결과 사이에 구분선 추가
결과

추가
각 기사들에 종목을 정답 레이블로 해서 지도 학습을 시킬 수도 있다...
이때 만약 Logistic Regression 을 통해 분류 모델을 만들었다면,
계수 분석을 통해 어떤 기사가 어떤 종목으로 생각하는 이유를 알아낼 수도 있다.
배움
문서의 벡터화
코사인 유사도
지도 학습
'[Deep daiv.] > [Deep daiv.] NLP' 카테고리의 다른 글
| [Deep daiv.] WIL, NLP - 7. Seq2seq with Attention (0) | 2024.08.29 |
|---|---|
| [Deep daiv.] WIL, NLP - 5. 토픽 모델링 (0) | 2024.08.22 |
| [Deep daiv.] WIL, NLP - 4. 의미 연결망 분석(Sematic Network Analysis) (0) | 2024.08.21 |
| [Deep daiv.] WIL, NLP - 3. 군집 분석 (0) | 2024.08.20 |
| [Deep daiv.] WIL, NLP - 1. 텍스트 처리 (0) | 2024.08.09 |