
1. 군집 분석
군집 분석은 데이터의 특성에 따라 유사한 것끼리 묶어 분석하는 것을 의미합니다.
다시 말해, 유사성을 기반으로 군집을 분류하고, 군집에 따라 유형별 특징을 분석하는 기법입니다.
텍스트에 대한 군집 분석에서는 군집으로 묶여진 텍스트끼리는 최대한 유사하고, 다른 군집으로 묶여진 텍스트들과는 최대한 유사하지 않도록 분류하는 것이 핵심입니다.
2. 유사?
텍스트 유사도를 계산하는 방식에는 여러 가지 방법이 있지만,
지금은 자카드 유사도와 코사인 유사도를 사용하겠습니다.
- 자카드 유사도(* Jaccard Similarity): 두 텍스트 문서 사이에 공통된 용어의 수와 해당 텍스트에 존재하는 총 고유 용어 수의 비율을 사용하는 유사도입니다.
https://heytech.tistory.com/358
[NLP] 문서 유사도 분석: (3) 자카드 유사도(Jaccard Similarity)
📚 목차 1. 자카드 유사도 개념 2. 자카드 유사고 실습 1. 자카드 유사도 개념 자카드 유사도(Jaccard Similarity)는 \(2\)개의 집합 \(A\), \(B\)가 있을 때 두 집합의 합집합 중 교집합의 비율입니다. 즉,
heytech.tistory.com
- 코사인 유사도(* Cosine Similarity): 벡터 표현 사이의 각도에 대한 코사인 값을 사용합니다. BoW 와 TF-IDF 행렬은 텍스트에 대한 벡터 표현으로 사용할 수 있습니다.
2.0 기본 설정
import nltk
nltk.download('punkt')
nltk.download('wordnet')
from nltk import word_tokenize
from nltk.stem import WordNetLemmatizer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
2.1 자카드 유사도
자카드 유사도를 기반으로 문서들의 유사도를 비교해보겠습니다.
def jaccard_similarity(d1, d2):
lemmatizer = WordNetLemmatizer()
words1 = [lemmatizer.lemmatize(word.lower()) for word in word_tokenize(d1)]
words2 = [lemmatizer.lemmatize(word.lower()) for word in word_tokenize(d2)]
inter = len(set(words1).intersection(set(words2)))
union = len(set(words1).union(set(words2)))
return inter / union
d1 = "Think like a man of action and act like man of thought"
d2 = "Try not to become a man of success but rather try to become a man of value"
d3 = "Give me liberty, of give me death"
print(jaccard_similarity(d1, d2))
print(jaccard_similarity(d1, d3))
print(jaccard_similarity(d2, d3))
# 0.17647058823529413
# 0.07142857142857142
# 0.0625
2.2 코사인 유사도
코사인 유사도를 통해서도 구해봅니다.
import numpy as np
tiv = TfidfVectorizer()
corpus = [d1, d2, d3]
tfidf = tiv.fit_transform(corpus).todense()
print(cosine_similarity(np.asarray(tfidf[0]), np.asarray(tfidf[1])))
print(cosine_similarity(np.asarray(tfidf[0]), np.asarray(tfidf[2])))
print(cosine_similarity(np.asarray(tfidf[1]), np.asarray(tfidf[2])))
# [[0.22861951]]
# [[0.06083323]]
# [[0.04765587]]
3. 데이터 전처리
데이터 전처리를 위해 konlpy 와 Mecab 을 설치해줍니다.
그리고 네이버 영화 리뷰 데이터를 받아와 전처리를 해줍니다.
from konlpy.tag import Mecab
import urllib.request
# 리뷰 데이터를 가져옵니다.
raw = urllib.request.urlopen('https://raw.githubusercontent.com/e9t/nsmc/master/ratings.txt').readlines()
# 리뷰 데이터를 10000개만 가져옵니다.
raw = [x.decode() for x in raw[1:10000]]
reviews = []
for i in raw:
reviews.append(i.split('\t')[1])
네이버 리뷰 데이터를 Mecab 을 통해 토큰화해줍니다.
tagger = Mecab()
reviews = [tagger.morphs(x) for x in reviews]
print(reviews)
# output
# [['어릴', '때', '보', '고', '지금', '다시', '봐도', '재밌', '어요', 'ㅋㅋ'], ['디자인', '을 ...
3.1 Word2Vec 생성
Word2Vec 생성에 필요한 라이브러리들을 추가합니다.
from gensim.models import Word2Vec
Word2Vec 모델을 생성합니다.
word2vec = Word2Vec(reviews, min_count = 5)
# W2V 의 wv.most_similar 메소드를 통해 가장 유사한 단어를 찾을 수 있습니다.
word2vec.wv.most_similar('영화')
# output:
'''
[('작품', 0.9124408960342407),
('듯', 0.9059200882911682),
('표현', 0.8819276690483093),
('마음', 0.8794344663619995),
('멜로', 0.8791808485984802),
('드라마', 0.8786312341690063),
('잔잔', 0.8784134984016418),
('내', 0.8774775862693787),
('이야기', 0.8766973614692688),
('따뜻', 0.8760198354721069)]
'''
3.2 t-SNE 를 통해 단어 벡터 시각화
벡터의 시각화를 위해 t-SNE 를 import 해줍니다.
또한, matplotlib 의 한글 폰트 적용을 위해 여러가지 모듈을 import 해줍니다.
from sklearn.manifold import TSNE
from matplotlib import font_manager as fm
from matplotlib import rc
Word2Vec 으로 만들어진 단어 벡터들의 차원은 굉장히 큰데,
이를 시각화 시키기 위해 2차원으로 축소 시켜줍니다.
# W2V 의 모든 단어들을 벡터화
vocab = word2vec.wv.index_to_key
similarity = word2vec.wv[vocab]
# 차원 축소
transform_similarity = tsne.fit_transform(similarity)
# DataFrame 으로 변환
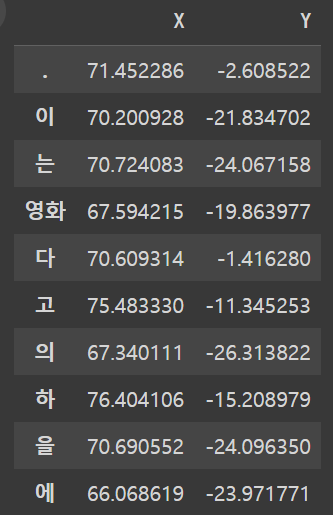
df = pd.DataFrame(transform_similarity, index = vocab, columns = ['X', 'Y'])
df[:10]
결과
그 후 시각화 합니다.
import seaborn as sns
import matplotlib.pyplot as plt
plt.style.use('seaborn-white')
sns.lmplot(x='X', y='Y', data=df, fit_reg=False)
plt.show()
결과

4. 군집화
4.1 Scikit-learn, Scipy 를 통한 계층적 군집화
계층적 군집화란 개별 개체들을 유사한 개체나 그룹과 통합해 군집화를 수행하는 알고리즘입니다. 비계층적 군집화와는 달리 군집 수를 지정하지 않아도 군집화를 할 수 있다는 것이 장점입니다.
계층적 군집화는 모든 개체간 거리나 유사도가 미리 계산되어 있어야만 하며, 계산복잡도도 비계층적 군집화보다 큽니다.
4.1.1 Scipy 를 통한 거리 계산
Scipy의 pdist 를 통해 미리 개체간의 거리를 계산합니다.
from scipy.spatial.distance import pdist, squareform # pdist: 거리 계산, squareform: 루트
from scipy.cluster.hierarchy import linkage, dendrogram # linkage: dendrogram 을 위함
distmatrix = pdist(df, metric='euclidean')
row_dist = pd.DataFrame(squareform(distmatrix))
row_dist
결과

이를 이용하여 덴드로그램을 그려줍니다.
row_clusters = linkage(distmatrix, method='complete') # 클러스터링은 최대 거리가 최소가 되는 것을 기준으로 한다.
plt.figure(figsize=(20,10))
dendrogram(row_clusters, leaf_rotation=50, leaf_font_size=3) # 잎 노드를 50도 회전, 사이즈는 3으로
plt.show()
결과

4.2 비계층적 군집화
Scikit-learn 에서는 비계층적 군집화의 일종인 agglomerativeClustering(* 병합 군집)을 이용하여 계층적 군집화를 수행해볼 수 있습니다.
(* 비계층적 군집화 다른 예시들)
2024.08.09 - [[Deep daiv.] 복습] - [Deep daiv.] TIL - 3.1 차원축소와 클러스터링
[Deep daiv.] TIL - 3.1 차원축소와 클러스터링
1. PCA 주성분 분석 고차원의 데이터를 낮은 차원의 데이터로 바꿀 때, 어떻게 바꿔야 최대한 특징을 살리면서 차원을 낮출 수 있을까를 고안하다가 나온것이 PCA 입니다. 그렇다면 어떻게 해야 '
hw-hk.tistory.com
병합 군집은 각 개체들을 클러스터로 간주, 종료 조건을 만족할 때 까지 가장 비슷한 두 클러스터들을 합치며 진행합니다.
병합 군집의 종료 조건에는 3가지를 지정할 수 있습니다:
- ward: 모든 클러스터 내의 분산을 가장 적게 증가시키는 두 클러스터를 합침(* 기본값)
- average: 클러스터간 평균 거리가 가장 짧은 두 클러스터를 합침
- complete: 클러스터간 최대 거리가 가장 짧은 두 클러스터를 합침
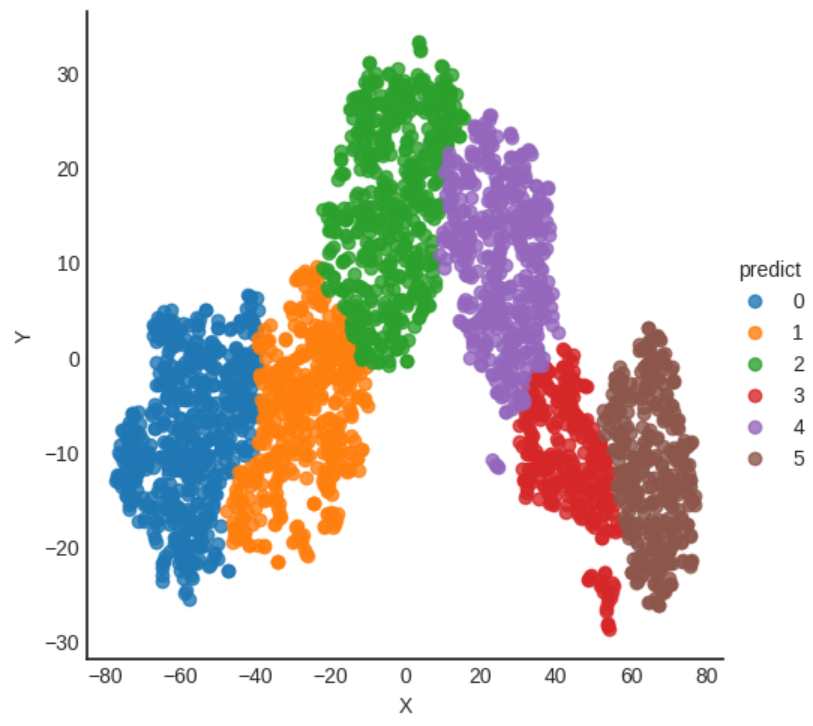
4.2.1 ward 를 통한 비계층적 군집화
from sklearn.cluster import AgglomerativeClustering
ward = AgglomerativeClustering(n_clusters=6, linkage='ward')
predict = ward.fit_predict(df)
result = df.copy()
result['predict'] = predict
sns.lmplot(x='X', y='Y', data=result, fit_reg=False, hue='predict')
plt.show()
결과

4.2.2 average 를 통한 비계층적 군집화
from sklearn.cluster import AgglomerativeClustering
avg = AgglomerativeClustering(n_clusters=6, linkage='average')
predict = avg.fit_predict(df)
result = df.copy()
result['predict'] = predict
sns.lmplot(x='X', y='Y', data=result, fit_reg=False, hue='predict')
plt.show()
결과

4.2.3 complete 를 통한 비계층적 군집화
from sklearn.cluster import AgglomerativeClustering
compl = AgglomerativeClustering(n_clusters=6, linkage='complete')
predict = compl.fit_predict(df)
result = df.copy()
result['predict'] = predict
sns.lmplot(x='X', y='Y', data=result, fit_reg=False, hue='predict')
plt.show()
결과
배움
클러스터링의 여러가지 방법
계층적 클러스터링의 방법(Scipy의 pdist 와 linkage, ward, complete, average 등...)
차원축소와 시각화
'[Deep daiv.] > [Deep daiv.] NLP' 카테고리의 다른 글
| [Deep daiv.] WIL, NLP - 7. Seq2seq with Attention (0) | 2024.08.29 |
|---|---|
| [Deep daiv.] WIL, NLP - 5. 토픽 모델링 (0) | 2024.08.22 |
| [Deep daiv.] WIL, NLP - 4. 의미 연결망 분석(Sematic Network Analysis) (0) | 2024.08.21 |
| [Deep daiv.] TIL & WIL - 5. 자연어 처리 & 텍스트 처리 (Contd.) (0) | 2024.08.14 |
| [Deep daiv.] WIL, NLP - 1. 텍스트 처리 (0) | 2024.08.09 |