
https://chloamme.github.io/2021/12/08/illustrated-gpt2-korean.html#h-%EC%9E%85%EB%A0%A5-encoding
[번역] 그림으로 설명하는 GPT-2 (Transformer Language Model 시각화)
이 글은 Jay Alammar님의 글을 번역한 글입니다. [추가정보] This post is a translated version of The Illustrated GPT-2 (Visualizing Transformer Language Models) by Jay Alammar.
chloamme.github.io
을 기반으로 설명한 글입니다.
0. Word Embedding
머신 러닝 모델들이 단어를 처리하고 계산에 이용하기 위해서는, 이 단어들을 숫자로 표현(* numeric representation)을 해야만 합니다.
Word2Vec은 벡터를 이용하면 제대로 단어의 의미와 의미와 관련된 관계(* 예를들어, 단어들이 비슷한지 혹은 반대인지, 혹은 "Stockholm"과 "Sweden"이 "Cairo"와 "Egypt"와 동일한 관계를 가지는지)
그리고 문법과 문법과 관견된 관계(* 예를들어 "had"와 "has"가 가지는 관계와 "was"와 "is"가 가지는 관계가 같은지) 를 나타낼 수 있음을 보였습니다.
2024.08.16 - [[Deep daiv.]/[Deep daiv.] 복습] - [Deep daiv.] TIL - 6. Word2Vec을 활용한 단어 임베딩
[Deep daiv.] TIL - 6. Word2Vec을 활용한 단어 임베딩
0. 현재 상황 2024.08.14 - [[Deep daiv.] 복습] - [Deep daiv.] TIL & WIL - 5. 자연어 처리 & 텍스트 처리 (Contd.) [Deep daiv.] TIL & WIL - 5. 자연어 처리 & 텍스트 처리 (Contd.)이전 글2024.08.09 - [[Deep daiv.] NLP] - [Deep daiv.
hw-hk.tistory.com
사람들은 매우 빠른 모델이 이용하는 작은 데이터셋에서 처음부터 학습시키는 것보다 아주 많은 양의 텍스트 데이터에서 pre-trained된 embedding을 이용하는것이 좋다는 것을 알아냈습니다.(* 작은 데이터셋에서 embedding을 학습시키는것은 부정확할 수 있습니다.)
그래서 이제 이러한 Word2Vec혹은 GloVe와 같은 알고리즘들을 이용해 pre-trained된 단어들의 embedding을 다운받는게 가능해졌습니다.
아래는 "stick"이라는 단어의 GloVe embedding의 예제입니다:

1. ELMo
만약 우리가 GloVe representation을 이용한다면, 이 "stick"이라는 단어는 그 어떤 맥락(* context)에서도 같은 벡터로 나타내질 것입니다.(* "stick"이라는 단어는 어떻게 이용되냐에 따라 여러 의미를 가질 수 있습니다. 한국어로 생각한다면 "눈"이라는 단어는 감각기관으로서의 "눈"과 하늘에서 내리는 "눈"이라는 여러 의미를 가질 수 있습니다. 하지만 GloVe를 사용한다면 두 의미를 가지는 "눈"이라는 단어는 하나의 벡터로 표현될 것입니다.)
그러지 말고 어떤 맥락에 있는지에 따라 다른 embedding을 이용하는게 어떨까? 라는 생각에서 탄생한것이 contextualized word-embedding입니다.

contextualized word-embedding은 각 단어에게 문장의 맥락 속에서 어떠한 의미를 가지는지에 따라 다른 embedding을 가지게 할 수 있습니다.(* 아래의 예시에서 볼 수 있듯, GloVe에서의 "play"는 스포츠와 관련된 이웃들이 있는 반면, ELMo는 "play"에 대해 문맥에 따라 다른 의미로 embedding하는 모습을 볼 수 있습니다.)

Word2Vec이나 GloVe처럼 각 단어에 고정된 embedding을 대신에, ELMo는 먼제 전체 문장을 봅니다. 그리고 특정한 task로 학습된 bi-directional LSTM을 이용하여 각 단어의 embedding을 생성합니다.

ELMo가 이용하는 LSTM은 거대한 데이터 셋에서 학습되며, 그 다음 자연어를 처리하는 다른 모델에서 하나의 부분으로 이용할 수 있습니다.
ELMo는 단어의 sequence에서 다음 단어를 예측하는 task인 Language Modeling에서 언어에 대한 이해를 습득합니다. 이 Task가 좋은 이유는 다음 단어를 label로 쓰기 때문에 사람의 도움없이 세상에 있는 엄청난 양의 모든 텍스트 데이터를 학습 데이터로 이용할 수 있다는 점입니다.

ELMo의 입력으로 "Let's stick to"가 주어졌을 때, 그 다음으로 올 확률이 가장 높은 단어를 예측하는 task가 바로 Language Modeling task입니다. 큰 데이터 셋에 학습되었을 때, 모델은 문장들에서 언어의 패턴을 학습합니다.
또한 ELMo에는 bi-directional LSTM을 사용한다는 특징이 있습니다. uni-direction이 아닌 bi-direction을 모두 봄으로써 이제 Language Model은 단순히 다음 단어에 대해서만 추측을 하는 것이 아니라, 그 전 단어에 대해서도 이해할 수 있습니다.

마지막으로, ELMo는 앞에서 보앗던 hidden states들을 하나의 벡터로 합쳐서 contextualized embedding이라고 부릅니다. 합치는 방법으로 논문에서는 hidden states들을 concatenate를 한 후 weighted sum을 구하는 방식을 제안했습니다.

이때, LSTM의 높은 level의 word embedding은 일반적으로 context-dependent적인 측면을 갖고, 낮은 level의 word embedding은 구문의 측면을 갖습니다. 이에 따라서 각 layer의 가중치를 설정합니다.
아래는 ELMo의 성능 향상을 위한 조건입니다:

각 레이어에 대한 가중치가 클 수록 색이 진하게 표현됩니다. context가 반영되지 않은 embedding 방식을 사용하면 가장 성능이 좋지 않고, 높은 layer일 수록 가중치를 높이는 방식으로 설정하면 성능이 가장 좋습니다.

입력과 출력 모두 ELMo를 concat하지 않으면 성능이 가장 좋지 않고, 입력과 출력 모두 ELMo를 concat하면 성능이 가장 좋습니다.
2. GPT
라벨링 된 데이터에 비해 라벨링 되지 않은 데이터의 수가 압도적으로 많습니다. 많은 양의 라벨링 되지 않은 데이터를 사용해서 언어모델을 만든것이 바로 GPT입니다.
하지만 비지도 학습, 즉 라벨링 되지 않은 데이터를 이용하여 단어 단위의 정보를 이끌어 내는것은 여러모로 어렵습니다. 그렇기 때문에 GPT가 선택한 방법이 바로 Language Model입니다.
2.1 Language Model
기본적으로는 문장의 일부롤 보고 다음 단어를 예측하는 것을 할 수 있는 머신 러닝 모델을 말합니다. 가장 유명한 Language Model로는 현재까지 입력된 것을 보고 다음 단어를 제안하는 스마트폰 키보드가 있습니다.
GPT는 이런 점에서는 비슷하다 볼 수 있지만, GPT는 훨씬 크고 복잡합니다.
최초의 트랜스포머 모델은 encoder와 decoder로 구성되어 있습니다. 하지만 GPT는 트랜스포머의 decoder 블럭만을 상용합니다. 이를 통해 GPT는 전통적인 Language Model들 처럼 한번에 하나의 token을 출력합니다.

이러한 모델들은 각 token이 생성된 후에 입력 시퀀스에 더해지는 방식으로 동작합니다. 그러한 새 시퀀스는 다음 단계에서 모델의 입력으로 들어갑니다. 이 것을 "auto-regression"이라고 부릅니다. 이 것은 RNN을 엄청나게 효과적으로 만든 방법 중 하나입니다.
2.2 모델
훈련된 GPT모델을 돌려보는 가장 간단한 방법은 그 것 자체의 램블링(* ramdling; 패턴없이 되는 대로 퍼져나가는)을 하도록 만드는 것입니다.(* 기술적 용어로, generating unconditional samples)

모델은 input token 하나를 가지고 있으므로, 한 번만 모든 레이버를 통과합니다. 이를 통해 vector가 만들어지고, 그 vector에 모델의 어휘 전체에 대해 점수가 매겨지면, 가장 높은 확률을 갖는 단어인 'the'를 획득할 수 있습니다.
하지만 이때, 선택에 변화를 줄 수 있습니다.
예를 들어 키보드 앱에서 제안하는 단어를 계속 클릭하면, 가끔 반복 루프에 빠질 수 있습니다. 이때 이를 해결하는 방법으로 두 번째나 세 번째로 제안한 단어를 선택하는 것입니다.
동일한 상황이 여기에도 벌어집니다. GPT-2는 top-k라는 parameter를 가지고 있어서 우리는 모델이 top단어가 아닌 다른 단어를 sampling하게 만들 수 있습니다.
다음 단계에서, 첫 번째 단계의 출력을 입력 시퀀스에 덧붙인 뒤 모델이 다음 예측을 수행합니다:

2.3 입력 Encoding
이전에 봤던 NLP모델들처럼, GPT모델도 embedding matrix에서 입력 단어의 embedding을 조회합니다.

각 행은 단어 embedding입니다. 단어를 표현하고 그 의미를 함유하는 숫자 형태의 표현 리스트입니다. 이 리스트의 크기는 GPT모델 사이즈에 따라 다릅니다. 제일 작은 모델은 단어당 768 embedding 크기를 갖습니다.
처음 시작할 때, embedding matrix에서 시작 토큰 <s>의 embedding을 조회합니다. 모든 모델의 첫번째 block에 이 정보를 전달하기 전에, positional encoding 정보를 통합해야만 합니다. 이는 transformer block에서 시퀀스 상에서의 word들의 순서 정보를 알려주는 신호(정보)입니다. 훈련된 모델을 구성하는 다른 한 부분은 입력의 1024개 위치 각각에 대한 positional encoding vector입니다.
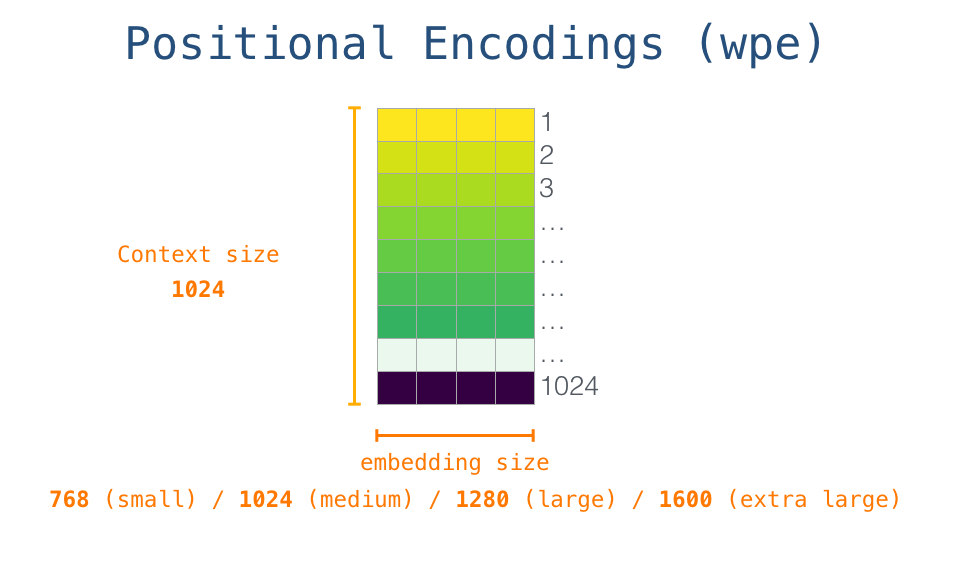
이 과정을 한 번에 나타내면 다음과 같습니다:

상위 Stack으로 이동
이제 첫번째 block은 token을 self-attention 프로세스를 통해 전달하고, neural network 레이어로 전달하여 처리합니다. 첫번째 transformer block이 이 token을 처리하면, 그 결과 vector를 다음 block에서 처리하도록 윗쪽 stack으로 올립니다. 프로세스는 각 block마다 동일하지만 각 block은 각자의 self-attention 및 NN 하위 레이어에 대한 weight들을 가지고 있습니다.

Self-attention Recap
언어는 context에 매우 의존적입니다. 예를들어, 로봇의 제 2원칙을 봅시다:
A robot must obey the orders given it by human beings except where such orders would conflict with the First Law.
문장에서 다른 단어를 참조하는 단어들 3군데를 강조표기 했습니다. 이 단어들은 참조하는 context와 통합적으로 보지 않으면 이해 또는 처리할 수 없습니다. 모델이 이 문장을 처리할 때, 다음을 알 수 있어야 합니다.
- 그것은 로봇을 가르킵니다.
- 그러한 명령들은 이 법칙의 앞부분의 "인간이 그것에 내리는 명령들"을 가르킵니다.
- 제 1원칙은 제 1원칙의 전체를 가르킵니다.
이것이 self-attention이 하는 일입니다. 단어들을 처리하기 전에, 특정 단어의 context를 설명하는 관련 word들에 대한 모델의 이해를 만듭니다. segment에서 각 word가 얼마나 관련되어 있는지 score를 할당하고, 그 vector representation을 합산하는 방식으로 이를 수행합니다.

Self-attention process
Self-attention은 segment에서 각 token의 경로를 따라 처리됩니다. 중요한 요소들은 다음 세가지의 vector들 입니다:
- Query: Query는 다른 모든 word들과 score를 계산(각 단어마다 고유 key값 사용)하는데 사용되는 현재 단어(word)의 representation 입니다. 우리는 현재 처리 중인 token의 query 값만 고려합니다.
- Key: Key vector는 segment에서 모든 word들에 대한 레이블과 같습니다. 관련 word를 검색할 때 매칭해보는 항목입니다.
- Value: Value vector는 실제 word representation 입니다. 각 단어가 얼마나 관련이 있는지 score를 매기고 나면, 현재의 word를 표현(representation)하기 위한 합산(add up)한 값입니다.

대략적으로 비유해보자면, 서류 캐비넷에서 어떤 서류를 찾는 것과 같다고 생각할 수 있습니다. Query는 찾고자 하는 주제를 적은 메모지 입니다. Key는 캐비넷 안의 서류 폴더들에 달린 레이블과 같습니다. 메모지와 tag(레이블)를 매칭시키면, 폴더에서 내용물을 꺼내는데, 이 내용물이 바로 value vector입니다. 단지 다른 점은, 하나의 value만 찾는 것이 아니라, 여러 폴더들에서 여러 value들의 혼합을 찾는다는 것입니다.
Query vector를 각 key vector에 곱해서, 각 폴더 별 score값을 만듭니다. 기술적으로는 내적을 통해 연산한 뒤 softmax 연산을 통해 계산합니다.


이 가중치 혼합된 value vector는 50%는 단어 robot에, 30%는 a에, 19%는 it에 attention을 준 vector를 생성합니다. 이 글의 뒷부분에서 self-attention에 대해 더 자세히 알아보겠습니다. 지금은 모델의 출력 방향으로 윗쪽 stack을 계속 알아봅시다.
모델 출력
모델의 최상위 block이 output vector를 생성할 때, 모델은 그 vector와 embedding matrix를 곱합니다.

embedding matrix의 각 행은 모델 어휘단어들의 embedding에 해당합니다. 이 곱셈의 결과는 모델의 어휘에서 각 word에 대한 score로 해석됩니다. 즉, 단어를 선택하기 위한 score로 사용할 수 있습니다.

가장 높은 score를 갖는 token을 선택할 수도 있습니다 (top_k=1). 하지만, 모델이 다른 word들도 고려한다면 더 좋은 결과를 얻을 수 있습니다. 더 좋은 전략은 전체 리스트에서 score를 어떤 word를 고르기 위한 확률값으로 사용하여 단어를 선택하는 것입니다. 따라서 절충안은 top_k를 40으로 잡고 모델이 가장 높은 score를 갖는 40개의 word를 고려하도록 하는 것입니다.

그렇게 해서, 모델은 하나의 word를 출력하면서 한 iteration을 종료합니다. 모델은 전체 컨텍스트가 생성될 때까지 혹은 EOS token이 생성될 때까지 iteration을 계속 수행합니다.
'[Deep daiv.] > [Deep daiv.] NLP' 카테고리의 다른 글
| [Deep Daiv.] NLP, 논문 리뷰 - Bahdanau Attention (1) | 2024.11.17 |
|---|---|
| [Deep daiv.] NLP, WIL - 9. ELMo and GPT (2) (0) | 2024.11.13 |
| [Deep daiv.] NLP, WIL - 7.1 Seq2seq 실습 (1) | 2024.09.06 |
| [Deep daiv.] WIL, NLP - 8. 순환 신경망 실습 (6) | 2024.09.02 |
| [Deep daiv.] WIL, NLP - 6. 단어 임베딩 (1) | 2024.08.29 |