
https://arxiv.org/abs/1409.0473
Neural Machine Translation by Jointly Learning to Align and Translate
Neural machine translation is a recently proposed approach to machine translation. Unlike the traditional statistical machine translation, the neural machine translation aims at building a single neural network that can be jointly tuned to maximize the tra
arxiv.org
Abstract.
기존의 통계적인 기계 번역기와 달리, 신경망 번역기는 하나의 신경망을 번역기의 성능이 좋아지는 방향으로 어떻게 조절할까에 집중합니다. 최근에 제시된 번역기 (Seqence to Seqence)는 encoder-decoder구조로서 encoder에서 원문 문장을 고정된 길이의 vector로 변형하여, decoder에 보내 번역을 만들어가는 방법입니다.
2024.08.29 - [[Deep daiv.]/[Deep daiv.] NLP] - [Deep daiv.] WIL, NLP - 7. Seq2seq with Attention
[Deep daiv.] WIL, NLP - 7. Seq2seq with Attention
0. 시작하기 전 https://nlpinkorean.github.io/visualizing-neural-machine-translation-mechanics-of-seq2seq-models-with-attention/ Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)최근 10년 동안의 자연
hw-hk.tistory.com
이 논문에서는 이런 고정 길이 vector를 사용하는 것이 성능 향상의 병목이라고 판단합니다. 그래서 target word을 예측하는데 가장 합리적인 source sentence의 부분들을 잘 찾기위한 모델을 적용함으로써 이를 해결할 수 있다고 봅니다. 이때는 Attention이라는 말이 없었지만, target word를 생성하기 위해 source sentence의 한 부분을 attend한다는 점에서 attention이라고 추후에 이름붙게 됩니다.
기존에 사용했던 엄격한 (원문에서는 hard-alignment)방법 대신 유연한 (원문에서는 soft-alignment)방법을 사용해서 English-to-French번역의 SOTA를 달성했다고 합니다.
Introduction.
앞서 말했듯이, 기존에 사용중이었던 encoder-decoder기반의 모델은 입력 문장을 고정된 길이의 vector로 표현합니다. decoder는 그 vector, encoder의 output을 통해 문장을 번역, 생성해 나갑니다. 여기서 생각할만한 잠재적인 문제는 신경망은 입력, 원본문장으로부터 얻을 수 있는 정보들을 고정된 길이의 vector로 압축해야한다는 것입니다.
이는 입력문장의 길이가 길면 길수록 더욱 힘듭니다. 예를 들어 책의 양이 1000장인 책이랑, 100장인 책이랑 모두 A4용지 한 장에 정리하라고 한다면, 당연히 1000장 책이 더 힘들것입니다. 그렇기 때문에 기존 모델은 입력 문장의 길이가 길어질수록 성능이 급격히 줄어든다는 문제가 있었습니다.
이런 문제를 해결하기 위해서 이 논문에서는 할당과 번역이 동시에 이루어지는 방법을 제안합니다. 그래서 논문의 이름이 Neural machine translation by jointly learning to align and translate인 것입니다. 모델이 한 단어씩 번역해나갈 때마다, decoder는 source sentence의 가장 집중해야하는 부분으로부터 target word를 할당받습니다. 그러면 모델은 그 할당받은 context vector와 이전에 생성되었던 단어들을 통해 다음 문장을 예측하는 것입니다.
기존의 방법과 가장 뚜렷이 구별되는 점은 제시된 모델은 모든 입력 문장을 고정된 길이의 vector로 압축시키려하지 않고, vector의 sequence로 입력 문장을 인코딩합니다. 그리고 decoding단계에서 그 vector의 sequence, 즉 matrix의 적절한 부분을 이용해 다음 문장을 예측합니다. 이는 신경망이 정보들을 고정된 길이의 vector로 뭉개지 않음으로써 긴 문장에 더 잘 대처할 수 있게 해줍니다.
Background: Neural Machine Translation
이 부분에서는 기존에 번역을 위해 사용했던 통계적인 방법과 RNN, LSTM과 GRU에 대한 설명이 이어집니다.
Background: RNN Encoder-Decoder
Cho와 Sutskever에 의해 제안된 RNN Encoder-Decoder모델은 할당과 번역을 동시에 이루어낸 혁명적인 구조였습니다. Encoder-Decoder모델에서 encoder는 입력 문장 x를 context vector c로 바꿉니다. RNN의 사용에 가장 일반적인 접근은 다음과 같습니다.

과

이때, ht는 시간 t의 hidden state이고, f와 q는 비선형 함수입니다.
decoder는 다음 문장 yt를 예측하기 위해 주어진 context vector c와 이전까지 예측했던 단어들 y1 ... yt-1을 이용합니다. 이를 조건부 확률로 나타내면 다음과 같습니다.

Learning to align and translate.
해당 논문에서는 새로운 구조인 biRNN을 제시합니다. 이를 한 번 생각해보면, 장기 의존성 문제를 해결하기 위한 노력이 아니었을까 생각합니다. RNN의 특성상, 그리고 현대의 딥러닝 모델들은 가장 최근에 학습한 데이터에 파라미터들이 맞춰지는 문제가 있습니다. RNN은 특히 Sequential하게 입력을 받기 때문에 가장 처음에 입력된 단어는 상대적으로 마지막에 입력된 단어에 비해 정보가 적은 상태로 context vector가 만들어지게 됩니다.
이를 방지하기 위해서 양 방향에서 encoding을 해줌으로써 장기 의존성 문제를 해결하고자 하지 않았을까.. 비슷한 이유로 seq2seq모델에서 입력을 반대로 집어넣지 않았을까.. seq2seq모델이 나올때는 biRNN같은 구조는 없었으니까 가장 장기의존성을 떨어뜨리는 방법은 입력의 첫 부분을 가장 마지막에 넣어서, 즉 출력의 첫 부분과 입력의 첫 부분을 물리적으로 가깝게 만들어주어서 초기 오류값을 최대한 낮추려고 하지 않았을까 생각합니다. RNN기반의 decoder또한 오류가 누적되는 문제가 있기 때문에, 초기 오류값을 최대한 낮추면 성능이 엄청 낮아지지 않을것을 기대하지 않았을까 합니다.
Decoder: General Description

새로운 모델에서는 확률을 다음과 같이 정의할 수 있습니다.

이때 si는 다음과 같이 계산됩니다.

이는 기존의 encoder-decoder접근 방식과 다릅니다. 각각의 y에 context vector c가 아닌 다른 값이 들어가기 때문입니다. context vector c는 encoder의 hidden states에 영향을 받습니다. 새롭게 정의되는 context vector c는 다음과 같이 정의됩니다. 이는 hi의 가중합으로 계산됩니다.
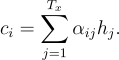
이때 각각의 hj에 대한 가중치 alpha는 다음과 같이 계산됩니다.

eij는 다음과 같이 계산됩니다.

eij는 j위치에 있는 입력과 i위치에 있는 출력이 얼마나 연관되어있는지를 나타냅니다. 할당 모델 a는 Feedforward Neural Network로 다른 컴포넌트들과 같이 학습됩니다. 할당 모델은 직접적으로 soft-alignment를 계산합니다. 이는 역전파를 통해 학습되는 것입니다.
자세한 수식은 뒤에 appendix에서 설명합니다.
어쨋든, 이를 통해 제시된 모델은 encoder에서의 정보를 고정된 길이의 vector로 압축시키면서 버리지 않게됩니다. 이런 접근방법을 통해서 정보들은 sequential한 vector를 통해 넓게 펼처지게되고, decoder는 적절하게 이를 선택합니다.
Encoder: Bidirectional RNN for Annotating Sequences
일반적인 RNN의 경우는 입력 문장 x의 순서를 따라 읽게됩니다. 하지만, 제시된 모델 (biRNN)은 뒤에 이어지는 단어 뿐만 아니라 따라오는 단어들도 읽게 됩니다. 그러므로 이를 양방향 RNN이라 부릅니다.
BiRNN은 전방향과 후방향 RNN으로 구성됩니다.
https://ws-choi.github.io/blog-kor/bidirectional-rnn-in-pytorch/
PyTorch에서의 Bidirectional RNN에 대한 정확한 이해 · Woosung Choi
PyTorch에서의 Bidirectional RNN에 대한 정확한 이해 28 Nov 2020 본 포스트는 Understanding Bidirectional RNN in PyTorch- Ceshine Lee를 한국어로 번역한 자료입니다. This post is a Korean translation version of the post: Understandi
ws-choi.github.io
Experiment Setting.
Dataset.
그냥 영어-프랑스어 데이터를 사용합니다.
Models.
일반적인 RNN encoder-decoder모델과 이 논문에서 제시한 모델을 비교합니다. 또한 각 모델은 학습하는 입력 데이터의 길이에 따라 -30과 -50모델로 나뉩니다. 이를 통해 긴 문장에 얼마나 잘 대처하는 지를 알 수 있습니다.
또한 minibatch stochasic gradient descent방식을 통해 모델의 파라미터를 학습시켰습니다.
https://light-tree.tistory.com/133
딥러닝 용어정리, MGD(Mini-batch gradient descent), SGD(stochastic gradient descent)의 차이
제가 공부한 내용을 정리한 글입니다. 제가 나중에 다시 볼려고 작성한 글이다보니 편의상 반말로 작성했습니다. 잘못된 내용이 있다면 지적 부탁드립니다. 감사합니다. MGD(Mini-batch gradient descent
light-tree.tistory.com
Results.
Quatitaive Results.

기존에 존재하던 RNN기반 encoder-decoder모델은 입력되는 문장의 길이가 길어지면 길어질수록, score가 급격하게 떨어지는 모습을 보이는데, 이 논문에서 제시하는 모델의 경우는 입력되는 문장이 길어도 비교적 안정된 성능을 보입니다.
Qualitative Analysis.
Alignment.
이 논문에서 제시하는 방법은 생성된 번역문과 원문, 입력 문장 사이의 soft-alignment을 검사할 수 있는 직관적인 방법을 제시합니다. 이는 Figure3.를 통해서 잘 볼 수 있습니다.




Figure 3를 보면, 대각선의 원소들은 강한 연결성을 볼 수 있습니다. 하지만, 또한 대각선 원소들끼리 강한 연결성을 보이지 않는 부분도 발견할 수 있습니다. 형용사와 명사는 영어와 프랑스어에서 서로 다른 어순으로 배치됩니다. 하지만 Fig.3(a)를 보면 적절하게 번역이 되었음을 알 수 있습니다. ([European Economic Area]의 번역을 보면 알 수 있다. 어순이 바뀌어서 score가 반대 대각선으로 강조된 모습.)
또 [the man]의 번역이 soft-alignment의 강점을 보여주는 예시입니다.
(자세한 내용은 본문 참조)
Long Senteces.
RNNsearch, 즉 이 논문에서 제시한 모델은 입력 문장은 고정 길이 vector로 표현할 필요가 없을 뿐만 아니라, 특정한 단어 주변의 입력 문장들을 정확하게 encoding할 필요가 없습니다.
(이에 대한 예시는 본문을 참조)
즉, RNNencdec은 입력 문장의 원래 의미를 빼먹지만, RNNsearch는 입력 문장의 원래 의미를 잃어버리지 않습니다. 이는 장기 의존성에 따른 차이같긴 합니다. 다음 예시를 보면 이를 더 정확하게 알 수 있는데,
(이에 대한 예시는 본문을 참조)
RNNencdec은 거의 30단어를 생성한 후에는 입력 문장의 의미를 빼먹고 생성해내기 시작합니다. 그렇기 때문에 닫는 quotation mark를 빼먹는 기본적인 실수를 하기도 합니다. 하지만 RNNsearch는 긴 문장도 적절하게 해석합니다.
Related Work.
Learning to Align
Gaussian kernel과 같은 CNN기반의 kernel은 매우 엄격하게 통제되는 alignment model이었습니다. 하지만 이 논문에서 제시하는 alignment model은 유연한 모델로, 기계 번역에서는 문법적으로 옳은 번역을 위해 reordering이 필요한 경우가 많기 때문에 유연한 할당 모델이 더 유리합니다.
반면에 제시된 모델은 기존의 번역 모델에 비해 계산해야하는 가중치의 값이 많기 때문에, 15-40단어정도의 task는 감당할 수 있지만, 다른 task에 적용하기에는 어려움이 있을 수 있습니다. 이에 관해서는 한 번의 attention계산을 위해서 가중치 행렬이 여러개가 필요하기 때문에 모델이 무거워집니다. 이후에 dot-product만으로 attention을 구하는 방법이 나온것을 생각하면 가중치 행렬을 사용하는 것이 이 모델의 한계가 된다는 점은 동의합니다.
Neural Networks for Machine Translation
그냥 SOTA를 찍었다는 이야기입니다.
Conclusion
encoder-decoder접근방식으로 불리는 기존의 기계 번역 방법은 고정된 길이 vector로 입력 문장을 encoding해야한다는 문제점이 있었습니다. 이는 긴 문장을 번역하는데에 병목이었습니다. 문장의 길이가 길어질수록, 고정된 길이의 vector로 모든 정보를 압축시키기 한계가 있었기 때문입니다.
해당 논문에서는 이 문제를 혁신적인 모델로 해결합니다. 기존에 사용하던 hard-alignment대신 soft-alignment (추후 attention이라고 불리는) 방법을 이용해서 고정된 길이의 vector로 encoding하지 않게 되었습니다. 이를 통해 decoder는 encoder의 원하는 부분에 대해서만 집중해서 번역을 할 수 있었고, 이는 다룰 수 있는 입력 문장의 길이가 늘어나는 긍정적인 결과를 만들었습니다.
Main Questions.
1. 왜 특정 단어의 의미를 표현할 때 주변 N개의 단어(context window)를 주로 활용할까요?
→ "You shall know a word by the company it keeps." 라는 존 루퍼트 퍼스(John Rupert Firth)의 말에 따르면 같은 문장 안에 있는 단어는 유사한 의미를 갖는다고 전제할 수 있습니다. 실제로 언어 모델링은 이런 전제를 바탕으로 이루어집니다.
2. Attention 매커니즘은 Long Term Dependency 문제를 극복했다는 것 이외에 어떤 의의를 가질까요?
→ 딥러닝 모델의 해석가능성에 대한 가능성을 보여줬습니다. 입력 문장과 출력 문장간의 연결 강도를 보여줌으로써 (Attention matrix를 통해) 모델이 어떻게 동작했는지를 해석할 수 있게 되었습니다.
'[Deep daiv.] > [Deep daiv.] NLP' 카테고리의 다른 글
| [Deep daiv.] NLP, 논문 리뷰 - Language Models are Few-Shot Learners (GPT-3) (5) | 2024.11.29 |
|---|---|
| [Deep daiv.] NLP, 논문 리뷰 - Attention is all you need (Transformer) (1) | 2024.11.27 |
| [Deep daiv.] NLP, WIL - 9. ELMo and GPT (2) (0) | 2024.11.13 |
| [Deep daiv.] NLP, WIL - 9. ELMo and GPT (1) (1) | 2024.09.09 |
| [Deep daiv.] NLP, WIL - 7.1 Seq2seq 실습 (1) | 2024.09.06 |