
https://arxiv.org/abs/1706.03762
Attention Is All You Need
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new
arxiv.org
Abstract.
기존의 지배적인 transduction model들은 CNN 혹은 RNN기반이었습니다. 특히 가장 좋은 성능을 보이는 모델은 attention매커니즘을 활용하는 encoder-decoder모델이었습니다.
제시된 논문에서는 오로지 attention매커니즘만을 활용하는 Transformer라는 구조를 소개합니다. 이는 병렬화나 훈련 시간의 측면에서 기존의 방법들에 비해 훨씬 효율적입니다.
기존 encoder-decoder기반, RNN기반의 모델들은 RNN의 특성상 병렬적으로 처리할 수 없이, sequential하게 입력을 받아야했습니다. 그렇기때문에 입력들을 병렬로 처리할 수 있는 Transformer는 기존의 방법에 비해 효율적인 구조였습니다.
또한 RNN기반의 모델들이 그렇듯, 입력들을 sequential하게 받다보니 장기 의존성 문제가 두드러지게 나타납니다. 하지만 Transformer의 경우는 오로지 attention매커니즘만을 사용하기 때문에, 장기 의존성 문제를 거의 해결했습니다.
해당 Transformer는 다양한 task에서 우수한 성능을 보였습니다.
Introduction.
기존에는 RNN, LSTM (long short-term memory), GRU (gated recurrent)를 사용하는 신경망이 특히 기계 번역과 언어 모델에서 굉장히 좋은 성능을 보여왔습니다.
RNN기반 모델의 내재적인 원리 (sequential하게 입력들을 처리하는 성질)는 특별히 제한된 batch입력들만 학습할 수 있게, 즉 병렬화를 막습니다. 이에 대해, 효율적인 계산을 위한 많은 연구가 있었지만 문제는 여전했습니다.
하지만 attention매커니즘은 seqence의 position에 상관하지 않고 모델의 의존성들을 학습할 수 있기 때문에 병렬화 문제를 해결할 수 있습니다. 하지만 여전히 attention매커니즘은 RNN기반 모델과 같이 사용되고 있습니다.
해당 논문에서는 오로지 attention만을 사용하는 모델을 통해 입력 전체에 대한 의존행렬을 만들 수 있었습니다. 이는 높은 병렬화 성능과 다양한 task에서 SOTA를 달성할 수 있었습니다.
Background.
... 진짜 배경 지식
Model Architecture.
대부분의 시퀀스 신경망 모델은 encoder-decoder모델입니다. 이때 모델의 입력의 표현은 (x1, x2, ... , xn)이고, 이를 통해 attention matrix Z = (z1, z2, ... , zn)을 만듭니다. 또한 주어진 Z를 통해서 출력 문장 (y1, y2, ... , ym)을 생성합니다. 각 단계는 auto-regressive한 방식으로 생성됩니다.

위 그림의 Transformer는 self-attention과 FNN (Fully-connnected Neural Network)의 stack으로 이루어진 encoder와 decoder block으로 이루어져있습니다.
Encoder and Decoder Stacks
Encoder: encoder stack의 개수는 6개입니다. 그리고 이는 두 개의 부분 layer를 갖습니다. 첫 번째는 multi-head self attention이고, 두 번째는 간단한 FNN입니다. 또한 residual connection을 두 부분 layer사이에 위치시켰습니다.
residual connection은 resNet에서 처음 사용된 방식으로 모델의 깊이가 깊어질수록 기울기 소실현상이 발생하는데, 이를 방지하기 위해 layer를 통과해서 나온 결과값에 처음 입력값을 다시 한 번 더 더해줌으로써 기울기가 빠르게 소실되는 문제를 해결했습니다. 이를 통해 모델의 깊이가 깊어져서 생기는 문제를 해결할 수 있습니다.
resudal의 공식은 다음과 같습니다:
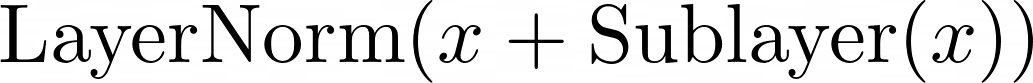
또한 sub-layer에서 사용하는 embedding vector의 차원은 512로 설정했습니다.
Decoder: decoder stack또한 encoder와 마찬가지로 6개의 stack을 쌓았습니다. decoder는 encoder와 같은 sub-layer 두 개를 갖고, 추가적으로 masked multi-head attention을 추가했습니다. 또한 decoder의 multi-head self attention layer는 encoderd의 attention layer로부터 생성된 결과로 계산되는 attention layer입니다.
Attention


attention함수는 Query, Key, Value쌍들로 이루어집니다. 결과는 Value vector들의 가중합으로 이루어집니다. 이때의 가중합은 Q와 K에 대한 함수로 만들어집니다.
Scaled Dot-Product Attention
먼저 입력 Q와 K의 차원은 dk입니다. 제시된 논문에서는 이를 내적해서 root(dk)로 나눈 후, softmax함수를 통과시켜 V와 가중합을 함으로써 attention값을 구했습니다.
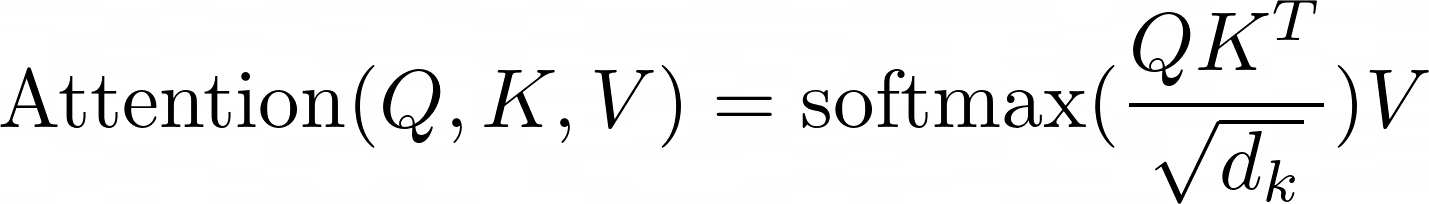
내적을 사용해서 attention을 구한다면 효율적으로 attention을 구할 수 있습니다. 하지만, Q와 K의 차원이 커지면 내적 결과값, 즉 유사도와 상관없이 내적의 값이 증가되는 경향이 있습니다.
차원이 크면, 더해지는 factor의 양도 많아지기 때문에, 유사도와 상관없이 softmax함수 위에서의 값이 양 끝으로 치우치는 결과가 발생할 수 있습니다. 그렇게 된다면 기울기가 소실되는 문제가 발생하기 때문에, root(dk)로 정규화를 해줘서 이 문제를 해결하고자 했습니다.
Multi-head Attention
모델의 embedding차원인 512로 K,Q,V를 생성하지 않고, 여러개의 차원으로 나누어서 attention을 진행하면 많은 이점이 있음을 발견했습니다.
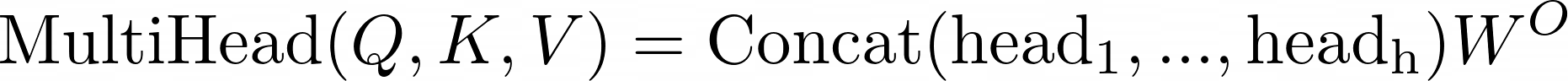

Multi-head를 통해 Attention들을 여러 벡터차원에서 표현할 수 있기 때문에, 표현력이 다양해진다는 장점과, 그 부분공간에서의 관계 또한 학습할 수 있다는 장점이 있습니다.
해당 논문에서는 8개의 head를 사용했습니다.
Applications of Attention in our Model
- in encoder-decoder attention: Q는 dec의 output, K,V는 enc의 output입니다. 이는 모든 위치의 dec이 입력 seq의 어디든지 집중할 수 있게 해줍니다. enc에서 모든 seq에 대한 attention K, V를 만들었고, dec에서는 masked attetion이기 때문에 만약 dec에서 따로 Q,K,V를 만든다면 dec에서의 Q는 seq의 모든 토큰에대해 집중할 수 없고, 지금까지 생성된 문장에 대해서만 집중할 수 있게 됩니다.
- in encoder: 이전 enc의 결과물로 Q, K, V가 결정됩니다.
- in decoder: 입력 문장이 왼쪽으로 흐르는것을 막기위해, 즉 auto-regressive를 지키기위해 decoder에서의 self-attention에서는 mask (-inf)를 붙였습니다. 이를 통해 decoder에서 attention이 아직 생성되지 않은 토큰들을 참조하는 것을 막았습니다.
Position-wise Feed-Forward Networks
각각의 부분 layer에는 FFN이 붙어있는데, 각각의 layer들의 FNN은 독립적으로 동작합니다. 또한 활성화 함수로 ReLU를 사용했습니다.
이 또한, stack이 깊어질수록 기울기 소실에 대한 우려때문에 ReLU를 사용한 것으로 보입니다.

해당 layer의 입력과 출력의 차원은 model의 embedding차원인 512이고, 내부 layer의 차원은 2048로 model의 embedding차원의 4배입니다.
Embedding and Softmax
다른 seq2seq model들은 dmodel차원으로 embedding할때 사전학습된 emb model을 사용했습니다. 하지만 제시된 모델에서는 모델과 같이 학습되는 emb과 선형변환기를 사용합니다.
해당 모델은 두 개의 emb이 같은 가중치를 공유하는 layer로 구성됩니다.
Positional Encoding
이 모델은 RNN이나 CNN을 사용하지 않기 때문에 입력에 대한 상대/절대적인 위치 정보를 주입해주어야합니다. 그래서 제시된 모델에서는 positional encoding을 사용합니다.
positional encoding의 차원은 dmodel과 같이 설정해서 embedding된 vector에 더할 수 있게 해주었습니다.
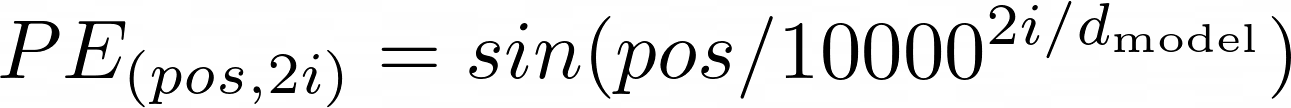

여기서 왜 summation을 사용했을까?
우선 memory의 문제가 있을 수 있다. 일반적으로 어떤 정보를 다른 vector에 주입할때는 concat을 사용한다. 하지만 concat을 사용하면 embedding차원이 두 배로 늘어나고, 그때 당시의 하드웨어를 고려했을때는 이는 부담이었을 수 있다.
그렇다면 왜 sin, cos일까?
다른 방법을 생각해보면... 만약 위치를 나타내기 위해서, 가장 앞에 token에는 1, 그 뒤는 2, ... 이런식으로 번호를 붙인다면, 뒤에 가면 갈 수록 값이 너무 커질 수 있습니다. 즉, 정규화가 안된다는 문제가 있습니다.
그렇다면 seq의 길이가 n이라고 한다면, 1/n, 2/n ... 이런식으로 번호를 붙인다면 정규화된 번호를 붙였기 때문에 가능하지 않을까? 하지만 아닙니다. 이렇게 된다면 가장 앞에 위치한 token의 positional encoding값이 문장의 길이에 따라 달라질 수 있기 때문입니다.
예를 들어, seq의 길이가 100인 문장의 가장 앞 token의 encoding값은 1/100이지만, seq의 길이가 10인 문장의 가장 앞 token의 encoding값은 1/10이 되기때문입니다.
그렇다면 최대와 최소값의 범위가 정해져있어서, 정규화가 되어있고, 주기성이 있기 때문에 절대적인 위치를 encoding할 수 있다는 장점이 있습니다.
다시 돌아와서 제시된 모델은 다음과 같은 PE를 통해 위치를 입력 문장에 녹여낼 수 있었습니다.
Why Self-Attention
빠르게 요약하면,
- 시간복잡도 상에서의 이점
- 병렬화
- 장기의존성 해결
Training
좋은 성능이 나옴
Results
- head가 많다고 무조건 좋은 성능이 나오지는 않음
- 모델이 클수록 좋은 성능을 보임 (scaling law의 시작?)
Appendix
2024.09.09 - [[Deep daiv.]/[Deep daiv.] NLP] - [Deep daiv.] NLP, WIL - 9. ELMo and GPT (1)
[Deep daiv.] NLP, WIL - 9. ELMo and GPT (1)
https://chloamme.github.io/2021/12/08/illustrated-gpt2-korean.html#h-%EC%9E%85%EB%A0%A5-encoding [번역] 그림으로 설명하는 GPT-2 (Transformer Language Model 시각화)이 글은 Jay Alammar님의 글을 번역한 글입니다. [추가정보] This
hw-hk.tistory.com
2024.11.13 - [[Deep daiv.]/[Deep daiv.] NLP] - [Deep daiv.] NLP, WIL - 9. ELMo and GPT (2)
[Deep daiv.] NLP, WIL - 9. ELMo and GPT (2)
2024.09.09 - [[Deep daiv.]/[Deep daiv.] NLP] - [Deep daiv.] NLP, WIL - 9. ELMo and GPT (1) [Deep daiv.] NLP, WIL - 9. ELMo and GPT (1)https://chloamme.github.io/2021/12/08/illustrated-gpt2-korean.html#h-%EC%9E%85%EB%A0%A5-encoding [번역] 그림으로
hw-hk.tistory.com
2024.11.17 - [[Deep daiv.]/[Deep daiv.] NLP] - [Deep Daiv.] NLP, 논문 리뷰 - Bahdanau Attention
[Deep Daiv.] NLP, 논문 리뷰 - Bahdanau Attention
https://arxiv.org/abs/1409.0473 Neural Machine Translation by Jointly Learning to Align and TranslateNeural machine translation is a recently proposed approach to machine translation. Unlike the traditional statistical machine translation, the neural mach
hw-hk.tistory.com
'[Deep daiv.] > [Deep daiv.] NLP' 카테고리의 다른 글
| [Deep daiv.] NLP, 논문 리뷰 - Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (2) | 2024.12.21 |
|---|---|
| [Deep daiv.] NLP, 논문 리뷰 - Language Models are Few-Shot Learners (GPT-3) (5) | 2024.11.29 |
| [Deep Daiv.] NLP, 논문 리뷰 - Bahdanau Attention (1) | 2024.11.17 |
| [Deep daiv.] NLP, WIL - 9. ELMo and GPT (2) (0) | 2024.11.13 |
| [Deep daiv.] NLP, WIL - 9. ELMo and GPT (1) (1) | 2024.09.09 |