
https://arxiv.org/abs/2201.11903
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
We explore how generating a chain of thought -- a series of intermediate reasoning steps -- significantly improves the ability of large language models to perform complex reasoning. In particular, we show how such reasoning abilities emerge naturally in su
arxiv.org
Abstract.
제시한 논문은 어떻게 chain of thought (이하 CoT)를 생성하는지, 그리고 이가 어떻게 복잡한 추론을 요구하는 태스크에 대해서 LLM이 좋은 성능을 보이는지에 대해 설명합니다.
이는 특히 수학이나 상식, 기호적 추론 태스크에서 훌륭한 성능을 보였습니다.
이는 CoT를 활용한 PaLM 540B모델이 수학 벤치마크에서 SOTA를 보여주었으며, 이는 파인튜닝한 GPT-3보다 더 좋은 성능을 보였습니다.
Introduction.
NLP분야에서 성능을 향상시키는 방법으로는 모델의 사이즈를 향상시키는 (Scaling-up)방법이 사용되었습니다. 하지만 이는 수학이나 상식등의 분야에서는 충분한 성능 향상을 이뤄내지 못했습니다.
이 방법은 두 가지 아이디어에서 출발했습니다:
- 산술 문제를 풀 때, 모델이 단순히 답만 생성해내도록 하는 것이 아닌, 마지막 최종적인 정답까지 도달하는 데에 이론적 근거(rationales)도 생성해내도록 하면 성능이 좋아진다는 사실
- LLM은 prompting을 통해 in-context few-shot learning을 할 수 있으며, 최근 간단한 질답 태스크에서 뛰어난 성능을 보였다는 사실
하지만 위 두 사실, 아이디어들은 중요한 문제점을 갖고 있습니다.
이론적 근거(rationales)을 생성해서 학습시키는 방식은 비용이 많이 드는 방법입니다. 이는 단순한 input-output prompting보다 더 나은 성능을 보일 정도의 이론적 근거를 만들어줘야 하는데 이것이 병목이 될 수 있습니다.
또한 전통적인 prompting방법을 사용한 이전 연구에서 추론이 필요한 태스크에서 그다지 좋은 성능을 내지 못한 경우가 있습니다.
이 논문에서는 위 두 아이디어들의 장점들만 잘 결합해서 그들의 한계를 뛰어넘습니다. 이는 다음과 같은 prompt를 이용해서 달성할 수 있습니다:
<input, chain of thought, output>
CoT의 예시는 아래와 같습니다:
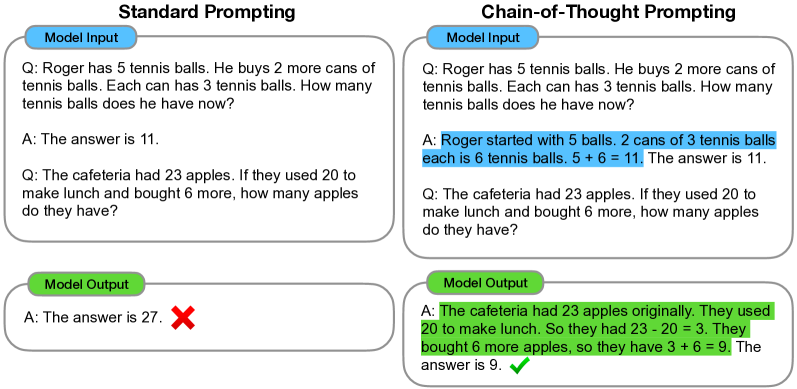
이 방법은 다량의 훈련 데이터셋이 없고 generality의 감소 없이 다양한 태스크에 적용할 수 있는 모델을 만들 수 있다는 점에서 유의미한 방법입니다.
Chain-of-Thought Prompting.
누군가가 복잡한 추론 문제를 푼다고 했을 때, 일반적으로 그들은 문제를 중간 단계들과 최종 정답으로 분해한다음 문제를 풀 것입니다. 이것이 이 논문에서 목표로 하는 점입니다.
다시 말해, 이 논문의 목적은 언어 모델이 중간 추존과정을 통해 최종 정답으로 이어질 수 있게 만들어주는 것입니다. 이 논문에서는 CoT형식의 프롬프트를 조금만 few-shot으로 제공해주면 모델이 스스로 CoT를 만들어냄을 보입니다.
CoT prompting이 추론 태스크에서 좋은 성능을 내는 이유는 다음과 같습니다:
- CoT를 통해 문제를 푸는 과정을 단계별로 분해해 추론할 수 있게 해주며, 이를 통해 태스크 해결에 추가적인 연산을 할당할 수 있게합니다. *이를 생성형 모델이 다음 단어를 생성하는 원리를 통해 이해해보자면, 다음 토큰을 생성하는 데에 필요한 조건부 확률의 조건들을 합리적인 추론의 단계로 채워넣음, 즉 조건부를 조절하여 다음 토큰이 추가적인 연산과 관련된 토큰을 만들 수 있게 해주는 것입니다.
- CoT를 통해 모델의 출력 결과에 대해 해석가능성을 부여합니다. 만약 모델이 틀린 답을 내놓았을 경우에도 어느 부분에서 잘못된 결과를 도출했는지 찾기(debug) 쉬워집니다. *하지만 이는 모델이 만들어내는 CoT대로 모델이 진짜 동작했다고 믿었을 때 가능한 것으로 실제로 모델이 어떤 과정을 통해서 최종적인 출력을 만들어냈는지는 알 수 없습니다(black box)
- CoT방식의 추론은 산술, 추론 태스크 등의 태스크 뿐만 아니라 사람이 해결하고자 하는 대부분의 태스크에 적용 가능합니다. *prompt방법론을 사용했기 때문에 generality가 높다는 것을 설명하는 것 같다.
- CoT는 현재 상용화된 language model에 쉽게 적용시킬 수 있습니다.

Arithmetic Reasoning
Experimental Setup
(위 Figure 1.과 같은 setting)
총 4개의 벤치마크 데이터 셋(GSM8K, SVAMP, ASDiv, AQuA, MAWPS)에 대해 실험을 진행했고, 정확한 비교를 위해 chain-of-thought prompt를 만들 때 같은 입력에 대해 여러 명의 사람이 서로 다른 prompt를 만들고 하나를 골라서 사용했습니다. *여기에서 알 수 있듯 prompt를 만드는 역량에 따라서 성능이 달라질 수 있다.
Results.
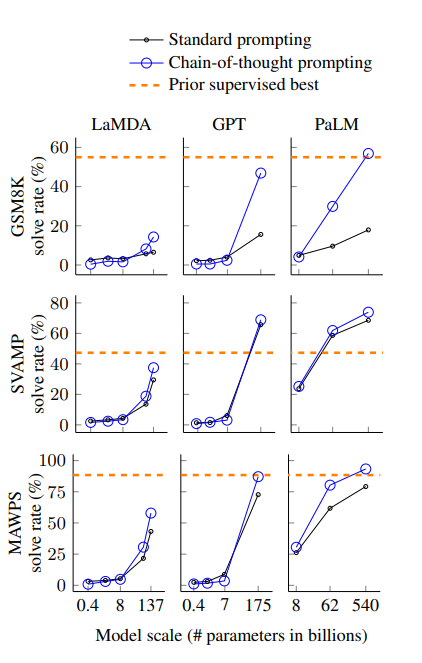
결과에서 볼 수 있듯, 모델의 스케일이 커질 수록 CoT의 성능 향상이 더 두드러지게 나타납니다. 또한 CoT는 복잡한 문제에 대해서는 더 좋은 성능을 보였지만, 쉬운 문제의 경우에는 standard prompting과 비교하여 성능이 감소하거나 적게 증가하는 모습을 보였습니다. *이는 추론의 단계가 비교적 짧은 경우는 CoT의 방식인 깊고, 추론이 여러단계로 이어지는 방법이 필요없고, 심지어는 좋지 않다는 것을 알 수 있습니다.
위에서 설명했던 설명가능성을 이용하여, CoT가 어떻게 만들어졌는지를 알아봤는데, 결과는 다음과 같습니다:
- 맞춘 문제 중 50개를 살펴보니, 단 2문제만 모델이 생성한 CoT에 오류가 있었으며, 나머지 문제에 대해서는 정답과 CoT에 포함된 추론 과정 역시 정확했다. *맞췄지만 추론의 과정이 틀린 case를 통해서 모델이 만들어내는 CoT와 실제 모델이 정답을 추론하는 과정이 다를 수 있음을 알 수 있습니다.
- 틀린 문제 중 50개를 살펴보니 46%의 문제는 CoT 추론 과정에서 오류가 없거나 사소한 것만 있었고, 나머지 54%의 문제는 CoT의 추론 과정에서 중요한 오류가 있었습니다.
Ablation Study.
본 연구에서는 CoT가 왜 성능을 높여주는지 알아보기 위해 여러 조건들을 바꿔가보며 추가적인 실험을 진행했습니다.
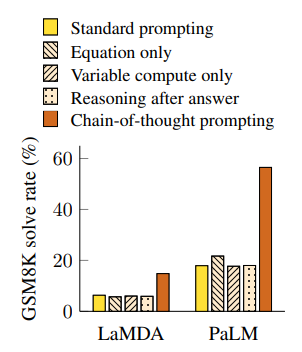
- Equation only: CoT가 수학에 관한 태스크를 수행하는데 좋은 성능을 보인 이유는 최종적인 정답으로 향하는 수식들을 생성하기 때문인데, 그렇다면 오직 수식만을 이용하는 CoT를 사용하면 좋은 성능을 보이는지를 확인하기 위함. 어려운 태스크의 경우 비교적 괜찮은 성능을 보였지만, 쉬운 태스크의 경우는 Standard prompting방법보다 더 낮은 점수를 기록했음.
- Variable compute only: Standard prompt보다 CoT가 성능이 더 좋은 이유가 prompt의 길이가 늘어나면서 모델의 연산량이 증가하는 것 때문인지 확인하기 위함. CoT와 길이를 맞추기 위해 Standard prompt에 dots(...)을 붙여줘서 길이를 맞춰줌. 하지만, CoT보다 낮은 성능을 보임. *이를 통해 CoT의 성능이 단순 연산량의 증가때문은 아님을 알 수 있음.
- Chain of thought after answer: CoT를 활용해서 점수가 높게 나온 것이 prompt에 그저 태스크에 관한 정보만을 제공했기 때문인지 아닌지를 확인하기 위해 기존에 CoT와 answer의 순서를 바꿔줌. 하지만 기존 CoT보다 더 낮은 점수를 기록. *CoT가 단순 정보 제공용이 아닌 모델의 추론에 실제로 도움을 줌을 알 수 있음.
Robustness of Chain of Thought.
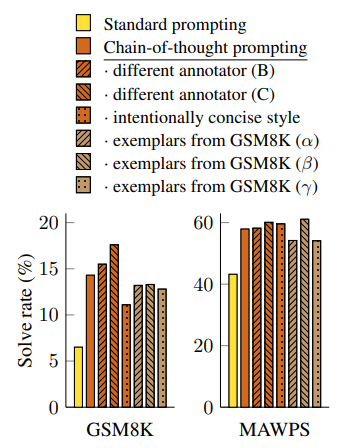
GPT-3의 SST-2 벤치마크에서는 prompt를 작성하는 작성자에 따라 최소 54.3%에서 93.4%(SOTA)까지 성능의 차이가 났었는데, 이는 이전에 말했던 prompt나 CoT를 주입하는 작성자의 역량의 따라 성능이 달라질 수 있다는 문제를 보여줍니다.
해당 논문에서도 여러 examplar(* prompt 작성자)의 prompt를 이용해 각각 학습을 해본 결과, 모든 상황에서 기존의 standard prompt보다 좋은 성능을 기록했습니다. 즉 examplar의 역량과 별개로 CoT의 성능이 보장됨을 보여줍니다. *하지만 CoT examplar간의 성능차이는 어쩔 수 없나봅니다...
Commonsense Reasoning.
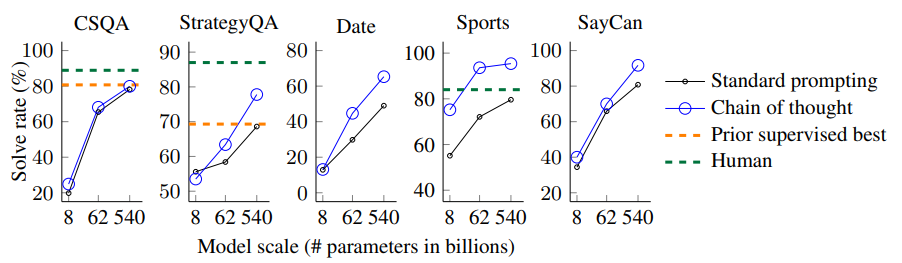
대부분의 벤치마크에서 Standard prompting보다 좋은 성능을 보였습니다.
Symbolic Reasoning.
기호 추론 태스크는 일반적으로 사람에게는 쉽지만 언어 모델에는 어려운 태스크를 말합니다.
기호 추론 태스크는 크게 두 가지로 나눌 수 있습니다:
- Last letter concatenation
- 문장에 있는 단어들의 끝 문자만 모으는 것(ex. "Amy Brown" -> "yn")
- Coin flip
- 동전이 있을 때, 동전의 초기 상태가 주어지고 동전이 몇 번 뒤집어졌는지 정보를 준 뒤, 마지막 동전의 상태를 맞추는 태스크.

Discussion.
- 사람의 추론과정을 CoT를 통해서 모델에게 주입해준 것으로 이것이 실제로 모델이 추론하는 것인지에 대한 대답이 아님.
- examplar가 CoT를 생성해야 하기 때문에 이에 대한 비용이 있을 수 있음.
- 위에서 말했듯이 모델이 만들어낸 CoT가 모델의 실제 추론 과정인지 아닌지는 알 수 없음.
- CoT가 큰 모델들에 대해서만 좋은 성능을 보였기 때문에 작은 모델에서도 CoT가 효율적으로 적용될 방법을 추후 연구해 봐야함.
'[Deep daiv.] > [Deep daiv.] NLP' 카테고리의 다른 글
https://arxiv.org/abs/2201.11903
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
We explore how generating a chain of thought -- a series of intermediate reasoning steps -- significantly improves the ability of large language models to perform complex reasoning. In particular, we show how such reasoning abilities emerge naturally in su
arxiv.org
Abstract.
제시한 논문은 어떻게 chain of thought (이하 CoT)를 생성하는지, 그리고 이가 어떻게 복잡한 추론을 요구하는 태스크에 대해서 LLM이 좋은 성능을 보이는지에 대해 설명합니다.
이는 특히 수학이나 상식, 기호적 추론 태스크에서 훌륭한 성능을 보였습니다.
이는 CoT를 활용한 PaLM 540B모델이 수학 벤치마크에서 SOTA를 보여주었으며, 이는 파인튜닝한 GPT-3보다 더 좋은 성능을 보였습니다.
Introduction.
NLP분야에서 성능을 향상시키는 방법으로는 모델의 사이즈를 향상시키는 (Scaling-up)방법이 사용되었습니다. 하지만 이는 수학이나 상식등의 분야에서는 충분한 성능 향상을 이뤄내지 못했습니다.
이 방법은 두 가지 아이디어에서 출발했습니다:
- 산술 문제를 풀 때, 모델이 단순히 답만 생성해내도록 하는 것이 아닌, 마지막 최종적인 정답까지 도달하는 데에 이론적 근거(rationales)도 생성해내도록 하면 성능이 좋아진다는 사실
- LLM은 prompting을 통해 in-context few-shot learning을 할 수 있으며, 최근 간단한 질답 태스크에서 뛰어난 성능을 보였다는 사실
하지만 위 두 사실, 아이디어들은 중요한 문제점을 갖고 있습니다.
이론적 근거(rationales)을 생성해서 학습시키는 방식은 비용이 많이 드는 방법입니다. 이는 단순한 input-output prompting보다 더 나은 성능을 보일 정도의 이론적 근거를 만들어줘야 하는데 이것이 병목이 될 수 있습니다.
또한 전통적인 prompting방법을 사용한 이전 연구에서 추론이 필요한 태스크에서 그다지 좋은 성능을 내지 못한 경우가 있습니다.
이 논문에서는 위 두 아이디어들의 장점들만 잘 결합해서 그들의 한계를 뛰어넘습니다. 이는 다음과 같은 prompt를 이용해서 달성할 수 있습니다:
<input, chain of thought, output>
CoT의 예시는 아래와 같습니다:
이 방법은 다량의 훈련 데이터셋이 없고 generality의 감소 없이 다양한 태스크에 적용할 수 있는 모델을 만들 수 있다는 점에서 유의미한 방법입니다.
Chain-of-Thought Prompting.
누군가가 복잡한 추론 문제를 푼다고 했을 때, 일반적으로 그들은 문제를 중간 단계들과 최종 정답으로 분해한다음 문제를 풀 것입니다. 이것이 이 논문에서 목표로 하는 점입니다.
다시 말해, 이 논문의 목적은 언어 모델이 중간 추존과정을 통해 최종 정답으로 이어질 수 있게 만들어주는 것입니다. 이 논문에서는 CoT형식의 프롬프트를 조금만 few-shot으로 제공해주면 모델이 스스로 CoT를 만들어냄을 보입니다.
CoT prompting이 추론 태스크에서 좋은 성능을 내는 이유는 다음과 같습니다:
- CoT를 통해 문제를 푸는 과정을 단계별로 분해해 추론할 수 있게 해주며, 이를 통해 태스크 해결에 추가적인 연산을 할당할 수 있게합니다. *이를 생성형 모델이 다음 단어를 생성하는 원리를 통해 이해해보자면, 다음 토큰을 생성하는 데에 필요한 조건부 확률의 조건들을 합리적인 추론의 단계로 채워넣음, 즉 조건부를 조절하여 다음 토큰이 추가적인 연산과 관련된 토큰을 만들 수 있게 해주는 것입니다.
- CoT를 통해 모델의 출력 결과에 대해 해석가능성을 부여합니다. 만약 모델이 틀린 답을 내놓았을 경우에도 어느 부분에서 잘못된 결과를 도출했는지 찾기(debug) 쉬워집니다. *하지만 이는 모델이 만들어내는 CoT대로 모델이 진짜 동작했다고 믿었을 때 가능한 것으로 실제로 모델이 어떤 과정을 통해서 최종적인 출력을 만들어냈는지는 알 수 없습니다(black box)
- CoT방식의 추론은 산술, 추론 태스크 등의 태스크 뿐만 아니라 사람이 해결하고자 하는 대부분의 태스크에 적용 가능합니다. *prompt방법론을 사용했기 때문에 generality가 높다는 것을 설명하는 것 같다.
- CoT는 현재 상용화된 language model에 쉽게 적용시킬 수 있습니다.
Arithmetic Reasoning
Experimental Setup
(위 Figure 1.과 같은 setting)
총 4개의 벤치마크 데이터 셋(GSM8K, SVAMP, ASDiv, AQuA, MAWPS)에 대해 실험을 진행했고, 정확한 비교를 위해 chain-of-thought prompt를 만들 때 같은 입력에 대해 여러 명의 사람이 서로 다른 prompt를 만들고 하나를 골라서 사용했습니다. *여기에서 알 수 있듯 prompt를 만드는 역량에 따라서 성능이 달라질 수 있다.
Results.
결과에서 볼 수 있듯, 모델의 스케일이 커질 수록 CoT의 성능 향상이 더 두드러지게 나타납니다. 또한 CoT는 복잡한 문제에 대해서는 더 좋은 성능을 보였지만, 쉬운 문제의 경우에는 standard prompting과 비교하여 성능이 감소하거나 적게 증가하는 모습을 보였습니다. *이는 추론의 단계가 비교적 짧은 경우는 CoT의 방식인 깊고, 추론이 여러단계로 이어지는 방법이 필요없고, 심지어는 좋지 않다는 것을 알 수 있습니다.
위에서 설명했던 설명가능성을 이용하여, CoT가 어떻게 만들어졌는지를 알아봤는데, 결과는 다음과 같습니다:
- 맞춘 문제 중 50개를 살펴보니, 단 2문제만 모델이 생성한 CoT에 오류가 있었으며, 나머지 문제에 대해서는 정답과 CoT에 포함된 추론 과정 역시 정확했다. *맞췄지만 추론의 과정이 틀린 case를 통해서 모델이 만들어내는 CoT와 실제 모델이 정답을 추론하는 과정이 다를 수 있음을 알 수 있습니다.
- 틀린 문제 중 50개를 살펴보니 46%의 문제는 CoT 추론 과정에서 오류가 없거나 사소한 것만 있었고, 나머지 54%의 문제는 CoT의 추론 과정에서 중요한 오류가 있었습니다.
Ablation Study.
본 연구에서는 CoT가 왜 성능을 높여주는지 알아보기 위해 여러 조건들을 바꿔가보며 추가적인 실험을 진행했습니다.
- Equation only: CoT가 수학에 관한 태스크를 수행하는데 좋은 성능을 보인 이유는 최종적인 정답으로 향하는 수식들을 생성하기 때문인데, 그렇다면 오직 수식만을 이용하는 CoT를 사용하면 좋은 성능을 보이는지를 확인하기 위함. 어려운 태스크의 경우 비교적 괜찮은 성능을 보였지만, 쉬운 태스크의 경우는 Standard prompting방법보다 더 낮은 점수를 기록했음.
- Variable compute only: Standard prompt보다 CoT가 성능이 더 좋은 이유가 prompt의 길이가 늘어나면서 모델의 연산량이 증가하는 것 때문인지 확인하기 위함. CoT와 길이를 맞추기 위해 Standard prompt에 dots(...)을 붙여줘서 길이를 맞춰줌. 하지만, CoT보다 낮은 성능을 보임. *이를 통해 CoT의 성능이 단순 연산량의 증가때문은 아님을 알 수 있음.
- Chain of thought after answer: CoT를 활용해서 점수가 높게 나온 것이 prompt에 그저 태스크에 관한 정보만을 제공했기 때문인지 아닌지를 확인하기 위해 기존에 CoT와 answer의 순서를 바꿔줌. 하지만 기존 CoT보다 더 낮은 점수를 기록. *CoT가 단순 정보 제공용이 아닌 모델의 추론에 실제로 도움을 줌을 알 수 있음.
Robustness of Chain of Thought.
GPT-3의 SST-2 벤치마크에서는 prompt를 작성하는 작성자에 따라 최소 54.3%에서 93.4%(SOTA)까지 성능의 차이가 났었는데, 이는 이전에 말했던 prompt나 CoT를 주입하는 작성자의 역량의 따라 성능이 달라질 수 있다는 문제를 보여줍니다.
해당 논문에서도 여러 examplar(* prompt 작성자)의 prompt를 이용해 각각 학습을 해본 결과, 모든 상황에서 기존의 standard prompt보다 좋은 성능을 기록했습니다. 즉 examplar의 역량과 별개로 CoT의 성능이 보장됨을 보여줍니다. *하지만 CoT examplar간의 성능차이는 어쩔 수 없나봅니다...
Commonsense Reasoning.
대부분의 벤치마크에서 Standard prompting보다 좋은 성능을 보였습니다.
Symbolic Reasoning.
기호 추론 태스크는 일반적으로 사람에게는 쉽지만 언어 모델에는 어려운 태스크를 말합니다.
기호 추론 태스크는 크게 두 가지로 나눌 수 있습니다:
- Last letter concatenation
- 문장에 있는 단어들의 끝 문자만 모으는 것(ex. "Amy Brown" -> "yn")
- Coin flip
- 동전이 있을 때, 동전의 초기 상태가 주어지고 동전이 몇 번 뒤집어졌는지 정보를 준 뒤, 마지막 동전의 상태를 맞추는 태스크.
Discussion.
- 사람의 추론과정을 CoT를 통해서 모델에게 주입해준 것으로 이것이 실제로 모델이 추론하는 것인지에 대한 대답이 아님.
- examplar가 CoT를 생성해야 하기 때문에 이에 대한 비용이 있을 수 있음.
- 위에서 말했듯이 모델이 만들어낸 CoT가 모델의 실제 추론 과정인지 아닌지는 알 수 없음.
- CoT가 큰 모델들에 대해서만 좋은 성능을 보였기 때문에 작은 모델에서도 CoT가 효율적으로 적용될 방법을 추후 연구해 봐야함.