
Prompt?
[Deep daiv.] NLP, 논문 리뷰 - Language Models are Few-Shot Learners (GPT-3)
https://arxiv.org/abs/2005.14165 Language Models are Few-Shot LearnersRecent work has demonstrated substantial gains on many NLP tasks and benchmarks by pre-training on a large corpus of text followed by fine-tuning on a specific task. While typically tas
hw-hk.tistory.com
일반적으로 prompt라고 하면, GPT-3에서 처음 사용되었고 현재의 LLM에서도 많이 사용되는 텍스트로 이루어진 prompt를 생각할 수 있습니다. 하지만, 이 글에서 말할 prompt는 텍스트가 아니라 모델 앞, 뒷단에 위치한 파라미터를 의미합니다.
이러한 연구가 이루어진 이유는 GPT-3논문에서 새로운 태스크를 지시하기 전에 텍스트로 해당 작업에 대한 몇 가지 예시를 먼저 보여주면 성능이 높아진다는 연구가 이미 이루어졌기 때문입니다. 이것을 점화(Priming)이라고 합니다. 점화의 핵심은 새로운 작업을 수행하기 위한 준비 단계가 LM에게는 필요하고, 이를 프롬프트를 통해 달성한다는 점입니다.
또한 대규모 언어 모델(LLM)의 발전은 인간과 유사한 방식으로 다양한 자연어 처리 작업을 수행할 수 있는 능력을 보여줬지만, 이러한 모델들을 특정 작업에 최적화하기 위한 기존의 fine-tuning 방법론은 많은 리소스를 요구하며, 이는 실용적인 적용에 있어서 큰 장벽이 되어왔습니다. 그렇기 때문에 다양한 방식의 PEFT(Prameter Efficient Fine Tuning) 방법들이 경쟁적으로 발표되던 시기에 나온 논문이 아래의 두 방법들입니다.
Prompt Tuning과 Prefix Tuning은 LM의 파인튜닝을 간소화한 방법이라는 점에서 매우 비슷한 개념입니다.
Prompt Tuning은 특정한 다운스트림 태스크를 수행하기 위해 언어모델의 가중치를 고정하고, 개별 태스크마다 프롬프트의 파라미터를 업데이트하는 Soft Prompt의 학습 방법을 사용합니다. Prefix Tuning또한 비슷한데, 모델의 전체 매개변수를 파인튜닝하는 대신, 입력 시퀀스에 학습 가능한 'prefix'를 추가하여 모델을 특정 작업에 적응시키는 것입니다.
우선, Soft Prompt가 있는데
Hard Prompt도 있을까요?
있습니다.

프롬프트의 학습 방법은 크게 Hard Prompt와 Soft Prompt로 구분합니다. Hard Prompt는 input의 특성에 따라 input 값이 미리 정의된 텍스트 템플릿으로 바뀝니다. 즉, Positive, Negative와 같이 주로 자연어 형태의 이산적인(discrete) 값을 갖습니다. 하지만, LM은 이산적인 값이 아닌 연속적인 값으로 임베딩이 된 후 학습이 되기 때문에 Hard Prompt는 최적화되지 않는다는 단점이 있습니다. *그 뿐 아니라 점화의 관점에서 바라볼 때, 해야하는 태스크를 설명하는 prompt가 뒤에 있다는 점도 성능 향상의 병목이지 않았을까?
반면, Soft Prompt는 input앞에 튜닝이 가능한 임베딩 조각(tunable piece of embedding, *Hard Prompt와 달리 연속적인 값을 갖는 prompt)이 붙게 됩니다. 이 임베딩 조각은 실수로 이루어진 연속적인 값으로 학습되고, 기존의 Hard Prompt학습에 비해 더 효과적인 학습이 가능합니다.
앞으로는 Soft Prompt Tuning과 Prompt Tuning을 섞어서 사용하겠습니다.
(Soft) Prompt Tuning

위 그림은 Prompt Tuning과 Model Tuning(*Full Parameter Tuning)을 비교해 설명합니다. Model Tuning은 언어모델의 모든 파라미터를 튜닝하는 방법으로, 태스크 A와 B, C에 맞게 모든 파라미터를 튜닝해야합니다. 하지만, Prompt Tuning은 기존의 학습된 모델의 가중치는 고정하고 태스크 A와 B, C에 맞게 input 텍스트(e.g., a1, b1, c1)에 추가적인 k개의 튜닝이 가능한 토큰(e.g., A, B, C,*soft prompt이기 때문에 실제로는 embedding되는 어떤 임의의 실수 vector)을 붙입니다. *모델의 모든 파라미터는 가중치를 고정하고, prompt부분만 학습을 진행하는 것으로 학습하는 파라미터의 양이 많이 줄게됩니다.
이때, 아래와 같은 고려사항이 있을 수 있습니다:
- Prompt 표현의 초기값을 무엇으로 할 것인가?
Prompt 표현의 초기값을 설정하는 데는 3가지 방법이 있습니다. 첫번째는 무작위 초기화(random initialization)를 사용해 처음부터 모델을 훈련하는 것입니다. 두번째 방법은 개별 프롬프트 토큰을 모델의 vocabulary에서 추출한 임베딩으로 초기화하는 것입니다. 마지막으로는 프롬프트의 출력 클래스를 나열하는 임베딩으로 초기화하는 방법입니다.
테스트 결과에 따스면, 무작위 초기화를 해주는 것보다 vocabulary 또는 출력 클래스의 임베딩으로 초기화를 해주는 것이 더 좋은 성능이 나왔습니다.
- Prompt의 길이를 얼마로 할 것인가?
Prompt의 길이를 위한 파라미터의 비용은 EP로 계산합니다. E는 토큰 임베딩의 차원이고, P는 프롬프트의 길이입니다. 프롬프트의 길이가 더 짧을수록, 새로운 파라미터가 더 적게 튜닝되어야 합니다. 연구 결과의 따르면, Prompt의 길이는 5~100사이의 값이 적절한 것으로 나왔습니다. *Prompt의 길이가 길면 더 다양한 Task에 맞춰서 Tuning할 수 있다는 장점이 있지만, 더 많은 양의 파라미터를 Tuning해야하기 때문에 비용이 더 많이 듭니다.
(Soft) Prompt Tuning Results

Prompt Tuning의 성능은 위 그림과 같습니다. Prompt Tuning은 모델의 크기가 커질수록 성능이 향상됩니다. 특히, 모델의 크기가 수십억 개의 파라미터를 초과하는 경우, Model Tuning과 거의 동일한 성능을 보입니다. *모델 자체의 크기가 크다면, 각각의 태스크를 위한 Full Parameter Tuning은 너무 과하다는 것을 의미합니다.
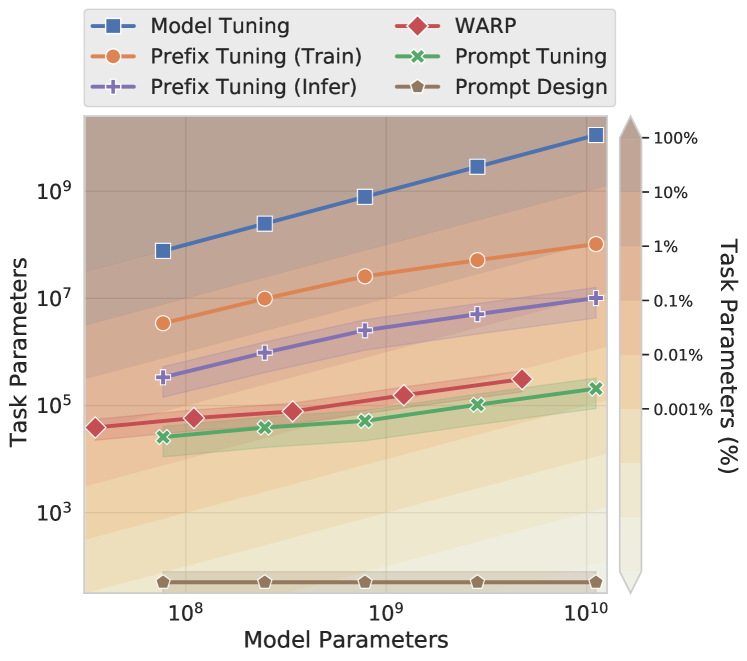
위 그림은 파인 튜닝에 필요한 파라미터의 개수를 비교한 결과입니다. Model Tuning이 100%의 파라미터를 갖고 있다면, Prompt Tuning은 0.001%의 파라미터를 가지고 Model Tuning만큼의 성능을 보일 수 있습니다. Prefix Tuning이 0.1%의 파라미터를 학습하는 것과 비교할 때, Prompt Tuning은 아주 적은 파라미터로 효율적인 Fine-tuning이 가능해집니다. 즉, Prompt Tuning이 대규모의 언어모델을 특정한 다운스트림 태스크에 적용하는 데 효율적으로 사용될 수 있습니다.
Prefix Tuning

Prompt Tuning과 비슷한 아이디어에서 시작한 이 개념은 Prefix를 잘 찾아주면 좋은 Prompt가 되고, 이렇게 좋은 Prompt를 찾을 수 있다면 LLM 대답의 퀄리티가 좋아진다는 것이 주요 포인트입니다. Prompt Tuning과 마찬가지로 '좋은 Prefix'를 찾기 위해서 '학습'을 진행합니다. 기존의 역전파 방식을 그대로 사용하되, Gradient를 받는 주체가 모델 파라미터가 아닌 Prefix만 된다는 차이만 있습니다.
하지만 이때, Prefix vector를 바로 학습하는 것은 실험적으로 성능이 좋지 못했기 때문에, Prametrization을 사용합니다. 즉, MLP를 사용해서 Prefix를 찾아주는 것인데, 그림으로 표현하면 다음과 같습니다:

P를 직접 찾는 것이 아닌, MLP를 학습하여 나온 Feature를 사용하겠다는 의미입니다.

위 그림은 Fine Tuning과 Prefix Tuninf 방법의 학습 파라미터를 비교하는 그림입니다. 위쪽의 Fine Tuning을 보면 각 Task별로 Transformer 전체를 재학습하는 모습을 표현하고 있습니다. 엄청 많은 학습 파라미터가 표현된 모습인데 반해, Prefix Tuning에서는 앞쪽 Prefix만 학습해주고 있습니다. Task별로 아주 적은 Prefix 파라미터만 학습하면 되기에 매우 효율적임을 알 수 있습니다.
다른 방법들과의 비교
Prefix Tuning vs Prompt Tuning
Prefix Tuning은 모든 트랜스포머 레이어에 접두어 시퀀스를 붙여 학습하는 방법으로, Prefix Tuning은 트랜스포머의 모든 계층에 접두어를 붙이는 반면 (아래 그림 참조), Prompt Tuning은 input앞에 접두어를 붙여 하나의 프롬프트 표현을 사용합니다. 즉, Prompt Tuning은 Prefix Tuning보다 더 적은 파라미터로 모델의 Fine-Tuning이 가능합니다. 예를 들어, BART를 사용할 때, Prefix Tuning은 인코더와 디코더 네트워크에 모두 접두사를 붙이지만, Prompt Tuning은 인코더의 프롬프트에만 접두어를 붙입니다.

P-Tuning
다른 PEFT로 P-Tuning도 있습니다.
P-Tuning은 간단히 말해, 인간이 디자인한 패터을 사용해 학습이 가능한 연속적인 Prompt를 input전체에 삽입하는 방법입니다. P-tuning은 입력 전체에 연속적인 prompt를 삽입하는 반면, Prompt Tuning은 접두어로 붙이기 때문에 P-tuning보다 단순해집니다. 또한 P-Tuning은 프롬프트와 모델의 주요 파라미터를 같이 업데이트하는 반면, Prompt Tuning은 언어모델을 고정된 상태로 사용하기 때문에 더 효율적입니다.
P-tuning에 대한 자세한 내용은 아래의 블로그를..
https://ghqls0210.tistory.com/337
P-Tuning
P-Tuning은 아래 논문에서 처음 소개되었습니다. https://arxiv.org/pdf/2103.10385.pdf 논문 제목이 GPT Understands, too 인데 그 이유는 GPT 모델의 경우, 논문이 나온 당시 GPT 모델은 NLI (Natural Language Inference), AE (
ghqls0210.tistory.com
참고자료
https://arxiv.org/abs/2101.00190
Prefix-Tuning: Optimizing Continuous Prompts for Generation
Fine-tuning is the de facto way to leverage large pretrained language models to perform downstream tasks. However, it modifies all the language model parameters and therefore necessitates storing a full copy for each task. In this paper, we propose prefix-
arxiv.org
https://arxiv.org/abs/2104.08691
The Power of Scale for Parameter-Efficient Prompt Tuning
In this work, we explore "prompt tuning", a simple yet effective mechanism for learning "soft prompts" to condition frozen language models to perform specific downstream tasks. Unlike the discrete text prompts used by GPT-3, soft prompts are learned throug
arxiv.org
https://blog.harampark.com/blog/llm-prompt-tuning/
논문 리뷰 | PEFT의 대표적인 사례인 Prompt Tuning 알아보기
HuggingFace의 PEFT 중 하나로 지원하는 Prompt Tuning에 대해 알아보자. Prompt Tuning을 제안한 논문인 The Power of Scale for Parameter-Efficient Prompt Tuning을 읽고 리뷰한다.
blog.harampark.com
https://ffighting.net/deep-learning-paper-review/language-model/prefix-tuning/
[논문 리뷰] Prefix Tuning: Optimizing Continuous Prompts for Generation
효율적으로 LLM을 문제에 맞게 학습하는 방법중 하나인 Prefix Tuning 논문을 쉽게 설명합니다. 기존 Fine Tuning, Adapter 등의 PEFT 방식과 Prefix Tuning은 무엇이 다른지 그림을 통해 쉽게 이해해봅니다.
ffighting.net
https://stydy-sturdy.tistory.com/45
[딥러닝 이론] Prompt Tuning VS Prefix Tuning
시험기간이 끝나고 오랜만에 글을 써본다. 내 공부는 꾸준히 하고 있었지만 시험 기간이 겹쳐 글을 쓸 시간이 도저히 없었다. (핑계..) 오늘은 여러 논문들을 들으며 헷갈렸던 개념들, 특히 'Visual
stydy-sturdy.tistory.com
'[Deep daiv.] > [Deep daiv.] NLP' 카테고리의 다른 글
Prompt?
[Deep daiv.] NLP, 논문 리뷰 - Language Models are Few-Shot Learners (GPT-3)
https://arxiv.org/abs/2005.14165 Language Models are Few-Shot LearnersRecent work has demonstrated substantial gains on many NLP tasks and benchmarks by pre-training on a large corpus of text followed by fine-tuning on a specific task. While typically tas
hw-hk.tistory.com
일반적으로 prompt라고 하면, GPT-3에서 처음 사용되었고 현재의 LLM에서도 많이 사용되는 텍스트로 이루어진 prompt를 생각할 수 있습니다. 하지만, 이 글에서 말할 prompt는 텍스트가 아니라 모델 앞, 뒷단에 위치한 파라미터를 의미합니다.
이러한 연구가 이루어진 이유는 GPT-3논문에서 새로운 태스크를 지시하기 전에 텍스트로 해당 작업에 대한 몇 가지 예시를 먼저 보여주면 성능이 높아진다는 연구가 이미 이루어졌기 때문입니다. 이것을 점화(Priming)이라고 합니다. 점화의 핵심은 새로운 작업을 수행하기 위한 준비 단계가 LM에게는 필요하고, 이를 프롬프트를 통해 달성한다는 점입니다.
또한 대규모 언어 모델(LLM)의 발전은 인간과 유사한 방식으로 다양한 자연어 처리 작업을 수행할 수 있는 능력을 보여줬지만, 이러한 모델들을 특정 작업에 최적화하기 위한 기존의 fine-tuning 방법론은 많은 리소스를 요구하며, 이는 실용적인 적용에 있어서 큰 장벽이 되어왔습니다. 그렇기 때문에 다양한 방식의 PEFT(Prameter Efficient Fine Tuning) 방법들이 경쟁적으로 발표되던 시기에 나온 논문이 아래의 두 방법들입니다.
Prompt Tuning과 Prefix Tuning은 LM의 파인튜닝을 간소화한 방법이라는 점에서 매우 비슷한 개념입니다.
Prompt Tuning은 특정한 다운스트림 태스크를 수행하기 위해 언어모델의 가중치를 고정하고, 개별 태스크마다 프롬프트의 파라미터를 업데이트하는 Soft Prompt의 학습 방법을 사용합니다. Prefix Tuning또한 비슷한데, 모델의 전체 매개변수를 파인튜닝하는 대신, 입력 시퀀스에 학습 가능한 'prefix'를 추가하여 모델을 특정 작업에 적응시키는 것입니다.
우선, Soft Prompt가 있는데
Hard Prompt도 있을까요?
있습니다.
프롬프트의 학습 방법은 크게 Hard Prompt와 Soft Prompt로 구분합니다. Hard Prompt는 input의 특성에 따라 input 값이 미리 정의된 텍스트 템플릿으로 바뀝니다. 즉, Positive, Negative와 같이 주로 자연어 형태의 이산적인(discrete) 값을 갖습니다. 하지만, LM은 이산적인 값이 아닌 연속적인 값으로 임베딩이 된 후 학습이 되기 때문에 Hard Prompt는 최적화되지 않는다는 단점이 있습니다. *그 뿐 아니라 점화의 관점에서 바라볼 때, 해야하는 태스크를 설명하는 prompt가 뒤에 있다는 점도 성능 향상의 병목이지 않았을까?
반면, Soft Prompt는 input앞에 튜닝이 가능한 임베딩 조각(tunable piece of embedding, *Hard Prompt와 달리 연속적인 값을 갖는 prompt)이 붙게 됩니다. 이 임베딩 조각은 실수로 이루어진 연속적인 값으로 학습되고, 기존의 Hard Prompt학습에 비해 더 효과적인 학습이 가능합니다.
앞으로는 Soft Prompt Tuning과 Prompt Tuning을 섞어서 사용하겠습니다.
(Soft) Prompt Tuning
위 그림은 Prompt Tuning과 Model Tuning(*Full Parameter Tuning)을 비교해 설명합니다. Model Tuning은 언어모델의 모든 파라미터를 튜닝하는 방법으로, 태스크 A와 B, C에 맞게 모든 파라미터를 튜닝해야합니다. 하지만, Prompt Tuning은 기존의 학습된 모델의 가중치는 고정하고 태스크 A와 B, C에 맞게 input 텍스트(e.g., a1, b1, c1)에 추가적인 k개의 튜닝이 가능한 토큰(e.g., A, B, C,*soft prompt이기 때문에 실제로는 embedding되는 어떤 임의의 실수 vector)을 붙입니다. *모델의 모든 파라미터는 가중치를 고정하고, prompt부분만 학습을 진행하는 것으로 학습하는 파라미터의 양이 많이 줄게됩니다.
이때, 아래와 같은 고려사항이 있을 수 있습니다:
- Prompt 표현의 초기값을 무엇으로 할 것인가?
Prompt 표현의 초기값을 설정하는 데는 3가지 방법이 있습니다. 첫번째는 무작위 초기화(random initialization)를 사용해 처음부터 모델을 훈련하는 것입니다. 두번째 방법은 개별 프롬프트 토큰을 모델의 vocabulary에서 추출한 임베딩으로 초기화하는 것입니다. 마지막으로는 프롬프트의 출력 클래스를 나열하는 임베딩으로 초기화하는 방법입니다.
테스트 결과에 따스면, 무작위 초기화를 해주는 것보다 vocabulary 또는 출력 클래스의 임베딩으로 초기화를 해주는 것이 더 좋은 성능이 나왔습니다.
- Prompt의 길이를 얼마로 할 것인가?
Prompt의 길이를 위한 파라미터의 비용은 EP로 계산합니다. E는 토큰 임베딩의 차원이고, P는 프롬프트의 길이입니다. 프롬프트의 길이가 더 짧을수록, 새로운 파라미터가 더 적게 튜닝되어야 합니다. 연구 결과의 따르면, Prompt의 길이는 5~100사이의 값이 적절한 것으로 나왔습니다. *Prompt의 길이가 길면 더 다양한 Task에 맞춰서 Tuning할 수 있다는 장점이 있지만, 더 많은 양의 파라미터를 Tuning해야하기 때문에 비용이 더 많이 듭니다.
(Soft) Prompt Tuning Results
Prompt Tuning의 성능은 위 그림과 같습니다. Prompt Tuning은 모델의 크기가 커질수록 성능이 향상됩니다. 특히, 모델의 크기가 수십억 개의 파라미터를 초과하는 경우, Model Tuning과 거의 동일한 성능을 보입니다. *모델 자체의 크기가 크다면, 각각의 태스크를 위한 Full Parameter Tuning은 너무 과하다는 것을 의미합니다.
위 그림은 파인 튜닝에 필요한 파라미터의 개수를 비교한 결과입니다. Model Tuning이 100%의 파라미터를 갖고 있다면, Prompt Tuning은 0.001%의 파라미터를 가지고 Model Tuning만큼의 성능을 보일 수 있습니다. Prefix Tuning이 0.1%의 파라미터를 학습하는 것과 비교할 때, Prompt Tuning은 아주 적은 파라미터로 효율적인 Fine-tuning이 가능해집니다. 즉, Prompt Tuning이 대규모의 언어모델을 특정한 다운스트림 태스크에 적용하는 데 효율적으로 사용될 수 있습니다.
Prefix Tuning
Prompt Tuning과 비슷한 아이디어에서 시작한 이 개념은 Prefix를 잘 찾아주면 좋은 Prompt가 되고, 이렇게 좋은 Prompt를 찾을 수 있다면 LLM 대답의 퀄리티가 좋아진다는 것이 주요 포인트입니다. Prompt Tuning과 마찬가지로 '좋은 Prefix'를 찾기 위해서 '학습'을 진행합니다. 기존의 역전파 방식을 그대로 사용하되, Gradient를 받는 주체가 모델 파라미터가 아닌 Prefix만 된다는 차이만 있습니다.
하지만 이때, Prefix vector를 바로 학습하는 것은 실험적으로 성능이 좋지 못했기 때문에, Prametrization을 사용합니다. 즉, MLP를 사용해서 Prefix를 찾아주는 것인데, 그림으로 표현하면 다음과 같습니다:
P를 직접 찾는 것이 아닌, MLP를 학습하여 나온 Feature를 사용하겠다는 의미입니다.
위 그림은 Fine Tuning과 Prefix Tuninf 방법의 학습 파라미터를 비교하는 그림입니다. 위쪽의 Fine Tuning을 보면 각 Task별로 Transformer 전체를 재학습하는 모습을 표현하고 있습니다. 엄청 많은 학습 파라미터가 표현된 모습인데 반해, Prefix Tuning에서는 앞쪽 Prefix만 학습해주고 있습니다. Task별로 아주 적은 Prefix 파라미터만 학습하면 되기에 매우 효율적임을 알 수 있습니다.
다른 방법들과의 비교
Prefix Tuning vs Prompt Tuning
Prefix Tuning은 모든 트랜스포머 레이어에 접두어 시퀀스를 붙여 학습하는 방법으로, Prefix Tuning은 트랜스포머의 모든 계층에 접두어를 붙이는 반면 (아래 그림 참조), Prompt Tuning은 input앞에 접두어를 붙여 하나의 프롬프트 표현을 사용합니다. 즉, Prompt Tuning은 Prefix Tuning보다 더 적은 파라미터로 모델의 Fine-Tuning이 가능합니다. 예를 들어, BART를 사용할 때, Prefix Tuning은 인코더와 디코더 네트워크에 모두 접두사를 붙이지만, Prompt Tuning은 인코더의 프롬프트에만 접두어를 붙입니다.
P-Tuning
다른 PEFT로 P-Tuning도 있습니다.
P-Tuning은 간단히 말해, 인간이 디자인한 패터을 사용해 학습이 가능한 연속적인 Prompt를 input전체에 삽입하는 방법입니다. P-tuning은 입력 전체에 연속적인 prompt를 삽입하는 반면, Prompt Tuning은 접두어로 붙이기 때문에 P-tuning보다 단순해집니다. 또한 P-Tuning은 프롬프트와 모델의 주요 파라미터를 같이 업데이트하는 반면, Prompt Tuning은 언어모델을 고정된 상태로 사용하기 때문에 더 효율적입니다.
P-tuning에 대한 자세한 내용은 아래의 블로그를..
https://ghqls0210.tistory.com/337
P-Tuning
P-Tuning은 아래 논문에서 처음 소개되었습니다. https://arxiv.org/pdf/2103.10385.pdf 논문 제목이 GPT Understands, too 인데 그 이유는 GPT 모델의 경우, 논문이 나온 당시 GPT 모델은 NLI (Natural Language Inference), AE (
ghqls0210.tistory.com
참고자료
https://arxiv.org/abs/2101.00190
Prefix-Tuning: Optimizing Continuous Prompts for Generation
Fine-tuning is the de facto way to leverage large pretrained language models to perform downstream tasks. However, it modifies all the language model parameters and therefore necessitates storing a full copy for each task. In this paper, we propose prefix-
arxiv.org
https://arxiv.org/abs/2104.08691
The Power of Scale for Parameter-Efficient Prompt Tuning
In this work, we explore "prompt tuning", a simple yet effective mechanism for learning "soft prompts" to condition frozen language models to perform specific downstream tasks. Unlike the discrete text prompts used by GPT-3, soft prompts are learned throug
arxiv.org
https://blog.harampark.com/blog/llm-prompt-tuning/
논문 리뷰 | PEFT의 대표적인 사례인 Prompt Tuning 알아보기
HuggingFace의 PEFT 중 하나로 지원하는 Prompt Tuning에 대해 알아보자. Prompt Tuning을 제안한 논문인 The Power of Scale for Parameter-Efficient Prompt Tuning을 읽고 리뷰한다.
blog.harampark.com
https://ffighting.net/deep-learning-paper-review/language-model/prefix-tuning/
[논문 리뷰] Prefix Tuning: Optimizing Continuous Prompts for Generation
효율적으로 LLM을 문제에 맞게 학습하는 방법중 하나인 Prefix Tuning 논문을 쉽게 설명합니다. 기존 Fine Tuning, Adapter 등의 PEFT 방식과 Prefix Tuning은 무엇이 다른지 그림을 통해 쉽게 이해해봅니다.
ffighting.net
https://stydy-sturdy.tistory.com/45
[딥러닝 이론] Prompt Tuning VS Prefix Tuning
시험기간이 끝나고 오랜만에 글을 써본다. 내 공부는 꾸준히 하고 있었지만 시험 기간이 겹쳐 글을 쓸 시간이 도저히 없었다. (핑계..) 오늘은 여러 논문들을 들으며 헷갈렸던 개념들, 특히 'Visual
stydy-sturdy.tistory.com