
https://arxiv.org/abs/2005.11401
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Large pre-trained language models have been shown to store factual knowledge in their parameters, and achieve state-of-the-art results when fine-tuned on downstream NLP tasks. However, their ability to access and precisely manipulate knowledge is still lim
arxiv.org
Abstract.
기존의 Pre-trained language model은 factual knowledge들을 매개변수에 저장하고 downstream NLP task에 맞게 fine-tuning을 했을 때, 굉장히 좋은 성능을 보였습니다.
하지만, 매우 정교하게 지식들을 조작하는 능혁은 제한되었습니다. 즉, knowledge-intensive task에서는 그 task에 맞는 architecture를 갖는 모델에 비해 성능이 떨어졌습니다.
게다가, 모델의 결정에 대한 출처를 제공하거나 새로운 지식을 업데이트하는 것 또한 열린 과제로 남아있었습니다.
*기존 parametric model은 새로운 지식을 습득하기 위해서는 새로운 데이터를 이용해서 parameter tuning을 했어야 했지만, RAG모델의 경우에는 non-parametric memory만 수정하면 되기 때문에 비용이 값쌉니다.
그래서 이 논문에서는 언어 생성을 위해 Pre-trained model과 non-parametric memory를 결합한 Retrieval-Augmented Generation(RAG)를 제안합니다. 이 논문에서는 두 가지 RAG방법론을 소개합니다:
- 같은 retrieved passage들을 통해 하나의 전체 문장을 생성하는 방법
- 한 토큰마다 retrieved passage들이 달라질 수 있는 방법
RAG방법은 광범위한 지식 집약형 NLP task에 대해서 평가되었고, open domain QA task에서 SOTA를 달성했습니다. 언어 생성의 측면에서는 RAG모델은 기존의 seq2seq baseline모델에 비해 좀 더 구체적이고 다양하며 사실에 기반한 언어들을 생성함을 발견했습니다.
Introduction.
기존의 Pre-trained language model은 상당한 양의 지식을 데이터로부터 습득하고, 또한 암시적인 지식 기반으로서 외부 메모리에 접근하지 않고 이를 가능하게 했습니다. 하지만 이런 방법은 흥미롭지만, 다음과 같은 단점들이 존재했습니다:
- 기존 모델들은 그들의 지식을 쉽게 수정하거나 확장할 수 없습니다. *앞서 말했듯 매개변수로 저장되어있는 지식들을 수정하기는 비용이 많이 들고 힘든 작업입니다.
- 그리고 기존 모델들의 예측에 도움이 되는 insight들을 직접적으로 모델에 제공할 수 없습니다. *어떤 태스크에 대한 직접적인 직관들을 모델에 직접 주입할 수 없고, tuning을 통해서만 주입할 수 있기 때문입니다.
- 마지막으로, "환각"을 불러일으킬 수 있습니다.
매개변수화한 메모리와 비-매개변수화된 메모리의 결합을 통한 모델은 다음과 같은 단점을을 극복할 수 있었고, 최근에 제안된 REALM이나 ORQA는 꽤 유망한 성능을 보였습니다. 하지만 open-domain QA에서는 그리 좋지 못했습니다.
그래서 이 논문에서는 retrieval-augmented generation(RAG)라고 불리는 범용적인 목적의 fine-tuning을 통해 pre-trained된 모델에 non-parametric memory를 부여했습니다. 여기서 parametric memory는 사전학습된 seq2seq transformer를 말하고, non-parametric memory는 Wikipedia의 dense vector를 의미합니다.

the retriever(Dense Passage Retriever, henceforth DPR)은 사용자 입력에 따른 잠재적인 문서들(*non-parametric memory)을 제공하고, 이에 seq2seq model(BART)는 잠재적인 문서들과 입력을 함께 출력을 생성하기 위한 조건으로 입력합니다.
앞서 말했던 두 가지 방법에 따라(a per-output basis or a per-token basis) top-k근사치에 해당하는 잠재 문서들을 뽑아냅니다.
이전에는 특정한 task에 맞는 non-parametric memory를 활용하는 architecture들을 많이 제안했었습니다. 하지만 제시한 방법은 광범위한 양의 지식에 대한 학습을 parametric과 non-parametric memory를 통해 학습합니다. 중요한 점은 pre-trained access mechanism을 활용하면 지식에 접근하는 능력을 추가 학습 없이 사용할 수 있다는 점입니다. *여기서 강조하는 점은 RAG는 task specific한 architecture가 아니라는 점입니다. 광범위한 지식을 non-parametric하게 접근하기 때문에 task에 대한 추가 학습 없이 지식에 접근할 수 있는 능력을 지녔다고 말합니다.
제시한 방법론은 parametric과 non-prametric memory를 결합함으로써 일반 사람이라면 외부적인 참조자료가 없다면 불가능한 지식 집약형 task에 대해 좋은 성능을 보인다는 점입니다.
Methods.
Input sequence x를 사용하여 text passage z를 검색하고 target sequence y를 생성하는 RAG model은 다음 두개의 component를 활용합니다:
- query x에 대해 distribution을 반환하는 parameter η 를 가진 retriever
Retriever 및 generator를 end-to-end로 학습하기 위해 검색된 document를 latent variable로 간주합니다. *이는 위 식에서 document를 z라는 variable로 간주한 이유입니다.
이 논문에서는 생성된 택스트에 대한 distribution을 생성하기 위해 latent document에 대해 다른 방식으로 marginalization하는 두 방식을 소개합니다:
- RAG-Sequence: 모델은 동일한 문서를 사용하여 각 target token을 예측
- RAG-Token: 모델이 다른 문서를 기반으로 각 target token을 예측
Models.
RAG-Sequence Model.
RAG-Sequence Model은 동일하게 검색된 문서를 이용하여 target sequence를 생성합니다. top-k approximation을 통해 seq2seq probability p(x|y)를 얻기위해 검색된 passage를 marginalized single latent variable로 처리합니다.
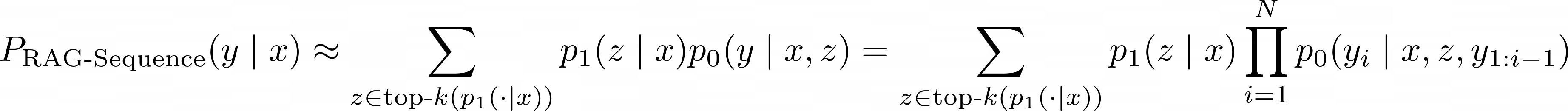
RAG-Token Model
RAG-Token Model은 각 target token에 대해 다른 latent passage를 사용합니다. 이를 통해 generator는 답변을 생성할 때 여러 document에서 내용을 선택할 수 있습니다. RAG는 target 길이가 1인 sequence로 간주하여 sequence classification task에도 사용할 수 있으며, 이 경우 RAG-Sequence와 RAG-Token은 동일합니다.

Retriever: DPR.
검색에 관한 component인 pη(z∣x)는 DPR을 기준으로 하며 DPR은 bi-encoder architecture를 따릅니다.

여기서 d(z)는 BERT transformer에 의해 생성된 document의 dense representation이고 q(x)는 다른 매개변수를 가진 BERT transformer에 의해 생성된 query representation입니다.
가장 높은 prior probabiliy pη(z∣x)를 갖는 k개의 요소 z의 리스트 top−k(pη(⋅∣x))를 효율적으로 계산하기 위해 FAISS라이브러리에서 제공하는 MIPS(Maximum Inner Product Search) index를 사용합니다.
Generator: BART.
Generator의 component인 pθ(yi∣x,z,y1:i−1)은 BART의 encoder, decoder를 사용하여 모델링하며 400M parameter를 가진 BART-large를 사용합니다. BART를 통해 생성할 때 input x와 검색된 컨텐츠 z를 결합하기 위해서는 간단하게 concetenation을 사용합니다.
Training.
검색할 document에 대해서는 학습하지 않고 Retriever와 Generator를 공동으로 학습합니다. 입력/출력 쌍 (xj,yj)가 주어지면 Adam을 통해 ∑j−logp(yj∣xj)를 minimize합니다.
학습 중 document encoder를 업데이트하면 document indexing을 정기적으로 업데이트 해야하므로 비용이 많이 소모됩니다. 그래서 query encoder와 generator를 fine-tuning하고 document encoder를 고정상태로 유지합니다.
Decoding.
Test및 decoding 단계에서 RAG-Sequence와 RAG-Token은 argmax p(y|x)를 근사하는 다른 방법을 필요로 합니다.
- RAG-Token
RAG-Token Model은 transition probability를 가진 auto-regressive seq2seq generator로 볼 수 있습니다.
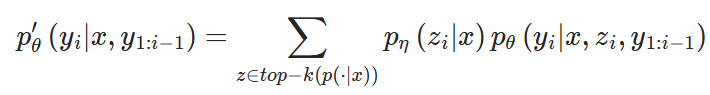
Decoding단계에서 pθ′(yi∣x,y1:i−1)을 사용해서 standard beam decoder를 사용할 수 있습니다.
- RAG-Sequence
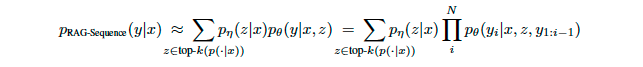
RAG-Sequence의 경우, sequence를 끝까지 생성한 이후 document에 대해 marginalize를 진행하기에 기존 beam search 방법론을 적용할 수 없다는 문제가 생깁니다.
그래서 논문에서는 document별로 beam search를 진행합니다.
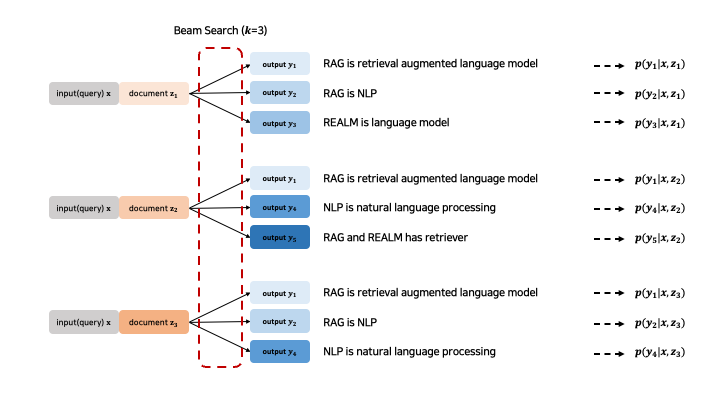
input x가 주어질 때, 이에대한 top-k document를 retrieve하게 됩니다. 여기서는 top-k를 3으로 설정했기 때문에, 3개의 document가 활용되는 것을 확인할 수 있습니다.
그 다음으로는, 각각의 document별로 beam search를 진행합니다. 즉, 하나의 input x와 document z별로 logit이 높은 순서로 k개의 sequence를 생성합니다.
이 과정을 거치면 예시의 맨 오른쪽처럼 각각의 document와 output에 대한 p(y|x,z)가 구해지게 됩니다. 이를 document z에 대해 marginalize를 함으로써 최종 p(y|x)를 구하게 되는데 이는 아래와 같습니다:

그런데, 여기서 문제가 발생합니다. 아래 수식에서 빨간색 확률들을 살펴보면, 해당 확률들은 beam search 과정에서 발견되지 않은 값들입니다.
p(y2|x, z2)의 경우를 살펴보면, 해당 확률은 x와 z2가 주어졌을 때 output으로 y2가 나올 확률입니다. 그러나 좌측 상단의 beam search 과정, 혹은 이전 예시의 사진에서 볼 수 있듯이 y2는 document z2로부터 산출된 적이 없습니다.
따라서 이에 대한 확률 값을 모른다는 문제가 발생합니다. p(y2|x,z2)값을 모르기 때문에 당연히 이를 marginalize할 수 없고, 결과적으로는 p(y2|x)값을 구할 수 없게 되는 것입니다.
이를 계산하기 위해서는 p(y2|x,z2)와 같이 발견되지 않은 값들에 대해 additional forward, 즉 추가적으로 model에 입력을 넣어서 해당 값을 산출해야합니다. 그러나, 이 과정은 비용적으로나, 시간적으로나 매우 비효율적이기 때문에 해당 논문에서는 해당 값들을 0으로 처리하는 Fast Decoding방식을 제안합니다.

'[Deep daiv.] > [Deep daiv.] NLP' 카테고리의 다른 글
https://arxiv.org/abs/2005.11401
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Large pre-trained language models have been shown to store factual knowledge in their parameters, and achieve state-of-the-art results when fine-tuned on downstream NLP tasks. However, their ability to access and precisely manipulate knowledge is still lim
arxiv.org
Abstract.
기존의 Pre-trained language model은 factual knowledge들을 매개변수에 저장하고 downstream NLP task에 맞게 fine-tuning을 했을 때, 굉장히 좋은 성능을 보였습니다.
하지만, 매우 정교하게 지식들을 조작하는 능혁은 제한되었습니다. 즉, knowledge-intensive task에서는 그 task에 맞는 architecture를 갖는 모델에 비해 성능이 떨어졌습니다.
게다가, 모델의 결정에 대한 출처를 제공하거나 새로운 지식을 업데이트하는 것 또한 열린 과제로 남아있었습니다.
*기존 parametric model은 새로운 지식을 습득하기 위해서는 새로운 데이터를 이용해서 parameter tuning을 했어야 했지만, RAG모델의 경우에는 non-parametric memory만 수정하면 되기 때문에 비용이 값쌉니다.
그래서 이 논문에서는 언어 생성을 위해 Pre-trained model과 non-parametric memory를 결합한 Retrieval-Augmented Generation(RAG)를 제안합니다. 이 논문에서는 두 가지 RAG방법론을 소개합니다:
- 같은 retrieved passage들을 통해 하나의 전체 문장을 생성하는 방법
- 한 토큰마다 retrieved passage들이 달라질 수 있는 방법
RAG방법은 광범위한 지식 집약형 NLP task에 대해서 평가되었고, open domain QA task에서 SOTA를 달성했습니다. 언어 생성의 측면에서는 RAG모델은 기존의 seq2seq baseline모델에 비해 좀 더 구체적이고 다양하며 사실에 기반한 언어들을 생성함을 발견했습니다.
Introduction.
기존의 Pre-trained language model은 상당한 양의 지식을 데이터로부터 습득하고, 또한 암시적인 지식 기반으로서 외부 메모리에 접근하지 않고 이를 가능하게 했습니다. 하지만 이런 방법은 흥미롭지만, 다음과 같은 단점들이 존재했습니다:
- 기존 모델들은 그들의 지식을 쉽게 수정하거나 확장할 수 없습니다. *앞서 말했듯 매개변수로 저장되어있는 지식들을 수정하기는 비용이 많이 들고 힘든 작업입니다.
- 그리고 기존 모델들의 예측에 도움이 되는 insight들을 직접적으로 모델에 제공할 수 없습니다. *어떤 태스크에 대한 직접적인 직관들을 모델에 직접 주입할 수 없고, tuning을 통해서만 주입할 수 있기 때문입니다.
- 마지막으로, "환각"을 불러일으킬 수 있습니다.
매개변수화한 메모리와 비-매개변수화된 메모리의 결합을 통한 모델은 다음과 같은 단점을을 극복할 수 있었고, 최근에 제안된 REALM이나 ORQA는 꽤 유망한 성능을 보였습니다. 하지만 open-domain QA에서는 그리 좋지 못했습니다.
그래서 이 논문에서는 retrieval-augmented generation(RAG)라고 불리는 범용적인 목적의 fine-tuning을 통해 pre-trained된 모델에 non-parametric memory를 부여했습니다. 여기서 parametric memory는 사전학습된 seq2seq transformer를 말하고, non-parametric memory는 Wikipedia의 dense vector를 의미합니다.
the retriever(Dense Passage Retriever, henceforth DPR)은 사용자 입력에 따른 잠재적인 문서들(*non-parametric memory)을 제공하고, 이에 seq2seq model(BART)는 잠재적인 문서들과 입력을 함께 출력을 생성하기 위한 조건으로 입력합니다.
앞서 말했던 두 가지 방법에 따라(a per-output basis or a per-token basis) top-k근사치에 해당하는 잠재 문서들을 뽑아냅니다.
이전에는 특정한 task에 맞는 non-parametric memory를 활용하는 architecture들을 많이 제안했었습니다. 하지만 제시한 방법은 광범위한 양의 지식에 대한 학습을 parametric과 non-parametric memory를 통해 학습합니다. 중요한 점은 pre-trained access mechanism을 활용하면 지식에 접근하는 능력을 추가 학습 없이 사용할 수 있다는 점입니다. *여기서 강조하는 점은 RAG는 task specific한 architecture가 아니라는 점입니다. 광범위한 지식을 non-parametric하게 접근하기 때문에 task에 대한 추가 학습 없이 지식에 접근할 수 있는 능력을 지녔다고 말합니다.
제시한 방법론은 parametric과 non-prametric memory를 결합함으로써 일반 사람이라면 외부적인 참조자료가 없다면 불가능한 지식 집약형 task에 대해 좋은 성능을 보인다는 점입니다.
Methods.
Input sequence x를 사용하여 text passage z를 검색하고 target sequence y를 생성하는 RAG model은 다음 두개의 component를 활용합니다:
- query x에 대해 distribution을 반환하는 parameter η 를 가진 retriever
Retriever 및 generator를 end-to-end로 학습하기 위해 검색된 document를 latent variable로 간주합니다. *이는 위 식에서 document를 z라는 variable로 간주한 이유입니다.
이 논문에서는 생성된 택스트에 대한 distribution을 생성하기 위해 latent document에 대해 다른 방식으로 marginalization하는 두 방식을 소개합니다:
- RAG-Sequence: 모델은 동일한 문서를 사용하여 각 target token을 예측
- RAG-Token: 모델이 다른 문서를 기반으로 각 target token을 예측
Models.
RAG-Sequence Model.
RAG-Sequence Model은 동일하게 검색된 문서를 이용하여 target sequence를 생성합니다. top-k approximation을 통해 seq2seq probability p(x|y)를 얻기위해 검색된 passage를 marginalized single latent variable로 처리합니다.
RAG-Token Model
RAG-Token Model은 각 target token에 대해 다른 latent passage를 사용합니다. 이를 통해 generator는 답변을 생성할 때 여러 document에서 내용을 선택할 수 있습니다. RAG는 target 길이가 1인 sequence로 간주하여 sequence classification task에도 사용할 수 있으며, 이 경우 RAG-Sequence와 RAG-Token은 동일합니다.
Retriever: DPR.
검색에 관한 component인 pη(z∣x)는 DPR을 기준으로 하며 DPR은 bi-encoder architecture를 따릅니다.
여기서 d(z)는 BERT transformer에 의해 생성된 document의 dense representation이고 q(x)는 다른 매개변수를 가진 BERT transformer에 의해 생성된 query representation입니다.
가장 높은 prior probabiliy pη(z∣x)를 갖는 k개의 요소 z의 리스트 top−k(pη(⋅∣x))를 효율적으로 계산하기 위해 FAISS라이브러리에서 제공하는 MIPS(Maximum Inner Product Search) index를 사용합니다.
Generator: BART.
Generator의 component인 pθ(yi∣x,z,y1:i−1)은 BART의 encoder, decoder를 사용하여 모델링하며 400M parameter를 가진 BART-large를 사용합니다. BART를 통해 생성할 때 input x와 검색된 컨텐츠 z를 결합하기 위해서는 간단하게 concetenation을 사용합니다.
Training.
검색할 document에 대해서는 학습하지 않고 Retriever와 Generator를 공동으로 학습합니다. 입력/출력 쌍 (xj,yj)가 주어지면 Adam을 통해 ∑j−logp(yj∣xj)를 minimize합니다.
학습 중 document encoder를 업데이트하면 document indexing을 정기적으로 업데이트 해야하므로 비용이 많이 소모됩니다. 그래서 query encoder와 generator를 fine-tuning하고 document encoder를 고정상태로 유지합니다.
Decoding.
Test및 decoding 단계에서 RAG-Sequence와 RAG-Token은 argmax p(y|x)를 근사하는 다른 방법을 필요로 합니다.
- RAG-Token
RAG-Token Model은 transition probability를 가진 auto-regressive seq2seq generator로 볼 수 있습니다.
Decoding단계에서 pθ′(yi∣x,y1:i−1)을 사용해서 standard beam decoder를 사용할 수 있습니다.
- RAG-Sequence
RAG-Sequence의 경우, sequence를 끝까지 생성한 이후 document에 대해 marginalize를 진행하기에 기존 beam search 방법론을 적용할 수 없다는 문제가 생깁니다.
그래서 논문에서는 document별로 beam search를 진행합니다.
input x가 주어질 때, 이에대한 top-k document를 retrieve하게 됩니다. 여기서는 top-k를 3으로 설정했기 때문에, 3개의 document가 활용되는 것을 확인할 수 있습니다.
그 다음으로는, 각각의 document별로 beam search를 진행합니다. 즉, 하나의 input x와 document z별로 logit이 높은 순서로 k개의 sequence를 생성합니다.
이 과정을 거치면 예시의 맨 오른쪽처럼 각각의 document와 output에 대한 p(y|x,z)가 구해지게 됩니다. 이를 document z에 대해 marginalize를 함으로써 최종 p(y|x)를 구하게 되는데 이는 아래와 같습니다:
그런데, 여기서 문제가 발생합니다. 아래 수식에서 빨간색 확률들을 살펴보면, 해당 확률들은 beam search 과정에서 발견되지 않은 값들입니다.
p(y2|x, z2)의 경우를 살펴보면, 해당 확률은 x와 z2가 주어졌을 때 output으로 y2가 나올 확률입니다. 그러나 좌측 상단의 beam search 과정, 혹은 이전 예시의 사진에서 볼 수 있듯이 y2는 document z2로부터 산출된 적이 없습니다.
따라서 이에 대한 확률 값을 모른다는 문제가 발생합니다. p(y2|x,z2)값을 모르기 때문에 당연히 이를 marginalize할 수 없고, 결과적으로는 p(y2|x)값을 구할 수 없게 되는 것입니다.
이를 계산하기 위해서는 p(y2|x,z2)와 같이 발견되지 않은 값들에 대해 additional forward, 즉 추가적으로 model에 입력을 넣어서 해당 값을 산출해야합니다. 그러나, 이 과정은 비용적으로나, 시간적으로나 매우 비효율적이기 때문에 해당 논문에서는 해당 값들을 0으로 처리하는 Fast Decoding방식을 제안합니다.