
Deadlock Handling
system이 deadlocked되었다는 것은 일련의 transaction들이 서로 상대방이 lock을 해제하기를 무한정 기다리는 상황을 의미합니다. 대부분의 locking protocol에서는 deadlock의 발생가능성이 항상 있습니다.
2025.06.06 - [[학교 수업]/[학교 수업] Database] - [Database] Concurrency Control
[Database] Concurrency Control
Concurrency control Concurrency control의 목표는 DBMS가 Serializable하고 Recoverable하며 가급적이면 Cascadeless인 스케줄을 생성하도록 스케줄링 결정을 내리는 것입니다.2025.05.25 - [[학교 수업]/[학교 수업] Databa
hw-hk.tistory.com
Deadlock Prevention
deadlock prevention은 시스템이 절대 deadlock 상태에 빠지지 않도록 보장하는 프로토콜입니다. 여기에는 몇 가지 deadlock 방지 전략이 존재합니다:
- pre-declaration: 각 transaction이 실행을 시작하기 전에 필요한 모든 data item에 대한 모든 lock을 획득하도록 요구합니다. *hold and wait 방지
- Graph-based protocol: 그래프 기반 프로토콜과 같이 모든 데이터에 대해 partial ordering을 부여하고, transaction이 이 순서에 따라서만 데이터에 lock을 획득하도록 요구합니다. *circular wait 방지
- wait-die scheme(non-preemptive): older transaction은 younger transaction이 테이터 항목의 lock을 해제할 때까지 기다릴 수 있지만, younger transaction은 older transaction을 기다리지 않고 즉시 rollback(die) 됩니다. rollback된 transaction은 원래의 timestamp를 가지고 재시작됩니다.
- wound-wait scheme(preemptive): older transaction은 younger transaction을 기다리는 대신 강제로 rollback(wound)시킬 수 있습니다. younger transaction은 older transaction을 기다립니다. 이 방식은 wait-die보다 rollback 횟수가 적습니다.
- Timeout-based schemes: transaction이 lock을 기다리는 시간을 특정 값으로 제한합니다. 기다리는 시간이 초과되면 transaction을 rollback됩니다. 구현은 간단하지만, deadlock 상태가 아니어도 불필요한 rollback이 발생할 수 있으며, 적절한 timeout value를 선택하기 어려우며, starvation의 발생 가능성도 있습니다.
*wait-die, wound-wait 방식 모두 older transaction에게 우선권을 줌으로써 starvation을 해결합니다.
Deadlock Detection
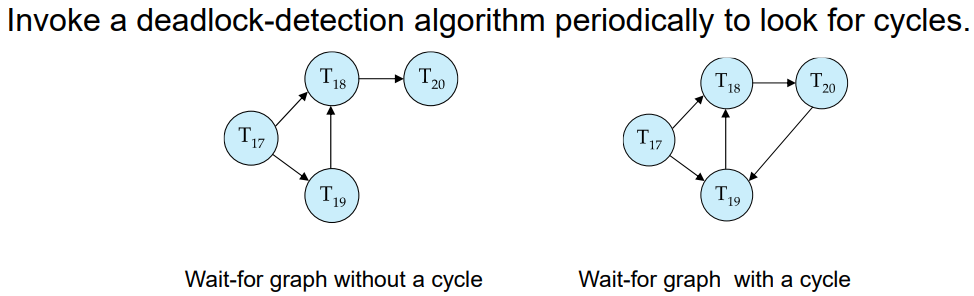
시스템이 deadlock 상태에 진입하는 것을 허용하되, 주기적으로 deadlock 상태 발생 여부를 확인합니다. 이를 위해 wait-for graph를 이용합니다.
이는 transaction을 정점으로 하여, Ti가 Tj가 가지고 있는 lock을 기다리고 있다면 Ti에서 Tj로 향하는 간선을 그릴 수 있습니다. 그리고 wait-for graph에 사이클이 존재하는 경우에만 시스템은 deadlock 상태에 있다고 가정합니다. 주기적인 cycle 생성 여부 알고리즘을 실행하여 사이클을 찾습니다.
Deadlock Recovery
deadlock이 발견되면 사이클을 깨기 위해 하나 이상의 transaction을 victim으로 선택하여 rollback을 수행합니다. 희생자 선택시 최소 비용을 발생시키는 transaction을 선택하는 등의 기준이 사용될 수 있습니다.
(1) Total rollback은 모든 transaction을 abort하고 재시작하는 방법, (2) Partial rollback은 사이클 내 다른 transaction이 기다리는 lock을 해제할 만큼만 rollback하는 방법입니다. victim 선정 방식이 잘못되면 starvation이 발생할 수 있으므로, 예를 들어 deadlock transaction 집합에서 가장 오래된 transaction을 희생자로 선택하지 않는 방법들을 선택할 수 있습니다.
*older transaction먼저 commit할 수 있게 하면 starvation이 발생하지 않는다. 그래서 wait-die, wound-wait방식 모두 older transaction에게 우선권을 줘서 starvation이 발생하지 않았던 것이다.
Multiple Granularity
데이터 항목을 다양한 크기로 허용하고 계층 구조로 조직화하여, 여러 수준의 데이터 항목에 대한 locking을 가능하게 합니다. small granularity는 larger one에 중첩될 수 있고 이는 트리 구조로 표현할 수 있습니다.
transaction이 명시적으로 특정 노드에 lock을 걸면, 해당 노드의 모든 하위 노드에도 동일한 모드로 implicit하게 lock이 걸립니다. granularity of locking은 트리의 어느 수준에서 locking을 수행하는지를 의미하며, 이는 concurrency 및 overhead와 trade off를 갖습니다. *fine granularity는 높은 동시성을 제공하지만 locking overhead가 높습니다. 반면에 Coarse granularity는 낮은 동시성을 제공하지만 locking overhead가 낮습니다.
*Multiple Granularity locking protocol이 필요한 이유
왜 “Multiple Granularity Locking(다중 세분화 잠금)”이 필요할까?
- 잠금 단위(Granularity)마다 장-단점이 뚜렷하다
- 세밀한 잠금(레코드·페이지) → 동시성↑ 하지만 트랜잭션이 수천 개 잠금을 들고 있으면 락 테이블 관리·메시지 왕복 비용이 커진다.
- 거친 잠금(테이블·DB 전체) → 관리 비용↓ 하지만 한 트랜잭션이 테이블 전체를 막아 버리면 다른 트랜잭션은 대기 → 병행성↓.
→ Multiple Granularity는 두 극단 사이를 자유롭게 오가도록 해 “높은 동시성과 낮은 오버헤드를 동시에 달성”하려는 설계다 23.Concurrency-2.
- 의도 잠금(Intention Locks)이 상위 노드 충돌 여부를 빠르게 판정
- S/X 외에 IS, IX, SIX 모드를 도입해 “아래 단계에서 더 세밀한 잠금을 잡을 의도가 있다”는 사실만 상위 노드에 표시한다.
- DBMS는 상위 노드 하나만 검사해도 충돌 유무를 알 수 있으므로, 행 단위로 내려가 직접 확인할 필요가 없다 23.Concurrency-2.
- “스캔 vs. 단일 행 수정” 같이 성격이 다른 트랜잭션을 자연스럽게 공존
- 예) 대량 조회 T₁: 테이블에 S 잠금 → 레코드들은 건드리지 않음.
- 예) 단일 업데이트 T₂: 테이블에 IX 잠금 + 수정할 행에 X 잠금.
- 두 트랜잭션이 동시에 진행될 수 있다. 과거에는 T₂가 테이블 전체를 X-lock 하거나 T₁이 모든 행을 S-lock 하는 식의 극단적 선택뿐이었다.
- Lock Escalation/De-escalation
- 트랜잭션이 “행 수백 개”를 잠근 순간 시스템이 자동으로 “테이블 S/X 락”으로 승격(escalation) → 락 개수·메모리 사용량 급감.
- 반대로 “작업 범위가 줄면” 더 세밀한 잠금으로 하향(de-escalation) 가능 23.Concurrency-2.
- 팬텀(phantom)·인덱스 잠금과도 궁합이 좋다
- 범위 스캔 시 테이블 IS + 인덱스의 리프 노드 S 잠금으로 팬텀 현상을 제어.
- 행 삽입·삭제는 IX + 인덱스 리프 노드 X 잠금이어서 충돌을 정확히 감지한다 23.Concurrency-2.
- 어떤 프로토콜과도 결합 가능
- 2PL(Strict 2PL 등)의 “growing/shrinking” 규칙을 그대로 적용하면서 노드 간 root→leaf 순서만 지키면 된다.
- Tree protocol과 달리 S-락도 허용하므로 범용 트랜잭션에 활용 가능.

Intention lock modes
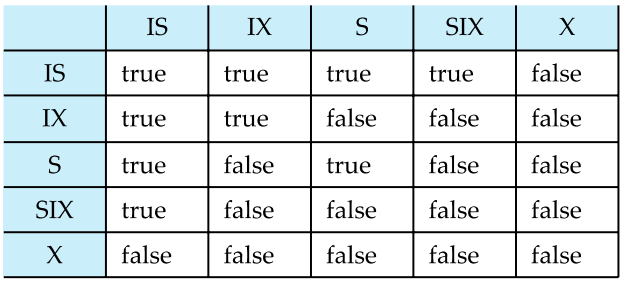
lock mode에 S(Shared)와 X(eXclusive)모드 외에 IS, IX, SIX 모드가 추가됩니다. 이들은 하위 수준에서 locking이 수행될 것임을 나타내며, 상위 노드를 S 또는 X 모드로 locking할 때 하위 노드 전체를 검사할 필요가 없게 합니다.
- intention-shared (IS): 하위 수준에서 shared lock만 명시적으로 걸 것임을 나타냅니다.
- intention-exclusive (IX): 하위 수준에서 shared 또는 exclusive lock을 명시적으로 걸 것임을 나타냅니다.
- shared and intention-exclusive (SIX): 해당 노드 자체가 shared lock을 걸고, 하위 수준에서 exclusive lock을 명시적으로 걸 것임을 나타냅니다.
GPT
1. Intention Lock(IL) 패밀리 ― 한 번 더 깊이 파보기
| IS | Intent Shared | 상위 노드만 “표지판” → 하위 객체에는 곧 S-Lock을 잡을 것 |
▸ 개별 행/페이지 읽기 ▸ 범위 조회 (S,-Locks 다수) |
모든 읽기와 호환, 쓰기(X)엔 충돌 |
| IX | Intent Exclusive | 상위 노드 표지판 → 하위에 X-Lock 예정 | ▸ 행/페이지 수정(UPDATE/DELETE) ▸ INSERT(새 레코드 X-Lock) |
다른 IX·IS와는 OK (다른 레코드 수정 허용) -- S·X와는 충돌 |
| S | Shared | 해당 노드 자체를 전체 읽기 전용 | ▸ 테이블 전체 스캔(백업 등) | 다른 S·IS와만 호환 |
| SIX | Shared-Intent Exclusive | 상위 노드 전체를 읽으면서 하위 일부엔 X-Lock 예정 |
▸ “테이블 전체 읽으면서 일부 행 수정” 쿼리(예: UPDATE … WHERE condition 큰 범위) | IS만 호환 (다른 읽기만 가능) 단 한 트랜잭션만 보유 가능 |
| X | Exclusive | 해당 노드 전체에 쓰기 | ▸ ALTER TABLE, 대량 갱신, 테이블 재빌드 | 그 어떤 락과도 호환 X |
- IS·IX·SIX 는 상위-노드 전용 “경고 표지판”. 실제 데이터는 하위 객체의 S/X 락으로 보호됩니다.
- 트리 최상위(root)까지 의도 락을 위→아래 방향으로 획득해야 2-PL 위반이 없습니다.
2. 작동 예시 ― 4 개의 현실적 상황
예시 A) 다른 행을 동시에 갱신·조회* (최소 충돌)
| ① 상위 표지판 | IX(table) | IS(table) | IS vs IX → true |
| ② 하위 락 | X(R₁) | S(R₂) | 다른 행 → 호환 |
| 결과 | 두 트랜잭션 동시에 진행 |
왜 가능? 상위엔 IX·IS만 있어도 서로 OK, 실제 충돌 여부는 행 단위에서 결정.
예시 B) 같은 행 갱신 vs 조회 (필연 충돌)
| ① IX(table) | IS(table) (호환) | |
| ② X(R₁) 이미 보유 | S(R₁) 요청 → 대기 (S vs X = false) | |
| 결과 | T₂가 대기 → 직렬 순서 보장 |
예시 C) 테이블-스캔(백업) 중에 행 업데이트 시도
| ① S(table) 획득 | (요청) IX(table) | |
| ② | IX vs S = false → T₂ 대기 | |
| 의미 | 백업 수행 중에는 어떠한 쓰기도 금지 |
예시 D) SIX 활용 시나리오 (대량 읽기 + 일부 수정)
- SIX(table Orders) : 테이블 전체는 읽기 공유,
그러나 “곧 특정 행에 X-Lock 들어갈 것” 신호. - 다른 트랜잭션들은 IS(table) 로 읽기만 허용 (단순 조회 OK).
다른 S·IX·SIX·X는 모두 충돌 → 대기 - T₁이 조건에 맞는 각 행에 X(Rᵢ) → 개별 행 수정.
- 커밋 시 상·하위 락 한꺼번에 해제.
SIX 장점:
대량 읽기 동안 “읽기-전용 동시성”은 유지하고,
선택적 행 수정도 가능하게 해 주는 타협안.
3. 의도 락의 규칙 & 미묘한 포인트
| 획득 경로 | 루트 → 리프 순서(상→하)로 잡고, 해제는 반대로 | 데드락 위험 감소 |
| 병합(Escalation) | 다수 행에 X-Lock 잡다 → DBMS가 자동으로 페이지 IX→X 또는 테이블 IX→X 승격 | 락 수 줄여 관리 오버헤드↓ 하지만 동시성도 함께 ↓ |
| 변환(Conversion) | IS → IX / IX → X 등 승격만 허용 (보통). 다른 트랜잭션과 충돌 시 대기 | 읽다 보니 수정해야 할 때 유용 |
| SIX 독점성 | 한 노드에 SIX는 1개만 허용. 또 다른 트랜잭션의 SIX·S·IX·X 모두 차단 | 조건-UPDATE 같은 중간 규모 변경 작업 보호 |
| 표지판 개념 | IS/IX는 데이터 보호 기능은 없음. 상위 노드에 “아래로 가면 충돌 위험 있으니 주의”라는 선언 |
상위 잠금으로 빠른 호환성 체크 → 트리 탐색 깊이 줄임 |
4. 정리
- 의도 락(IS, IX, SIX) 은 다중-그래뉼러리티 환경에서
“상위-노드 한 곳”만 보면 잠금 충돌 여부를 즉시 판단하도록 돕는 경고표지판. - Compatibility Matrix 는 이 다섯 모드의 동시 보유 가능성을 체계적으로 정의한다.
- 예시 A~D 처럼 의도 락 덕분에 다른 행/페이지/작업 간 동시성은 높이고,
같은 데이터/범위 충돌은 정확히 차단해 직렬성을 지켜 준다.
Multiple Granularity Locking Scheme
Transaction Ti가 node Q에 lock을 걸때 다음의 규칙을 지켜야합니다:
- root node가 가장 먼저 locking되어야 합니다.
- 특정 모드로 locking하려면 parent node가 특정 intention lock mode 혹은 S/X lock mode로 locking되어야 합니다.
- transaction은 2PL을 따라야합니다(즉, Ti는 lock을 얻을때, 이전에 unlock했으면 안됩니다).
- lock을 root에서 leaf방향으로 획득되며, leaf에서 root방향으로 해제됩니다.
- lock의 수가 많이지면 더 높은 세분성 수준의 lock으로 전환하는 lock granularity excalation이 있을 수 있습니다.
Insert/Delete Operations and predicate reads
데이터들을 삭제하거나 삽입하는 경우는 X-lock을 획득해야합니다(삽입하는 경우에는 automatically 얻습니다). 이러한 규칙은 읽기/쓰기 연산이 삭제와 (lock이) 충돌할 수 있도록 보장하며, 삽입된 tuple이 해당 transaction이 commit될 때까지 다른 transaction이 접근할 수 없도록 합니다.
Phantom Phenomenon
phantom phenomenon은 transaction이 조건을 만족하는 record 집합을 검색한 후, 다른 transaction이 조건을 만족하는 새로운 record를 삽입(또는 삭제/수정)하고 commit했을 때, 처음 transaction이 동일한 검색을 수행하면 결과 집합이 달라지는 현상입니다. 이것은 serialization anomaly의 한 형태입니다. 이는 tuple 수준의 locking만으로는 이 현상을 막을 수 없습니다. phantom phenomenon의 근본적인 문제는 tuple 존재에 대한 정보 자체가 공유되는 데이터 항목이기 때문입니다.


Handling Phantoms
- 관련된 table을 나타내는 데이터 항목에 lock을 거는 방식: 검색 transaction은 shared lock을, 삽입/삭제 transaction은 exclusive lock을 획득합니다. 하지만 이는 삽입/삭제 시 동시성을 매우 낮춥니다. *table, relation단위는 너무 크다.
- Index locking: 모든 테이블에 최소 하나의 index가 있다고 가정하고 index를 통해 tuple에 접근합니다. 검색을 수행하는 transaction은 접근하는 index leaf node에 S-lock을 획득합니다. 삽입/갱신/삭제를 수행하는 transaction은 영향을 받는 모든 index leaf node에 X-lock을 획득합니다. 이때는 2PL를 따라야하며, 이는 phantom phenomenon이 발생하지 않음을 보장합니다.
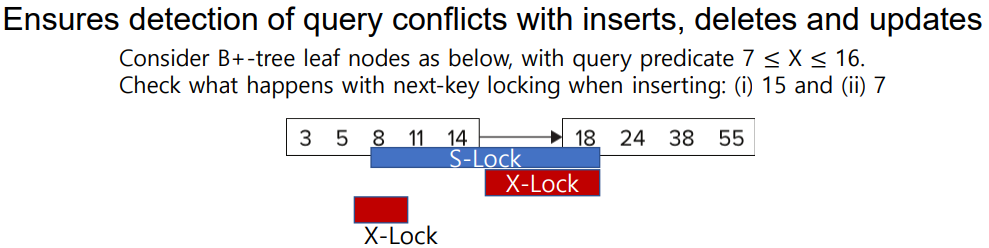
- Next-key locking: index locking의 단점(많은 삽입 시 낮은 동시성)을 개선한 b+-tree 기반 프로토콜입니다. lookup 조건을 만족하는 값들 뿐만 아니라, index 상에서 그 다음에 오는 next key value에도 lock을 겁니다. lookup에는 S-look을 삽입/삭제/갱신에는 X-lock을 사용합니다. 이를 통해 높은 동시성을 제공하며 phantom을 방지합니다.
'[학교 수업] > [학교 수업] Database' 카테고리의 다른 글
| [Database] Recovery (0) | 2025.06.10 |
|---|---|
| [Database] Concurrency Control (3) (0) | 2025.06.06 |
| [Database] Concurrency Control (1) | 2025.06.06 |
| [Database] Query Processing (0) | 2025.05.27 |
| [Database] LSM tree (0) | 2025.05.27 |
Deadlock Handling
system이 deadlocked되었다는 것은 일련의 transaction들이 서로 상대방이 lock을 해제하기를 무한정 기다리는 상황을 의미합니다. 대부분의 locking protocol에서는 deadlock의 발생가능성이 항상 있습니다.
2025.06.06 - [[학교 수업]/[학교 수업] Database] - [Database] Concurrency Control
[Database] Concurrency Control
Concurrency control Concurrency control의 목표는 DBMS가 Serializable하고 Recoverable하며 가급적이면 Cascadeless인 스케줄을 생성하도록 스케줄링 결정을 내리는 것입니다.2025.05.25 - [[학교 수업]/[학교 수업] Databa
hw-hk.tistory.com
Deadlock Prevention
deadlock prevention은 시스템이 절대 deadlock 상태에 빠지지 않도록 보장하는 프로토콜입니다. 여기에는 몇 가지 deadlock 방지 전략이 존재합니다:
- pre-declaration: 각 transaction이 실행을 시작하기 전에 필요한 모든 data item에 대한 모든 lock을 획득하도록 요구합니다. *hold and wait 방지
- Graph-based protocol: 그래프 기반 프로토콜과 같이 모든 데이터에 대해 partial ordering을 부여하고, transaction이 이 순서에 따라서만 데이터에 lock을 획득하도록 요구합니다. *circular wait 방지
- wait-die scheme(non-preemptive): older transaction은 younger transaction이 테이터 항목의 lock을 해제할 때까지 기다릴 수 있지만, younger transaction은 older transaction을 기다리지 않고 즉시 rollback(die) 됩니다. rollback된 transaction은 원래의 timestamp를 가지고 재시작됩니다.
- wound-wait scheme(preemptive): older transaction은 younger transaction을 기다리는 대신 강제로 rollback(wound)시킬 수 있습니다. younger transaction은 older transaction을 기다립니다. 이 방식은 wait-die보다 rollback 횟수가 적습니다.
- Timeout-based schemes: transaction이 lock을 기다리는 시간을 특정 값으로 제한합니다. 기다리는 시간이 초과되면 transaction을 rollback됩니다. 구현은 간단하지만, deadlock 상태가 아니어도 불필요한 rollback이 발생할 수 있으며, 적절한 timeout value를 선택하기 어려우며, starvation의 발생 가능성도 있습니다.
*wait-die, wound-wait 방식 모두 older transaction에게 우선권을 줌으로써 starvation을 해결합니다.
Deadlock Detection
시스템이 deadlock 상태에 진입하는 것을 허용하되, 주기적으로 deadlock 상태 발생 여부를 확인합니다. 이를 위해 wait-for graph를 이용합니다.
이는 transaction을 정점으로 하여, Ti가 Tj가 가지고 있는 lock을 기다리고 있다면 Ti에서 Tj로 향하는 간선을 그릴 수 있습니다. 그리고 wait-for graph에 사이클이 존재하는 경우에만 시스템은 deadlock 상태에 있다고 가정합니다. 주기적인 cycle 생성 여부 알고리즘을 실행하여 사이클을 찾습니다.
Deadlock Recovery
deadlock이 발견되면 사이클을 깨기 위해 하나 이상의 transaction을 victim으로 선택하여 rollback을 수행합니다. 희생자 선택시 최소 비용을 발생시키는 transaction을 선택하는 등의 기준이 사용될 수 있습니다.
(1) Total rollback은 모든 transaction을 abort하고 재시작하는 방법, (2) Partial rollback은 사이클 내 다른 transaction이 기다리는 lock을 해제할 만큼만 rollback하는 방법입니다. victim 선정 방식이 잘못되면 starvation이 발생할 수 있으므로, 예를 들어 deadlock transaction 집합에서 가장 오래된 transaction을 희생자로 선택하지 않는 방법들을 선택할 수 있습니다.
*older transaction먼저 commit할 수 있게 하면 starvation이 발생하지 않는다. 그래서 wait-die, wound-wait방식 모두 older transaction에게 우선권을 줘서 starvation이 발생하지 않았던 것이다.
Multiple Granularity
데이터 항목을 다양한 크기로 허용하고 계층 구조로 조직화하여, 여러 수준의 데이터 항목에 대한 locking을 가능하게 합니다. small granularity는 larger one에 중첩될 수 있고 이는 트리 구조로 표현할 수 있습니다.
transaction이 명시적으로 특정 노드에 lock을 걸면, 해당 노드의 모든 하위 노드에도 동일한 모드로 implicit하게 lock이 걸립니다. granularity of locking은 트리의 어느 수준에서 locking을 수행하는지를 의미하며, 이는 concurrency 및 overhead와 trade off를 갖습니다. *fine granularity는 높은 동시성을 제공하지만 locking overhead가 높습니다. 반면에 Coarse granularity는 낮은 동시성을 제공하지만 locking overhead가 낮습니다.
*Multiple Granularity locking protocol이 필요한 이유
왜 “Multiple Granularity Locking(다중 세분화 잠금)”이 필요할까?
- 잠금 단위(Granularity)마다 장-단점이 뚜렷하다
- 세밀한 잠금(레코드·페이지) → 동시성↑ 하지만 트랜잭션이 수천 개 잠금을 들고 있으면 락 테이블 관리·메시지 왕복 비용이 커진다.
- 거친 잠금(테이블·DB 전체) → 관리 비용↓ 하지만 한 트랜잭션이 테이블 전체를 막아 버리면 다른 트랜잭션은 대기 → 병행성↓.
→ Multiple Granularity는 두 극단 사이를 자유롭게 오가도록 해 “높은 동시성과 낮은 오버헤드를 동시에 달성”하려는 설계다 23.Concurrency-2.
- 의도 잠금(Intention Locks)이 상위 노드 충돌 여부를 빠르게 판정
- S/X 외에 IS, IX, SIX 모드를 도입해 “아래 단계에서 더 세밀한 잠금을 잡을 의도가 있다”는 사실만 상위 노드에 표시한다.
- DBMS는 상위 노드 하나만 검사해도 충돌 유무를 알 수 있으므로, 행 단위로 내려가 직접 확인할 필요가 없다 23.Concurrency-2.
- “스캔 vs. 단일 행 수정” 같이 성격이 다른 트랜잭션을 자연스럽게 공존
- 예) 대량 조회 T₁: 테이블에 S 잠금 → 레코드들은 건드리지 않음.
- 예) 단일 업데이트 T₂: 테이블에 IX 잠금 + 수정할 행에 X 잠금.
- 두 트랜잭션이 동시에 진행될 수 있다. 과거에는 T₂가 테이블 전체를 X-lock 하거나 T₁이 모든 행을 S-lock 하는 식의 극단적 선택뿐이었다.
- Lock Escalation/De-escalation
- 트랜잭션이 “행 수백 개”를 잠근 순간 시스템이 자동으로 “테이블 S/X 락”으로 승격(escalation) → 락 개수·메모리 사용량 급감.
- 반대로 “작업 범위가 줄면” 더 세밀한 잠금으로 하향(de-escalation) 가능 23.Concurrency-2.
- 팬텀(phantom)·인덱스 잠금과도 궁합이 좋다
- 범위 스캔 시 테이블 IS + 인덱스의 리프 노드 S 잠금으로 팬텀 현상을 제어.
- 행 삽입·삭제는 IX + 인덱스 리프 노드 X 잠금이어서 충돌을 정확히 감지한다 23.Concurrency-2.
- 어떤 프로토콜과도 결합 가능
- 2PL(Strict 2PL 등)의 “growing/shrinking” 규칙을 그대로 적용하면서 노드 간 root→leaf 순서만 지키면 된다.
- Tree protocol과 달리 S-락도 허용하므로 범용 트랜잭션에 활용 가능.
Intention lock modes
lock mode에 S(Shared)와 X(eXclusive)모드 외에 IS, IX, SIX 모드가 추가됩니다. 이들은 하위 수준에서 locking이 수행될 것임을 나타내며, 상위 노드를 S 또는 X 모드로 locking할 때 하위 노드 전체를 검사할 필요가 없게 합니다.
- intention-shared (IS): 하위 수준에서 shared lock만 명시적으로 걸 것임을 나타냅니다.
- intention-exclusive (IX): 하위 수준에서 shared 또는 exclusive lock을 명시적으로 걸 것임을 나타냅니다.
- shared and intention-exclusive (SIX): 해당 노드 자체가 shared lock을 걸고, 하위 수준에서 exclusive lock을 명시적으로 걸 것임을 나타냅니다.
GPT
1. Intention Lock(IL) 패밀리 ― 한 번 더 깊이 파보기
| IS | Intent Shared | 상위 노드만 “표지판” → 하위 객체에는 곧 S-Lock을 잡을 것 |
▸ 개별 행/페이지 읽기 ▸ 범위 조회 (S,-Locks 다수) |
모든 읽기와 호환, 쓰기(X)엔 충돌 |
| IX | Intent Exclusive | 상위 노드 표지판 → 하위에 X-Lock 예정 | ▸ 행/페이지 수정(UPDATE/DELETE) ▸ INSERT(새 레코드 X-Lock) |
다른 IX·IS와는 OK (다른 레코드 수정 허용) -- S·X와는 충돌 |
| S | Shared | 해당 노드 자체를 전체 읽기 전용 | ▸ 테이블 전체 스캔(백업 등) | 다른 S·IS와만 호환 |
| SIX | Shared-Intent Exclusive | 상위 노드 전체를 읽으면서 하위 일부엔 X-Lock 예정 |
▸ “테이블 전체 읽으면서 일부 행 수정” 쿼리(예: UPDATE … WHERE condition 큰 범위) | IS만 호환 (다른 읽기만 가능) 단 한 트랜잭션만 보유 가능 |
| X | Exclusive | 해당 노드 전체에 쓰기 | ▸ ALTER TABLE, 대량 갱신, 테이블 재빌드 | 그 어떤 락과도 호환 X |
- IS·IX·SIX 는 상위-노드 전용 “경고 표지판”. 실제 데이터는 하위 객체의 S/X 락으로 보호됩니다.
- 트리 최상위(root)까지 의도 락을 위→아래 방향으로 획득해야 2-PL 위반이 없습니다.
2. 작동 예시 ― 4 개의 현실적 상황
예시 A) 다른 행을 동시에 갱신·조회* (최소 충돌)
| ① 상위 표지판 | IX(table) | IS(table) | IS vs IX → true |
| ② 하위 락 | X(R₁) | S(R₂) | 다른 행 → 호환 |
| 결과 | 두 트랜잭션 동시에 진행 |
왜 가능? 상위엔 IX·IS만 있어도 서로 OK, 실제 충돌 여부는 행 단위에서 결정.
예시 B) 같은 행 갱신 vs 조회 (필연 충돌)
| ① IX(table) | IS(table) (호환) | |
| ② X(R₁) 이미 보유 | S(R₁) 요청 → 대기 (S vs X = false) | |
| 결과 | T₂가 대기 → 직렬 순서 보장 |
예시 C) 테이블-스캔(백업) 중에 행 업데이트 시도
| ① S(table) 획득 | (요청) IX(table) | |
| ② | IX vs S = false → T₂ 대기 | |
| 의미 | 백업 수행 중에는 어떠한 쓰기도 금지 |
예시 D) SIX 활용 시나리오 (대량 읽기 + 일부 수정)
- SIX(table Orders) : 테이블 전체는 읽기 공유,
그러나 “곧 특정 행에 X-Lock 들어갈 것” 신호. - 다른 트랜잭션들은 IS(table) 로 읽기만 허용 (단순 조회 OK).
다른 S·IX·SIX·X는 모두 충돌 → 대기 - T₁이 조건에 맞는 각 행에 X(Rᵢ) → 개별 행 수정.
- 커밋 시 상·하위 락 한꺼번에 해제.
SIX 장점:
대량 읽기 동안 “읽기-전용 동시성”은 유지하고,
선택적 행 수정도 가능하게 해 주는 타협안.
3. 의도 락의 규칙 & 미묘한 포인트
| 획득 경로 | 루트 → 리프 순서(상→하)로 잡고, 해제는 반대로 | 데드락 위험 감소 |
| 병합(Escalation) | 다수 행에 X-Lock 잡다 → DBMS가 자동으로 페이지 IX→X 또는 테이블 IX→X 승격 | 락 수 줄여 관리 오버헤드↓ 하지만 동시성도 함께 ↓ |
| 변환(Conversion) | IS → IX / IX → X 등 승격만 허용 (보통). 다른 트랜잭션과 충돌 시 대기 | 읽다 보니 수정해야 할 때 유용 |
| SIX 독점성 | 한 노드에 SIX는 1개만 허용. 또 다른 트랜잭션의 SIX·S·IX·X 모두 차단 | 조건-UPDATE 같은 중간 규모 변경 작업 보호 |
| 표지판 개념 | IS/IX는 데이터 보호 기능은 없음. 상위 노드에 “아래로 가면 충돌 위험 있으니 주의”라는 선언 |
상위 잠금으로 빠른 호환성 체크 → 트리 탐색 깊이 줄임 |
4. 정리
- 의도 락(IS, IX, SIX) 은 다중-그래뉼러리티 환경에서
“상위-노드 한 곳”만 보면 잠금 충돌 여부를 즉시 판단하도록 돕는 경고표지판. - Compatibility Matrix 는 이 다섯 모드의 동시 보유 가능성을 체계적으로 정의한다.
- 예시 A~D 처럼 의도 락 덕분에 다른 행/페이지/작업 간 동시성은 높이고,
같은 데이터/범위 충돌은 정확히 차단해 직렬성을 지켜 준다.
Multiple Granularity Locking Scheme
Transaction Ti가 node Q에 lock을 걸때 다음의 규칙을 지켜야합니다:
- root node가 가장 먼저 locking되어야 합니다.
- 특정 모드로 locking하려면 parent node가 특정 intention lock mode 혹은 S/X lock mode로 locking되어야 합니다.
- transaction은 2PL을 따라야합니다(즉, Ti는 lock을 얻을때, 이전에 unlock했으면 안됩니다).
- lock을 root에서 leaf방향으로 획득되며, leaf에서 root방향으로 해제됩니다.
- lock의 수가 많이지면 더 높은 세분성 수준의 lock으로 전환하는 lock granularity excalation이 있을 수 있습니다.
Insert/Delete Operations and predicate reads
데이터들을 삭제하거나 삽입하는 경우는 X-lock을 획득해야합니다(삽입하는 경우에는 automatically 얻습니다). 이러한 규칙은 읽기/쓰기 연산이 삭제와 (lock이) 충돌할 수 있도록 보장하며, 삽입된 tuple이 해당 transaction이 commit될 때까지 다른 transaction이 접근할 수 없도록 합니다.
Phantom Phenomenon
phantom phenomenon은 transaction이 조건을 만족하는 record 집합을 검색한 후, 다른 transaction이 조건을 만족하는 새로운 record를 삽입(또는 삭제/수정)하고 commit했을 때, 처음 transaction이 동일한 검색을 수행하면 결과 집합이 달라지는 현상입니다. 이것은 serialization anomaly의 한 형태입니다. 이는 tuple 수준의 locking만으로는 이 현상을 막을 수 없습니다. phantom phenomenon의 근본적인 문제는 tuple 존재에 대한 정보 자체가 공유되는 데이터 항목이기 때문입니다.
Handling Phantoms
- 관련된 table을 나타내는 데이터 항목에 lock을 거는 방식: 검색 transaction은 shared lock을, 삽입/삭제 transaction은 exclusive lock을 획득합니다. 하지만 이는 삽입/삭제 시 동시성을 매우 낮춥니다. *table, relation단위는 너무 크다.
- Index locking: 모든 테이블에 최소 하나의 index가 있다고 가정하고 index를 통해 tuple에 접근합니다. 검색을 수행하는 transaction은 접근하는 index leaf node에 S-lock을 획득합니다. 삽입/갱신/삭제를 수행하는 transaction은 영향을 받는 모든 index leaf node에 X-lock을 획득합니다. 이때는 2PL를 따라야하며, 이는 phantom phenomenon이 발생하지 않음을 보장합니다.
- Next-key locking: index locking의 단점(많은 삽입 시 낮은 동시성)을 개선한 b+-tree 기반 프로토콜입니다. lookup 조건을 만족하는 값들 뿐만 아니라, index 상에서 그 다음에 오는 next key value에도 lock을 겁니다. lookup에는 S-look을 삽입/삭제/갱신에는 X-lock을 사용합니다. 이를 통해 높은 동시성을 제공하며 phantom을 방지합니다.
'[학교 수업] > [학교 수업] Database' 카테고리의 다른 글
| [Database] Recovery (0) | 2025.06.10 |
|---|---|
| [Database] Concurrency Control (3) (0) | 2025.06.06 |
| [Database] Concurrency Control (1) | 2025.06.06 |
| [Database] Query Processing (0) | 2025.05.27 |
| [Database] LSM tree (0) | 2025.05.27 |