
Failure Classifier
Database system에서 발생할 수 있는 failure case는 다음과 같습니다:
- Transaction failure:
- Logical errors: transaction내부의 error condition으로 인해 transaction이 끝나지 않는 것을 말합니다.
- System errors: deadlock과 같이 error condition으로 인해 database system이 동작중인 transaction을 종료해야만 하는 상황을 말합니다.
- System crash: power failure나 다른 hardware/software failure로 인해 system이 crash가 발생한 상황을 말합니다.
- Fail-stop assumption: non-volatile storage에 저장된 contents들은 system crash로 인해 손상되지 않는다고 가정합니다. *그래서 log를 disk(non-volatile)에 저장합니다.
- Disk failure: disk 자체의 failure로 인해 disk storage의 전체 또는 일부가 파괴되는 경우를 말합니다.
- disk drive는 checksum을 활용하여 failure를 detection합니다. *checksum은 data의 요약값으로 데이터들의 checksum을 활용하여 데이터 손상이 발생했는지를 확인합니다.
Recovery Algorithms
transaction Ti가 A계좌에서 B계좌로 $50을 이체하는 경우 Ti는 A와 B에 대한 update가 db에 저장되기를 요청합니다. 만약 두 modification작업이 완료되기 전에 failure가 발생하면, 즉 Non-atomic modification은 inconsistent한 DB를 만들게됩니다. 이는 Atomicity 원칙을 위반하는 것입니다.
또한 transaction이 commit된 직후에 failure가 발생했는데도 DB가 정되지 않는다면, update가 손실될 수 있고, 이는 durability 원칙을 위반하는 것입니다.
이에 대한 recovery algorithm은 두 부분으로 구성됩니다:
(1) failure로부터 recovery하기 위한 충분한 정보가 존재하도록 정상적인 transaction 처리중에 정보를 수집합니다. *log가 될 수 있습니다.
(2) failure가 발생한 후 DB의 내용을 atomicity, consistency, durability 원칙을 보장하도록 복구하는 동작합니다.
Data Access
DB system에서 데이터가 존재하는 공간은 크게 두 개입니다:
- Physical blocks: 이는 disk에 상주하는 block입니다.
- Buffer blocks: 이는 main memory에 임시로 상주하는 block입니다.
그리고 disk와 main memory사이에서 데이터를 전송할 때는 두 연산을 사용합니다:
- input(B): 이는 physical block B를 main memory로 전송합니다.
- output(B): 이는 buffer blcok B를 disk로 전송하여 해당 physical block을 대체합니다.
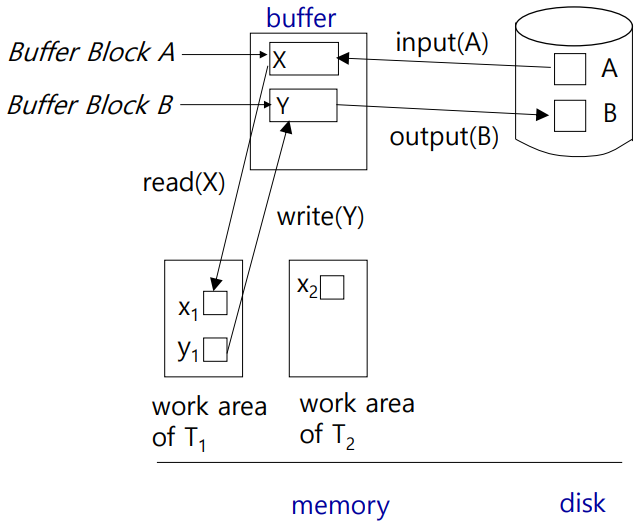
각각의 transaction은 접근 및 업데이트하는 모든 data item의 local copies들(위 그림에서는 x1, y1, x2)을 보관하는 private work-area를 갖습니다. 그리고 이때 data item X에 대한 Ti의 local copies들을 xi라고 위 그림에서 부릅니다.
system buffer block과 private work-area사이의 data item transfer는 다음의 연산을 통해 수행됩니다:
- read(X): data item X의 값을 local variable xi에 할당합니다.
- write(X): local variable xi의 값을 buffer block의 data item X에 할당합니다.
- 이때 output(Bx) 연산은 write(X) 연산 바로 뒤에 수행될 필요는 없습니다. 즉, 시스템은 적절하다고 판단될 때 output연산을 수행할 수 있습니다.
추가적으로 처음에 data item X에 접근하기 전에는 read(X)를 수행해야 합니다(이후의 읽기는 local copies를 이용가능). 하지만 write(X)는 transaction commit 전에 언제든지 실행될 수 있습니다. *write()의 경우는 그냥 buffer block으로 밀어넣으면 되기 때문에
Recovery and Atomicity
failure가 발생해도 atomicity, durability를 보장하기 위해 DB 자체를 수정하기 전에 수정 내용을 설명하는 정보를 stable storage(ex. disk storage). 이때 stable storage는 failure 이후에도 내용이 보존되는 저장소를 의미합니다. 일반적으로 덜 사용되는 방법은 shadow-copy와 shadow-paging이 있습니다.

*이 방법은 COW방법을 기반으로 하는 recovery방법론으로, db에 새로운 update가 있다면 기존의 db인 old db를 새롭게 복사하여 new copy of db를 만듭니다. 그리고 이를 shadow-copy라고 합니다. 그 후 update의 내용을 new copy of db에 적용합니다.
만약 이 과정에서 failure가 발생했다면 db-pointer는 old copy를 아직 가르키고 있기 때문에 아무것도 수정되지 않은 상태로 남게됩니다(Nothing). 정상적으로 update가 적용되었으면 db를 가르키는 db-pointer의 값을 old copy가 아닌 new copy를 향하도록 변경합니다(All). 이를 통해 Atomicity(All or Nothing)을 보장합니다.
하지만 이는 db전체를 copy해야하는 overhead가 있고 이를 완화하기 위해 shadow paging기법을 사용합니다.
shadow paging
shadow paging은 log based recovery의 대안이며, transaction이 serial하게 실행될 때 유용합니다. *즉 shadow paging방법은 concurrent execution에 취약합니다.
transaction의 life cycle동안 두 개의 page table을 유지합니다;
(1) current page table
(2) shadow page table
shadow page table은 transaction 실행 이전의 database 상태를 복구하기 위해 non-volatile storage에 저장됩니다. 그리고 이 shadow page table은 transaction 실행 중에는 절대 수정되지 않습니다.
처음에는 두 page table이 동일합니다. transaction 실행 중 데이터 접근에는 current page table만을 사용합니다. 어떤 page가 처음으로 쓰여지려고 할 때마다:
(1) 해당 page의 copy가 사용되지 않는 새 page에 만들어집니다.(2) current page table은 이제 이 copy를 가리키도록 변경됩니다.(3) 실제 update는 이 복사본 page에 수행됩니다.
*이때 쓰여진다. modify된다는 것은 write(x)를 의미합니다. 그렇가면 flush()는 output()을 의미하나?


이때 transaction이 commit되기 위해서는 다음의 단계를 수행합니다:
(1) main memory에 있는 수정된 모든 page를 disk로 flush합니다.
(2) current page table을 disk에 출력합니다.
(3) disk에 있는 shadow page table에 대한 pointer를 update하여, current page table을 새로운 shadow page table로 만듭니다.
그 후 shadow page table에 대한 pointer가 변경이 되면, transaction은 commit된 상태가 됩니다. failure후에는 recovery가 필요하지 않으며 새로운 transaction은 shadow page table을 사용하여 즉시 시작할 수 있습니다. 한편 current/shadow page table이 더 이상 가리키지 않는 page들은 해제되어야 합니다(garbage collection).
pros:
- log record를 기록하는 overhead가 없습니다(하지만 다른 overhead가 존재합니다).
- recovery가 간단합니다.
cons:
- 전체 페이지 테이블을 복사하는 비용이 매우 비쌉니다.
- commit overhead가 높습니다. 모든 updated page와 page table을 flush해야합니다.
- 각 transaction 완료 후에 수정된 데이터의 이전 version을 포함하는 DB page에 대한 garbage collection이 필요합니다.
- transaction의 동시 실행을 허용하도록 알고리즘을 확장하기 어렵습니다. *반면 log기반 기법은 concurrency 기반 확장이 쉽습니다.
Log-based Recovery
log는 log records의 sequence입니다. log는 db의 업데이트 활동에 대한 정보를 기록합니다. log는 stable storage에 보관됩니다. Transaction Ti가 시작될 때, <Ti start> log record를 작성하여 자신을 등록합니다. Ti가 write(X)를 실행하기 전에, <Ti, X, V1, V2> log record가 작성됩니다. 여기서 V1은 이전 값, V2는 새로 작성될 값입니다. Ti가 마지막 명령문을 완료하면, <Ti commit> log record가 작성됩니다.
log를 사용하는 두 가지 접근방식이 존재합니다:
- Immediate database modification
- Deferred database modification
Immediate database modification
immediate database modification은 commit되지 않은 transaction의 업데이트를 transaction이 commit하기 전에 buffer나 disk 자체에 적용할 수 있도록 허용합니다. update log record는 database item이 쓰여지기 전에 disk(stable storage)에 쓰여져야합니다.
update된 block을 disk로 출력하는 것(output)은 transaction commit 전 또는 후 언제든지 발생할 수 있습니다. 또한 block이 output되는 순서는 block이 write되는 순서와 다를 수 있습니다.
Deferred database modification
deferred database modification 방법은 transaction commit 시점에만 buffer/disk update(output)을 수행합니다. 이 방식은 recovery의 일부 측면을 단순화하지만, local copy를 저장하고 있어야한다는 overhead가 있습니다. *output을 commit단계에서만 수행하니까 계속 결과를 local에서 들고있어야합니다.
Transaction commit
Transaction은 자신의 commit record가 stable storage에 output되었을 때 commit되었다고 간주됩니다. transaction의 이전 log record들은 이미 output되어있어야합니다. *log record는 log들을 시간 순으로 나열한 것이고 commit은 모든 instruction들 중 가장 마지막 instr.이기 때문에. transaction이 수행한 write은 transaction이 commit될 때 buffer에 남아있을 수 있으며 나중에 output될 수 있습니다.
Concurrency Control and Recovery
concurrent transaction들은 하나의 disk buffer와 하나의 log를 공유합니다. *이때 buffer block은 하나 이상의 transaction에 의해 업데이트된 data item을 가질 수 있습니다. 하나의 buffer block을 사용하는 transaction이 여러개이기 때문에. 만약 transaction Ti가 item을 수정했다면, Ti가 commit 또는 abort될 때까지 다른 transaction이 동일한 item을 수정할 수 없다고 가정합니다(isolation).
이는 update된 item에 대해 lock-X를 획득하고 transaction이 끝날 때까지 lock을 유지함으로써 보장할 수 있습니다(Strict 2PL). 서로 다른 transaction의 log record들은 섞여서 나타날 수 있습니다. *같은 log를 공유하기 때문에.
Undo and Redo Operation
- Undo(Ti)
- Ti에 의해 업데이트된 모든 data item의 값을 이전 값으로 복원합니다. Ti의 마지막 log record부터 역순으로 진행합니다. data item X가 이전 값 V로 복원될 때마다 <Ti, X, V>라는 log record가 작성됩니다. transaction의 undo가 완료되면, <Ti abort> log record가 작성됩니다.
- Redo(Ti)
- Ti에 의해 업데이트된 모든 data item의 값을 새로운 값으로 설정합니다. Ti의 첫 번째 log record부터 순방향으로 진행합니다. 이 경우 logging은 수행되지 않습니다.
Recovering from Failure
(1) log에 <Ti start>는 있지만 <Ti commit>또는 <Ti abort>가 포함되지 않은 경우, transaction Ti는 Undo되어야합니다.
(2) log에 <Ti start>가 포함되고 <Ti commit> 또는 <Ti abort> 가 포함된 경우, transaction Ti는 Redo되어야합니다.

(a) log에 <T0 start>만 있는 경우: undo(Ti)를 실행합니다. B는 2000으로, A는 1000으로 복원되고 <T0, B, 2000> <T0, A, 1000> <T0 abort> log record가 작성됩니다.
(b) log에 T0 commit은 있지만 T1 start만 있는 경우: redo(T0)와 undo(T1)를 수행합니다. A와 B는 각각 950과 2050으로 설정되고, C는 700으로 복원됩니다. <T1 C, 700> <T1, abort>가 작성됩니다.
(c) log에 T0 commit과 T1 commit이 모두 있는 경우: redo(T0)와 redo(T1)을 수행합니다. A와 B는 각각 950과 2050으로 설정되고, C는 600으로 설정됩니다.
만약 transaction T1가 이전에 undo되었고 log에 <Ti abort> record가 작성되었는데 failure가 발생한 경우, 그 상태에서의 복구하는 것은 redo(Ti)를 수행하는 것입니다. *<T1 abort>가 있으니까. 이러한 redo는 repeating history라고 하며 이전 값을 복원했던 단계를 포함하여 transaction Ti의 원래 모든 작업을 다시 수행합니다. 이는 불필요해보이지만 단순성을 높여줍니다.
Checkpoints
log에 기록된 모든 transaction을 redo/undo하는 것은 시스템이 오랫동안 실행된 경우 시간이 많이 걸릴 수 있습니다. 이미 없데이트를 데이터베이스에 output한 것을 불필요하게 redo할 수도 있습니다. 따라서 주기적으로 checkpointing을 수행하여 recovery 절차를 간소화합니다.
checkpointing의 절차는 다음과 같습니다:
(1) 현재 main memory에 있는 모든 log record를 stable storage로 output합니다.
(2) 모든 수정된 buffer block을 disk로 output합니다.
(3) checkpoint 시점에 활성화된 모든 transaction 목록 L과 함께 <checkpoint L> log record를 stable storage에 output합니다.
(4) checkpointing중에는 모든 update 작업이 중지됩니다.
recovery 중에는 checkpoint전에 완료되지 않은 transaction과 checkpoint 이후에 시작된 transaction만 고려하면 됩니다. 가장 최근의 <checkpoint L> record를 찾기 위해 역방향으로 log를 scan합니다. L에 포함된 transaction 또는 checkpoint 이후에 시작된 transaction만 redo 또는 undo가 필요합니다.

'[학교 수업] > [학교 수업] Database' 카테고리의 다른 글
| [Database] Concurrency Control (3) (0) | 2025.06.06 |
|---|---|
| [Database] Concurrency Control (2) (1) | 2025.06.06 |
| [Database] Concurrency Control (1) | 2025.06.06 |
| [Database] Query Processing (0) | 2025.05.27 |
| [Database] LSM tree (0) | 2025.05.27 |
Failure Classifier
Database system에서 발생할 수 있는 failure case는 다음과 같습니다:
- Transaction failure:
- Logical errors: transaction내부의 error condition으로 인해 transaction이 끝나지 않는 것을 말합니다.
- System errors: deadlock과 같이 error condition으로 인해 database system이 동작중인 transaction을 종료해야만 하는 상황을 말합니다.
- System crash: power failure나 다른 hardware/software failure로 인해 system이 crash가 발생한 상황을 말합니다.
- Fail-stop assumption: non-volatile storage에 저장된 contents들은 system crash로 인해 손상되지 않는다고 가정합니다. *그래서 log를 disk(non-volatile)에 저장합니다.
- Disk failure: disk 자체의 failure로 인해 disk storage의 전체 또는 일부가 파괴되는 경우를 말합니다.
- disk drive는 checksum을 활용하여 failure를 detection합니다. *checksum은 data의 요약값으로 데이터들의 checksum을 활용하여 데이터 손상이 발생했는지를 확인합니다.
Recovery Algorithms
transaction Ti가 A계좌에서 B계좌로 $50을 이체하는 경우 Ti는 A와 B에 대한 update가 db에 저장되기를 요청합니다. 만약 두 modification작업이 완료되기 전에 failure가 발생하면, 즉 Non-atomic modification은 inconsistent한 DB를 만들게됩니다. 이는 Atomicity 원칙을 위반하는 것입니다.
또한 transaction이 commit된 직후에 failure가 발생했는데도 DB가 정되지 않는다면, update가 손실될 수 있고, 이는 durability 원칙을 위반하는 것입니다.
이에 대한 recovery algorithm은 두 부분으로 구성됩니다:
(1) failure로부터 recovery하기 위한 충분한 정보가 존재하도록 정상적인 transaction 처리중에 정보를 수집합니다. *log가 될 수 있습니다.
(2) failure가 발생한 후 DB의 내용을 atomicity, consistency, durability 원칙을 보장하도록 복구하는 동작합니다.
Data Access
DB system에서 데이터가 존재하는 공간은 크게 두 개입니다:
- Physical blocks: 이는 disk에 상주하는 block입니다.
- Buffer blocks: 이는 main memory에 임시로 상주하는 block입니다.
그리고 disk와 main memory사이에서 데이터를 전송할 때는 두 연산을 사용합니다:
- input(B): 이는 physical block B를 main memory로 전송합니다.
- output(B): 이는 buffer blcok B를 disk로 전송하여 해당 physical block을 대체합니다.
각각의 transaction은 접근 및 업데이트하는 모든 data item의 local copies들(위 그림에서는 x1, y1, x2)을 보관하는 private work-area를 갖습니다. 그리고 이때 data item X에 대한 Ti의 local copies들을 xi라고 위 그림에서 부릅니다.
system buffer block과 private work-area사이의 data item transfer는 다음의 연산을 통해 수행됩니다:
- read(X): data item X의 값을 local variable xi에 할당합니다.
- write(X): local variable xi의 값을 buffer block의 data item X에 할당합니다.
- 이때 output(Bx) 연산은 write(X) 연산 바로 뒤에 수행될 필요는 없습니다. 즉, 시스템은 적절하다고 판단될 때 output연산을 수행할 수 있습니다.
추가적으로 처음에 data item X에 접근하기 전에는 read(X)를 수행해야 합니다(이후의 읽기는 local copies를 이용가능). 하지만 write(X)는 transaction commit 전에 언제든지 실행될 수 있습니다. *write()의 경우는 그냥 buffer block으로 밀어넣으면 되기 때문에
Recovery and Atomicity
failure가 발생해도 atomicity, durability를 보장하기 위해 DB 자체를 수정하기 전에 수정 내용을 설명하는 정보를 stable storage(ex. disk storage). 이때 stable storage는 failure 이후에도 내용이 보존되는 저장소를 의미합니다. 일반적으로 덜 사용되는 방법은 shadow-copy와 shadow-paging이 있습니다.
*이 방법은 COW방법을 기반으로 하는 recovery방법론으로, db에 새로운 update가 있다면 기존의 db인 old db를 새롭게 복사하여 new copy of db를 만듭니다. 그리고 이를 shadow-copy라고 합니다. 그 후 update의 내용을 new copy of db에 적용합니다.
만약 이 과정에서 failure가 발생했다면 db-pointer는 old copy를 아직 가르키고 있기 때문에 아무것도 수정되지 않은 상태로 남게됩니다(Nothing). 정상적으로 update가 적용되었으면 db를 가르키는 db-pointer의 값을 old copy가 아닌 new copy를 향하도록 변경합니다(All). 이를 통해 Atomicity(All or Nothing)을 보장합니다.
하지만 이는 db전체를 copy해야하는 overhead가 있고 이를 완화하기 위해 shadow paging기법을 사용합니다.
shadow paging
shadow paging은 log based recovery의 대안이며, transaction이 serial하게 실행될 때 유용합니다. *즉 shadow paging방법은 concurrent execution에 취약합니다.
transaction의 life cycle동안 두 개의 page table을 유지합니다;
(1) current page table
(2) shadow page table
shadow page table은 transaction 실행 이전의 database 상태를 복구하기 위해 non-volatile storage에 저장됩니다. 그리고 이 shadow page table은 transaction 실행 중에는 절대 수정되지 않습니다.
처음에는 두 page table이 동일합니다. transaction 실행 중 데이터 접근에는 current page table만을 사용합니다. 어떤 page가 처음으로 쓰여지려고 할 때마다:
(1) 해당 page의 copy가 사용되지 않는 새 page에 만들어집니다.(2) current page table은 이제 이 copy를 가리키도록 변경됩니다.(3) 실제 update는 이 복사본 page에 수행됩니다.
*이때 쓰여진다. modify된다는 것은 write(x)를 의미합니다. 그렇가면 flush()는 output()을 의미하나?
이때 transaction이 commit되기 위해서는 다음의 단계를 수행합니다:
(1) main memory에 있는 수정된 모든 page를 disk로 flush합니다.
(2) current page table을 disk에 출력합니다.
(3) disk에 있는 shadow page table에 대한 pointer를 update하여, current page table을 새로운 shadow page table로 만듭니다.
그 후 shadow page table에 대한 pointer가 변경이 되면, transaction은 commit된 상태가 됩니다. failure후에는 recovery가 필요하지 않으며 새로운 transaction은 shadow page table을 사용하여 즉시 시작할 수 있습니다. 한편 current/shadow page table이 더 이상 가리키지 않는 page들은 해제되어야 합니다(garbage collection).
pros:
- log record를 기록하는 overhead가 없습니다(하지만 다른 overhead가 존재합니다).
- recovery가 간단합니다.
cons:
- 전체 페이지 테이블을 복사하는 비용이 매우 비쌉니다.
- commit overhead가 높습니다. 모든 updated page와 page table을 flush해야합니다.
- 각 transaction 완료 후에 수정된 데이터의 이전 version을 포함하는 DB page에 대한 garbage collection이 필요합니다.
- transaction의 동시 실행을 허용하도록 알고리즘을 확장하기 어렵습니다. *반면 log기반 기법은 concurrency 기반 확장이 쉽습니다.
Log-based Recovery
log는 log records의 sequence입니다. log는 db의 업데이트 활동에 대한 정보를 기록합니다. log는 stable storage에 보관됩니다. Transaction Ti가 시작될 때, <Ti start> log record를 작성하여 자신을 등록합니다. Ti가 write(X)를 실행하기 전에, <Ti, X, V1, V2> log record가 작성됩니다. 여기서 V1은 이전 값, V2는 새로 작성될 값입니다. Ti가 마지막 명령문을 완료하면, <Ti commit> log record가 작성됩니다.
log를 사용하는 두 가지 접근방식이 존재합니다:
- Immediate database modification
- Deferred database modification
Immediate database modification
immediate database modification은 commit되지 않은 transaction의 업데이트를 transaction이 commit하기 전에 buffer나 disk 자체에 적용할 수 있도록 허용합니다. update log record는 database item이 쓰여지기 전에 disk(stable storage)에 쓰여져야합니다.
update된 block을 disk로 출력하는 것(output)은 transaction commit 전 또는 후 언제든지 발생할 수 있습니다. 또한 block이 output되는 순서는 block이 write되는 순서와 다를 수 있습니다.
Deferred database modification
deferred database modification 방법은 transaction commit 시점에만 buffer/disk update(output)을 수행합니다. 이 방식은 recovery의 일부 측면을 단순화하지만, local copy를 저장하고 있어야한다는 overhead가 있습니다. *output을 commit단계에서만 수행하니까 계속 결과를 local에서 들고있어야합니다.
Transaction commit
Transaction은 자신의 commit record가 stable storage에 output되었을 때 commit되었다고 간주됩니다. transaction의 이전 log record들은 이미 output되어있어야합니다. *log record는 log들을 시간 순으로 나열한 것이고 commit은 모든 instruction들 중 가장 마지막 instr.이기 때문에. transaction이 수행한 write은 transaction이 commit될 때 buffer에 남아있을 수 있으며 나중에 output될 수 있습니다.
Concurrency Control and Recovery
concurrent transaction들은 하나의 disk buffer와 하나의 log를 공유합니다. *이때 buffer block은 하나 이상의 transaction에 의해 업데이트된 data item을 가질 수 있습니다. 하나의 buffer block을 사용하는 transaction이 여러개이기 때문에. 만약 transaction Ti가 item을 수정했다면, Ti가 commit 또는 abort될 때까지 다른 transaction이 동일한 item을 수정할 수 없다고 가정합니다(isolation).
이는 update된 item에 대해 lock-X를 획득하고 transaction이 끝날 때까지 lock을 유지함으로써 보장할 수 있습니다(Strict 2PL). 서로 다른 transaction의 log record들은 섞여서 나타날 수 있습니다. *같은 log를 공유하기 때문에.
Undo and Redo Operation
- Undo(Ti)
- Ti에 의해 업데이트된 모든 data item의 값을 이전 값으로 복원합니다. Ti의 마지막 log record부터 역순으로 진행합니다. data item X가 이전 값 V로 복원될 때마다 <Ti, X, V>라는 log record가 작성됩니다. transaction의 undo가 완료되면, <Ti abort> log record가 작성됩니다.
- Redo(Ti)
- Ti에 의해 업데이트된 모든 data item의 값을 새로운 값으로 설정합니다. Ti의 첫 번째 log record부터 순방향으로 진행합니다. 이 경우 logging은 수행되지 않습니다.
Recovering from Failure
(1) log에 <Ti start>는 있지만 <Ti commit>또는 <Ti abort>가 포함되지 않은 경우, transaction Ti는 Undo되어야합니다.
(2) log에 <Ti start>가 포함되고 <Ti commit> 또는 <Ti abort> 가 포함된 경우, transaction Ti는 Redo되어야합니다.
(a) log에 <T0 start>만 있는 경우: undo(Ti)를 실행합니다. B는 2000으로, A는 1000으로 복원되고 <T0, B, 2000> <T0, A, 1000> <T0 abort> log record가 작성됩니다.
(b) log에 T0 commit은 있지만 T1 start만 있는 경우: redo(T0)와 undo(T1)를 수행합니다. A와 B는 각각 950과 2050으로 설정되고, C는 700으로 복원됩니다. <T1 C, 700> <T1, abort>가 작성됩니다.
(c) log에 T0 commit과 T1 commit이 모두 있는 경우: redo(T0)와 redo(T1)을 수행합니다. A와 B는 각각 950과 2050으로 설정되고, C는 600으로 설정됩니다.
만약 transaction T1가 이전에 undo되었고 log에 <Ti abort> record가 작성되었는데 failure가 발생한 경우, 그 상태에서의 복구하는 것은 redo(Ti)를 수행하는 것입니다. *<T1 abort>가 있으니까. 이러한 redo는 repeating history라고 하며 이전 값을 복원했던 단계를 포함하여 transaction Ti의 원래 모든 작업을 다시 수행합니다. 이는 불필요해보이지만 단순성을 높여줍니다.
Checkpoints
log에 기록된 모든 transaction을 redo/undo하는 것은 시스템이 오랫동안 실행된 경우 시간이 많이 걸릴 수 있습니다. 이미 없데이트를 데이터베이스에 output한 것을 불필요하게 redo할 수도 있습니다. 따라서 주기적으로 checkpointing을 수행하여 recovery 절차를 간소화합니다.
checkpointing의 절차는 다음과 같습니다:
(1) 현재 main memory에 있는 모든 log record를 stable storage로 output합니다.
(2) 모든 수정된 buffer block을 disk로 output합니다.
(3) checkpoint 시점에 활성화된 모든 transaction 목록 L과 함께 <checkpoint L> log record를 stable storage에 output합니다.
(4) checkpointing중에는 모든 update 작업이 중지됩니다.
recovery 중에는 checkpoint전에 완료되지 않은 transaction과 checkpoint 이후에 시작된 transaction만 고려하면 됩니다. 가장 최근의 <checkpoint L> record를 찾기 위해 역방향으로 log를 scan합니다. L에 포함된 transaction 또는 checkpoint 이후에 시작된 transaction만 redo 또는 undo가 필요합니다.
'[학교 수업] > [학교 수업] Database' 카테고리의 다른 글
| [Database] Concurrency Control (3) (0) | 2025.06.06 |
|---|---|
| [Database] Concurrency Control (2) (1) | 2025.06.06 |
| [Database] Concurrency Control (1) | 2025.06.06 |
| [Database] Query Processing (0) | 2025.05.27 |
| [Database] LSM tree (0) | 2025.05.27 |