
https://arxiv.org/abs/2304.08069
DETRs Beat YOLOs on Real-time Object Detection
The YOLO series has become the most popular framework for real-time object detection due to its reasonable trade-off between speed and accuracy. However, we observe that the speed and accuracy of YOLOs are negatively affected by the NMS. Recently, end-to-e
arxiv.org
Motivation.
Image detection에서는 real-time에 사용하는데에 특화된 1-stage detector(e.g., YOLO family)와 attention을 이용해서 성능을 끌어올린 transformer계열(e.g., DETR)이 있습니다. YOLO와 같은 1-stage detector는 CNNs기반으로 computational cost가 작기 때문에 추론 속도가 빠르지만 dense prediction을 하기 때문에 GT와 prediction을 매칭하기 전에 prediction들끼리 겹치는 것 들을 제거할 필요가 있습니다. 이 알고리즘을 NMS라고 부릅니다:
https://ctkim.tistory.com/entry/Non-maximum-Suppression-NMS
NMS(Non-maximum Suppression)
☞ 문서의 내용은 가장 하단 참고문헌 및 사이트를 참고하여 필자가 보기 쉽도록 정리한 내용입니다. ☞ 틀린 내용 및 저작권 관련 문의가 있는 경우 문의하시면 수정 및 삭제 조치하겠습니다. N
ctkim.tistory.com
NMS는 다음 두 가지 단점이 존재합니다:
(1) NMS를 수행하는 과정에서 시간 소모가 심합니다. 이는 inference speed가 빠르다는 1-stage detector의 장점을 상쇄합니다.
(2) NMS에서 사용하는 hyperparameter들을 설정하는 것을 직접 해야합니다. 이로 인해, 여러 상황에 유연하게 대처할 수 없으며, 여러 상황에서 안정적으로 예측을 수행한다고 보장할 수 없습니다.
아래는 NMS에 대한 실험 결과입니다:

표 1. 은 NMS에서 사용하는 hyperparameter인 IoU/Confidence threshold값에 따라 정확도와 소요 시간이 어떻게 변하는지를 나타냅니다. 위 결과에 따르면 정확도와 소요 시간 사이의 trade-off 관계가 성립함을 알 수 있습니다. 즉, 성능을 위해서는 추론 속도를 포기해야합니다.
반면, attention기반의 DETR과 같은 모델들은 sparse prediction, 즉, query의 개수 만큼만 예측을 수행하기 때문에 NMS와 같은 후처리 기법이 필요하지 않습니다. 다시 말해, NMS로 인한 시간 소모는 없습니다. 하지만 attention이 sequence length에 제곱에 해당하는 시간 복잡도가 필요하기 때문에 real-time detector로서는 사용하기 힘들었었습니다. 이런 문제를 해결하기 위해 DETR을 real-time에 맞게 수정하려는 연구가 지속되었고, 대표적인 수정 방향은 다음과 같습니다:
(1) Accelerating Convergence: 일반적인 DETR은 모두 attention으로 이뤄졌기 때문에 계산이 많이 소모되고, 많은 양의 파라미터가 존재합니다. 이는 수렴 속도를 늦추는 원인이 됩니다. 그래서 Deformable attention과 같이 light-weight attention 방법들을 이용해 수렴 속도를 높이는 방향으로 연구가 진행되었습니다.
[CoIn] 논문 리뷰 | DEFORMABLE DETR: DEFORMABLE TRANSFORMERSFOR END-TO-END OBJECT DETECTION (Zhu et al., 2021)
https://arxiv.org/abs/2010.04159 Deformable DETR: Deformable Transformers for End-to-End Object DetectionDETR has been recently proposed to eliminate the need for many hand-designed components in object detection while demonstrating good performance. Howev
hw-hk.tistory.com
(2) Reducing computational cost: 앞서 말했듯, 일반적인 attention은 sequence length의 제곱에 해당하는 계산 복잡도가 필요하기 때문에 추론 속도가 늦습니다. 이를 해결하기 위해 Deformable attention이나 Efficient DETR, Sparse DETR과 같은 다양한 연구가 진행되었습니다.
[CoIn] 논문 리뷰 | SPARSE DETR: EFFICIENT END-TO-END OBJECT DETECTION WITH LEARNABLE SPARSITY (Roh et al., 2022)
https://arxiv.org/abs/2111.14330 Sparse DETR: Efficient End-to-End Object Detection with Learnable SparsityDETR is the first end-to-end object detector using a transformer encoder-decoder architecture and demonstrates competitive performance but low comput
hw-hk.tistory.com
(3) Optimizing query initialization: 일반적인 DETR은 query를 최적화하기 힘듭니다. 이를 해결하기 위해 Conditional DETR이나 Anchor DETR과 같이 query의 값을 잘 초기화하는 방법이 연구되었습니다.
제안된 모델은 위 세가지 방향에서의 문제들을 해결하는 방향으로 DETR을 수정했고, 결과적으로 추론 속도의 측면과 # prams의 측면에서 YOLO family보다 더 나은 성능을 보여줍니다.
Efficient Hybrid Encoder.
제안된 모델의 구조를 살펴보기 전에 먼저 DETR에서의 Encoder의 중요성을 살펴보고 갑니다. 가장 기본적인 DETR의 경우는 image feature를 입력으로 받아 self-attention을 수행하고, 이를 decoder의 key/value로 사용합니다. 즉, encoder에서의 sequence length는 image feature의 차원입니다. 한편, decoder에서의 sequence length는 # queries 입니다. 다시 말해, decoder의 시간 복잡도는 # queries를 줄이면 어느 정도 해결할 수 있지만, encoder의 경우는 쉽지 않고, decoder에 비해 computational bottleneck입니다. 따라서 real-time에 맞게 효율적인 DETR을 만들기 위해서는 Encoder를 가볍게 만들어야합니다.
가장 최근의 DETR계열의 encoder(예: DINO)는 multi-scale encoder를 사용합니다.
[CoIn] 논문 리뷰 | DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection (Zhang et al., 2022)
https://arxiv.org/abs/2203.03605 DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object DetectionWe present DINO (\textbf{D}ETR with \textbf{I}mproved de\textbf{N}oising anch\textbf{O}r boxes), a state-of-the-art end-to-end object detector.
hw-hk.tistory.com
즉, input feature를 scale마다 feature를 얻어서 이들 각각에 대해 attention을 수행함으로서 encoding을 수행합니다. high-level feature와 low-level feature를 하나의 sequence로 concat한 후 encoder에 입력으로 사용합니다. 아래는 DINO(Zhang et al., 2023) 모델의 Overview입니다:

해당 논문의 저자는 위 방법이 계산의 중복을 만든다고 말합니다. high-level feature는 low-level feature를 통해 만들어졌습니다. 즉, high-level feature는 low-level feature의 정보를 이미 갖고 있습니다. 그런데 다시 self-attention을 통해 high-level과 low-level의 관계를 학습할 필요가 없다는 것입니다. attention은 high-level feature에 대해서만 하는 것이 계산의 중복을 만들지 않는다고 말합니다.
그렇다고 high-level에 대해서만 attention을 수행하기에는 low-level은 상대적으로 물체가 크고, 큼직한 패턴들에 대한 정보가 많고, high-level은 상대적으로 작고, 조밀한 패턴에 대한 정보가 많기 때문에, 이 둘을 모두 사용하는 것이 성능에 있어서 좋은 것은 맞습니다. 따라서 계산 비용이 비싼 attention은 high-level feature에 대해서만, low-level feature와 high-level feature를 fusion하는 것은 가벼운 CNNs을 이용합니다.
The Real-time DETR.
Overview.

위 그림에서 Backbone은 ResNet을 사용하며, S3, S4, S5은 저-수준, 중간-수준, 고-수준의 feature입니다. 위에서 말했듯, high-level feature에 대해서만 Attention을 수행합니다. 그 layer를 AIFI(Attention based Intra-scale Feature Interaction)이라고 부릅니다. 이는 일반적인 self-attention과 똑같습니다.
이렇게 만들어진 F5와 S3, S4를 CNNs을 이용해서 fusion을 합니다. 이 layer를 CCFF(CNN-based Cross-scale Feature Fusion)이라고 부릅니다. 이때 fusion cell은 다음과 같이 구성됩니다:

RepBlock은 1x1 conv와 3x3 conv로 이뤄진 모듈로, N개 쌓을 수 있습니다. 이때 N을 적절히 조절함으로써 RT-DETR의 크기와 성능을 조절할 수 있습니다(Scalable). 한편 S3, S4, F5의 해상도를 맞추기 위해 Fusion block에 들어가기 전에 Up sampling(Bilinear interpolation)와 Down sampling(Conv)를 수행합니다. 이는 위 Overview 그림에 있는 노란 block(Conv 1x1)과 파란 block(Conv 3x3)과는 다릅니다.
이 과정을 모두 식으로 정리하면 다음과 같습니다:

이렇게 나온 Output을 이용해서 query를 초기화해줍니다. 이는 불확실성을 기준으로 top-k에 해당하는 query만을 살려서 decoder의 입력으로 사용합니다. 이때 uncertainty는 다음과 같이 계산합니다:

이때 P()는 localization score(like IoU score), C()는 classification score(confidence)입니다. 그리고 localization score와 classification confidence가 모두 높으면 uncertainty는 낮으며, 하나라도 크다면 uncertainty가 크다고 해석할 수 있습니다. 한편, "P와 C가 모두 낮다면 uncertainty가 낮아지지 않나?" 라고 생각할 수 있지만, 기존의 loss가 P()와 C()를 높이는 방향으로 학습하기 때문에 모델의 퇴화가 일어나지 않는다는 가정하에 이런 uncertainty 공식을 만든 것 같습니다.
한편 최종적인 loss에 Uncertainty score를 넣어줌으로써 MLP도 uncertainty를 줄이는 방향으로 학습됩니다. 아래는 최종 loss function들 입니다:

위와 같이 uncertainty 기반 query 초기화는 성능이 좋았는데, 아래는 query들의 IoU Score와 Classification Score의 분포를 나타낸 그림입니다:

그림 6. 에 따르면 IoU Score와 Classification Score가 모두 높은 곳(오른쪽 위)에 Vanilla(초기화 안한 query)보다 제안된 방법으로 초기화된 query가 더 많은 것을 알 수 있습니다. 이는 제안된 방법이 IoU score와 classification score가 높은 상태에서 decoder의 입력으로 들어가기 때문에 훨씬 더 적은 계산으로도 충분히 좋은 성능을 보일 수 있다는 것을 보여줍니다.
Results.
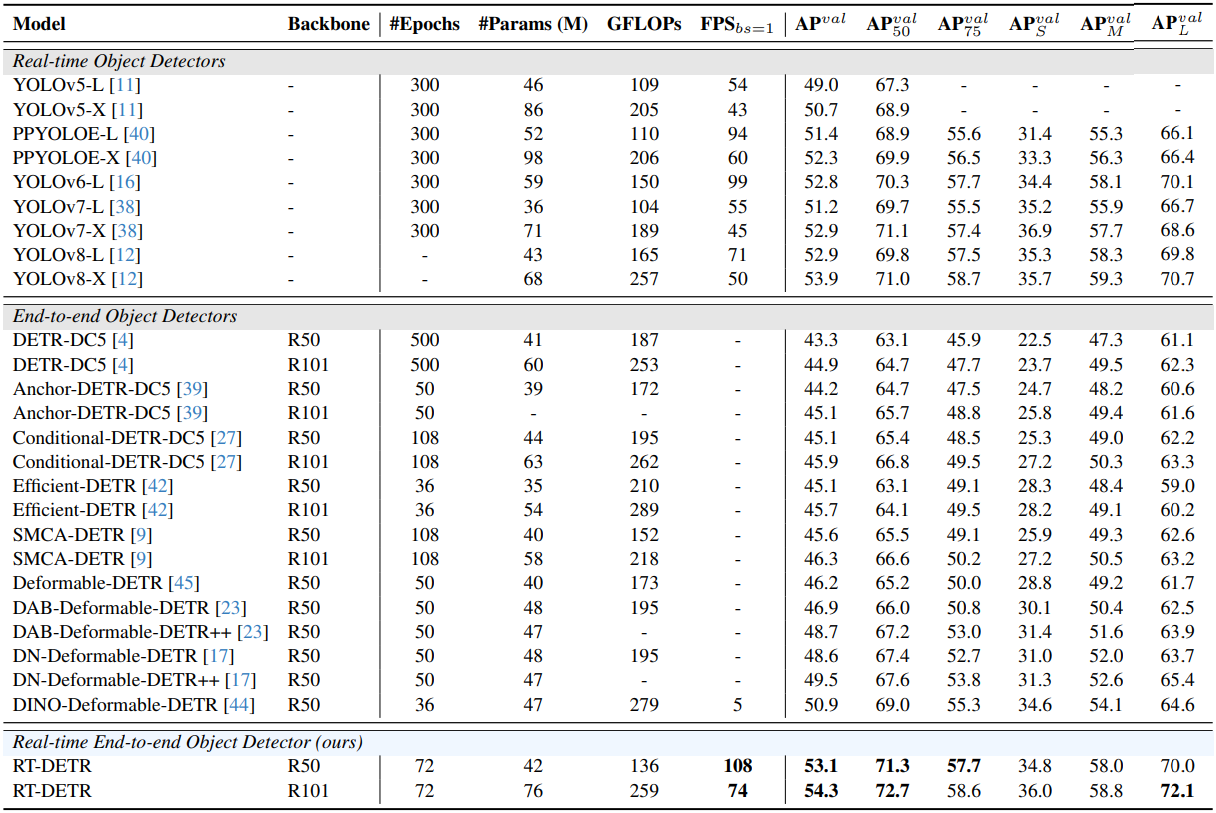

표 2와 그림 1. 은 다른 image detection SOTA모델들과 제안된 방법론을 비교한 표입니다. 위 표에 따르면 제안된 모델(RT-DETR)이 추론 속도(FPS)와 파라미터의 수(# Params), 학습 속도(# Epochs), 성능(AP)의 측면에서 모두 우월함을 보여줍니다.

표 4. 는 위에서 봤던 그림 6. 의 연장선으로, Vanilla query에 비해 제안된 방법으로 query를 초기화하는 것이 더 정확함을 보여줍니다.