
https://arxiv.org/abs/2412.04234
DEIM: DETR with Improved Matching for Fast Convergence
We introduce DEIM, an innovative and efficient training framework designed to accelerate convergence in real-time object detection with Transformer-based architectures (DETR). To mitigate the sparse supervision inherent in one-to-one (O2O) matching in DETR
arxiv.org
Motivation.
Attention 기반의 DETR은 # queries 만큼의 prediction만을 생성하기 때문에 spare supervision이라고 말할 수 있습니다. 한편 YOLO와 같은 detector는 # prediction이 매우 많습니다(그래서 inference시에 NMS를 수행하는 것입니다). 따라서 YOLO와 같은 모델은 dense supervision이라고 말할 수 있습니다. 이렇게 supervision이 많으면, 직관적으로 학습할 것들이 많기 때문에 더 빠른 수렴에 도움이 됩니다. 그렇다고 DETR의 수렴 속도를 늘리기 위해 # queries를 늘리게 되면 attention으로 인한 computational cost가 늘어나기 때문에 오히려 수렴 속도가 느려질 수 있습니다.
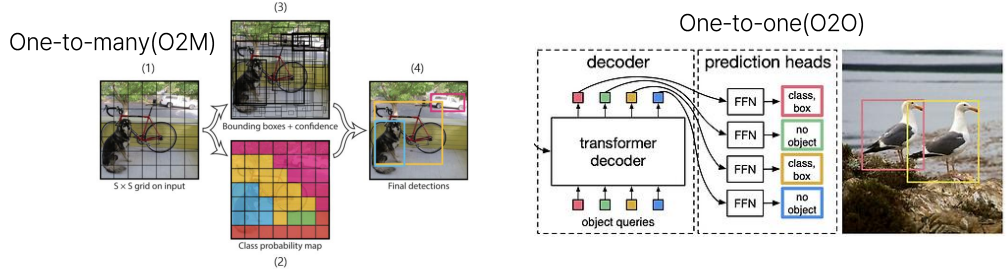
DETR의 경우는 one-to-one(O2O) matching을 수행하기 때문에, 정확히 # queries만큼의 예측만을 수행하며, 그 중 몇개의 prediction은 positive sample(GT와 matching이 되어서 GT방향으로 학습이 되는 샘플)이 되며, 나머지는 negative sample(GT와 matching이 되지 않아서 background로 예측하도록 학습이 되는 샘플)이 됩니다. 이는 DETR이 O2O matching algorithm인 hungarian matching algo. 를 prediction과 GT를 매칭하는데 사용하기 때문입니다(YOLO는 SimOTA라는 동적인 matching algo. 를 사용합니다. 이를 통해 하나의 GT에 대해 여러 개의 prediction이 매칭됩니다. 이를 one-to-many matching(O2M)이라고 부릅니다). 아래의 그림은 O2O와 O2M의 차이를 그림으로 나타낸 것입니다:
그렇다고 YOLO를 사용하기에는 이전에도 살펴봤듯(2025.08.26 - [[CoIn]/[(Video) Object Detection]] - [CoIn] 논문 리뷰 | DETRs Beat YOLOs on Real-time Object Detection (Zhao et al., 2023))
[CoIn] 논문 리뷰 | DETRs Beat YOLOs on Real-time Object Detection (Zhao et al., 2023)
https://arxiv.org/abs/2304.08069 DETRs Beat YOLOs on Real-time Object DetectionThe YOLO series has become the most popular framework for real-time object detection due to its reasonable trade-off between speed and accuracy. However, we observe that the spe
hw-hk.tistory.com
NMS라는 후처리 기법을 이용해야 inference를 수행할 수 있기 때문에 1-stage라는 이점이 사라집니다. 또한 NMS의 hyperparameter를 사람이 직접 설정해야하며, 동적으로 상황에 맞게 설정할 수 없기 때문에 모든 상황에 있어서 안정적인 예측을 할 것이라는 보장이 없습니다. 이런 동기속에서 DETR의 수렴 속도를 높이기 위한 다양한 연구들이 진행되었습니다. 이를 해결하기 위한 방향으로는 크게 두 방향이 존재합니다:
(1) slow convergence: 애초의 느린 수렴 속도를 높이는 방향으로 진행합니다. 수렴 속도가 느린 이유는 앞서 말했듯, DETR은 YOLO와 달리 sparse supervision을 제공하기 때문입니다. 따라서 O2M matching과 같은 supervision을 NMS를 사용하지 않으면서 DETR에 적용해야하는 문제가 있습니다.
이를 해결하기 위해 이전에는 # queries를 늘림으로써 supervision의 개수를 늘리려고 했습니다. 하지만 시간 복잡도가 늘어나는 문제는 감당해야합니다. 따라서 해당 논문에서는 # queries가 아닌 # targets 을 데이터 증강을 통해 늘림으로써 positive sample의 개수를 늘립니다. 이는 # queries 가 늘어난 것이 아니기 때문에 계산 복잡도는 그대로이며, GT와 matching이 되는 prediction의 개수가 늘어나기 때문에 빠른 수렴 속도를 보장합니다.
(2) Low-quality matches: YOLO는 일반적으로 8k 이상의 예측을 만들어내지만, DETR의 경우는 100개에서 300개 정도의 예측을 만들어내기 때문에 하나 하나의 prediction이 소중합니다. 하지만 랜덤하게 초기화되는 queries들로 인해 low-quality matches들이 늘어나며, 수렴이 늦어지게 됩니다. 이는 RT-DETR(Zhao et al., 2023) 등에서 나오는 query initialization(selection)으로 해결할 수 있는데, 이때 query는 이미지 상에서 우세한 target의 근처로 초기화되는 경향이 있습니다.
즉, 우세한 target 하나 근처에 여러 개의 prediction들이 생성되는데, DETR은 O2O matching이기 때문에 해당 target(GT)와는 단 하나의 prediction이 매칭됩니다. 이는 곧 우세한 target 근처에 초기화된 나머지 prediction들이 low-quality matches가 된다는 의미입니다(confidence는 높지만 IoU score는 매우 낮은 matches). 기존의 focal loss(loss 함수의 일종)는 low-quality matches들에 의한 loss를 무시하다시피 했지만 해당 논문에서는 low-quality matches들로부터 loss가 잘 흐를 수 있도록 loss 함수를 새롭게 만듬으로써 더 빠른 수렴 속도를 달성합니다.

그림 2. 에서 (a)는 일반적으로 YOLO에서 사용하는 O2M matching을 보여줍니다. (a)에 따르면 하나의 target에 대해서 여러 개의 prediction들이 matching될 수 있기 때문에 dense supervision입니다. 반면 (b)에 따르면 하나의 target에 대해서는 단 하나의 prediction들만 matching될 수 있기 때문에 target 근처의 prediction들은 negative samples들이 됩니다. 즉, sparse supervision입니다. 제안된 방법론인 (c)는 target의 개수를 늘림으로써 target과 매칭되는 samples(positive samples)들의 개수를 늘립니다. 이는 O2O보다 더 많은 supervision을 제공합니다. (d)는 IoU가 작지만 confidence score가 높은 low-quality matches의 예시입니다.
여기서 다른 얘기지만 궁금한게, 그림 2의 (c)에서 보이듯, 입력 이미지를 4개로 증강해서 입력으로 사용하면, 그 만큼 # params, 혹은 sequence length가 늘어나기 때문에 계산 비용이 비싸지 않나? 원본 이미지의 해상도는 그대로 했다고 하니까...

그림 3. 은 Hungarian(O2O)와 SimOTA(O2M)에서의 # positive samples를 비교한 그림입니다. 이에 따르면 O2O matching이 O2M에 비해 # pos samples이 작음을 알 수 있습니다. 즉, O2O는 sparse supervision을 제공합니다.
Method.
Preliminaries.
image detection에서 loss를 계산할 때는 모든 target들에 대해, 각 target당 matching된 prediction들마다의 loss를 구해 모두 더하는 방식으로 loss를 구합니다. 이를 식으로 나타내면 다음과 같습니다(N = # targets, M = # matches for the target):
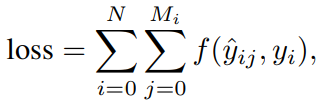
이때 f는 loss 함수로, 일반적으로 image detection에서는 focal loss를 사용합니다:

일반적으로 하나의 image에서는 foreground object(target, GT)보단 background가 훨씬 많기 때문에, 모델은 background에 대해 더 잘 맞히게 된다(foreground보다). 이를 방지하기 위해 모델이 충분히 강한 확신을 가지고 예측을 한다면 loss를 조금만 흘려보내 이미 잘 맞히는 것에 대해서는 더 잘 맞힐 필요가 없음을 학습시킵니다.
위 식을 보면,
y=1일 때(=해당 prediction이 GT와 matching이 되었을 때),
그때의 확률 p가 크다면(=GT라는 강한 확신을 갖고 있다면),
(1-p)^(gamma)에 의해 log(p)가 어떻든 loss의 크기가 작아지게 됩니다.
이를 통해 y=1일 때, 모델이 강한 확신을 갖고 있다면 loss를 줄이는 것입니다.
반대로 y=0일 때(=해당 prediction이 GT와 matching이 되지 않았을 때),
그때의 확률 p가 작다면(=GT라는 약한 확신=background라는 강한 확신),
p^(gamma)에 의해 log(1-p)가 어떻든 loss의 크기가 작아지게 됩니다.
이를 통해 y=0일 때, 모델이 강한 확신을 갖고 있다면 loss를 줄이는 것입니다.
VariFocal Loss (VFL).
VFL은 FL에서 한 단계 더 나아갑니다:

q는 IoU score를 말합니다. alpha는 가중치 상수입니다. negative(GT와 matching이 안된) sample의 경우는 FL과 유사합니다. 한편, pos sample에 대해서는 q를 이용한 가중치를 추가하는데,
예를 들어,
y=1일 때(=해당 prediction이 GT와 matching이 되었을 때)의 식을 보면,
() 안에 식은 IoU와 classification을 균형있게 학습하기 위한 loss 식입니다.
그러나, () 안에 식이 어떻든 q(=IoU score)가 낮으면 loss가 작아지게 됩니다.
즉, # targets을 늘림으로써 생기는 low-quality matches들은 q가 작기 때문에, 많이 생겼지만 전혀 학습에 도움이 되지 않는 상황이 발생합니다.
따라서 해당 논문의 저자는 low-quality matches들이 학습에 기여할 수 있도록 loss 함수를 수정합니다.
Matchability-Aware Loss.
MAL은 VFL과 달리 y=1일 때, 식의 가장 앞에 q를 곱하지 않음으로써 low-quality라고 학습에 참여되지 않는 것을 방지했습니다:

아래의 그림은 low-quality matches에 대한 loss를 VFL와 MAL에 대해서 비교한 그림입니다:

VFL과 달리 MAL는 low-quality match에 대해서 loss가 정상적으로 잘 흐르며, high-quality match에 대해서는 VFL과 동일한 수준으로 loss가 흐릅니다.
Results.
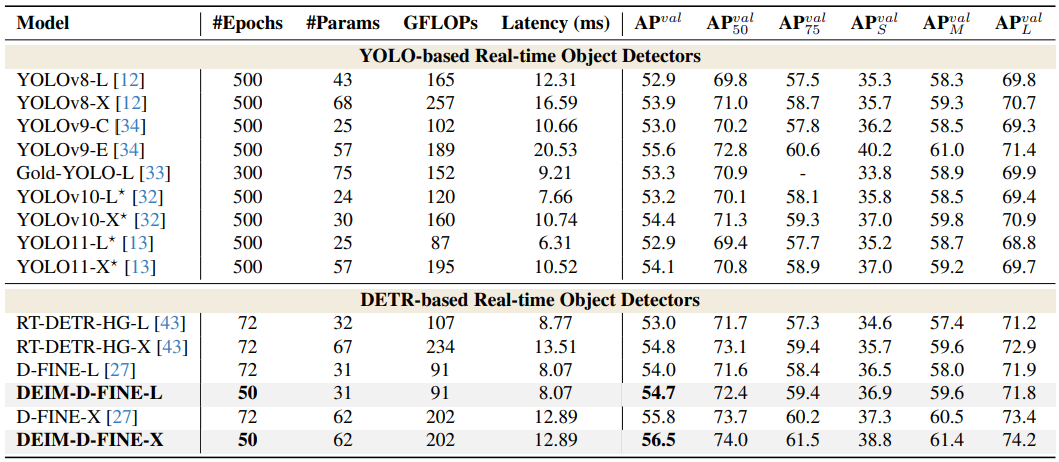
표 1. 은 다른 모델들과 제안된 방법론(DEIM)으로 학습된 모델들의 수렴 속도(# epoch)과 성능(AP)를 비교한 표입니다. 이에 따르면 해당 방법론이 다른 방법론들에 비해 성능은 더 좋게 학습되며 수렴 속도는 더 빠름을 알 수 있습니다.

표 6. 은 ablation study의 일종으로, RT-DETR(Zhao et al., 2023)과 D-FINE(Peng et al., 2024)에 해당 방법론을 차례로 적용했을 때의 성능을 비교한 표입니다. 이에 따르면 제안된 방법론의 모든 과정이 꼭 필요하며, 다양한 모델들에도 적용할 수 있는 방법론임을 보여줍니다.
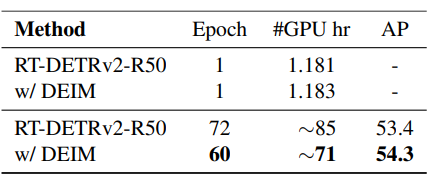
표 7. 은 RT-DETR을 fine-tuning 시켰을 때, 기존 모델 대비 더 나은 성능을 만드는 데에 학습 epoch 수와 GPU 사용 시간을 정리한 표입니다. 이를 통해 제안된 방법론이 더 빠른 수렴속도를 보장한다는 것을 알려줍니다.