
https://arxiv.org/abs/1910.07467
Root Mean Square Layer Normalization
Layer normalization (LayerNorm) has been successfully applied to various deep neural networks to help stabilize training and boost model convergence because of its capability in handling re-centering and re-scaling of both inputs and weight matrix. However
arxiv.org
Abstract.
LayerNorm은 입력들과 가중치 행렬 모두의 re-centering(재-중심화)와 re-scaling(재-스케일링)을 도와주며, 훈련을 안정화하고 모델 수렴을 도와주기 때문에 다양한 심층 신경망들에 잘 사용되어왔습니다. 하지만, LayerNorm은 계산량이 많아 신경망의 추론 속도를 크게 낮출 수 있습니다. 따라서 해당 논문의 저자는 LayerNorm에서 re-centering(평균으로 빼주는 것)은 불필요하다고 가정하며, RMSNorm(Root Mean Squre LayerNorm)을 제안합니다. RMSNorm은 한 layer 내의 뉴런들의 합산된 입력들을 정규화하며(LayerNorm과 유사), RMS를 이용하여 re-scaling과 implicit 하게 학습률에 적응(learning rate adaptation)할 수 있도록 합니다. RMSNorm은 LayerNorm보다 더 효율적입니다(평균과 분산이라는 계산 비용이 큰 통계량을 사용하지 않아도 되기 때문에). 또한 pRMSNorm(partial RMSNorm)을 통해 합산된 입력들의 p%만을 이용하여 추론함으로써 위 속성들을 부여할 수도 있습니다.
Introduction.
Ba et al.은 한 layer내의 뉴런들의 평균과 분산을 이용해 정규화함으로써 훈련을 안정화하고, 모델의 수렴을 가속화하는 LayerNorm을 제안했습니다. 이는 단순하며, 훈련 케이스(batch)들 사이의 의존성을 요구하지 않는 점에서(BatchNorm 대비 LayerNorm이 갖는 장점), 컴퓨터 비전이나 음성 인식, 자연어 처리 분야에서 큰 성공을 거두었습니다. 심지어 RNN을 사용하여 가변 길이 시퀀스들을 처리하는 경우에는 LayerNorm이 필수적입니다(RNN과 같은 아키텍처에서 BatchNorm을 사용하면 훈련 케이스마다 달라지는 시퀀스 길이에 따라 BatchNorm의 효과가 떨어질 수 있습니다).
하지만, LayerNorm은 계산 오버헤드를 발생시킵니다. 작고 얕은 신경망들은 LayerNorm이 별로 들어가지 않기 때문에, 이는 큰 문제가 아니지만, 만약 모델들이 크고 깊어진다면 계산 오버헤드는 큰 문제가 될 수 있습니다. 결과적으로, 더 빠르고 더 안정적인 훈련으로부터(LayerNorm으로부터) 오는 이득들은 훈련 단계당 증가되는 계산 비용에 의해 상쇄 되어버립니다:
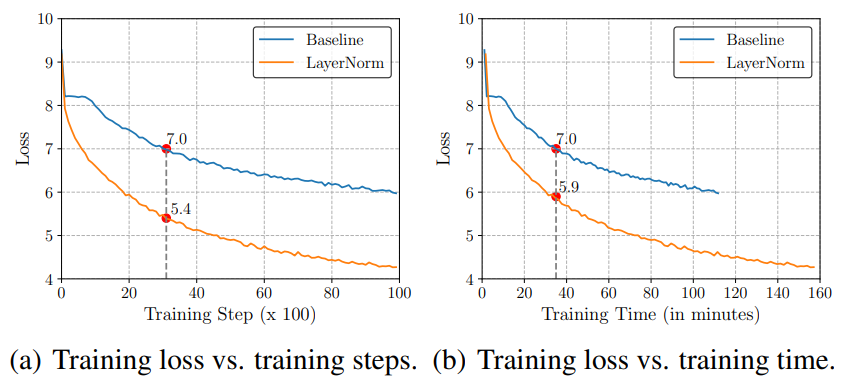
그림 1. 은 이를 보여줍니다. (a)를 보면 같은 training step에서 baseline은 7.0의 loss를 기록했을 때, LayerNorm을 적용한다면 5.4의 loss를 기록함으로써, training step의 관점에서는 LayerNorm이 1.6%p의 loss상의 이득을 볼 수 있었습니다. 하지만, (b)를 보면 baseline이 7.0의 loss를 기록할 때, LayerNorm은 5.9의 loss를 기록함으로써, LayerNorm의 계산 지연으로 인해 학습 시간의 측면에서는 1.1%p 정도의 이득만 볼 수 있었습니다.
LayerNorm의 성질중에서 (학습의) 안정화에 기여하는 것으로 알려진 주요한 특징은 re-centering 입니다. 하지만 저자들은 평균 정규화가 hidden state들이나 model gradient들의 분산을 줄이는데 기여하지 않는다고 가정하며, RMSNorm을 제안합니다. 이는 한 layer 내의 뉴런에 대해 오직 평균 제곱근(RMS) 통계량 만으로 정규화합니다. 이는 re-centering 속성은 없지만, layer activations들의 크기를 안정화하는 것은 돕습니다(re-scaling).
또한 저자들은 입력들의 부분집합에서 RMS를 추정함으로써 더욱 계산 효율적인 NormLayer를 만들었습니다. 합산된 입력들이 i.i.d 구조를 갖는다고 가정하며, 오직 처음 p%의 합산된 입력들만을 이용하여 전체를 추정하는 pRMSNorm을 제안합니다.
(... 성능 자랑 ...)
Related Work.
심층 신경망들이 겪는 하나의 bottleneck은 내부 공변량 변화(internal covariate shift) 문제였습니다. layer의 입력 분포는 이전 layer들이 업데이트됨에 따라 변할 수 있으며, 이는 훈련을 상당히 느리게 합니다. 이를 해결하기 위한 방법이 바로 Normalization입니다.
Note: 내부 입력(출력)값들의 분포가 변하면 학습이 느려지는 원인은 다양합니다.
가장 직관적인 이유는:
- Layer L의 파라미터가 업데이트되면 해당 layer의 출력 분포가 변하며, 그 다음 Layer L+1 은 이전에 학습한 가중치가 더 이상 새로운 입력에 대해서 최적이 아니게 되며, 새로운 분포에 맞춰 다시 가중치를 수정해야 합니다.
- 입력 분포가 한쪽으로 쏠리는 등 분포가 제어되지 않으면, Activation Function이 제 기능을 못할 수도 있습니다. 예를 들어, sigmoid나 tanh 함수를 보면, 입력값이 너무 커지거나 너무 작아지면, 그래프의 기울기가 거의 0이 되며, 역전파시 가중치 업데이트가 전혀 일어나지 않게 됩니다. 하지만 Normalization을 통해 입력 분포를 강제로 평균 0, 분산 1 근처로 모아주면, 활성화 함수의 기울기가 가장 가파른 구간(가운데)을 사용하게 하여 학습이 잘 되게 만들어줍니다.
- 정규화는 학습률에도 제약을 걸 수 있습니다. 예를 들어, 어떤 layer의 입력은 값이 0.1인데, 다른 layer의 입력은 1000인 상황을 가정합니다. 이 상태에서 큰 값에 적절한 큰 학습률을 적용하면, 작은 값에 대한 가중치들이 튀어버려 학습이 망가질 수 있습니다. 그래서 가장 불안정한 layer를 기준으로 학습률을 아주 낮게(보수적으로) 잡아야 합니다. 결과적으로 학습률이 작아지기 때문에, 수렴까지 가는 데 시간이 오래걸립니다.
loffe and Szededy는 각 훈련 mini batch로부터 추정된 평균과 분산 통계량들에 기초하여 activations들을 안정화하는 BatchNorm을 제안함으로써 이를 해결합니다. 하지만, RNN과 같이 가변 길이 시퀀스를 처리하는 경우, BatchNorm의 mini batch 의존성이 문제가 될 수 있습니다.
이런 문제를 해결하기 위해, Salimans and Kingma는 가중치 행렬을 가중치 벡터들의 길이로 정규화하는 WeightNorm을 제안하며, Ba et al.은 동일한 layer로부터 통계량을 계산하는 LayerNorm을 제안합니다. (... 다양한 Normalization 방법들 ...) 하지만, 이런 연구들은 여전히 원래 정규화 구조를 따르며, re-centering과 re-scaling을 위해 전체 입력들로부터 얻은 평균 통계량을 사용합니다. 하지만 RMSNorm은 re-centering을 제거하고 오직 합산된 입력들을 오직 RMS만을 이용하여 정규화합니다.
Background.
우선 FFN 상황에서의 LayerNorm에 대해 간략히 검토합니다. 입력 벡터 x가 주어졌을 때, FFN은 출력 벡터 y로 projection합니다:

wi는 i번째 출력 뉴런에 대한 가중치 벡터값을, bi는 편향, f는 비선형 함수를 뜻합니다. 이 기본 네트워크는 internal covariate shift 문제를 겪을 수도 있으며, 이는 gradient 안정성에 부정적 영향을 미치고, 모델 수렴을 지연시킵니다. 따라서 이 변화를 줄이기 위해 LayerNorm은 이들의 평균과 분산을 고정하기 위해 다음과 같이 정규화를 수행합니다:

a_bar는 a의 정규화된 대안으로서 동작하며, g는 표준화된 입력들을 re-scale하는 데 사용되는 파라미터이며 1로 초기화됩니다. μ와 σ는 평균과 표준편차이며, 이는 각각 다음과 같이 계산됩니다:

RMSNorm.
LayerNorm이 성공할 수 있었던 이유로 가장 잘 알려진 설명은 re-centering과 re-scaling입니다. re-centering은 모델이 입력들과 가중치들 모두에서의 이동 노이즈에 민감하지 않게 하며, re-scaling은 입력들과 가중치들이 무작위로 스케일링될 때, 출력 표현들이 온전하게 유지되도록 도와줍니다. 저자들은 re-scaling이 LayerNorm의 성공에 대한 이유라고 분석하며, re-centering은 중요하지 않다고 보았습니다. 따라서 오직 re-scaling에반 집중하여, RMS 통계량만을 이용하는 RMSNorm을 제안합니다:

합산된 입력들의 평균이 0일 때, RMSNorm은 정확히 LayerNorm과 동일하며, RMSNorm은 LayerNorm과 같이 합산된 입력들을 re-centering하지는 않지만, 해당 속성이 그렇게 중요하지는 않았다는 점을 실험을 통해 증명합니다. RMS는 입력들의 quadratic mean을 측정하여, RMSNorm에서 합쳐진 입력들을 sqrt(n)으로 스케일링 된 단위 구(unit sphere)로 강제합니다. 이렇게 함으로써 출력 분포는 입력 및 가중치 분포들의 스케일링과 관계없이 layer activatons들의 안정성을 부여합니다.
Invariance는 정규화 후의 모델 출력이 그것의 입력 및 가중치 행렬에 따라서 변하는지를 측정합니다. Ba et al.은 서로 다른 정규화 방법들이 서로 다른 Invariance들을 보여주며, 이는 모델의 견고성에 큰 기여를 합니다. 우선 기본적인 RMSNorm은 다음과 같습니다:

RMSNorm은 가중치 행렬과 입력 입력 재스케일링(g)에 대해 모두 Invariance합니다. 이는 RMS의 다음과 같은 선형성 덕분입니다:

가중치 행렬이 delta라는 인자에 의해 스케일링된다고 가정합니다(W' = (delta)W). RMS의 선형성 덕분에, 최종 레이어 출력에는 영향을 미치지 않습니다:

만약, 스케일링이 오직 개별 가중치 "벡터"들에 대해서만 수행된다면, 서로 다른 스케일링 인자들은 RMS의 선형성 속성을 깨뜨리기 때문에, 이 invariance는 더 이상 성립하지 않습니다. 유사하게, 만약 우리가 입력에 delta라는 인자로 스케일을 강제한다면(x'=(delta)x), RMSNorm은 위와 같은 이유로 invariance가 유지됩니다.
위 분석은 오직 입력들과 가중치 행렬을 스케일링하는 것의 영향만을 고려합니다. 그러나, 신경망은 일반적으로 SGD(Stochastic Gradient Desence) 방식으로 훈련되며, 모델 gradient의 견고성은 파라미터들의 업데이트와 모델 수렴에 매우 결정적입니다. 그러므로 RMSNorm이 모델의 수렴을 돕는다는 것을 증명하기 위해서는 RMSNorm에서의 모델 gradient들의 속성을 조사해야 합니다.
손실함수가 L이라고 할 때, 역전파를 수행하기 위해 파라미터 g와 b에 대한 gradient를 구하면 다음과 같습니다:
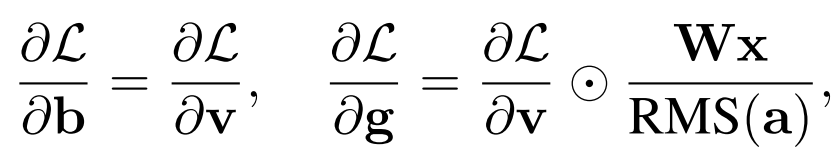
두 gradients 보두 위에서 설명한 RMS의 선형성으로 인해 x와 가중치 행렬 W의 스케일링에 대해 invariance 성질을 갖습니다. 이 벡터 파라미터들과 달리, 가중치 행렬 W의 gradient는 더 복잡합니다:

논문의 저자는 R항이 입력(x)와 가중치 행렬(W) 스케일링 둘 다와 음의 상관관계를 갖는다는 것을 발견했습니다. delta라는 스케일을 입력 x(x' = (delta)x) 혹은 가중치 행렬 W(W' = (delta)W)에 할당하면, 다음과 같은 R'을 구할 수 있습니다:
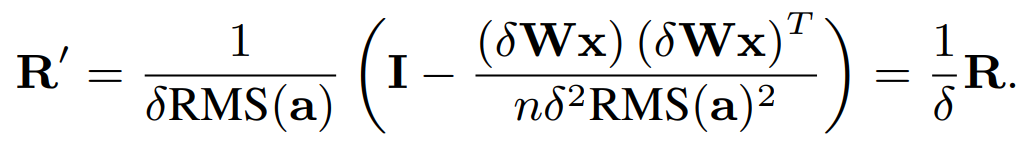
만약 스케일링 된 항인 R'을 다시 gradient of W 식에 넣으면, 이는 전체 입력 스케일링에 대해서 W에 대한 L의 gradient가 스케일에 대해서 invariance 하다는 것을 알 수 있습니다(gradient of W에서 x := (delta)x가 되어있고, W := (delta)W 이기 때문에, R' = 1/(delta)R이 delta에 대한 scale factor를 상쇄할 수 있습니다). 입력 스케일링에 대해 gradient of L/W의 민감도를 줄이는 것은 해당 gradient의 매끄러움을 보장하고 학습의 안정성을 개선합니다.
한편, R과 입력 또는 가중치 행렬과의 음의 상관관계는 Implicit Learning Rate Adaptor로서 동작하며, 이는 gradient 들의 norm을 동적으로 제어합니다(만약 입력이나 가중치 값이 너무 커진다면, gradient를 그에 반비례하게 줄여주는 효과를 말합니다). 이것이 RMSNorm이 LayerNorm보다 단순하지만 학습이 더 잘되는 이유가 됩니다.
pRMSNorm.
RMSNorm의 re-scaling invariance 특징은 linearity로 인해 가능한 것입니다. 한 layer 내의 뉴런들이 i.i.d 의 구조를 종종(?) 가진다는 점에서 해당 논문의 저자들은 RMS가 이 뉴런들의 부분집합으로부터 추정될 수 있다고 주장합니다. 이를 partial RMSNorm이라고 부릅니다. 아직 정규화되지 않은 입력 a가 주어졌을 때, pRMSNorm은 RMS 통계량을 a의 처음 p% 요소들로부터 다음과 같이 추론할 수 있습니다:
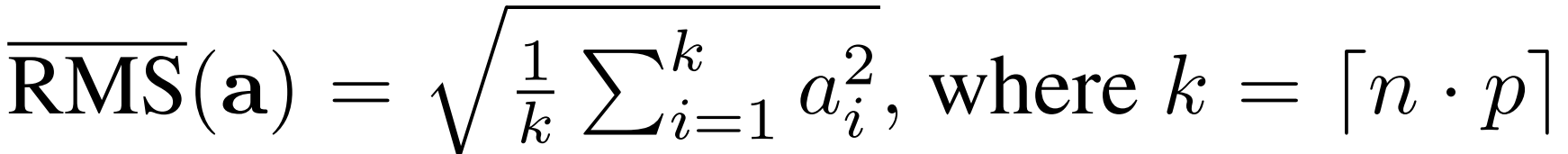
여기서 k는 RMS 추정에 사용된 요소들의 수를 의미합니다. linearity는 여전히 존재하며, 이는 pRMSNorm 또한 RMSNorm과 똑같은 invariance 특징을 공유한다는 것을 의미합니다. 하지만 부분적으로 추정된 RMS는 biased estimation이며, 이는 종종 부정확합니다. 따라서 pRMSNorm으로부터 저자들은 gradient instability(그래디언트 불안정성)을 관찰했으며, 거기서 gradient는 폭발하는 경향이 있었습니다.
Experiments.
(... 좋은 성능 기록 ...)