https://arxiv.org/pdf/1710.05941v1
Swish: A Self-Gated Activation Function
Abstract.
심층 신경망에서 활성화 함수의 선택은 훈련 과정과 task 성능에 상당한 영향을 미칩니다. 현재(2017년), 가장 성공적이로 널리 사용되는 활성화 함수는 Rectified Linear Unit(ReLU)입니다. ReLU에 대한 다양한 대안들이 제안되어 왔지만, 아무도 대체하지 못했습니다. 해당 연구는 Swish라고 하는 새로운 활성화 함수를 제안하며, f(x) = x * sigmoid(x) 입니다. 저자는 다양한 실험들을 통해 Swish가 ReLU보다 더 잘 동작하는 것을 확인했습니다.
Introduction.
모든 심층 신경망에는 linear transformation과 활성화 함수 f()가 존재합니다. 이때 활성화 함수는 심층 신경망 훈련의 성공에 주된 역할을 하며, 현재(2017년) 가장 성공적이고 널리 사용되는 활성화 함수는 ReLU(f(x) = max(x, 0))입니다. ReLU를 가진 심층 신경망들은 ReLU 함수의 입력이 양수일 때만 gradient가 흐르기 때문에, sigmoid나 tanh를 가진 신경망들보다 훨씬 쉽게 최적화되며, 이런 단순함과 효과성 덕분에, ReLU는 딥러닝 커뮤니티 전반에 걸쳐 사용되는 기본적인 활성화 함수가 되었습니다.
해당 연구에서는 Swish라고 불리는 새로운 활성화 함수를 제안합니다. Swish는 매끄럽고(smooth), 비단조(non-monotonic) 함수이며 f(x) = x * sigmoid(x) 로 정의됩니다. Swish는 심층 신경망들에서 일관되게 ReLU와 대등하거나 능가하는 성능을 기록했으며, ImageNet에서, ReLU들을 Swish 유닛으로 교체하는 것은 분류 정확도를 0.9% 향상시킵니다. 이는 Inception V3에서 Inception-ResNet-v2로 가면서 1년동안 1.3% 정확도 향상을 기록했다는 점에서 유의미한 수치입니다.
Swish.

σ(x) = (1+exp(-x))^-1 일 때, swish는 다음과 같이 정의됩니다. 이때 swish 그래프는 그림 1.과 같습니다:

ReLU와 유사하게 Swish는 위로는 unbounded이며, 아래로는 bounded입니다. 하지만 ReLU와 달리 Swish는 매끄러우며 비단조적입니다. swish의 도함수는 다음과 같습니다:

이때 Swish의 1차 및 2차 도함수는 그림2. 와 같습니다:

약 1.25보다 작은 입력들에 대해, 도함수는 1보다 작은 크기를 가지며, 역설적으로 Swish가 ReLU보다 더 나은 성능을 보임으로써, ReLU의 gradient 보존 속성(즉, x>0 일 때 1의 도함수를 갖는 것)이 더 이상 뚜렷한 이점이 아닐지도 모른다는 것을 암시합니다. 해당 연구에서는 BatchNorm을 사용할 때는 ReLU를 사용한 신경망보다 더 깊은 훈련이 Swish에서 가능하다는 것을 발견했습니다.
Swish를 다음과 같이 정의한다면, Swish는 ReLU의 일반화로 볼 수 있는데:
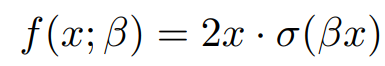
만약 β가 0이면, Swish는 선형 함수 f(x) = x가 되며, β→∞ 함에 따라, sigmoid는 0-1 함수에 접근하며, Swish는 ReLU가 됩니다. 이는 Swish가 선형함수와 ReLU 함수 사이를 interpolate한다는 것을 의미하며, 봅간의 정도는 모델에 의해 제어될 수도 있습니다. 만약 β를 학습 가능한 파라미터로 설정한다면, 이를 Swish-β라고 부릅니다.
이런 Swish의 설계는 LSTM에서의 gating을 위한 sigmoid에서 영감을 받았습니다. 그리고 Swish에서는 자기 자신을 gating하기 위해 동일한 값을 사용하며, 이를 self-gating이라고 부릅니다. 여러 개의 스칼라를 입력받아야 하는 일반적인 gating과 달리, self-gating은 오직 단일 스칼라만을 입력으로 요구합니다. 이는 Swish같은 self-gating activation function들이 ReLU 함수 같은 point-wise function을 쉽게 대체할 수 있도록 합니다.
왜 Swish가 다른 활성화 함수들을 능가하는지 증명하는 것은 어렵지만, Swish의 특징들(위로는 unbounded, 아래로는 bounded, smooth하고, non-monotonic한 성질)이 모두 유리한 방향으로 이끌었다고 생각합니다. 아래의 그림 3.은 다른 일반적인 활성화 함수들을 보여줍니다:

Unboundedness는 거의 0에 가까운 gradient로 인해 생기는 saturation을 피한다는 점에서 유용합니다. sigmoid나 tanh와 같은 고전적인 함수들은 해당 함수들의 선형 영역에 머무르기 위해 조심스럽게 초기화되어야 했습니다. ReLU는 x>0 이기만 하면 saturation을 피할 수 있었기 때문에, tanh대비 큰 개선이었습니다. 이는 매우 중요해서 최근에 제안된 거의 모든 활성화 함수들은 위로 unbounded 합니다.
또한 아래로 bounded 한 것은 강력한 정규화(regularization) 효과로 인해 유리할 수 있습니다. 큰 음수 입력들을 망각할 수 있기 때문에 극한에서 0에 수렴하는 함수들은 훨씬 더 큰 정규화 효과를 유도합니다. Swish는 그럼에도 불구하고 ReLU와 softplus와는 다른데, 그것은 음수 출력을 허용한다는 점입니다. Swish의 non-monotonic한 성질은 표현력을 증가시킬 수 있고, 흐름을 개선할 수 있습니다.
smoothness는 최적화와 일반화에서 유익한 역할을 수항해는데, 그림 5.는 무작위 신경망의 출력을 그림으로 나타낸 것입니다:

ReLU의 경우는 그 함수 자체의 매끄럽지 않은 성질로 인해 날카롭게 형성된 영역들이 많지만, Swish는 출력 자체가 매끄럽습니다. 직관적으로 이런 매끄러운 손실은 최적화 시에 초기화와 학습률에 대한 민감도를 줄이면서 이들을 횡단하기 쉽기 때문에, 최적화에 유리해집니다.
(... 실험 결과들 ...)
https://arxiv.org/abs/1612.08083
Language Modeling with Gated Convolutional Networks
The pre-dominant approach to language modeling to date is based on recurrent neural networks. Their success on this task is often linked to their ability to capture unbounded context. In this paper we develop a finite context approach through stacked convo
arxiv.org
Language Modeling with Gated Convolutional Networks(GLU)
Abstract.
현재(2016년)까지 언어 모델링에 대한 지배적인 접근법은 순환 신경망(RNN)에 기반합니다. 언어 모델링 task에서 RNN이 성공할 수 있었던 이유는 RNN이 무제한의 문맥(unbounded context)을 포착할 수 있기 때문입니다. 해당 연구에서는 stacked convolution을 통해 finite context 접근법을 개발했으며, 이는 순차적인 토큰들에 대한 병렬화(parallelization)를 가능하게 합니다.
Note: 이때 당시에는 무제한의 context를 허용하는 것까지는 필요없으며, RNN 구조에 의한 병렬화 불가능성이 가장 해결하고자 하는 문제였던 것 같습니다. 따라서 어느정도 유한한 context를 보고 다음 token을 생성하는 대신 합성곱 연산을 수행하는 부분에 대해서는 병렬화를 함으로써 효율성을 높인 것입니다.
Introduction.
통계적 언어 모델들은 단어 시퀀스의 확률 분포를 다음과 같이 추정합니다:

w는 단어 인덱스입니다. 신경망 기반의 언어 모델들은 단어들을 연속 공간에 임베딩함으로써 이 문제를 다룹니다. 현재(2017년) 언어 모델링의 SOTA는 LSTM 네트워크에 기반하며, 이는 이론적으로 긴 의존성들을 모델링할 수 있습니다. 해당 논문에서는 gated convolution network를 소개하며, 이를 언어 모델링에 적용합니다.
convolution network는 적층(stacked)될 수 있으며, 큰 문맥 크기들을 표현하고 더 추상적인 특징들을 통해 더 큰 문맥들을 표현하는 계층적 특징들을 추출할 수 있습니다. 이렇게 convolution을 사용하면, kernel 너비 k에 대해서 O(N/k) 연산들을 통해 장기 의존성을 모델링할 수 있습니다. 대조적으로 일반적인 RNN은 사슬 구조(chain structure)로 인해 sequence length에 선형적인 O(N)의 연산을 요구합니다.
또한 이런 계층적인 구조는 주어진 문맥 크기에 대한 비선형성들의 수가 사슬 구조(RNN)에 비해 줄어들기 때문에, 기울기 소실 문제를 완화할 수 있습니다. 또한 RNN의 다음 출력은 이전 hidden state에 의존하며, 이는 sequence 요소들에 걸친 병렬화를 가능하게 하지 않습니다. 하지만 convolution은 모든 입력 단어들의 계산이 동시에 수행될 수 있기 때문에 병렬화에 매우 유리합니다.
Approach.
해당 논문에서 RNN에서 전형적으로 사용되는 recurrent connections들을 gated temporal convolution들로 대체합니다. 신경망 기반 언어 모델들은 각 단어에 대한 확률 P(wi|hi)를 예측하기 위해 w0, w1, ..., wN에 대한 문맥의 표현 H = [h0, h1, ..., hN]을 생산합니다. 이때 recurrent function f 에 대해 hi = f(hi-1, wi-1)을 통해 계산되며, 이는 순차적인 과정이기 때문에 i에 걸쳐 병렬화할 수 없습니다. 따라서 f와 w를 합성곱함으로써 시간적 의존성을 없애고, 문장의 개별 단어들에 걸쳐 병렬화할 수 있도록 합니다.
RNN과 비교하여, 문맥의 크기는 유한하지만, 실제 task를 수행하는 데에 있어서 무한한 문맥은 필요하지 않으며, 합성곱을 사용해도 충분히 큰 문맥을 유지할 수 있음을 실험으로 증명합니다. 아래는 모델의 아키텍처입니다:
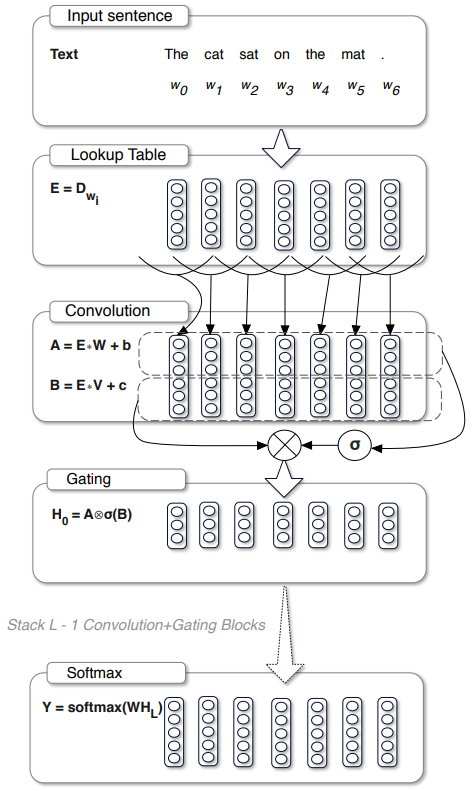
각 단어들은 lookup table D에 저장된 벡터 임베딩에 의해 표현되며, hidden layers들 h0, ..., hL은 다음과 같이 표현됩니다:

입력들을 합성곱할 때, hi가 미래 단어들로부터의 정보를 포함하지 않도록 주의해야 하며(causal), 이를 합성곱 입력들을 이동시킴으로써 해결합니다. 각 레이어의 출력은 게이트들 σ(X*V+c)에 의해 modulated된 선형 projection인 X*W+b입니다. LSTM과 유사하게, 해당 gate들은 계층구조에서 전달되는 정보를 제어하는 역할을 수행합니다. 이를 GLU(Gated Linear Unit)이라고 부릅니다.
마지막 layer에서 단어 예측을 얻기 위한 가장 간단한 선택은 softmax를 사용하는 것이지만, 큰 vocab size에 대해서는 계산이 비효율적입니다. 따라서 이를 개선하여, 매우 빈번한 단어들에 대해 더 높은 용량을 할당하고 희귀한 단어들에 더 낮은 용량을 할당하는 adaptive softmax를 사용합니다.
Gating Mechanisms.
gating mechanism은 정보가 네트워크에서 흐르는 경로를 제어하며, RNN에서 유용하게 적용되어 왔습니다. 예를 들어, LSTM은 입력 및 망각(input and forget) gates들에 의해 제어되는 별도의 cell을 통해 장기기억이 가능합니다. 해당 gate가 없다면 각 timestep마다 이뤄지는 연산들을 통해 정보가 쉽게 사라질 수 있습니다.
대조적으로, convolution network는 같은 종류의 기울기 소실이 문제가 되지 않으며, 그저 네트워크가 어떤 정보가 레이어들의 계층 구조를 통해 전파되어야 할지만을 제어하면 됩니다. 이는 모델로 하여금 어떤 단어들이나 특징들이 다음 단어를 예측하는 데 관련이 있는지 선택하도록 허용하기 때문에, 이 매커니즘이 언어 모델링에 유용합니다.
Oord et al. (2016b)는 gate tanh unit이라고 부르는 gate network를 제안했습니다:

GTU의 gradient는 다음과 같습니다:
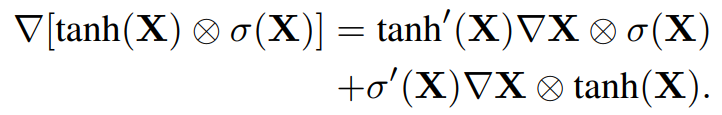
이는 layer가 쌓임에 따라 tanh'와 σ'에 의해 gradient가 점차 사라질 수 있습니다. 반면, GTU의 gradient는 다음과 같습니다:

이는 downscaling이 없는 σ로 인해 gradient가 유지되는 성질을 갖습니다. 이는 multiplication skip connection으로 생각할 수 있으며, 이는 gradient들이 layer들을 통해 흐르는 것을 돕습니다.
(... 실험 얘기 ...)
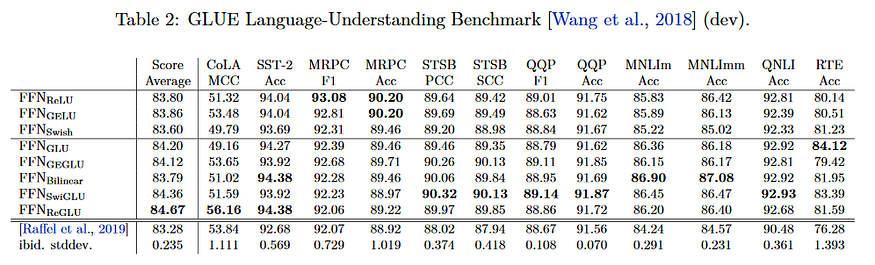
SwiGLU Activation Function
SwiGLU는 위 두가지를 결합하여 만든 함수입니다:

이는 다른 activation function 대비 많은 계산량이 단점이지만, 이를 뛰어넘는 높은 성능으로 인해 Qwen등 많은 LLM들에 사용중인 activation function입니다. 아래는 SwiGLU와 다른 Activation function들을 사용했을 때의 성능 비교입니다: