
https://arxiv.org/abs/2405.04434
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
We present DeepSeek-V2, a strong Mixture-of-Experts (MoE) language model characterized by economical training and efficient inference. It comprises 236B total parameters, of which 21B are activated for each token, and supports a context length of 128K toke
arxiv.org
Introduction.
읿반적으로 LLM의 지능은 파라미터의 수가 증가함에 따라 향상되는 경향이 있습니다. 그러나 그 성능은 더 큰 훈련용 컴퓨팅 자원들과 추론 처리량의 감소라는 단점으로 돌아옵니다. 이는 LLM들이 광범위하게 사용하는데 제약을 겁니다. 이를 해결하기 위해, DeepSeek-V2를 제안합니다. 이는 MoE 언어 모델이기 때문에, 경제적인 훈련과 효율적인 추론이 가능합니다. 이는 238B 파라미터를 가지며, 각 토큰에 대래 21B개의 파라미터가 활성화되고, 128K의 context length를 갖습니다.
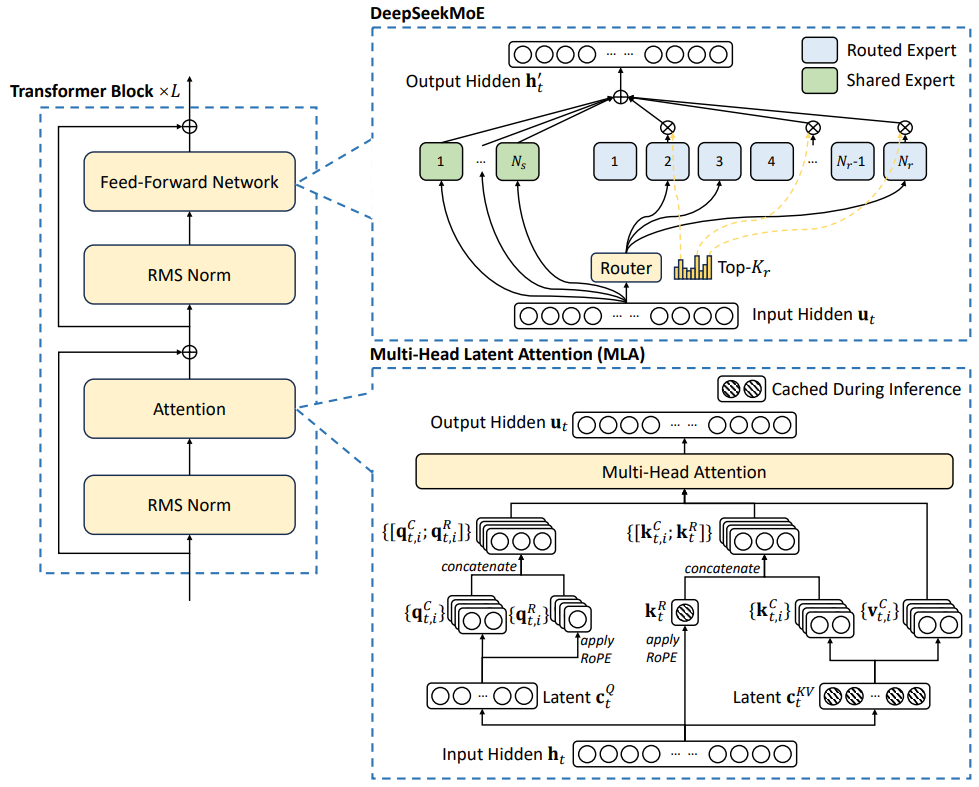
DeepSeek-V2에서는 Attention Module들과 FFNs들을 MLA(Multi-head Latent Attention)와 DeepSeekMoE로 최적화했습니다. Attention mechanism의 관점에서, MQA와 GQA, KV cache등이 제안되었지만, 이러한 방법들은 caching되는 KV들의 개수를 줄임으로써 attention의 문제를 해결합니다. 이런 딜레마를 해결하고자 저자들은 MLA를 사용합니다. 이는 low-rank key-value joint compression을 갖춘 attention mechanism입니다. 실험적으로 MLA는 MHA와 비교하여 우수한 성능을 달성하며, 추론 동안 KV cache를 상당히 줄이며, 추론 효율성을 높여줍니다.
FFNs에 대해서는 DeepSeekMoE 아키텍처를 따릅니다:
[CoIn] 논문 리뷰 | Mixtral of Experts & DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language M
https://arxiv.org/abs/2401.04088 Mixtral of ExpertsWe introduce Mixtral 8x7B, a Sparse Mixture of Experts (SMoE) language model. Mixtral has the same architecture as Mistral 7B, with the difference that each layer is composed of 8 feedforward blocks (i.e.
hw-hk.tistory.com
(... 성능과 강화학습(alignment)관련 얘기 ...)
Architecture.
DeepSeek-V2는 Transformer 아키텍처를 대부분 따르며, 이때 각 transformer block의 Attention module과 FFNs들은 새로운 아키텍처를 사용합니다. Attention에 대해서는 MLA를 사용하며, 이는 low-rank key-value joint compression을 활용합니다. 이는 추론 시간에 key-value cache의 병목을 제거하며, 효율적인 추론을 도와줍니다. FFNs에 대해서는 DeepSeekMoE 아키텍처를 사용합니다.
Multi-Head Latent Attention: Boosting Inference Efficiency
전통적인 transformer 모델들은 보통 Multi-Head Attention(MHA)를 사용하지만, 이는 decoding 단계에서 무거운 KV cache가 추론 효율성을 제한하는 병목이 됩니다. 따라서 KV cache를 줄이기 위해 MQA나 GQA가 제안되었습니다. 이는 더 작은 KV cache를 요구하지만, 그것들의 성능은 MHA와 일치하지는 않습니다. 이에 저자들은 Multi-Head Latent Attention(MLA)를 사용합니다.
먼저 표준 MHA 매커니즘은 다음과 같습니다. d를 임베딩 차원, n을 attention head의 수, dh를 헤드당 차원, 그리고 ht를 attention layer에서의 t번째 토큰 입력이라고 가정합니다. 표준 MHA는 먼저 qt, kt, vt를 계산합니다:

그런 다음, qt, kt, vt는 n개의 head들로 잘라집니다:

Wo는 출력의 projection matrix입니다. 추론 동안, 추론을 가속화하기 위해서 모든 key와 value들은 cache될 필요가 있습니다. 따라서 MHA는 각 토큰에 대해 2*n*d*l(l=# of layer)개의 요소들을 cache할 필요가 있습니다. 모델의 배포에서, 이 무거운 KV cache는 최대 배치 크기와 스퀀스 길이를 제한하는 큰 병목입니다.
MLA의 핵심은 key와 value들의 low-rank joint compression입니다:

여기서 c^KV는 key와 value들을 위해 압축된 latent vector이며, c^KV의 차원인 dc는 dh*n보다 매우 작습니다. W^DKV는 down-projection matrix이며, W^UK와 W^UV는 각각 key 와 value들을 위한 up-projection matrix 입니다. 추론 동안, MLA는 오직 c^KV만 캐시할 필요가 있습니다. 즉, KV cache는 오직 dc*l 개의 요소만을 가집니다. 다음은 MLA 내의 KV joint compression이 어떻게 KV cache를 줄이는지 직관적으로 보여줍니다:

여기에서 더 나아가, 훈련 동안 activation memory를 줄이기 위해, 쿼리들에 대해서도 low-rank compression을 수행합니다(이는 추론 중 KV cache의 크기를 줄여주지는 않습니다):

아래의 표는 다른 Attention mechanisms들과 MLA간의 KV cache를 비교한 것입니다:

Decoupled Rotary Position Embedding
DeepSeek-V2는 이렇게 KV cache를 줄이기 위해 MLA를 사용하는데, 여기에 RoPE(Rotary Position Embedding)을 사용하면 문제가 될 수 있습니다. RoPE는 토큰의 위치(t)에 따라 벡터를 회전시키는건데, 압축된 벡터(c)를 풀어서(WUK를 곱함) key를 만든다음, RoPE를 적용해야 하는 것입니다. 즉 MLA와 RoPE는 양립할 수 없다는 것입니다.
일반적으로 MLA를 사용할 때는 추론 속도를 높이기 위해, 원래 식인 Query x (Key 복원 행렬 x 압축된 Key) 대신, (Query x Key 복원 행렬) x 압축된 Key를 사용합니다. 이렇게 Key 복원 행렬(WUK)를 Query 쪽으로 미리 합쳐버리면, 추론할 때마다 거대한 Key를 다시 계산할 필요 없이 압축된 상태 그대로 연산할 수 있습니다. RoPE는 회전행렬를 곱하는 것이며, 이 회전은 토큰의 위치마다 달라집니다.
Key 복원 행렬 다음에 위치별 회전을 수행해야 하므로, Key 복원 행렬을 Query 쪽으로 미리 합칠 수가 없게 되는 것입니다. 어쩔 수 없이 매번 압축을 풀어서 거대한 Key를 만들고, RoPE를 적용한 후, 연산을 수행해야 하는데, 이렇게 되면 압축을 한 의미가 사라집니다. 따라서 Decoupled RoPE를 사용합니다. 이는 content(내용)과 position(위치)를 분리하여 따로 처리하는 것입니다.
query와 key를 각 두 부분으로 나눕니다:
- content part (압축된 내용 담당, c)
- 여기는 RoPE를 적용하지 않습니다.
- RoPE가 없으니, 위에서 말한 행렬 흡수 트릭을 쓸 수 있습니다.
- 즉, 압축된 상태로 매우 빠르게 연산 가능합니다.
- RoPE part (위치 정보 담당)
- 위치 정보를 담기 위해 아주 작은 별도의 벡터(qr, kr)를 만듭니다.
- 오직 여기에만 RoPE를 적용하며
- 이 부분은 압축되지 않지만, 차원이 매우 작아서(64) 메모리를 별로 안 씁니다.
- 최종 연산(concatenation)
- 최종 Query = [압축된 내용 Query] + [RoPE 먹인 작은 Query]
- 최종 Key = [압축된 내용 Key] + [RoPE 먹인 작은 Key]
- 이렇게 둘을 이어 붙여서(concat) Attention 연산을 수행합니다.
이를 수식으로 정리하면 다음과 같습니다:

DeepSeekMoE
FFNs에 대해서는 DeepSeekMoE의 아키텍처를 사용합니다. DeepSeekMoE는 두 가지 핵심 아이디어로 이뤄집니다: 1) 전문가들을 더 자세히 분할하는 것. 2) expert들의 전문화(지식 중복을 완화)하기 위해 shared experts들과 routed experts로 분기하는 것입니다. 동일한 수의 활성화 혹은 전체 expert parameters들로, DeepSeekMoE는 GShard와 같은 전통적인 MoE 아키텍처들을 큰 격차로 능가합니다. MoE의 구조는 다음과 같습니다:

(자세한 내용은 이전 DeepSeekMoE 논문 리뷰 블로그에)
Auxiliary Loss for Load Balance
또한 MoE 관련 통신 비용들을 제한하기 위해 device-limited routing 매커니즘을 사용합니다. expert parallelism이 사용될 때, routing된 experts들은 다수의 장치들에 걸쳐 분산됩니다. 이때, 각 토큰에 대해 MoE 관련 통신 빈도는 토큰들이 타겟으로 하는 전문가들이 들어있는 장치들의 수에 비례합니다. DeepSeekMoE는 fine-grained하게 experts들을 분할했기 때문에, activation된 experts들의 수는 클 수 있으며, 이로 인해 MoE 관련 통신 비용은 더 클 수 있습니다.
따라서 routing된 experts들은 naive한 top-k를 통해 선택되는 것이 아닌, 각 토큰의 목표 experts들이 최대 M개의 장치들에 분산될 것을 보장합니다. 즉, 각 토큰에 대해, 가장 점수가 높은 M개의 장치들을 선택합니다. 그 후, M개의 장치들 위에 있는 experts들 사이에서 top-k 선택을 수행하는 것입니다. M≥3 일 때, device-limited routing과 top-k routing이 거의 일치하는 성능을 보임을 실험적으로 발견했습니다.
DeepSeekMoE와 마찬가지로 load balancing을 위해서 auxiliary loss를 추가합니다. 이는 MoE를 학습할 때 매우 필수적인데, 1) unbalanced load는 routing collapse(일부 전문가들만이 완전히 훈련되며, 나머지 전문가들은 훈련이 전혀 안되는 상황)의 위험을 높일 수가 있습니다. 또한 2) expert parallelism이 사용될 때, unbalanced load는 계산의 효율성을 감소시킵니다. 따라서 DeepSeek-V2는 expert-level load balancing과 device-level load balancing, communication load balancing을 제어하기 위한 세 종류의 보조 손실을 사용합니다.
(expert-level load balancing과 device-level load balancing은 이전 DeepSeekMoE 와 똑같습니다)
Communication load balancing은 각 장치의 communication이 균형 잡히는 것을 보장합니다. 비록 device-limited routing mechanism이 각 장치의 송신 통신이 제한되는 것을 보장할지라고, 만약 특정 장치가 다른 장치들보다 더 많은 토큰들을 수신한다면, 실질적인 통신 효율성 또한 영향을 받을 수 있습니다. 이 문제를 완화하기 위해 다음과 같은 communication balance loss를 사용합니다:

이는 각 장치가 최대 MT개의 hidden state들을 다른 장치들로 전송할 때, 각 장치가 다른 장치들로부터 약 MT/D개의 hidden state들만을 수신하도록 장려합니다. communication balance loss는 장치들 사이의 균형 잡힌 정보 교환을 보장하며, 효율적인 통신들을 촉진합니다.
load balance loss들이 균형 잡힌 부하를 장려하는 것을 목표로 하는 반면, 그것(loss)들이 엄격한 부하 균형을 보장할 수는 없다는 것을 인정해야 합니다. 따라서, 훈련 동안 불균형한 부하에 의해 만들어지는 추가적인 계산 낭비를 완화하기 위해, device-level token-dropping을 사용합니다. 이는 먼저 각 장치에 대한 평균 계산 예산을 계산한 후, 각 장치에서 가장 낮은 친화도 점수(routing score)를 가진 토큰들을 계산 예산이 충족할 때까지 drop합니다. 이런 방식으로 추론 동안 토큰을 drop할지 말지를 효율성 요구사항들에 따라 유연하게 결정할 수 있으며, 훈련과 추론 사이의 일관성을 보장할 수 있습니다.
(... 성능과 RL관련 ...)