
https://sustcsonglin.github.io/blog/2024/deltanet-1/
DeltaNet Explained (Part I) | Songlin Yang
DeltaNet Explained (Part I) A gentle and comprehensive introduction to the DeltaNet Contents This blog post series accompanies our NeurIPS ‘24 paper - Parallelizing Linear Transformers with the Delta Rule over Sequence Length (w/ Bailin Wang, Yu Zhang, Y
sustcsonglin.github.io
Linear Attention as RNN
바닐라(기본) Softmax Attention Mechanism은 강력하긴 하지만, sequence length에 대해 quadratic complexity를 갖습니다. 즉, 문장의 길이가 2배 늘어나면, 계산량은 4배가 늘어나며, 길이가 10배면 계산 복잡도는 100배가 되는 것이며, 이는 긴 문서를처리할 때 치명적인 문제가 됩니다. 이때 단일 헤드를 가정하는 표준적인 softmax attention을 가정하여, 이 문제를 linear attention이 어떻게 해결하는지를 살펴보겠습니다:

Q, K, V는 각각 query, key, value를 말하며, M은 각 위치가 오직 이전 위치들에만 attend 할 수 있도록 보장하는 causal mask입니다(언어 모델의 경우는 다음 단어를 예측할 때 미래의 단어를 보면 안됩니다. 하지만 병렬로 학습을 할 때는 모델이 다음 단어를 참고할 수도 있습니다. 따라서 행렬의 대각선 위쪽(미래 정보)을 -inf로 가려버리는 M을 사용합니다).
Linear Attention이 하는 일은 단순히 softmax 연산자를 제거하는 것입니다:
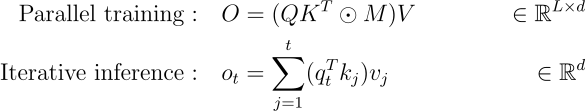
softmax를 제거하는 것만으로는 즉시 계산 복잡도가 줄어들지는 않습니다. 하지만, 이는 linearity를 가능하게 하는데, 특히 associativity(결합 법칙)은 효율성을 크게 향상시키는 방식으로 행렬의 곱을 재구조화할 수 있게 해줍니다. 행렬 곱셈에서 결합 법칙이란 (AB)C = A(BC)가 성립한다는 뜻입니다(A, B, C는 각각 행렬). 따라서 기존의 방식인 (QK^T)V를 사용하면, QK^T로 인해 NxN 행렬(매우 큰 행렬)이 생기며, O(N^2r)라는 계산복잡도가 만들어집니다. 하지만 Q(K^TV)를 사용하면, dxd 행렬이 먼저 생기며, 일반적으로 d는 N보다 훨씬 작으므로 계산량이 획기적으로 줄어듭니다(sequence length N에 대해서는 선형).
훈련을 위해서 연구자들은 subquadratic한 복잡도를 달성하기 위해 이 선형성을 활용할 수 있는 청크 단위 병렬처리(chunkwise parallel) 기술을 개발했으며, 이는 긴 문장을 작은 덩어리(chunk)로 쪼개서 병렬로 처리하는 기술입니다. 예를 들어, 기존의 RNNs의 경우 100단어를 처리하는 과정에서 state를 계산하기 위해서는 1번째 단어를 처리하고, 2번째 단어를 처리하고, ... 이렇게 순차적으로만 진행해야 했습니다. 즉, 앞사람이 끝날 때까지 뒷사람들이 모두 대기해야 합니다. 하지만 Chunkwise Parallel은 100단어를 처리하는 과정을 10단어씩 10개의 chunk로 자른 후, 각 덩어리 내부의 정보(state)를 계산하는 것은 앞 chunk의 결과가 없어도 미리 계산할 수 있기 때문에, 계산을 한 후, state의 선형성과 결합 법칙을 이용해 하나로 합쳐주면 GPU의 병렬 처리 기능을 충분히 활용하며 state를 계산할 수 있습니다.
추론을 위해, 위에서 사용했던 Iterative inference 식을 RNNs과 비슷한 형태로 재배열할 수 있습니다. 우선 위 식을 결합 법칙을 이용해 다음과 같이 재배열합니다:

이때 상태 행렬 St를 정의합니다:
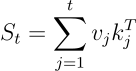
이제는 행렬 전체를 곱하는 관점이 아니라, 시점 t에서의 순차적 처리의 관점으로 바꿀 수 있습니다. St는 현재 시점(t)까지의 모든 과거 정보를 요약해서 담고 있는 그릇이며, vk^T는 벡터끼리 곱해서 행렬을 만드는 외적 연산으로, 이것이 곧 기억이 됩니다. 이를 통해 위 식을 다음과 같은 RNNs의 형식으로 만들 수 있습니다:

출력은 현재 상태 행렬에 query를 곱함으로써 구할 수 있으며, 상태는 이전 상태(St-1)에서 새로운 정보(vk^T)를 더함으로써 얻을 수 있습니다. 이는 완벽히 RNN의 정의와 일치합니다. 위 공식은 linear attention이 본질적으로 key-value 외적을 누적하는 matrix-valued state St를 가진 선형 RNN임을 보여주며, 이는 상태의 크기를 d에서 dxd로 효율적으로 확장할 수 있게 해줍니다.
그렇다면 왜 state의 크기 확장이 중요할까요? 전통적으로 RNN의 hidden dimension은 입력 차원과 동일하거나 비슷한 크기인 경우가 많았는데, 이는 행렬 곱셈 기반의 state update 비용이 비싸기 때문입니다. 기존 RNN은 다음 상태 ht를 계산할 때 Wxt-1과 같은 행렬-벡터 곱셈을 수행합니다. 만약 state의 크기(d)를 키우면, 가중치 행렬 W의 크기는 d^2으로 커집니다. 이로 인해 계산량이 너무 많아져서 속도가 느려지기 때문에, 어쩔 수 없이 상태 크기(d)를 입력 크기와 비슷하게 작게 유지해야 했습니다. 즉, 머리가 좋아지려면 뇌 용량(state)을 키워야 하는데, 뇌가 커지면 생각하는 속도(update)가 너무 느려져서 일부러 뇌를 작게 유지한다는 뜻입니다.
RNNs은 전체 과거 기록을 기억하기 위해 오직 recurrent state에만 의존하며, state의 크기는 특히 정보 검색(retrieval)과 같은 태스크에서 충분한 양의 정보를 기억하는 데 bottleneck이 됩니다. 즉, RNNs은 책 한 권(긴 문맥)을 읽고 나서, 그 내용을 작은 포스트잇 한 장(작은 hidden state)에 요약해야 하는 상황과 같습니다. 당연히 많은 정보가 손실되며, 특히 "100페이지 전에 나왔던 사람 이름이 뭐야?"와 같은 검색(retrieval) 질문을 받으면, 요약된 정보에는 그 세세한 내용이 없어서 대답을 못 합니다. 따라서 기억력(성능)을 높이기 위해서는 포스트잇(d차원의 hidden state)이 아니라 큰 노트(dxd state matrix)가 필요합니다.
Mamba 1이 이 문제를 명시적으로 지적한 이후 하드웨어 효율적인 state 확장을 연구하는 상당한 양의 연구가 진행되었으며, Linear attention 스타일의 외적 기반 업데이터가 state를 효율적으로 키우는 데 최적임이 입증되었습니다. 이 접근법을 사용하면 모든 이전의 key-value 쌍들을 유지하는 대신 오직 St만을 저장하고 업데이트하면 됩니다. 즉, 기존의 transformer들은 과거의 모든 토큰 정보(KV)를 리스트 형래로 줄줄이 달고 다니며(KV Cache), 문장이 길어지면 메모리가 터질 수도 있습니다(이를 해결하기 위해 MQA, GQA와 같은 방법들이 등장했습니다). 하지만 DeltaNet과 같은 Linear Attention 기반의 방법들은 모든 정보를 St라는 하나의 고정된 크기의 행렬에 압축해서 저장합니다. 즉 과거 데이터 리스트를 들고 다닐 필요가 없습니다.
이 최적화는 효율성을 극적으로 향상시키는데, 다음 단어 생성의 시간복잡도를 기존 O(N^2d)에서 O(Nd^2)로, 공간복잡도는 O(Nd)에서 O(d^2)로 줄여줍니다. 이러한 개선점들은 특히 두 가지 시나리오에서 유리하게 만들어줍니다:
- attention의 2차 복잡도가 심각한 병목이 될 수 있는 긴 sequence 모델링
- 계산이 주로 메모리 대역폭에 제한을 받는 생성 과정 동안, KV cache를 제거하는 것은 추론 지연 시간을 상당히 향상시킬 수 있습니다.
No Free Lunch: Key Limitation of Linear Attention
불행히도, linear attention이 항상 좋은 것은 아닙니다. linear attention의 고정된 크기의 state matrix는 모든 과거 정보를 완벽하게는 보존할 수 없음을 의미하며, 이는 정확한 검색(retrieval)을 특히 어렵게 만들 수 있습니다. 앞서 Linear Attention이 메모리 효율이 좋다고 했지만, 그에는 대가가 따르는 것입니다.
Linear Attention은 key-value associative memory(St)를 구현하는데, 이는 key-value 사이의 외적들의 합입니다. 즉, Linear Attention은 이 메모리 S를 v1k1^T + v2k2^T + v3k3^T + ... 의 형태로 차곡차곡 더해서 만듭니다. 모든 키가 단위 길이로 정규화되었다고 가정할 때, 특정 키 q(=ki)와 연관된 값을 검색하려고 하면, 다음과 같은 메모리를 얻을 수 있습니다:

메모리 S에 쿼리 q를 곱해서 값을 꺼내볼 수 있으며, 위 식과 같이 검색의 결과가 나오는 것입니다. 이때 vj는 찾고 싶은 정답이지만, ∑... 는 에러 항이 됩니다. 다른 key들(kj)이 간섭을 일으켜서 생기는 노이즈입니다. 찾고 싶은 것은 i인데, j들이 방해하는 것입니다. 이러한 검색 에러 항을 최소화하려면, 모든 j≠i 에 대해서 kj^Tki=0 이어야 합니다. 즉, 모든 키가 서로 직교해야 합니다.
그러나 d차원의 공간에서는 최대 d개의 직교 벡터만 가질 수 있습니다. 즉, 헤드의 차원(d)이 64라면, 서로 간섭 없이 완벽하게 저장할 수 있는 정보는 딱 64개뿐인 것입니다. 만약 문장의 길이가 64를 넘어가면 필연적으로 키들이 서로 겹치기 시작하고(직교가 깨짐), 노이즈가 발생하여 기억력이 떨어질 수 있습니다. 이것이 왜 헤드의 차원을 늘리는 것이 도움이 되는지를 설명합니다. 벡터 공간에 서로 다른 key-value 쌍을 저장할 수 있는 더 많은 공간을 제공하기 때문입니다.
Vanilla linear attention은 언어 모델링에서 softmax attention보다 성능이 큰 차이로 저조했습니다. 이에 대한 주된 원인은 메모리의 과부하입니다. key-value associative memory 시스템에서는 기존의 정보를 지우는(erase) 능력 없이 오직 새로운 key-value associative memory를 추가(add)할 수만 있기 때문입니다. 이는 시퀀스가 길어질수록 누적되는 검색 에러로 이어져 성능을 저하시킵니다. 즉, 시간이 지나서 잊어버리는 게 아니라, 너무 많은 정보가 들어와서 서로 섞이고 방해해서 기억을 못한다는 것입니다.
최근 GLA나 Mamba와 같은 게이트가 달린 Linear attention의 변형들은 forgetting mechanism을 도입함으로써 언어 모델링 태스크에서 표준 attention과의 성능 격차를 상당히 좁힐 수 있었습니다. 그러나 이 모델들은 여전히 문맥 내 검색(in-context retrieval) 및 정확한 복사 능력에서 근본적인 도전에 직면해 있습니다...
Linear attention과 RNN 사이의 밀접한 관계를 고려할 때, 연구자들이 forgetting gating mechanism으로 linear attention을 강화하고 싶어 하는 것은 놀라운 일이 아닙니다. 다음과 같은 forgetting mechanism이 있으면:

α(dxd 행렬, 0-1 사이의 값을 가지며, 이전 기억을 얼마나 남길지 결정합니다)를 어떻게 정의하는지에 따라서 모델의 종류가 달라질 수 있습니다:
- For Decaying Fast Weight: αt = λ (단순 스칼라 상수값으로 감쇠)
- For GLA(Gated Linear Attention): αt = sigmoid(w)T ... (게이트를 학습해서 동적으로 조절)
- For Mamba1 / Mamba2: SSM 이론에 기반한 더 정교한 게이팅 방법
DeltaNet: Linear Attention with Delta Rule
Delta Rule은 신경망에서 사용하는 오류 수정 학습 원칙입니다. 이는 우리가 원하는 것(target)과 우리가 실제로 얻은 것(prediction) 사이의 차이(delta)에 기반하여 모델의 파라미터를 조정하는 것입니다. 이는 단순히 정보를 입력받는 게 아니라 "내가 틀린 만큼 고친다"는 개념입니다. 이를 직관적으로 이해하기 위해, 아이에게 과녁을 조준하는 법을 가르친다고 상상해볼 수 있습니다. 만약 너무 왼쪽으로 쏘면 오른쪽으로 조정하라고 하고, 너무 오른쪽이면 왼쪽으로 조정하라고 할 것입니다. 이때 조정의 크기는 그들이 얼마나 빗나갔는지에 달려있으며, 이 개념이 Delta Rule에 직접적으로 반영되어 있습니다.
DeltaNet은 이 오류 수정의 원칙을 linear attention에 적용한 것입니다. 단순히 key-value 외적을 누적하는 대신, 예측 오차에 기반하여 업데이트합니다:

기존 Linear Attention과 달리 St-1kt는 기존 지식으로 예측한 값을 뜻하며, vt-St-1kt는 실제 값(vt)과의 오차를 의미합니다. 이때 β는 학습률의 역할을 수행합니다. 이 업데이트 규칙을 이해하는 또 다른 방법이 있습니다. St-1kt를 메모리에서 현재 키 kt와 연관된 오래된 값(old value)을 검색해 오는 것으로 생각할 수 있습니다. 동일한 키에 대해서 새로운 값 vt를 마주했을 때, 맹목적으로 덮어쓰는 대신 옛날 기억(St-1kt)와 새 기억(vt) 사이에서 균형(interpolation)을 맞출 수 있습니다:

이때 동적으로 정의되는 βt=0 일때는 메모리 내용을 그대로 유지하며(보존), 1일때는 오래된 연관 값을 새로운 값으로 완전히 대체합니다. 따라서 다음과 같이 Delta Rule을 이해할 수 있습니다:
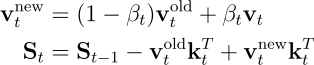
MQAR(Multi-Query Associative Recall)은 최근 인기 있는 합성 벤치마크로, O(N^2) 미만의 모델들의 in-context associative recall 능력을 측정하는 것을 목표로 합니다. MQAR 태스크는 다음과 같이 작동합니다:
input: A 4 B 3 C 6 F 1 E 2 → A ? C ? F ? E ? B ? ...
(the correct) output : 4, 6, 1, 2, 3 ...
기존의 gate convolution이나 recurrent model들은 이 태스크에서 성능이 저조하지만, DeltaNet은 눈에 띄게 강력한 성능을 보여줍니다. 이는 매우 중요한데, MQAR 성능이 실제 언어 모델링 태스크에서의 Associative-Recall 적중률과 강하게 상관관계가 있기 때문입니다:

또한 MQAR보다 더 포괄적인 벤치마크인 MAD에서도 실험을 수행했습니다:

DeltaNet이 왜 다른 Linear Attention 기반의 모델들 대비 검색을 잘 하는 이유는 loss function에 있습니다. DeltaNet의 gradient update 규칙은 매 timestep t에서 원하는 출력(vt)과 예측된 출력(St-1kt)사이의 평균 제곱 오차(MSE)를 gradient desent를 사용해 순차적으로 최소화하는 방법입니다:
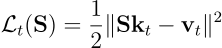
이를 미분하여 풀어보면 정확히 DeltaNet의 업데이트 규칙이 나옵니다:

즉, 매 timestep에서 검색 에러의 최소화를 목표로 하기 때문에, 정확한 검색을 위해 큰 에러를 줄이는 것이 중요한 associative recall과 같은 태스크에서 이상적인 것입니다. 반면 Vanilla Linear Attention은 linear loss function을 사용합니다:

이를 미분하면 단순한 더하기가 나옵니다:
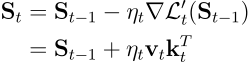
즉, 기존의 방식은 유사도를 높이는 것이 목표였지, 에러를 줄이는 것이 목표는 아니었습니다. 따라서 Linear Attention은 좋은 것을 더할 뿐 틀린 것을 고치는 것은 하지 않는 것입니다.