
0. 텍스트 전처리
텍스트 전처리는 풀고자 하는 문제의 용도에 맞게 텍스트를 사전에 처리하는 작업입니다. 요리를 할 때 재료를 제대로 손질하지 않으면, 요리가 엉망이 되는 것처럼 텍스트에 제대로 전처리를 하지 않으면 뒤에서 배울 자연어 처리 기법들이 제대로 동작하지 않습니다.
1. 영어 처리
1.1 대소문자 통합
대소문자를 통합하지 않는다면 컴퓨터는 같은 단어를 다르게 받아들일 수 있습니다. 따라서 python 의 내장 함수 .lower() 와 .upper() 를 통해 간단하게 통합할 수 있습니다.
s = 'AbCdEfGh'
str_lower = s.lower()
str_upper = s.upper()
print(str_lower, str_upper)
# abcdefgh ABCDEFGH
1.2 정규화
문자열에서 특정 문자열을 정규화 해야하는 경우가 있습니다. 예를 들어, 아래의 경우 UK 는 United Kingdom 으로, US 는 United States 로, 날짜 포멧은 뒤에가 년도로 확실히 구분될 수 있도록 바뀌어야합니다.
한편, 정규 표현식을 통해 특정 문자들을 편리하게 지정하고 추가, 삭제할 수 있습니다. 따라서 데이터 전처리에서 정규 표현식을 많이 사용합니다. python 에서는 정규 표현식을 지원하는 re 패키지를 제공합니다.
정규 표현식의 대표적인 문법은 다음과 같습니다.
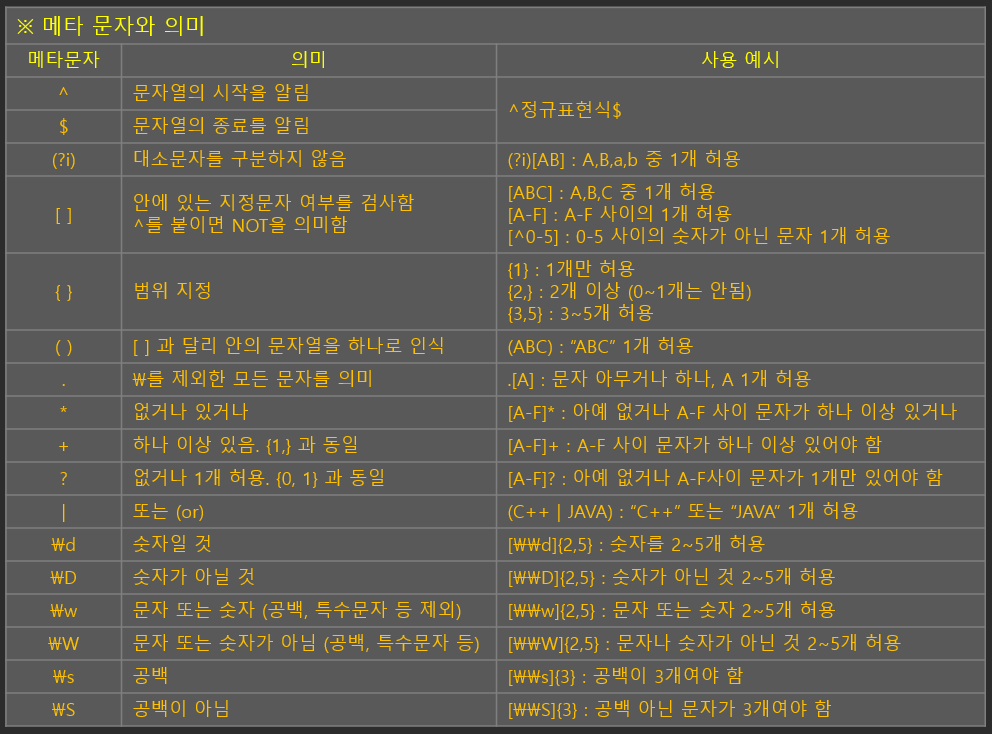
.match() .search()
정규 표현식을 활용하여 .match() 와 .search() 를 사용할 수 있습니다.
.match() 메소드는 컴파일한 정규 표현식을 이용해 문자열이 정규 표현식과 맞는지 검사하는 메소드입니다.
.search() 는 .match() 와 다르게, 문자열의 전체를 검사합니다.
check = 'ab?'
print(re.search('a', check))
print(re.match('kka', check))
print(re.search('kka', check))
print(re.match('ab', check))
# <re.Match object; span=(0, 1), match='a'>
# None
# None
# <re.Match object; span=(0, 2), match='ab'>
이때 정규 표현식을 그냥 문자열이 아닌 .compile() 을 통해 만들어준다면 성능이 더 좋습니다.
즉, compile() 을 사용하면 여러 번 사용할 경우 일반 사용보다 더 빠른 속도를 보입니다.
import time
normal_s_time = time.time()
r = 'ab.'
for i in range(1000):
re.match(r, 'abc')
print('일반 사용시 소요 시간: ', time.time() - normal_s_time)
compile_s_time = time.time()
r = re.compile('ab.')
for i in range(1000):
r.match('abc')
print('컴파일 사용시 소요 시간: ', time.time() - compile_s_time)
# 일반 사용시 소요 시간: 0.0016999244689941406
# 컴파일 사용시 소요 시간: 0.0006954669952392578
compile() 을 사용할 때는 re.match() 나 re.search() 가 아닌 compile() 을 통해 얻은 객체를 통해 사용해야 합니다.
.split()
정규 표현식에 해당하는 문자열을 기준을 문자열을 나누는 메소드입니다.
r = re.compile(' ')
print(r.split('abc abbc abcaba'))
r = re.compile('c')
print(r.split('abc abbc abcaba'))
r = re.compile('[1-9]')
print(r.split('asg1g ks2 v3dsf 4a 5asf'))
# ['abc', 'abbc', 'abcaba']
# ['ab', ' abb', ' ab', 'aba']
# ['asg', 'g ks', ' v', 'dsf ', 'a ', 'asf']
.sub()
정규 표현식과 일치하는 부분을 다른 문자열로 교체하는 메소드입니다.(* repalce 와 유사)
sub(* pattern, *string, *replace_string)
print(re.sub('[a-z]', 'abcdefg', '1'))
print(re.sub('[^a-z]', 'abc defg', '1'))
# 1
# abc defg
.findall()
컴파일한 정규 표현식을 이용해 정규 표현식과 맞는 모든 문자(열)을 리스트로 반환하는 메소드입니다.
print(re.findall('[\d]', '1ab 2cd 3ef 4g'))
print(re.findall('[\W]', '!avd@@#Df'))
# ['1', '2', '3', '4']
# ['!', '@', '@', '#']
.finditer()
컴파일한 정규 표현식을 이용해 정규 표현식과 맞는 모든 문자(열)을 iterator 객체로 반환하는 메소드입니다.
iterator 객체를 이용하면 생성된 객체를 하나씩 자동으로 가져올 수 있어서 처리가 편리합니다.
1.3 토큰화(Tokenization)
1.3.1 특수 문자에 대한 처리
단어에 일반적으로 사용되는 알파벳, 숫자와는 다르게 특수문자는 별도의 처리가 필요합니다.
일괄적으로 단어의 특수문자를 제거하는 방법도 있지만 특수문자가 단어에 의미를 가질 때 이를 학습에 반영시키지 못할 수도 있기 때문입니다.
그래서 특수문자에 대한 일괄적인 제거보다는 데이터의 특성을 파악하고, 처리를 하는 것이 매우 중요합니다.
예를 들어, ? 의 경우 의문문을 의미하지만, 이런 특수문자를 삭제한다면 이런 의미를 파악하지 못한체 넘어갈 수 있다는 문제가 있습니다.
1.3.2 특정 단어에 대한 토큰 분리 방법
한 단어이지만 토큰으로 분리할 때 판단되는 문자들로 이루어진 we're, United Kingdom 등의 단어는 어떻게 분리해야 할지 선택이 필요한 경우가 있습니다.we'er 은 한 단어이나 분리해도 단어의 의미에 별 영향을 끼치진 않지만 United Kingdom 은 두 단어가 모여 특정 의미를 가르켜서 분리해서는 안됩니다.그래서 사용자가 단어의 특성을 고려해 토큰을 분리하는 것이 학습에 유리합니다.
1.3.3 단어 토큰화
python 의 내장 함수인 split() 을 사용할 수 있습니다. 기본적으로는 공백을 기준으로 단어를 분리할 수 있습니다.
sentence = 'Time is Gold'
tokens = [x for x in sentence.split(' ')]
tokens
# ['Time', 'is', 'Gold']
토큰화는 nltk 패키지의 tokenize 모듈을 사용해 손 쉽게 구현할 수 있습니다.
단어 토큰화는 word_tokenizer() 를 활용해 구현 가능합니다.
import nltk
nltk.download('punkt')
from nltk.tokenize import word_tokenize
tokens = word_tokenize(sentence)
tokens
# ['Time', 'is', 'Gold']
1.3.4 문장 토큰화
문장 토큰화는 줄바꿈 문자('\n') 를 기준으로 문장을 분리할 수 있습니다.
sentences = 'The world is a beautiful book.\nBut of little use to him who cannot read it.'
print(sentences)
tokens = [x for x in sentences.split('\n')]
tokens
# The world is a beautiful book.
# But of little use to him who cannot read it.
# ['The world is a beautiful book.',
# 'But of little use to him who cannot read it.']
또는 nltk 의 sent_tokenizer() 를 통해 구현할 수도 있습니다.
from nltk.tokenize import sent_tokenize
tokens = sent_tokenize(sentences)
tokens
# ['The world is a beautiful book.',
# 'But of little use to him who cannot read it.']
문장 토큰화에서는 온점(.) 의 처리를 위해 이진 분류기를 사용할 수 있습니다.
온점은 문장과 문장을 구분해줄 수도, 문장에 포함된 단어(* Mr. Smith)를 구성할 수도 있기 때문에 이를 이진 분류기로 분류해 더욱 좋은 토큰화를 구현할 수도 있습니다.
1.3.5 정규 표현식을 이용한 토큰화
토큰화 기능을 직접 구현할 수도 있지만 정규 표현식을 이용해 간단하게 구현할 수도 있습니다.
nltk 패키지는 정규 표현식을 사용하는 토큰화 도구인 RegexpTokenizer 를 제공합니다.
from nltk.tokenize import RegexpTokenizer
sentence = 'Where there\'s a will, there\'s a way'
tokenizer = RegexpTokenizer('[\w]+')
tokens = tokenizer.tokenize(sentence)
tokens
# ['Where', 'there', 's', 'a', 'will', 'there', 's', 'a', 'way']
(* nltk 가 아니더라도 케라스나 TextBlob 을 이용하여 토큰화를 할 수 있습니다.)
from textblob import TextBlob
sentence = 'Where there\'s a will, there\'s a way'
blob = TextBlob(sentence)
blob.words
# WordList(['Where', 'there', "'s", 'a', 'will', 'there', "'s", 'a', 'way'])
1.3.6 기타 토크나이저
- WhiteSpaceTokenizer: 공백을 기준으로 토큰화
- WordPunktTokenizer: 텍스트를 알파벳 문자, 숫자, 알파벳 이외의 문자 리스트로 토큰화
- MWETokenizer: MWE 는 Multi-Word Expression 의 약자로 'republic of korea' 와 같이 여러 단어로 이뤄진 특정 그룹을 한 개체로 취급
- TweetTokenizer: 트위터에서 사용되는 문장의 토큰화를 위해서 만들어졌으며, 문장 속 감성의 표현과 감정을 다룸
1.4 n-gram
n-gram 은 n개의 어절이나 음절을 연쇄적으로 분류해 그 빈도를 분석합니다. n = 1 일때는 unigram, n = 2 일때는 bigram, n = 3 일때는 trigram, n 이 4 이상일때는 n-gram 이라고 부릅니다. 일반적으로는 bigram 을 사용합니다.
from nltk import ngrams
sentence = 'There is no royal road to learning'
bigram = list(ngrams(sentence.split(), 2))
print(bigram)
# [('There', 'is'), ('is', 'no'), ('no', 'royal'), ('royal', 'road'), ('road', 'to'), ('to', 'learning')]
trigram = list(ngrams(sentence.split(), 3))
print(trigram)
# [('There', 'is', 'no'), ('is', 'no', 'royal'), ('no', 'royal', 'road'), ('royal', 'road', 'to'), ('road', 'to', 'learning')]
(* nltk 패키지에 ngrams() 를 사용하거나, textblob 의 .ngrams() 를 사용할 수 있습니다.)
from textblob import TextBlob
blob = TextBlob(sentence)
blob.ngrams(n = 2)
# [WordList(['There', 'is']),
# WordList(['is', 'no']),
# WordList(['no', 'royal']),
# WordList(['royal', 'road']),
# WordList(['road', 'to']),
# WordList(['to', 'learning'])]
blob.ngrams(n = 3)
# [WordList(['There', 'is', 'no']),
# WordList(['is', 'no', 'royal']),
# WordList(['no', 'royal', 'road']),
# WordList(['royal', 'road', 'to']),
# WordList(['road', 'to', 'learning'])]1.5 PoS(parts of Speech) 태깅
Pos 는 품사를 의미하며, Pos 태깅은 문장 내에서 단어에 해당하는 각 품사를 태깅합니다.
(* nltk.pos_tag() 를 통해 사용할 수 있습니다.)
import nltk
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
from nltk import word_tokenize
words = word_tokenize("Think like man of action and act like man of thought")
nltk.pos_tag(words)
# [('Think', 'VBP'),
# ('like', 'IN'),
# ('man', 'NN'),
# ('of', 'IN'),
# ('action', 'NN'),
# ('and', 'CC'),
# ('act', 'NN'),
# ('like', 'IN'),
# ('man', 'NN'),
# ('of', 'IN'),
# ('thought', 'NN')]
Pos 태크 리스트는 다음과 같습니다.
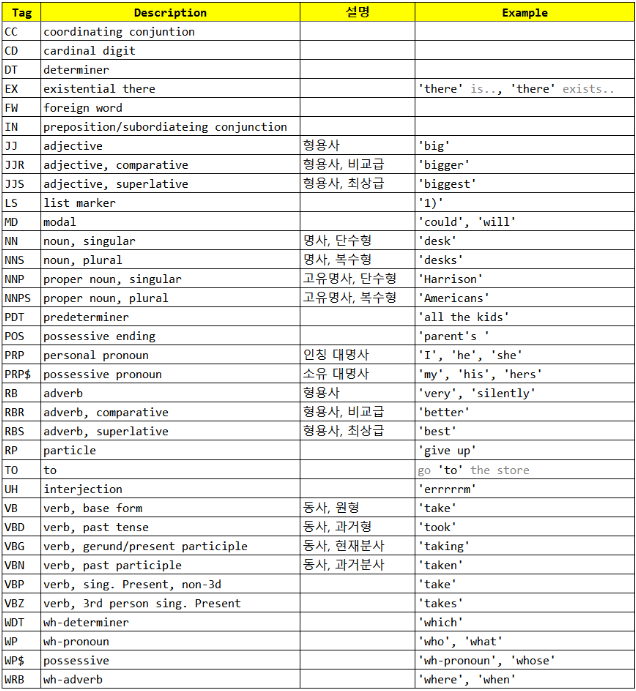
1.6 불용어(stop_words) 제거
영어의 전치사(on, in), 한국어의 조사(을, 를) 등은 분석에 필요하지 않은 경우가 많습니다. 길이가 짧은 단어나 등장 빈도 수가 적은 단어들 또한 분석에 큰 영향을 주지 않습니다.
일반적으로 사용되는 도구들은 해당 단어들을 제거해주지만 완벽하게 제거되지는 않습니다.
따라서 사용자가 불용어 사전을 만들어 해당 단어들을 제거하는 것이 좋습니다. 즉, 도구들이 걸러주지 않는 전치사, 조사 등을 불용어 사전으로 만들어 불필요한 단어들을 제거합니다.
stop_words = 'on in the'
stop_words = stop_words.split(' ')
stop_words
# ['on', 'in', 'the']
sentence = 'singer on the stage'
sentence = sentence.split(' ')
nouns = []
for noun in sentence:
if noun not in stop_words:
nouns.append(noun)
nouns
# ['singer', 'stage']
(* nltk 의 불용어 사전인 stopwords.words('언어')를 사용할 수도 있습니다.)
import nltk
nltk.download('stopwords')
from nltk import word_tokenize
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
print(stop_words)
# ['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're", "you've" ... ]
s = 'If you do not walk today, you will have to run tomorrow'
words = word_tokenize(s)
print(words)
# ['If', 'you', 'do', 'not', 'walk', 'today', ',', 'you', 'will', 'have', 'to', 'run', 'tomorrow']
no_stopwords = []
for w in words:
if w not in stop_words:
no_stopwords.append(w)
no_stopwords
# ['If', 'walk', 'today', ',', 'run', 'tomorrow']
1.7 철자 교정
텍스트에 오탈자가 존재하는 경우가 있을 수 있습니다. 예를 들어, 단어 'apple' 을 'aplpe' 과 같이 철자 순서가 바뀌거나 'spple' 와 같이 철자가 틀릴 수 있습니다.
사람이 적절한 추정을 통해 이해하는데는 문제가 없지만, 컴퓨터는 이러한 단어를 그대로 받아들여서 처리가 필수적입니다.
다행히도 철자 교정 알고리즘은 이미 개발되어 워드 프로세서나 다양한 서비스에서 많이 적용됩니다.
(!pip install autocorrect 로 autocorrect를 설치하고 Speller 를 import 하여 사용할 수 있습니다.)
!pip install autocorrect
from autocorrect import Speller
spell = Speller('en')
print(spell('peoplle'))
print(spell('peope'))
print(spell('peopla'))
# people
# people
# people
s = word_tokenize('Earlly biird cathchess the womm')
print(s)
# ['Earlly', 'biird', 'cathchess', 'the', 'womm']
ss = ' '.join([spell(s) for s in s])
print(ss)
# Early bird catches the worm
1.8 언어의 단수화와 복수화
textblob 의 .singularize() 와 .pluralize() 를 통해 단수화와 복수화를 할 수 있습니다.
1.9 어간(Stemming) 추출
nltk 의 .stem.PorterStemmer() 를 통해 stemmer 객체를 얻어서 구현할 수 있습니다.
1.10 표제어(Lemmatization) 추출
nltk 의 wordnet 을 다운로드 받고, WordNetLemmatizer 를 import 하면 구현할 수 있습니다.
1.11 개체명 인식(NER, Named-Entity-Recognition)
nltk 의 maxent_ne_chunker 와 words 를 다운로드 받고, pos_tag 를 통해 PoS 태깅한 것을 nltk.ne_chunk() 에 넣어주면 구현할 수 있습니다.
1.12 단어 중의성(Lexical Ambiguity)
nltk.wsd 에 lesk 를 import 하면 구현할 수 있습니다.
'[Deep daiv.] > [Deep daiv.] NLP' 카테고리의 다른 글
| [Deep daiv.] WIL, NLP - 7. Seq2seq with Attention (0) | 2024.08.29 |
|---|---|
| [Deep daiv.] WIL, NLP - 5. 토픽 모델링 (0) | 2024.08.22 |
| [Deep daiv.] WIL, NLP - 4. 의미 연결망 분석(Sematic Network Analysis) (0) | 2024.08.21 |
| [Deep daiv.] WIL, NLP - 3. 군집 분석 (0) | 2024.08.20 |
| [Deep daiv.] TIL & WIL - 5. 자연어 처리 & 텍스트 처리 (Contd.) (0) | 2024.08.14 |