
https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=11151299&tag=1
IEEE Xplore Full-Text PDF:
ieeexplore.ieee.org
Introduction.
https://namu.wiki/w/%EC%8A%A4%EB%A7%88%ED%8A%B8%20%EA%B7%B8%EB%A6%AC%EB%93%9C
스마트 그리드
스마트 그리드(Smart Grid)란 기존 전력망에 정보통신기술( ICT )을 융합하여 전력 생산, 전달, 소비를
namu.wiki
현대의 smart grid는 국제 표준들에 의해 설정된 극한의 온도(-40˚C to 70˚C)와 높은 습도(≤95% RH), 부품 손상을 유발하는 기계적 진동들을 포함하는 거친 현장 조건들에 직면합니다. 200만 건 이상의 서비스 기록들에 대한 연구에 따르면(J, Zhao et al., 2023), 고장의 19%가 이러한 현장 조건들의 조합으로부터 나오며, grid를 안정적으로 유지하기 위해서는 더 나은 진단 도구들이 필요함을 주장합니다.
하지만 기존의 방법들(예: 기본적인 임계값 사용, SVM, Random Forest 등)은 초기 결함을 놓치거나, hyperparameter등에 매우 의존적이며, 복잡한 데이터들의 관계를 이용하는데 어려움이 있습니다. 또한 다양한 데이터들의 유형들을 병합하는 것도 어렵습니다. 단순히 feature들을 겹합하는 것은 잘 동작하지 않으며, late-stage decision fusion(마지막 결정하는 단계에서 voting과 같은 방법으로 fusion하는 것)은 data(feature)들의 핵심 연결을 놓칠 수 있습니다.
현대의 딥러닝을 이용한 솔루션들을 더 정확하지만 현장에서 사용하기에는 너무 무겁습니다. 따라서 새롭게 만들어지는 딥러닝 기반 솔루션들은 정확도와 효율성의 균형을 맞추려고 노력하지만, grid application에서는 여전히 부족합니다. 해당 문제들을 정리하면 다음과 같습니다:
- 무거운 계산 없이 다양한 결함 크기들에 대해 정확도를 유지하는 것.
- 다양한 재료들에 대해 잘 동작하는 것(일반성).
- 다중 센서 데이터들을 동적으로 결합하는 것.
해당 논문은 위 문제들을 Attention-based fusion과, Dynamic Swin Transformer(DTN)을 통해 해결합니다. DTN은 불필요한 처리를 건너뛰기 위한 early-exit과, 계산이 가장 필요한 곳에 계산량을 집중하기 위한 routing을 포함합니다. 더 자세히 DTN이 가진 핵심적인 이점들은 다음과 같습니다:
- Dynamic Path Selection Mechanism: 해당 메커니즘은 모델이 feature들의 기반하여 계산 자원들을 적응적으로 할당하도록 허용하며, 더 단순한 샘플들에 대한 깊은 계산등의 낭비를 피하게 합니다. 결과적으로 이를 통해, 98.7%의 mAP와 86FPS라는 높은 추론 속도를 달성할 수 있습니다.
- Cross-Scale Attention Fusion Module: 이는 고해상도 세부사항들과 저해상도 전역 의미 정보들을 유기적으로 결합하여, 다양한 스케일의 변형들에 대해서 탐지를 가능하게 합니다.
- Confidence-Based Early Exit Mechanism: 이는 동적 임계값을 통해 샘플들의 79.3%가 얕은 계층들에서 추론을 완료하도록 하여, 계산 부하를 31.4% 만큼 줄여줍니다.
- Consistency Hierarchical Loss: 이는 조기 종료 계층들로부터의 출력이 정확도 측면에서 전체 계층 출력들로부터의 출력들과의 일관됨을 보장하며, 그로 인해 복잡한 배경들에서의 오탐(false detection) 비용을 줄여줍니다.
Methodology(원본 논문의 진행과 달리 실제 처리 순서대로 소개함).
우선 Cross-Scale Attention Fusion을 통해 다양한 scale의 feature들을 단순한 element-wise summation이 아닌, 각 scale들의 중요도를 감안하여 fusion된 feature map을 만들어줍니다:
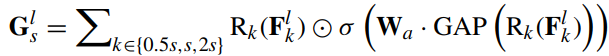
GAP는 Global Average Pooling으로, 전체 HxW에 대해서 averaging을 수행합니다. 이때 Rk는 resolution alignment로서, upsampling의 경우는 bilinear interpolation을, downsampling의 경우는 strides convolution을 수행하는 모듈이며, Wa는 Cx3 learnable matrix입니다. Wa와 softmax를 통해 각 scale별로 중요도가 계산되면, 이를 원본 feature map의 가중치로서 사용하여 fusion된 feature map G를 얻습니다.
이렇게 만들어진 G에 대해서 3x3, 1x1 conv를 통과시킨 후:

MSA(multi-head self-attention)을 patch단위로 수행합니다:

MSA의 결과로 나온 feature에 GAP를 수행한 후, MLP(C->3)를 통과시켜 각 scale에 대한 중요도를 예측합니다:

scale에 대한 중요도 g에 대해, Tanh를 통과시켜서 각 scale별로 Swin transformer의 연산을 수행할지 말지에 대한 activation vector α를 만들어냅니다:

α가 0.2보다 큰 경우에는 Swin Transformer 연산을 수행해주는데, 이는 다음과 같습니다:

STB1과 2는 각각 Window-MSA와 Shifted-Window-MSA 입니다. 그 결과로 나온 feature map H에 대해서 가중치 α를 곱해서 해당 layer의 최종 결과 Y를 출력합니다:

한편, early-exit을 위해 출력의 confidence를 예측해야하는데, 이는 다시 fusion된 feature map G를 사용하여 계산합니다. 이때 confidence α(위에서 나온 α와는 다름)는 다음과 같이 계산됩니다:

Wv는 3xC matrix로, α는 scale에 대해 결함이 있는 정도를 의미합니다. 만약 α가 하나의 scale에 몰려있다면, 해당 scale에 대해서 강한 확신이 있다는 뜻입니다. 따라서 위에서 구해진 α에 대해 가장 큰 α가 임의의 threshold를 넘으면 종료합니다(강한 확신이 있기 때문에).
*사실 이해가 안가는 포인트가 여기입니다. 어떻게 feature map에 대한 attention score를 해당 scale에 결함이 있다는 강한 확신으로 해석할 수 있는지 잘 모르겠습니다. 만약 임의의 head를 하나 통과시켜서 이를 confidence로 해석한다면 이해가 가지만, 이렇게 해석하는 건....
이때 threshold는 다음과 같습니다:

이때 평균과 표준편차는 training set 전체에 걸친 α들의 통계값입니다. 즉, "지금까지 학습할 때의 α들을 많이 봤는데, 확신이 좀 있네?" 하면 early-exit을 수행하는 것입니다. 하지만 confidence 뿐만 아니라 다음 조건도 존재합니다. 이는 consistency입니다. 해당 모델은 배경(정상)과 결함을 따로 예측합니다. 즉, softmax를 사용하지 않고 sigmoid를 사용하기 때문에, 배경일 확률 85%, 결함일 확률 90%가 가능합니다. 따라서 결함일 확률이 높으면, 당연히 배경일 확률이 줄어들어야한다는 것을 학습하기 위해 일관성 loss를 추가합니다:

이 모두를 고려하면 다음과 같은 early-exit 정책이 나옵니다:

한편, depth에 따라서 threshold를 다르게 적용할 수도 있습니다:

이는 depth가 깊어질수록 threshold가 낮아지는 특징을 갖습니다.
*여기도 이해가 안갑니다. 왜 layer가 깊어질 수록 threshold가 줄어야만 할까요? 그정도로 깊게 계산했으면 이제는 나가도 좋다는 것을 반영하기 위해서? 아니면 낮은 layer에서 쉽게 나가지 않도록 막기 위해서?
또한 다음 layer와 현재 layer의 차이가 없다면 early-exit을 하는 정책을 세울 수도 있습니다(w/ KL). 이를 고려하면 다음과 같은 early-exit 정책이 나옵니다:

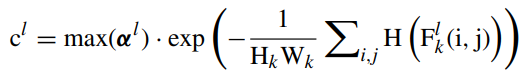
Experiment and Results.

해당 모델은 98.7% mAP@0.5를 달성하며, 이는 Swin Transformer보다 정확도는 1.9% 높으며, 68% 더 적은 FLOPs를 사용합니다. 또한 early-exit을 통해 86FPS 추론 속도를 가능하게 했으며, static Swin-T 대비 3.2배의 속도 가속을 보여줍니다.
한편 위 모델은 다음과 같은 한계점들이 존재합니다:
- early-exit threshold에 대한 현재의 설정은 여전히 적용 환경에 기반한 수동 조정을 요구하며, 완전한 자동화를 어렵게 만듭니다.
- 위 모델을 실험한 환경(전력 장비와 일부 산업 시나리오)에 대해서 효과적으로 검증되었을지라도, 극한 날씨 조건들, 강한 간섭 신호들, 또는 심각한 데이터 불균형 하에서의 그것의 robustness는 여전히 추가적인 평가와 최적화를 요구합니다.
- 대규모 분산 탐지 네트워크에서, 동적 라우팅과 early-exit 메커니즘들의 작업 스케줄링은 시스템 관리에서의 복잡성을 도입한다.
*3번의 경우는 생각해볼만 한데, 만약 정해진 sequence에 따라서 모델의 모듈을 사용하는 방식이라면(static routing), 메모리 환경이 제한된 상황에서(만약 전체 모델을 한 번에 올릴 수 있다면 이는 문제가 되지 않는다), 미리 다음 모듈을 caching 해놓음으로써 최적화를 할 수 있지만, dynamic routing의 경우 미리 caching을 할 수 없다는 점 때문에(run-time에 사용해야하는 모듈이 변경됨), 최적화에 어려움이 있을 수 있습니다.